はじめに
Azure Blob StorageにアップロードしたExcelファイル (.xlsx)のシート一覧をAzure Functionsで取得し、各シートに対する処理を記述したDataFlowをForEachで繰り返し処理する方法を検証しました。自分の備忘録としてメモします。
方針
- Functions でExcelファイルのシート一覧を出力する
- Functions ではPythonランタイムを使用し、Excelファイルの読み込みにはopenpyxlライブラリを使用する
- Synapse Pipeline Data Flow (or Azure Data Factory Data Flow)で、1シートを対象としたデータ加工フローを作成する
- Synapse Pipeline の ForEachアクティビティで Data Flowの処理繰り返し処理する
Functions の設定
各種設定
今回はHTTPトリガーで作成しました。
ひとまず、べた書きで"path": "container/directory/filename.xlsx",の箇所に対象とするExcelファイルを記述しました。
{
"scriptFile": "__init__.py",
"bindings": [
{
"authLevel": "function",
"type": "httpTrigger",
"direction": "in",
"name": "req",
"methods": [
"get",
"post"
]
},
{
"type": "http",
"direction": "out",
"name": "$return"
},
{
"name": "inputblob",
"type": "blob",
"dataType": "binary",
"direction": "in",
"path": "container/directory/filename.xlsx",
"connection": ""
}
]
}
local.settings.jsonにてAzureストレージアカウントへの接続情報を記載します。
Pythonの外部ライブラリを使用するため、"PYTHON_ENABLE_WORKER_EXTENSIONS": "1"の記載を追加します。
{
"IsEncrypted": false,
"Values": {
"AzureWebJobsStorage": "DefaultEndpointsProtocol=https;AccountName=アカウント名;AccountKey=アカウントキー;EndpointSuffix=core.windows.net",
"FUNCTIONS_WORKER_RUNTIME": "python",
"PYTHON_ENABLE_WORKER_EXTENSIONS": "1"
}
}
合わせて、requirements.txtにopenpyxlを追加します。
azure-functions
openpyxl == 3.0.6
Excelシート一覧を取得し出力する
__init__.pyはシンプルに受け取ったExcelデータをもとに、シート名の一覧を取得してカンマ区切りで返すコードになっています。
対象としているExcelファイルの中身がバイナリデータとして入ってくるため、BytesIOを使った処理を入れています。
シート名にはカンマ( , )が入っていない前提です。
import logging
from io import BytesIO
import azure.functions as func
import openpyxl
def main(req: func.HttpRequest, inputblob: bytes) -> func.HttpResponse:
logging.info('Python HTTP trigger function processed a request.')
workbook_b = BytesIO(inputblob)
workbook_b.seek(0)
wb = openpyxl.load_workbook(workbook_b)
output_txt = ",".join(wb.sheetnames)
return func.HttpResponse(f"{output_txt}")
Synapse Pipeline (Azure Data Factory)の設定
私の場合はSynapse PipelineにてData Flow, Pipelineの作成を行いましたが、基本的にAzure Data Factoryでも同様に作成可能です。
※下記スクリーンショット内では一部項目を白塗りしております。空欄に見えても実際には空欄ではない場合があるのでご注意ください。
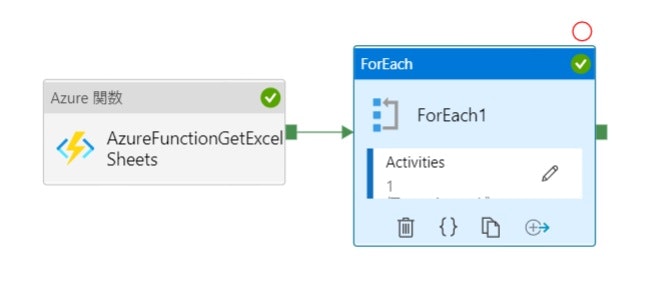
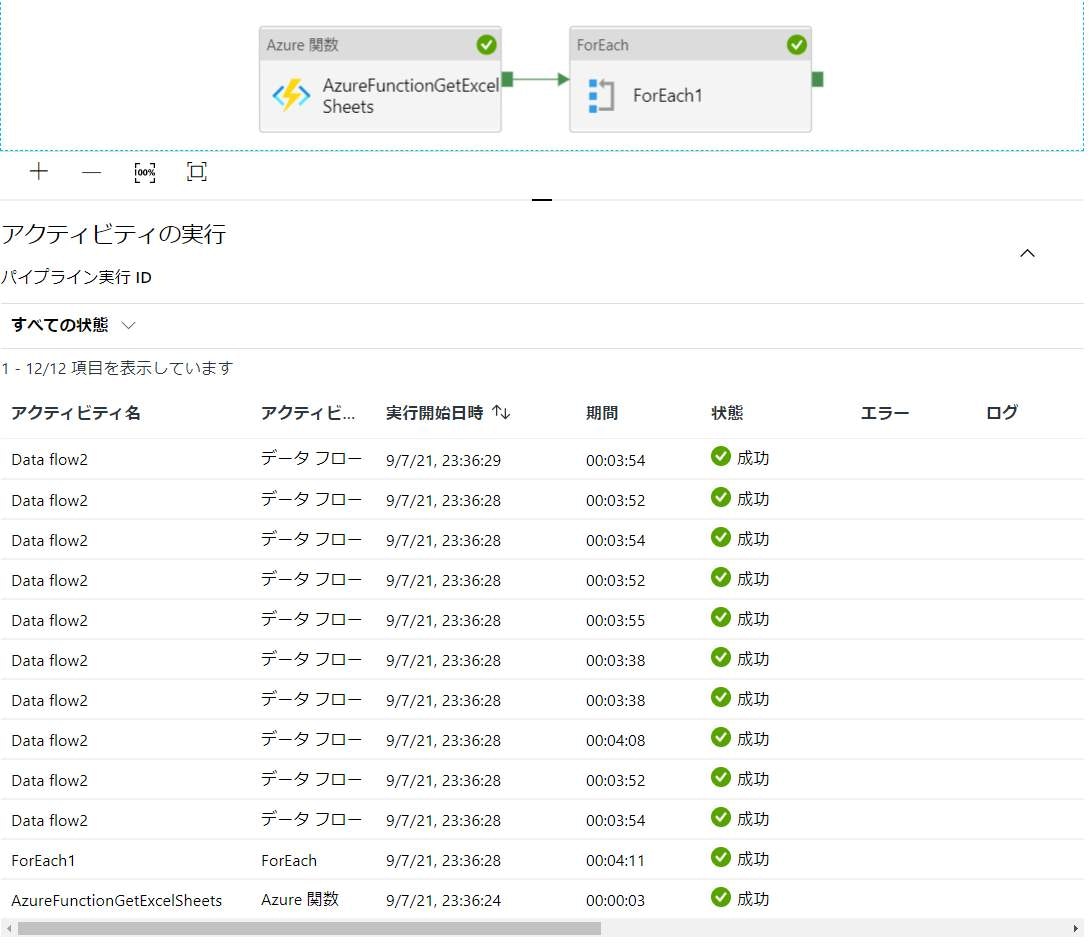
全体構成

Azure 関数アクティビティの設定
アクティビティ名: AzureFunctionGetExcelSheets

ForEachアクティビティの設定

項目の部分に下記記載をします。
Azure 関数アクティビティAzureFunctionGetExcelSheetsの出力結果のうち、Response (本文)部分を取得し、カンマ(,)でsplitしたものが配列としてForEachに入力されるイメージです。
これにより各シート名がForEach内のDataFlowへ受け渡されます。
@split(activity('AzureFunctionGetExcelSheets').output.Response,',')
Data Flowの設定
ForEachで繰り返し処理を行うData Flowには、シート名のパラメーターを設定します。
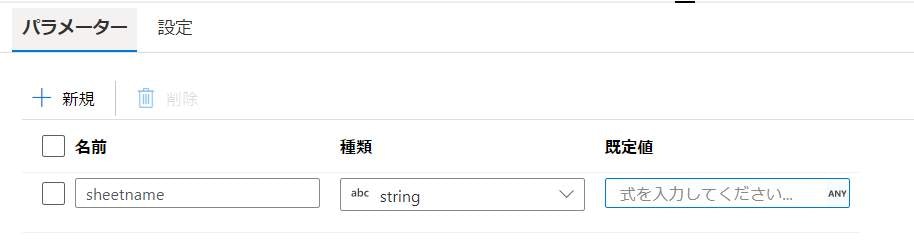
データセット設定
Data Flowのソースとなっているデータセットについて、シート名に@dataset().sheetnameと記載します。

※リンクサービス名、ファイルパス等は白塗りしております。
パラメーター欄にもsheetnameを追加します。
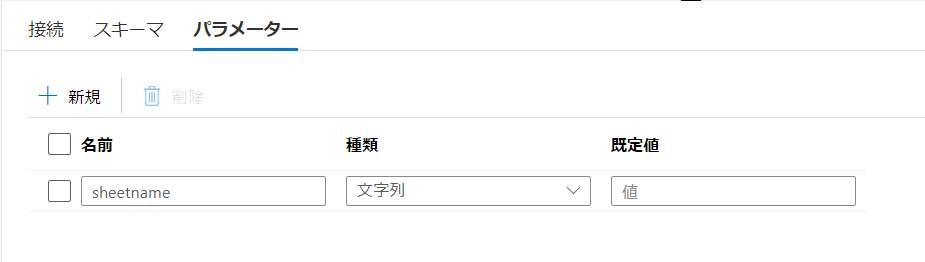
Pipeline側の設定 (ForEachアクティビティの設定②)
データセット側にパラメーターの設定を行うことで、PipelineのForEachアクティビティ内・Data Flow項目にてパラメーターの設定ができるようになります。
ForEach1アクティビティ項目をダブルクリックすることで、ForEach内の構成を作成できるようになります。
繰り返し処理の対象となるData Flowを指定し、source1パラメーターの値に@item()と記述します。ForEachに受け渡されたリスト内の各1項目がこの@item()に入ってくるイメージです。
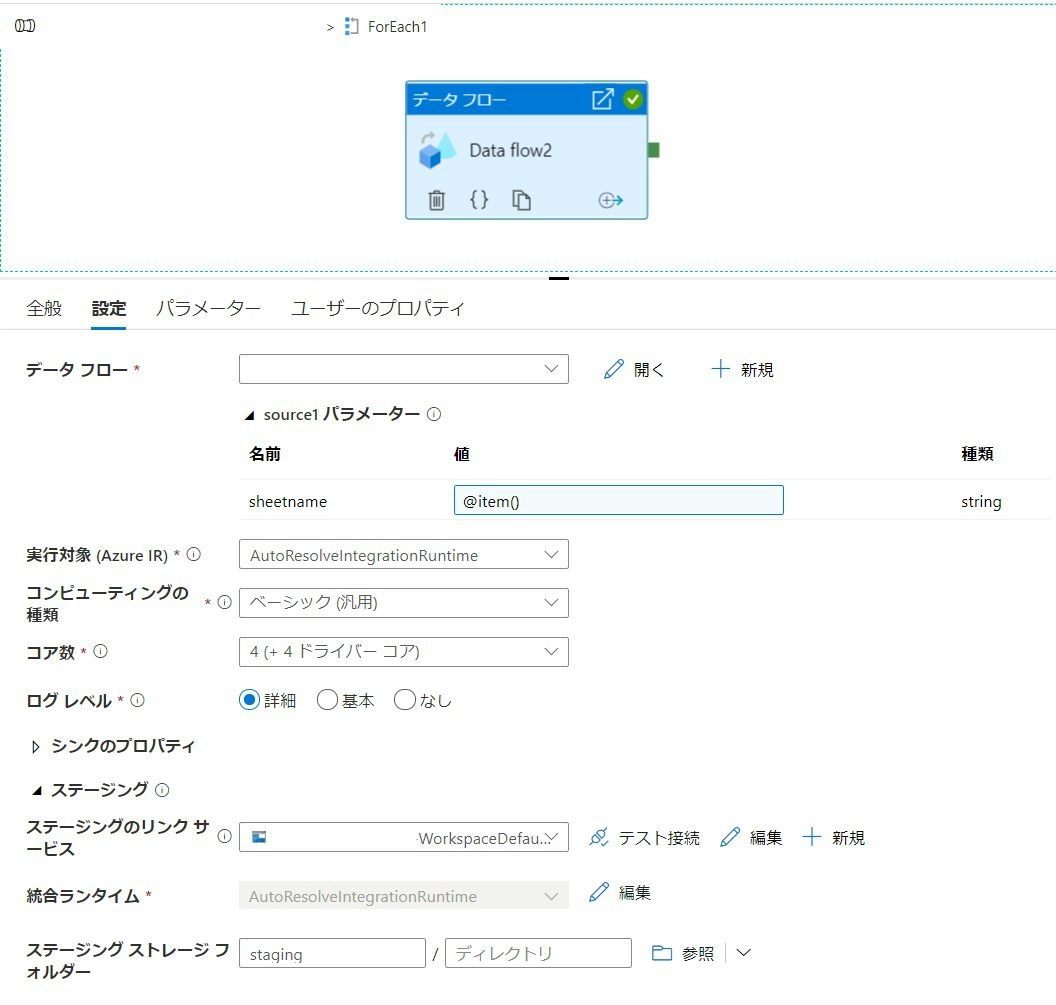
パラメーターパネルの方にもデータフローパラメーターの値として@item()と記載します。

おわりに
無事にFunctions→DataFlowの繰り返し処理のパイプラインが作成できました。
ForEach内の各Dataflowは並列に処理されているのでシート数が増えてもそこまで時間はかからないようです。
勉強しながら検証を行ったため、不要・重複した設定等あるかもしれません。もしご不明点、アドバイス等ございましたらコメントお願いいたします。