はじめに
今作っているポートフォリオは、スマホでパンケーキの焼き加減を画像判定させてひっくり返すタイミングを教えてくれるアプリです。美味しいパンケーキが山ほど食べたいので作りたくなっちゃいましたね、しょうがないですね。
そんなポートフォリオを作成する中でAPIのTeachableMachineについて調べる事になったので、その中で分かった事について共有します。 ( ゚д゚)
同じようなアプリを作りたい人に少しでも手助けになると恐縮です。
また、説明の中で間違っているところがあるかもしれないのでそこは暖かい目でよしなにお願いします。。。
この記事の読み方
まあまあな長文になってしまいました・・・ ので
1、TeachableMachineをとにかく触って遊んでみたい人→『TeachableMachineの使い方』まで
2、TeachableMachineの内容を理解したい人→『全体的な流れ』まで ※でもちゃんと説明できてないかもな所はお許しくだせえ
3、似たようなもの作ってみたい人→ 全部 嬉しみ(灬 ˊωˋ 灬)
という感じでお願いします。
TeachableMachineとは
- Googleが提供している機械学習ツールです
- 学習させられるのは画像プロジェクト、音声プロジェクト、ポーズプロジェクトの3つです。
- 学習させた内容のモデルを作成する事ができ、またそれを自身のwebアプリで使用することが出来ます。
TeachableMachineの使い方
使い方はとても簡単で実際触って遊んでみるのが一番早いところではあります。
https://teachablemachine.withgoogle.com/
ざっくり説明をします。٩(ˊωˋ)و
上記リンクから『使ってみる』をクリックするとプロジェクトを選ぶ画面になります。
今回は画像認識をするので画像プロジェクトを選んでみます。
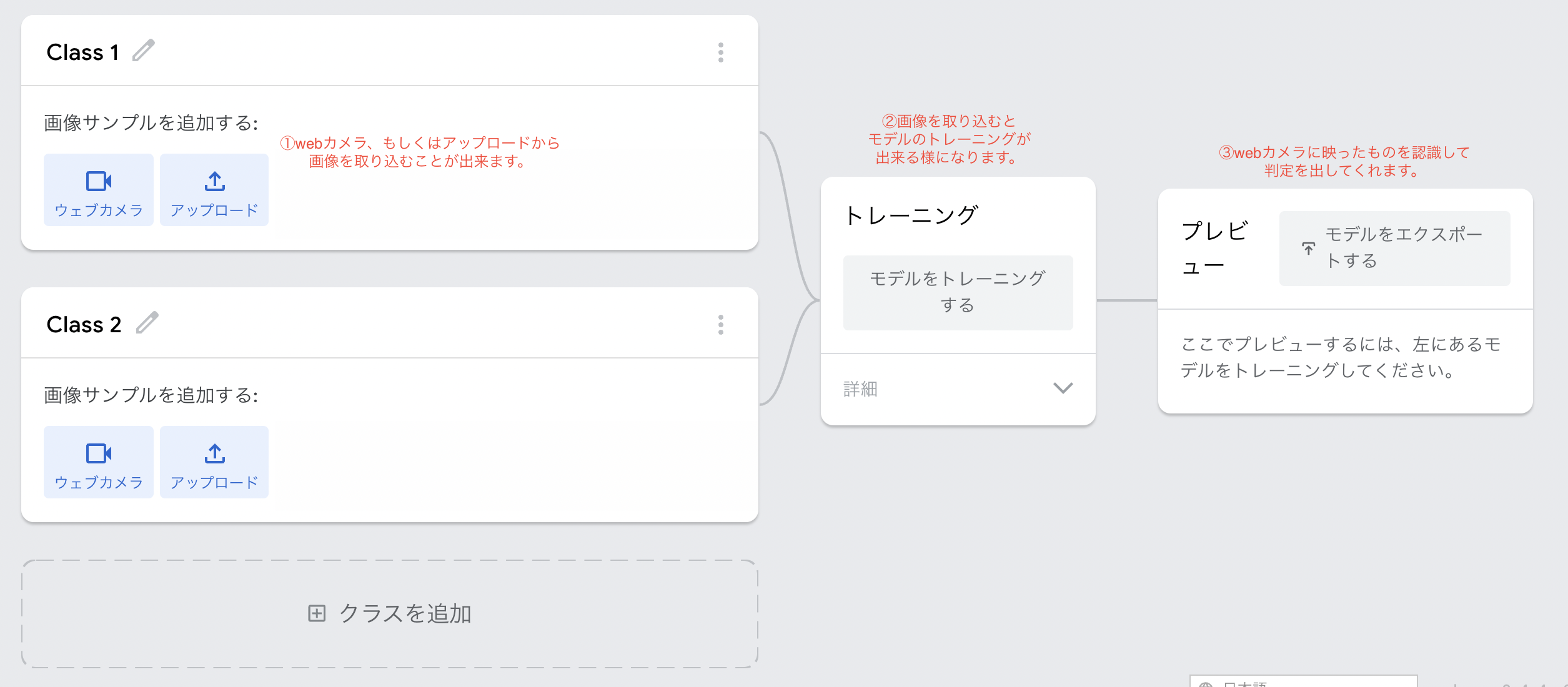
標準の画像を選択すると以下のような画面に遷移します。
①②③の順でやって遊んでみましょう₍₍ ◝(•̀ㅂ•́)◟ ⁾⁾
①ではウェブカメラからの取り込みを選択すると、長押しするだけで連続に読み取るので面白いです。
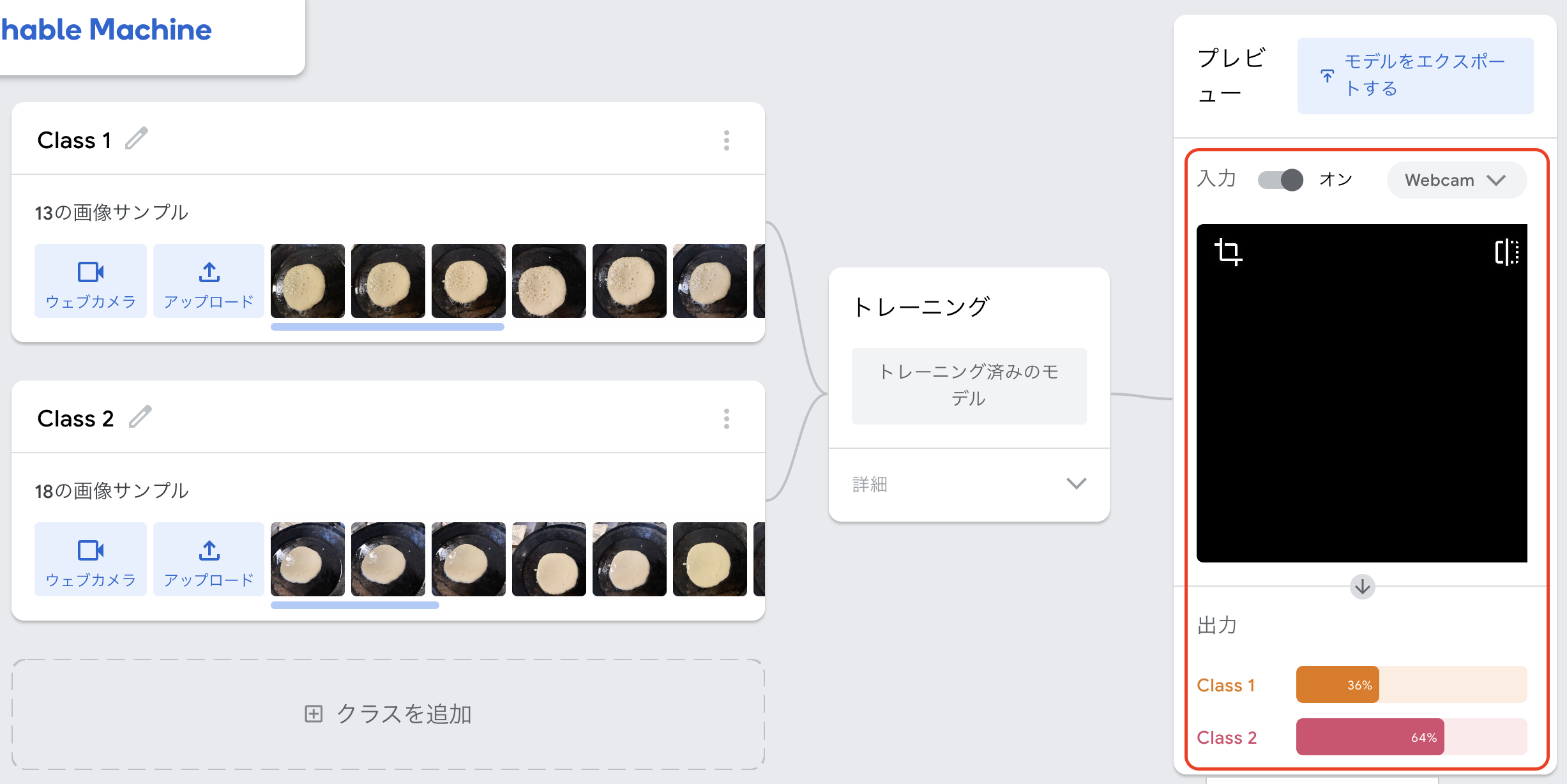
実際にパンケーキを取り込むとこんな感じです。
右の画面には本来はカメラ映像が出ていますが、部屋が映るので今回は消してます ( ゚д゚)
右下に判定内容がパーセント表示されるようになっています。
自分のサイトに取り込む
ここまで出来たら右上の『モデルをエクスポートする』をクリックしてみましょう
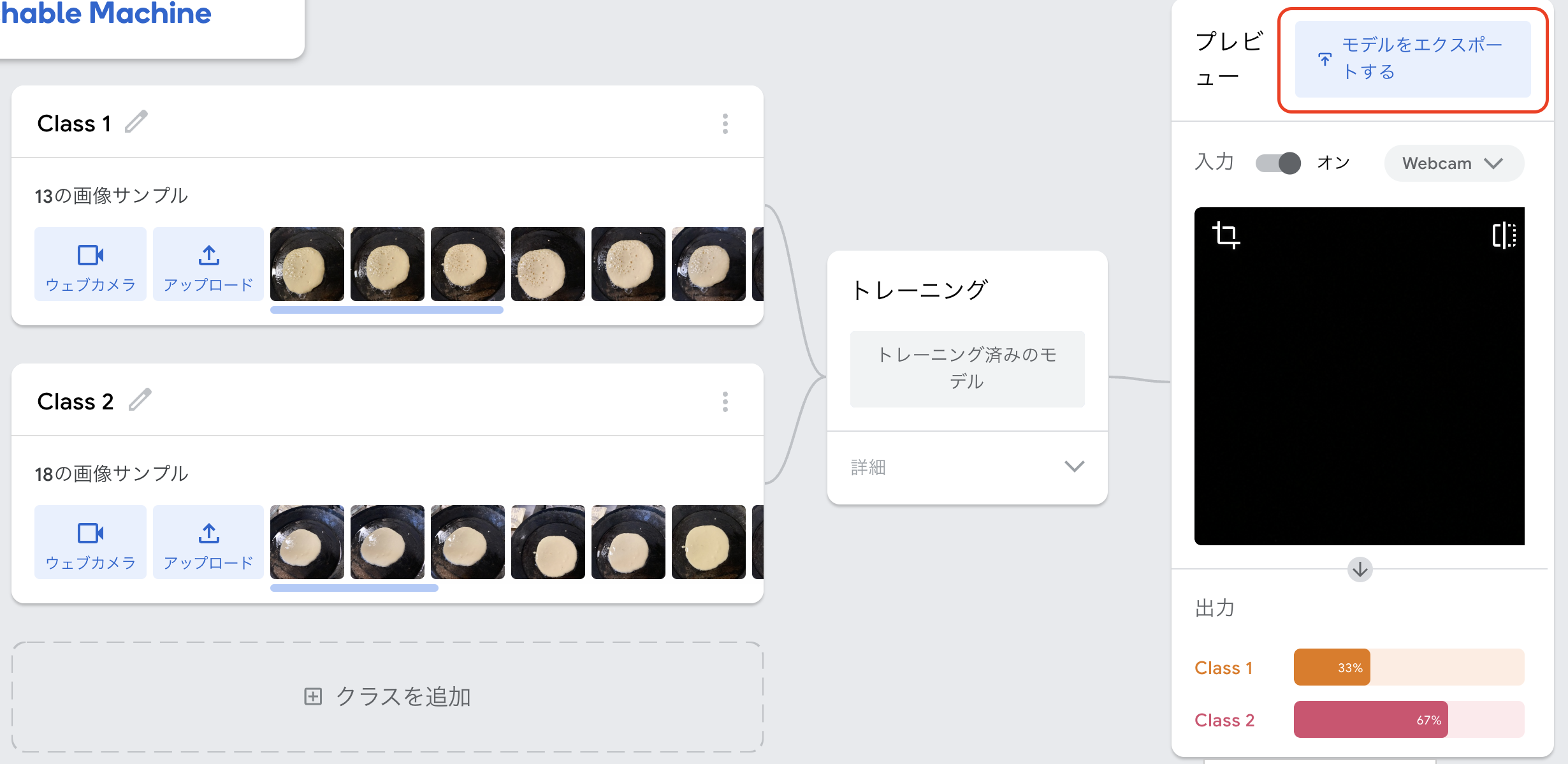
すると・・・
こんなのが出てきます。そしてjavascriptタブにあるコピーをクリックし
自分のサイトに貼り付ければそのまま使用する事も可能です。
このまま使う、であればこれだけで使う事ができてしまいます!なんて簡単なのでしょう。
ただ、現状はなんのこっちゃ分からんけど、とりあえず動いた!ヨシッ!の状態なので
htmlとjavascriptのコードの内容を読み解いてみましょう。
パッと見、コードが多くてうっ╭(°A°`)╮となるかもしれませんが
その多くはコメントアウトの内容が多いです。
なので翻訳してみると『何となくこんなことしてるのかな』程度には分かるかもしれません。
以下はただコメントアウト部分をgoogle翻訳を通しただけのjavascriptのコードになります。
// その他のAPI関数は次のとおりです。
// https://github.com/googlecreativelab/teachablemachine-community/tree/master/libraries/image
// TeachableMachineエクスポートパネルによって提供されるモデルへのリンク
const URL = "https://teachablemachine.withgoogle.com/models/vtT6LMR6V/";
let model, webcam, labelContainer, maxPredictions;
// 画像モデルをロードし、ウェブカメラをセットアップします
async function init() {
const modelURL = URL + "model.json";
const metadataURL = URL + "metadata.json";
// モデルとメタデータをロードする
// ファイルピッカーからのファイルをサポートするには、APIのtmImage.loadFromFiles()を参照してください
// またはローカルハードドライブからのファイル
// 注:ポーズライブラリは、ウィンドウに「tmImage」オブジェクトを追加します(window.tmImage)
model = await tmImage.load(modelURL, metadataURL);
maxPredictions = model.getTotalClasses();
// ウェブカメラをセットアップするための便利な機能
const flip = true; // ウェブカメラを反転するかどうか
webcam = new tmImage.Webcam(200, 200, flip); // 幅、高さ、フリップ
await webcam.setup(); // ウェブカメラへのアクセスをリクエストする
await webcam.play();
window.requestAnimationFrame(loop);
// DOMに要素を追加します
document.getElementById("webcam-container").appendChild(webcam.canvas);
labelContainer = document.getElementById("label-container");
for (let i = 0; i < maxPredictions; i++) { // and class labels
labelContainer.appendChild(document.createElement("div"));
}
}
async function loop() {
webcam.update(); // ウェブカメラフレームを更新する
await predict();
window.requestAnimationFrame(loop);
}
// 画像モデルを介してウェブカメラ画像を実行します
async function predict() {
// 予測は、画像、ビデオ、またはキャンバスのhtml要素を取り込むことができます
const prediction = await model.predict(webcam.canvas);
for (let i = 0; i < maxPredictions; i++) {
const classPrediction =
prediction[i].className + ": " + prediction[i].probability.toFixed(2);
labelContainer.childNodes[i].innerHTML = classPrediction;
}
}
そして以下がhtmlの内容
<div>Teachable Machine Image Model</div>
<button type="button" onclick="init()">Start</button>
<div id="webcam-container"></div>
<div id="label-container"></div>
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@1.3.1/dist/tf.min.js"></script>
<script src="https://cdn.jsdelivr.net/npm/@teachablemachine/image@0.8/dist/teachablemachine-image.min.js"></script>
全体的な流れ
大まかな流れは
1, htmlにあるbuttonをクリックするとinit()が作動する、これがトリガー
2, TeachableMachineのモデル取得とウェブカメラの設定と起動を行う
3, 2の情報を元に判定を繰り返して出力
という感じです。
細かく見ていきます。
まずhtmlにあるbuttonをクリックするとinit()が作動します。
<button type="button" onclick="init()">Start</button>
initが作動すると以下のような動きをしているようです。
・ TeachableMachineで作成したモデルを変数のmodelに入れる
model = await tmImage.load(modelURL, metadataURL);
・ TeachableMachineではClass1、Class2というようにクラス毎に画像読み込みをしていましたが
そのクラスを変数のmaxpredictionsに入れる、それぞれのクラスは配列として入る
maxPredictions = model.getTotalClasses();
・ webカメラの設定を決める
・ window.requestAnimationFrame(loop);でループ処理をスタートさせる
async function init() {
const modelURL = URL + "model.json";
const metadataURL = URL + "metadata.json";
// モデルとメタデータをロードする
// ファイルピッカーからのファイルをサポートするには、APIのtmImage.loadFromFiles()を参照してください
// またはローカルハードドライブからのファイル
// 注:ポーズライブラリは、ウィンドウに「tmImage」オブジェクトを追加します(window.tmImage)
model = await tmImage.load(modelURL, metadataURL);
maxPredictions = model.getTotalClasses();
// ウェブカメラをセットアップするための便利な機能
const flip = true; // ウェブカメラを反転するかどうか
webcam = new tmImage.Webcam(200, 200, flip); // 幅、高さ、フリップ
await webcam.setup(); // ウェブカメラへのアクセスをリクエストする
await webcam.play();
window.requestAnimationFrame(loop);
// DOMに要素を追加します
document.getElementById("webcam-container").appendChild(webcam.canvas);
labelContainer = document.getElementById("label-container");
for (let i = 0; i < maxPredictions; i++) { // and class labels
labelContainer.appendChild(document.createElement("div"));
}
ループ処理では以下のような流れで判定処理をし続けるようです。
・ model.predictの引数に(webcam.canvas)を入れる事で画像の判定結果をpredictionに格納
const prediction = await model.predict(webcam.canvas);
・for文でクラスの数だけクラス名と判定数値の要素を生成する。
例)今回TeachableMachineで作成したクラスは2つなので
<div>Class :2 判定数値</div>```の二つの要素が作成される事になります。
async function loop() {
webcam.update(); // ウェブカメラフレームを更新する
await predict();
window.requestAnimationFrame(loop);
}
// 画像モデルを介してウェブカメラ画像を実行します
async function predict() {
// 予測は、画像、ビデオ、またはキャンバスのhtml要素を取り込むことができます
const prediction = await model.predict(webcam.canvas);
for (let i = 0; i < maxPredictions; i++) {
const classPrediction =
prediction[i].className + ": " + prediction[i].probability.toFixed(2);
labelContainer.childNodes[i].innerHTML = classPrediction;
}
}
と、ここまでがTeachableMachineの何となくの流れです。
javascriptのコードで分からない所がちらほらあるかもしれませんが
その辺はググれば大体出てきます。
## 作りたいアプリに仕様を修正する
ポートフォリオで作成したいアプリが実現できるよう修正していきたいと思います。
今回やりたいことはざっくり3つです。
1, パンケーキを焼く時の表面のつぶつぶを画像認識させてひっくり返すタイミングを表示する
2, スマホのカメラを使うことを想定する為、フロントカメラではなくリアカメラで認識させる
3, 出力させる表現は『まだまだ、もう少し、今だ』の3つにしたい
1はとりあえず骨組みができたので2をやってみたいと思います。
### Videoタグにリアカメラの映像を出力する
スマホのカメラ出力のやり方について調べた所、多くの記事で
videoタグに出力する方法が載っていたので今回はそのやり方を取り入れる事にしました。
まずはhtmlにvideoタグを追加します。
次にjavascriptにカメラの設定を以下に変更します。
let medias;
//カメラの設定をmediasに格納、※environmentでリアカメラを設定
medias = {
audio: false,
video: {
facingMode: {
exact: "environment"
}
}
};
//DOMに要素追加
//カメラ映像を出すvideoタグを取得する
const video = document.getElementById("video");
//設定したカメラのセッティングで起動する変数promiseを設定
const promise = navigator.mediaDevices.getUserMedia(medias);
//カメラの起動許可を確認
promise.then(successCallback)
.catch(errorCallback);
//許可が取れるとコールバックしてvideoタグにカメラ映像を写す
function successCallback(stream) {
video.srcObject = stream;
};
//取れない場合はエラーメッセージを出す
function errorCallback(err) {
alert(err);
};
これでカメラの設定が自動的にリアカメラで取得できるようになりました。
そして、videoタグの内容をTeachableMachineで判定させるために
cancvasに動画を切り出した画像を入れる必要があります。
以下のようにしました。
var canvas =document.getElementById("canvas")
canvas.getContext("2d").drawImage(video, 0, 0, 200, 200)
getContextに"2d"の引数をわたす事で2Dグラフィックのオブジェクトを返すことが出来ます。
### 出力させる表現を『まだまだ、もう少し、今だ』の3つにする
出力する内容を変える方法については色々やり方があるかと思いますが、今回は以下のようにしました。
また、判定の出力に関して、デフォルトではfor文を使用してクラスの数だけ処理をしていましたが
今回はクラスの数に限らず3つの表現を出すだけなのでシンプルにしています。
あらかじめhtml内に```label-container```というidの要素を作成しておき
```labelContainer = document.getElementById("label-container")```
で要素を取得し、判定結果によってテキストを変更している、という感じです。
//予測は、画像、ビデオ、またはキャンバスのhtml要素を取り込むことができます
const prediction = await model.predict(canvas);
//predictionの数値によって結果を変える
if ( prediction[0].probability.toFixed(2)> 0.0) {
labelContainer.innerHTML = "まだまだ";
}
if ( prediction[0].probability.toFixed(2)> 0.1) {
labelContainer.innerHTML = "もう少し";
}
if ( prediction[0].probability.toFixed(2)> 0.2) {
labelContainer.innerHTML = "今だ";
}
### 全体のコード
なお、以下のコードではvideoタグとcanvasタグの両方のカメラの映像が見えるようになってしまっていますが、CSSでvideoの下にcanvasを配置して見えなくなるようにすれば見栄え問題なくなります。
以上!!TeachableMachineについて調べて分かったことでした。
面白いなと思ったら是非使ってみてください!!
お読み頂きありがとうございました٩(ˊᗜˋ)و