背景
「〇〇駅と××駅とではどっちが都会か」という「駅の都会度論争」を見聞きすることはしばしばありますが、論理的に決着がついている例を見たことはほぼありません (たぶん)。
というわけで、データを使ってこの論争に決着をつけることを試みようと思いました。
…という記事を以前書いたのですが (これ)、どうも結果が変な気がしたので、別のデータで試してみたら、いい感じの結果が得られたよー、ついでにいい感じの可視化ができたのでお見せしたいよー、という記事です。
前提
本記事では「都会度=駅周辺の小売業従業員数」(以下、従業員数) と定義して分析します。
以前の記事では「都会度=駅周辺の卸売業・小売業事業所の数」としていたのですが、以下の理由で上記のように変更しています。
- 卸売業は都会度の基準としてはイマイチな気がした
- 店の規模も含めて評価したほうがよい (零細な店より大規模な店のほうが都会な) 気がした
上記の基準が妥当か否かは議論が必要なところだと思いますが、大目に見ていただけると。
使用したデータ
平成26年商業統計の500mメッシュデータを使用しました。経済産業省が公開しています (これ)。境界データは e-Stat から、鉄道駅・路線データは 国土数値情報 からとっています。
以前の記事では 2016年経済センサスの活動調査 を使用しましたが、以下の理由で商業統計に変更しています。
- 経済センサスでは小売業と卸売業をまとめて集計したデータしかない
- 小売業事業所 = 小売業の企業のオフィス ≠ 店、になっている気がする
手順
① データのダウンロード・下処理
上記データをダウンロードしてよしなに下処理 (適当でスミマセン)。
なお今回は、異なる駅だが乗換駅扱いされているものについては、同一駅として扱います (これも前回からの変更点です)。例えば秋津駅と新秋津駅は駅名は異なりますが、乗換駅として扱われている (はずの) ため、同一駅として処理します。国土数値情報のデータには乗換駅扱いの別駅同士を紐づけるような情報は入っていないため、手動で頑張って作りました。
② Python で駅ごとに集計する
やや厳密さには欠けますが、「駅 A の従業員数」を以下のように定義します。
(駅~A~の従業員数)\equiv(駅~A~から~l~[m]~以内に位置するメッシュ内の従業員数の総計)
ここで、「あるメッシュ B が駅 A から l [m] 以内に位置する」とは、駅 A から l [m] 以内の少なくとも1つの地点 P がメッシュ B に含まれることをさします。
というわけで、以下のとおり Python (PyQGIS) の力を借りて集計していきます。書き捨てのコードをそのまま貼っているのでグチャグチャなのはご容赦ください。
import processing
import pandas as pd
from qgis.core import QgsProject, QgsFeatureRequest, NULL, QgsPointXY, QgsGeometry, QgsFeature, QgsVectorLayer
dir = '[path/to/project/dir]'
input_fname = '[path/to/input_data]'
output_fname = '[path_to_output_data]'
modifies_columns = False # 駅に関する情報を縮約して出力する (True) / 縮約しないで出力する (False)
l1 = 500
# データの読み込み
df = pd.read_csv(dir + input_fname, encoding='cp932')
df['n_employees'] = 0
# レイヤーの選択
station_layer = QgsProject.instance().mapLayersByName('N02-20_Station_XY')[0]
station_point_layer = QgsProject.instance().mapLayersByName('station_centroid')[0]
mesh_layer = QgsProject.instance().mapLayersByName('MESH_ALL')[0]
for i in range(len(df)):
n_stations = df['n_station_names'].iloc[i]
n_companies = df['n_companies'].iloc[i]
n_employees = 0
for station_id in range(1, n_stations + 1):
for company_id in range(1, n_companies + 1):
# 駅名
target = df[f'station_name{station_id}'].iloc[i]
company = df[f'company{company_id}'].iloc[i]
# 駅名に対応する地物
request = QgsFeatureRequest().setFilterExpression('"N02_005"=\'' + target + '\'' + 'and' + '"N02_004"=\'' + company + '\'')
features = station_point_layer.getFeatures(request)
points = [feature.geometry().asPoint() for feature in features]
if len(points) == 0:
continue
target_station_centroid_point = QgsPointXY(sum(point.x() for point in points) / len(points), sum(point.y() for point in points) / len(points))
# 重心をポイントレイヤーとして作成
centroid_layer = QgsVectorLayer('Point?crs=EPSG:2451', 'Centroid Layer', 'memory')
centroid_provider = centroid_layer.dataProvider()
centroid_feature = QgsFeature()
centroid_feature.setGeometry(QgsGeometry.fromPointXY(target_station_centroid_point))
centroid_provider.addFeatures([centroid_feature])
# バッファリング
buffer_output1 = processing.run("native:buffer", {'INPUT':centroid_layer,'DISTANCE':l1,
'SEGMENTS':5,'END_CAP_STYLE':0,'JOIN_STYLE':0,'MITER_LIMIT':2,'DISSOLVE':False,'OUTPUT':dir + 'data/rail/buffer_output1.shp'})
# 交差しているメッシュの取り出し
processing.run("native:selectbylocation", {'INPUT':dir + 'data/mesh/MESH_ALL.shp','PREDICATE':[0],
'INTERSECT':dir + 'data/rail/buffer_output1.shp','METHOD':0})
# メッシュ内の事業所数を集計
tmp_n_employees = 0
for mesh_feature in mesh_layer.selectedFeatures():
if mesh_feature['n_employee'] != NULL:
tmp_n_employees += mesh_feature['n_employee']
n_employees = max(n_employees, tmp_n_employees)
# セントロイドレイヤーを削除
QgsProject.instance().removeMapLayer(centroid_layer)
# Record the best result
df['n_employees'].iloc[i] = n_employees
if modifies_columns:
# 不必要なカラムを削除
df = df.drop([f'company{i}' for i in range(1, 7)], axis=1)
df = df.drop(['n_station_names', 'n_companies'], axis=1)
df['station_names'] = df[['station_name1', 'station_name2', 'station_name3', 'station_name4', 'station_name5', 'station_name6']].apply(
lambda x: '/'.join([str(s) for s in x if pd.notna(s)]), axis=1
)
df = df.drop([f'station_name{i}' for i in range(1, 7)], axis=1)
df = df[['station_names', 'n_employees']]
# n_employeesの降順に並び替え
df = df.sort_values(by='n_employees', ascending=False)
# n_employeesが0のレコードを削除
df = df[df['n_employees'] > 0]
# 結果を CSV として出力
df.to_csv(dir + output_fname, index=False, encoding='cp932')
プログラムの内容はよく分かっていない部分もあるので説明しません。GPT さんありがとう。
なお、乗換駅となっている別駅を扱うときは、各駅に対して従業員数を計算し、最大値をそれらの駅の従業員数としています。つまり、駅 A と駅 B を1つの乗換駅 C として扱った場合、(C の従業員数) = max{(A の従業員数), (B の従業員数)} としています。
結果
結果です。以下では l = 500 [m] とします。また、集計対象の駅は首都圏を中心に著者の独断で選びました。
前回はひどく見づらい横長な棒グラフを載せましたが、グループに分けて縦長な棒グラフにしようと思います。縦軸は駅名、横軸は従業員数です。
第1位グループ
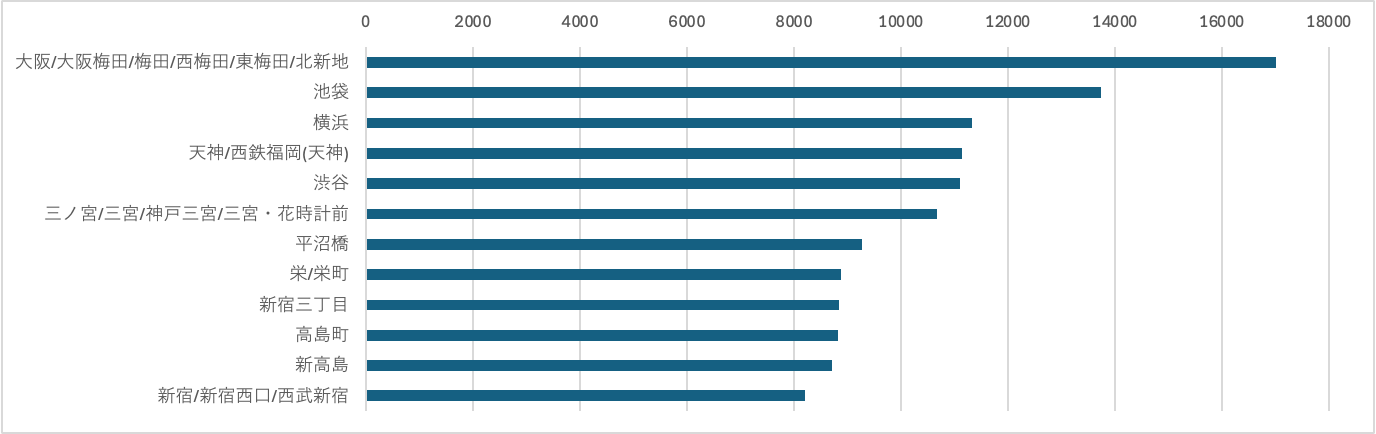
大阪駅が圧倒的1位。私は首都圏に住んでいますが、大阪駅前は東京のどこよりも栄えている感じがしたので、個人的には納得です。新宿が意外と下位ですが、西口はほぼオフィス街であることを考えると、妥当な結果のようにも思えてきます。東京大阪以外にも、横浜、天神、三ノ宮、栄などの巨大繁華街もランクイン。
第2位グループ
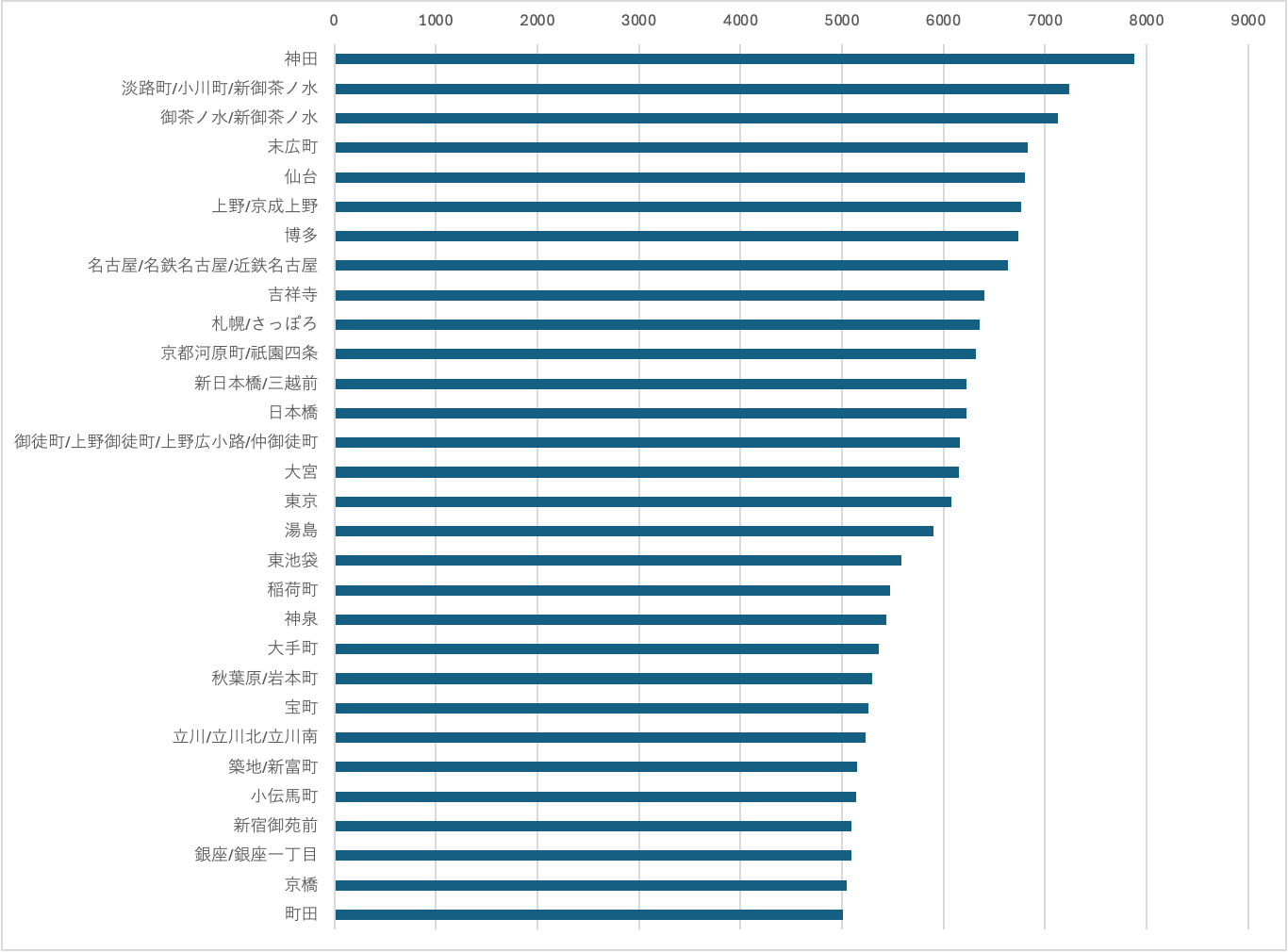
仙台と上野と博多と名古屋が同じくらいで、その少し下に札幌と吉祥寺、さらに少し下に大宮と、なるほど〜という結果。
さらにその下に立川、町田と、郊外駅の中では最強クラスの駅がランクイン。
第3位グループ
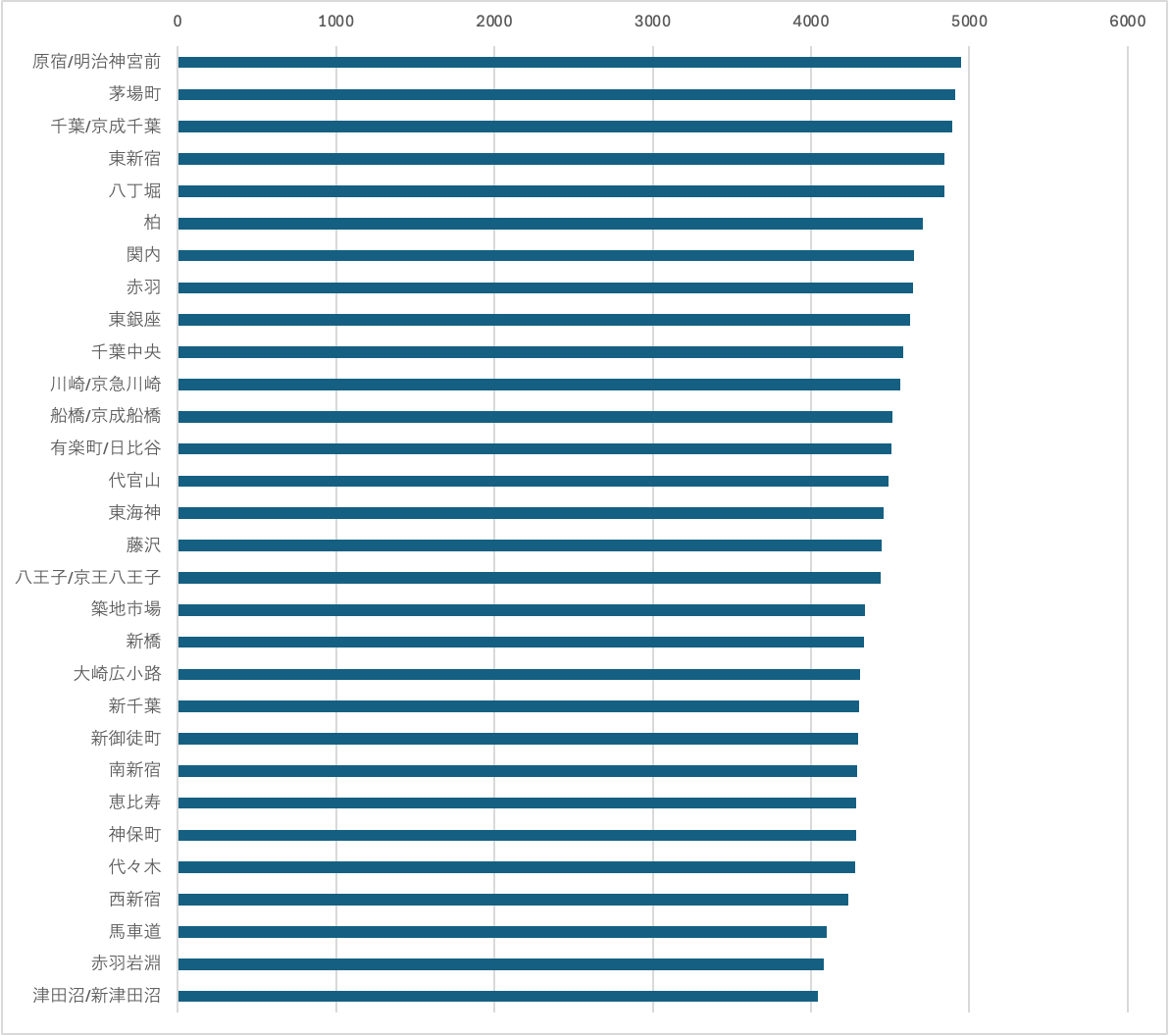
このあたりから首都圏の大きめの郊外駅が多くなります。抜き出すと、千葉、柏、川崎、船橋、藤沢、八王子、津田沼という順ですね。川崎がもっと上な気もしますが、概ねイメージどおりな並びです。
原宿と千葉が同じくらい、八王子と新橋が同じくらい、的な比較も普段しないので面白いですね。
第4位グループ
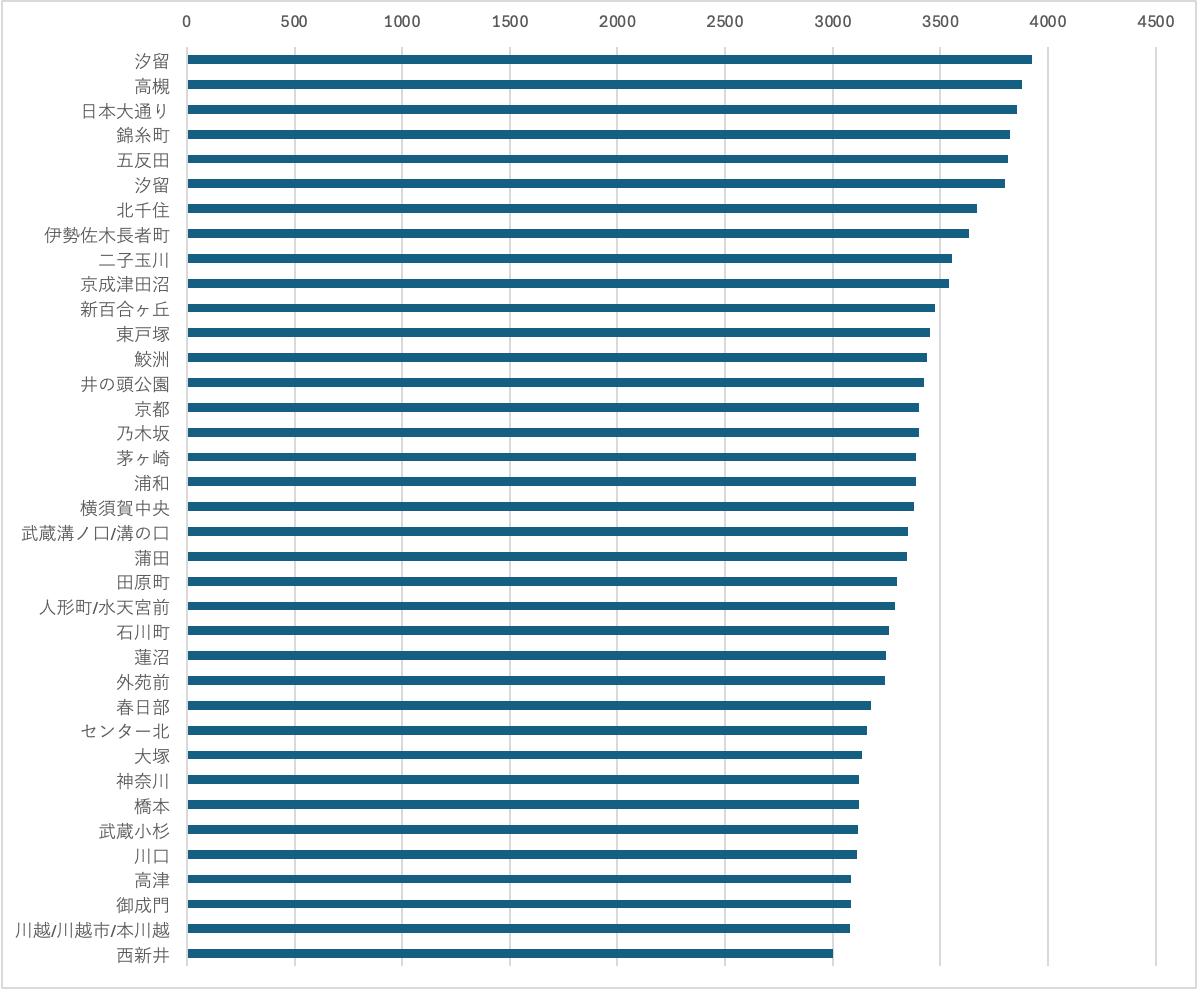
大阪の郊外駅である高槻がここにランクイン。首都圏からは二子玉川、新百合ヶ丘、横須賀中央、春日部、川越、西新井など私鉄の大きめのまちや、東戸塚、茅ヶ崎、溝の口、武蔵小杉、川口など中堅 (?) 層が並びます。錦糸町、北千住、蒲田など東京の玄関口的な駅も上位にいますね。あと京都市の中心が河原町なのは知っていたが、京都駅がここまで低ランクだとは思わなかったです。
第5位グループ
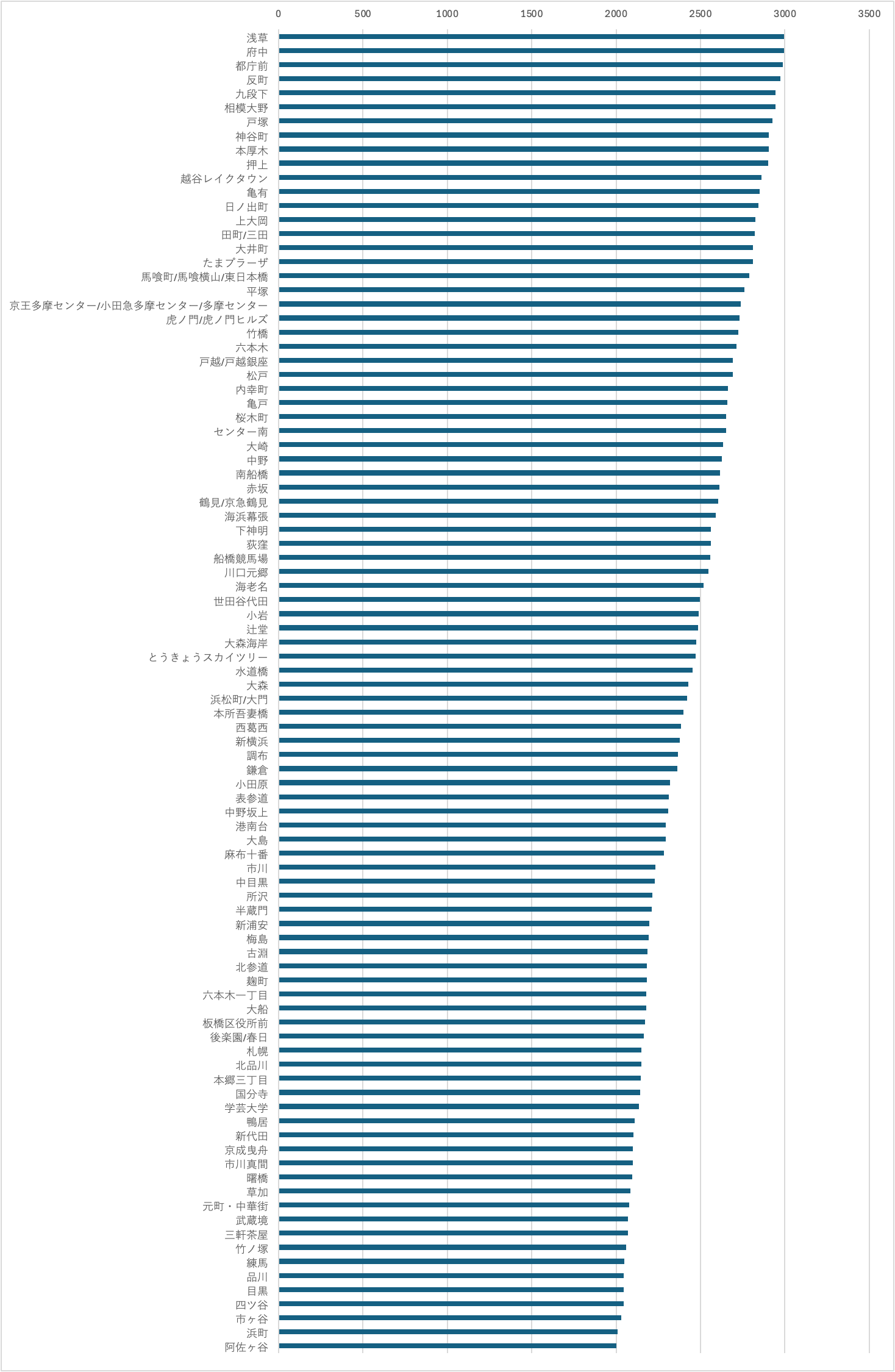
これは完全に個人的な感覚ですが、従業員数 2500 くらいまでの駅は駅前で大体なんでも完結するイメージですね。第6位グループ以降は省略で。
地図上に可視化
以上の結果を地図上で直感的に見られたら面白いなーと思い、以下のルールで描画してみました。
- 従業員数が7000以下の場合は円の半径に比例させる
- 従業員数が7000以上の場合は円の色を青→黄→赤のグラデーションにする
描画も Python (PyQGIS) にお世話になりました。例によって書き捨てのコードを以下に共有します。
import pandas as pd
from qgis.core import QgsProject, QgsFeatureRequest, QgsPointXY, QgsGeometry, QgsFeature, QgsVectorLayer, QgsField, QgsWkbTypes, QgsVectorFileWriter, QgsTextFormat, QgsTextBufferSettings, QgsTextBackgroundSettings, QgsSimpleFillSymbolLayer, QgsVectorLayerSimpleLabeling, QgsPalLayerSettings, QgsFillSymbol, QgsRenderContext, QgsSingleSymbolRenderer, QgsRuleBasedRenderer, QgsExpression, QgsProperty, QgsUnitTypes
from PyQt5.QtCore import QVariant
from PyQt5.QtGui import QColor, QFont
dir = '[dir/path]'
input_csv = '[path/to/input/data]' # `n_employees`カラムを含むCSVファイル
output_layer = '[path/to/output/layer1]' # 出力するシェープファイル名
output_text_layer = '[path/to/output/layer2]' # 出力するシェープファイル名
threshold1 = 7000 # 円の半径で表現する n_employees の最大値
threshold2 = 10000 # RGBのみで表現する n_employees の最大値
# データの読み込み
df = pd.read_csv(dir + input_csv, encoding='cp932')
# レイヤーの選択
station_layer = QgsProject.instance().mapLayersByName('N02-20_Station_XY')[0]
# 新しいベクターレイヤーを作成 (円)
circle_layer = QgsVectorLayer('Polygon?crs=EPSG:2451', 'Circles', 'memory')
circle_provider = circle_layer.dataProvider()
# 'station_names'と'n_employees'フィールドを追加
circle_provider.addAttributes([QgsField('station_names', QVariant.String), QgsField('n_employees', QVariant.Int)])
circle_layer.updateFields()
# 新しいベクターレイヤーを作成(テキスト)
text_layer = QgsVectorLayer('Point?crs=EPSG:2451', 'TextLabels', 'memory')
text_provider = text_layer.dataProvider()
text_provider.addAttributes([QgsField('n_employees_text', QVariant.String)])
text_layer.updateFields()
# 各レコードを処理
for index, row in df.iterrows():
station_points = []
station_names_list = []
for station_id in range(1, row['n_station_names'] + 1):
for company_id in range(1, row['n_companies'] + 1):
station_name = row[f'station_name{station_id}'].strip()
company_name = row[f'company{company_id}'].strip()
if pd.notna(station_name) and pd.notna(company_name):
request = QgsFeatureRequest().setFilterExpression(f'"N02_005"=\'{station_name}\' and "N02_004"=\'{company_name}\'')
features = station_layer.getFeatures(request)
for feature in features:
geom = feature.geometry()
geom_type = geom.type()
if geom_type == QgsWkbTypes.LineGeometry or geom_type == QgsWkbTypes.LineString:
centroid = geom.centroid().asPoint()
if centroid:
station_points.append(QgsPointXY(centroid))
station_names_list.append(station_name)
else:
print(f"Feature has unexpected geometry type: {geom_type}")
if not station_points:
continue
# 中心地点を計算
avg_x = sum(point.x() for point in station_points) / len(station_points)
avg_y = sum(point.y() for point in station_points) / len(station_points)
center_point = QgsPointXY(avg_x, avg_y)
# 駅名をスラッシュ区切りにする
station_names = '/'.join(sorted(set(station_names_list)))
# 円の作成
n_employees = row['n_employees']
radius = n_employees * 0.2 if n_employees < threshold1 else threshold1 * 0.2
geometry = QgsGeometry.fromPointXY(center_point).buffer(radius, 30)
# フィーチャの作成 (円)
feature = QgsFeature()
feature.setGeometry(geometry)
feature.setAttributes([station_names, n_employees])
circle_provider.addFeatures([feature])
# フィーチャの作成(テキスト)
text_feature = QgsFeature()
text_feature.setGeometry(QgsGeometry.fromPointXY(center_point))
text_feature.setAttributes([str(n_employees)])
text_provider.addFeatures([text_feature])
# フィーチャ追加後の更新
circle_layer.updateExtents() # 修正: フィーチャ追加後の更新
text_layer.updateExtents() # 修正: フィーチャ追加後の更新
# ユーザールールの作成
root_rule = QgsRuleBasedRenderer.Rule(None)
# 円のレンダリング (n_employees が threshold 未満なら青色、それ以上ならグラデーション)
second_max_n_employees = df['n_employees'].drop_duplicates().sort_values(ascending=False).iloc[1] # 大阪の値が大きすぎるので2番目に大きい値を取得
for feature in circle_layer.getFeatures():
n_employees = feature['n_employees']
if n_employees < threshold1:
color = QColor(0, 0, 255, 127) # 青色、半透明 (A=127)
elif n_employees < threshold2:
norm_color_value = (n_employees - threshold1) / (threshold2 - threshold1)
# n_employees 前後で色が連続に変化するようにグラデーションを設定
color = QColor(255 * norm_color_value, 255 * norm_color_value, 255 * (1 - norm_color_value), 127 + 32 * norm_color_value) # 青から黄へのグラデーション
elif n_employees <= second_max_n_employees:
norm_color_value = (n_employees - threshold2) / (second_max_n_employees - threshold2)
color = QColor(255, 255 * (1 - norm_color_value), 0, 190 + 32 * norm_color_value) # 黄から赤へのグラデーション
else:
color = QColor(255, 0, 100, 222)
fill_layer = QgsSimpleFillSymbolLayer()
fill_layer.setColor(color)
fill_symbol = QgsFillSymbol()
fill_symbol.changeSymbolLayer(0, fill_layer)
fliter_expression = f'"n_employees" = {n_employees}'
rule = QgsRuleBasedRenderer.Rule(symbol=fill_symbol, filterExp=fliter_expression)
root_rule.appendChild(rule)
# Renderer の設定
renderer = QgsRuleBasedRenderer(root_rule)
circle_layer.setRenderer(renderer)
# レイヤーを追加
QgsProject.instance().addMapLayer(circle_layer)
# テキストラベルの設定
text_format = QgsTextFormat()
text_format.setFont(QFont("Arial", 8))
text_format.setSizeUnit(QgsUnitTypes.RenderPoints)
text_format.setSize(8)
buffer_settings = QgsTextBufferSettings()
buffer_settings.setEnabled(True)
buffer_settings.setSize(0.8)
buffer_settings.setColor(QColor("white"))
text_format.setBuffer(buffer_settings)
text_background = QgsTextBackgroundSettings()
text_background.setFillColor(QColor("white"))
text_background.setEnabled(False)
text_format.setBackground(text_background)
text_settings = QgsPalLayerSettings()
text_settings.isExpression = False
text_settings.fieldName = "n_employees_text"
text_settings.placement = QgsPalLayerSettings.OverPoint
text_settings.setFormat(text_format)
# サイズのユニットを地図単位に設定
text_settings.sizeUnit = QgsUnitTypes.RenderMapUnits
text_settings.setFormat(text_format)
labeling = QgsVectorLayerSimpleLabeling(text_settings)
text_layer.setLabelsEnabled(True)
text_layer.setLabeling(labeling)
QgsProject.instance().addMapLayer(text_layer)
# シェープファイルとして保存
QgsVectorFileWriter.writeAsVectorFormat(circle_layer, dir + output_layer, 'utf-8', circle_layer.crs(), 'ESRI Shapefile')
QgsVectorFileWriter.writeAsVectorFormat(text_layer, dir + output_text_layer, 'utf-8', text_layer.crs(), 'ESRI Shapefile')
このプログラムの内容も特に説明はできませんしません。解読したい方は ChatGPT などを活用いただければと思います。
首都圏について描画した結果が以下です (凡例や縮尺がないのは許してください、、)。
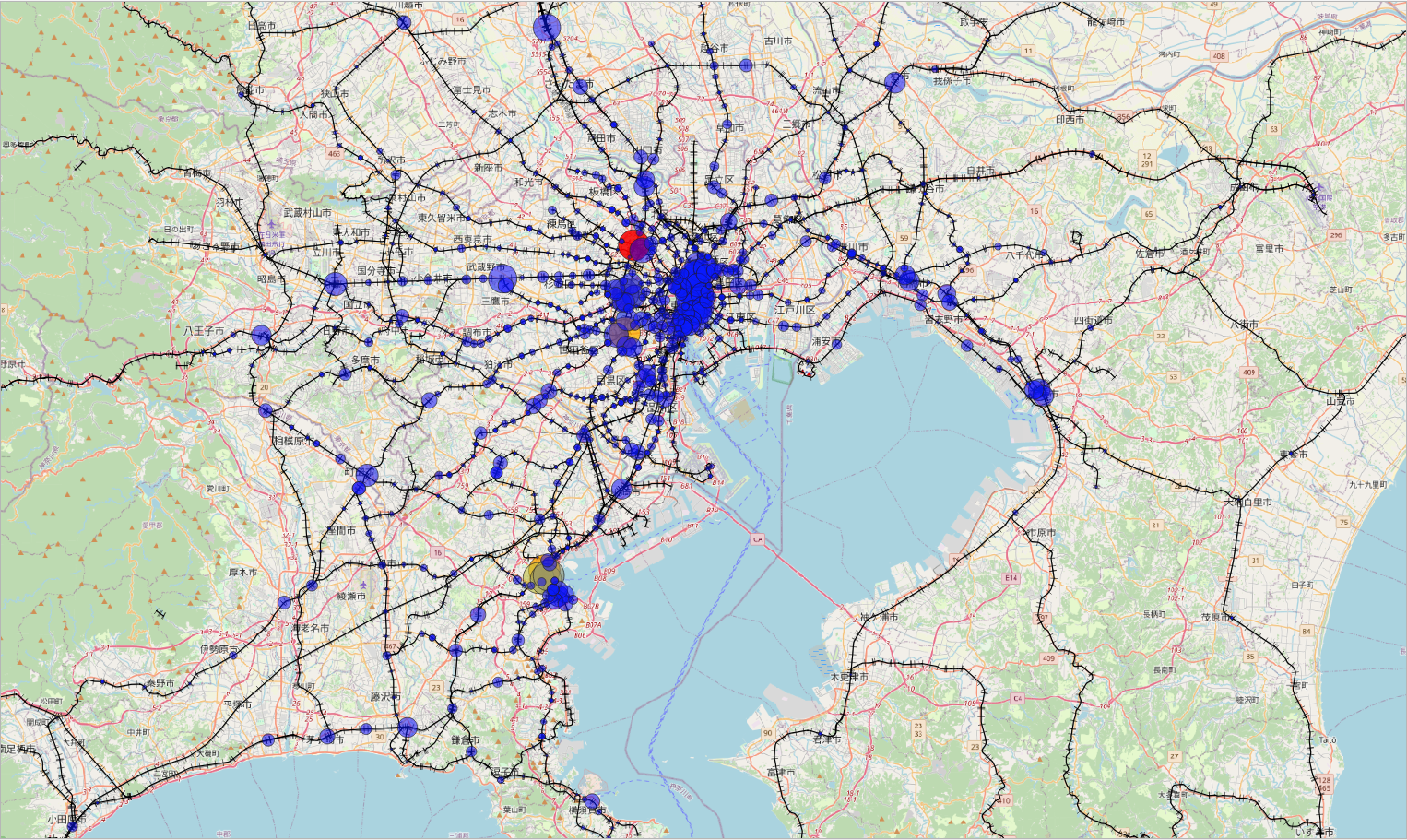
なかなか映えますよね。都心は円同士が重なり合って大変なことになっており、都心から各方面一定程度離れたところにサブセンターが存在している様子を見てとることができます。
まとめ
前回の記事から使用するデータや描画方法などを変更してみたところ、なかなか面白いアウトプットが得られました。描画はもっと工夫できる気もするので色々考えてみようと思います。