Vimで文字化けを防ぐための設定に関する記事が結構見つかるのですが、 Help に記載されている文字認識のルールをきちんと解説していることが少ないようですので、それらのルールを簡単にまとめ、そこから推定される推奨設定案を記載します。
「簡単に」と書きましたが結構な分量になってしまいましたので、
「細かい理屈はいいから設定だけ知りたい」という方は「.vimrc のおすすめ設定」から読んでください。
基本的な考え方
登場する設定値は以下になります。
| 値 | 役割 |
|---|---|
encoding |
Vim が内部処理に利用する文字コード。ただし、文字コード判定に失敗した場合はファイルの文字コードの最後の選択肢として利用される場合がある。 |
fileencodings |
Vim が 既存ファイルの 文字コード推定に使う文字コードのリスト。 |
fileencoidng |
ローカル設定値は、文字コード推定の結果Vimが設定する。 グローバル設定値は 新規ファイルを作成する際の文字コード として利用される。 |
ambiwidth |
UTF-8 を利用している場合に Ambiguous Width Character の字幅を指定するための設定値(詳細後述)。 |
langmenu |
GUIを使っている場合に、メニューの表示に使われる言語の設定(詳細後述)。 |
判定ルールは以下の通り。
- 既存のファイルを開いた場合、以下の手順で
fileencodingが選択されます:-
fileencodingsのリストを最初から順番に試し、エラーが発生しなかったものがfileencodingの値として設定されます。
この際、ファイルの中に内部エンコーディングencodingで表示できない文字が含まれる場合はエラーと解釈されるので注意が必要です(詳細後述)。 -
fileencodingsのすべてでエラーが発生した場合はfileencodingの値は空になります。この場合、ファイルの文字コードとしてはencodingに設定されている値を利用します。
-
- 新しいファイルを開いた場合、
fileencodingsの値は無視され、fileencodingのグローバル設定の値が利用されます。 - いずれの場合も、ファイルを開く際に
++enc <文字コード>オプションを指定した場合、fileencodingsによる文字コードの推定は行われず、ローカルのfileencodingは指定した文字コードに設定されます。
課題1 - ASCII のみを含むファイルを開いたときの文字コードの設定
前述の通り、既存のファイルを開いた場合は fileencodings に列挙されている文字コードを順番に試して、成功したものが fileencoding の値として採用されます。
ここで考慮する必要があるのは、ファイルが空、ないし ASCII のみで構成されていた場合です。
ASCIIのみを含むファイルは、ほぼどの文字コードでも問題なく開けるため(例外:ucs-bom)、そのようなファイルの文字コードは fileencodings に出てくる ucb-bom 以外の最初のものになると考えてください。
この事情により、通常は以下のいずれかの設定を行ってください:
-
fileencodingsの最初に自分がデフォルトで使いたい文字コードを指定する。 -
fileencodingsの先頭はusc-bomにして、2番めにデフォルトで使いたい文字コードを指定する。
諸般の事情により、デフォルトの文字コードを fileencodings の先頭に置けない場合は、autocmd を設定することで文字コードを指定することが可能です。以下で妥当な autocmd の設定を検討します。
対策案1 - Vim の fileenodings のヘルプに書いてあるやり方 ⇒ 失敗
この場合の基本的な対策は、 autocmd を適切に使うことですが、ヘルプに書いてある以下のサンプルだと(単純に空白文字以外の数を数えているため)今回期待する処理は実現されません:
au BufReadPost * if search('\S', 'w') == 0 |
\ set fenc=iso-2022-jp | endif
この場合、正規表現 \S は「空白文字以外」ですので、改行などを含む、ASCII コードのみからなるファイルでは fileencodings の最初の文字コードが使われてしまいます。
対策案2 - ASCIIの範囲の文字だけ含まれるかのチェック ⇒ 失敗
ファイルが ASCII コードのみで構成されているかの検定は正規表現 [^\x00-\x7F] を使うとできますので、これを利用して、 autocmd を設定してみると以下のような感じになります:
※参考: Vimに非ASCII文字を強調表示させる方法は?
autocmd BufReadPost * if search('[^\x00-\x7F]', 'w') == 0 |
\ setlocal fileencoding=utf-8 | endif
ところが、これだとファイルが読み込み専用だった場合に、 fileencoding の変更はある種の編集と解釈されるため、 'modeline' がオフなので、変更できません というエラーが出ることになります。
動作確認済 - autocmd によるデフォルトの文字コードの指定方法
このエラーを回避する設定は以下になります:
autocmd BufReadPost * if !&readonly && search('[^\x00-\x7F]', 'w') == 0 |
\ setlocal fileencoding=utf-8 | endif
オプション readonly の値をチェックすることでファイルが書き込み専用かどうかの判定をすることができます。
課題2 - ファイルに encoding で表現できない文字が含まれると文字化けする
盲点なのですが、ファイルが利用している文字コードが fileencodings にきちんと含まれていても、そのファイル中に encoding では表現できない文字が含まれていた場合にはファイルを開くときにエラーとして解釈されてしまいます。
このため、ファイルが encoding で表現できない文字が含む場合、fileencodings による推定結果が「該当する文字コードなし」になりますのでご注意ください。
具体的例
ファイルがUTF-8でエンコードされており、Vim の encoding が cp932 の場合、UTF-8 には含まれるが CP932 には含まれない文字がファイルにある場合、文字化けする。
対策 - 問題の起きにくい encoding の選択
この問題を避ける簡単な方法は、Vim の encoding を比較的サポートしている文字数が多い文字コードにすることです。
つまり UTF-8 にすれば問題はほとんど起きなくなります。
課題3 - encoding を UTF-8 にした場合に一部の2バイト文字の幅が1文字分になる
文字化けを防ぐ観点からは、Vim の内部文字コード encoding は UTF-8 などの表現できる文字が多い文字コードを利用するほうが有利ですが、Windows 版の Vim で内部文字コードを UTF-8 に設定すると、一部の文字で文字幅が正しく取得できないのか、本来2文字分のスペースでレンダリングされるべきものが1文字分の幅で表示されてしまいます。
文字幅が不正になる例↓
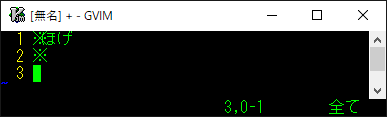
この問題は、UTF-8 の一部の文字が Ambiguous Width Character というロケールやフォントにより文字幅が変わる仕様になっているのが原因です。
対策 - ambiwidth の設定による文字幅の調整
Vim ではこれらの文字の幅を一括して設定するオプションとして、ambiwidth があります。
このオプションを適切に設定すればこれらの文字は2字幅で表示されますので、.vimrc に以下の設定を入れましょう。
if exists('&ambiwidth')
set ambiwidth=double
endif
参考: Width of some 2-byte character becomes width of 1-byte character, on Windows.
Vim の ambiwidth のヘルプにも以下の記載があり、この設定が推奨されています:
Perhaps it also has
to be set to "double" under CJK MS-Windows when the system locale is
set to one of CJK locales. See Unicode Standard Annex #11
(http://www.unicode.org/reports/tr11).
課題4 - GUIのメニューが文字化けする
Windows の場合、内部文字コード encoding を utf-8 にした場合、何もしないと GUI(Gvim)のメニューが文字化けします。
対策 - langmenu によるメニュー表示言語の設定
メニューの表示用の文字コードを langmenu で設定しましょう。
補足 - langmenu の設定は順番が重要です
langumenu の設定は、少しコツが必要です。
一度メニューが描画されてしまうと、 langmenu を設定しただけでは表示は変化しません。
設定の反映には、以下のような手順でメニューを再描画を行う必要があります(参照: :help langmenu)。
source $VIMRUNTIME/delmenu.vim
set langmenu=none
source $VIMRUNTIME/menu.vim
ここで、メニューの描画は、$VIMRUNTIME/menu.vim により実施されていますが、このスクリプトのロードは以下のいずれかのタイミングで行われます(参考: :help menu.vim)。
-
syntax onとなった場合。 -
filetype onとなった場合。 -
.vimrcのロードが終了した場合。
上の2つはよく .vimrc に出てくるので注意が必要です。
.vimrc の中でこれらの操作をしている場合、以下のいずれかの対策を行ってください。
-
syntax、filetypeの設定をlangmenuの設定より後になるように順番を調整する。 -
delmenu.vim及びmenu.vimにより、langmenu再設定後にメニューを再描画する。
よくデフォルトでロードされている $VIMRUNTIME/defaults.vim には syntax などの設定が入っている場合が多いので注意が必要です。
.vimrc のおすすめ設定
日本語をロケールとして使う方々におすすめの設定は以下の通り(確認した環境は Vim 8.2 MS-Windows 32 ビット版の公式配布バイナリです)
-
encodingの値は、表示できる文字の種類が多いutf-8がおすすめです。 -
fileencodingの値をで設定しておきましょう。この値は利用者が新しくファイルを作る場合に使用するべき文字コードを設定してください。 -
fileencodingsでは、前述の通り、先頭付近にデフォルトの文字コード(例ではutf-8)を置きましょう。 -
encodingがutf-8の場合に、Ambiguous Width Character の文字幅が常に2字幅になるように、ambiwidthの設定をしておきましょう。 - GUIの場合にメニューの文字化けを防ぐために
langmenuを設定しましょう。set langmenu=noneにして英語で表記するか、set langmenu=ja_JP.utf-8にしてencodingと整合性をとる方法のいずれかにしてください。
これらを反映し、私は以下のような設定にしています(実際はもう少しごちゃごちゃしていますが)。
" 1. 内部処理コードの設定
set encoding=utf-8
" 2. 空のファイルの文字コードの設定。
set fileencoding=&encoding
" 3. 先頭付近にデフォルトの文字コードを入れ、その他ありそうな文字コーqを列挙します。
set fileencodings=ucs-bom,utf-8,iso-2022-jp,cp932,euc-jp,default,latin
" 4. Ambiguous Width Characters の設定。
set ambiwidth=double
" 5. Menuの言語の設定
set langmenu=none
"set langmenu=ja_JP.utf-8 " 日本語のメニューを出すならこちら。
" ... `defaults.vim` のロードはこれより後に実行する。
バックアップ - それでも文字化けした場合の対応策
多くの類似記事にある通り、上記設定でも文字化けしてしまった場合は、以下の方法で文字コードを強制しましょう。
:e ++enc=utf-8
補足 - 設定を自動で行うプラグイン
上記のルールをふまえて、プラグインにまとめたものを GitHub に公開しました:
https://github.com/aikige/fenc_jp_simple.vim
補足 - Help をきちんと読んでみましょう
このあたりの詳細の仕様については、 fileencoding に関するヘルプに書いてありますので、一度以下を見てみることをおすすめします。
:help fileencodings
げ、英語だ… と思った方は以下の翻訳が役に立つと思われます:
その他の参考文書
-
East Asian Width Property Data File - Unicode の東アジア系文字の字幅の情報データベース。Ambiguous Width Character は
;Aという表示で区別できる。