はじめに
音声認識の勉強の傍、Kerasを使ってGTZANの音声データの分類を行なったので、その備忘録としてここに手法を残しておきます。
学習モデルはニューラルネットワーク(以下、NN)で、以下の特徴量を使って学習させました(これらの特徴量は、全てlibrosaで簡単に音声データから取得することができます)。
- メル周波数ケプストラム係数(MFCC):音高知覚の特徴
- スペクトル重心:音の重心
- ゼロクロッシングレート:周波数0をまたぐ割合
- クロマ周波数:オクターブ音(これが近いと似ているような音になる)
- スペクトルロールオフ:スペクトル分布の全帯域の 85% を占める周波数のこと
ざっくりしか説明していないので、もっと詳しく個別の項目について知りたい方は調べてください。
GTZANの音声認識は、比較的簡単なので、自分のように音声認識入門レベルの方にはおすすめです。
今回の手法による最終的な音声分類の正答率は「0.66」でしたが、工夫すればもっと精度を高くすることはできると思うのでぜひ色々な手法を試してください!
GTZANとは
GTZAN(公式)は10ジャンルについて各100曲(30秒)、合計1000曲のデータが収録されているデータセットになります。
音声ファイルの形式は全てWAV形式です(MP3は、人の耳には聞こえない周波数をカットして音楽データを削減、圧縮しているため機械学習はWAVファイルの方が適しているそうです)。
10ジャンルの内訳は以下のようになっています。
- ブルース
- クラシック
- カントリー
- ディスコ
- ヒップホップ
- ジャズ
- レゲエ
- ロック
- メタル
- ポップ
データの取得
まずは、こちらからデータをダウンロードして、カレントディレクトリに設置してください(1.1GBほどです)。
今後の作業を進めていく上で、直接ジャンルフォルダをいじれたほうが良いので、genresフォルダから各ジャンルフォルダを取り出して置いてください(以下のような階層イメージ)。
folder-----プログラムを書くPythonファイル
|
|----bluesフォルダ
|
|----classicalフォルダ
|
データの観察
データのダウンロードが終わったら試しに、どのようなデータが入っているのか確認してみます。
%matplotlib inline
import matplotlib.pyplot as plt
import librosa.display
import librosa
audio_path = 'genres/blues/blues.00000.au' #音声を指定
x , sr = librosa.load(audio_path) #音声をロード
plt.figure(figsize=(14, 5))
librosa.display.waveplot(x, sr=sr) #視覚化
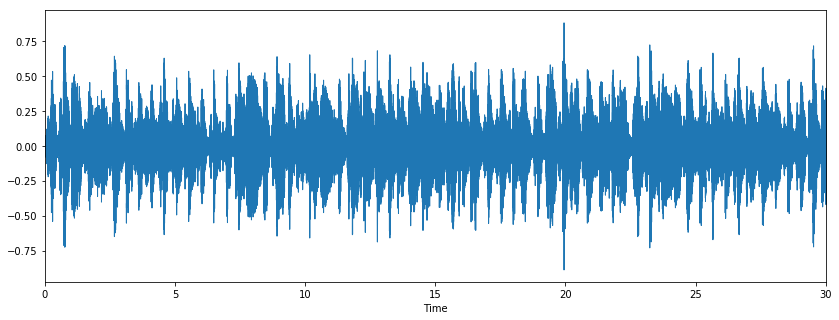
実際に音声を聞くこともできます。
import IPython.display as ipd
ipd.Audio(audio_path)
前処理
スペクトグラムに変換
現在のデータだと、「時間」と「周波数」の2次元のデータですが、スペクトラムに変換することで「時間」「周波数」「信号成分の強さ」といった3次元のデータとして音声を表すことができます。
例えば、先ほどのblues.00000.auをスペクトラムとして表すと以下のようになります。
X = librosa.stft(x)
Xdb = librosa.amplitude_to_db(abs(X)) #スペクトラムに変換
plt.figure(figsize=(14,5))
librosa.display.specshow(Xdb,sr=sr,x_axis='time',y_axis='hz')
plt.colorbar()
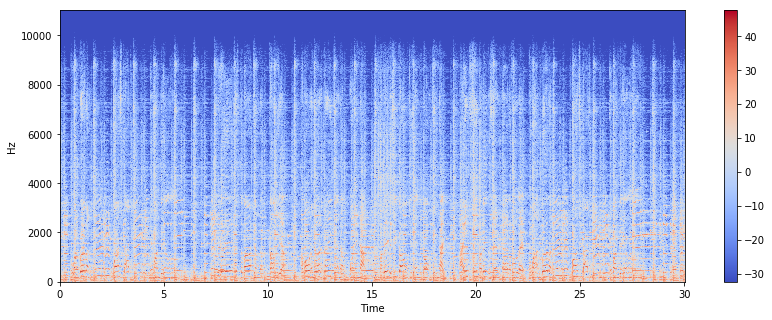
今回は、librosaを使って全ての音声データをスペクトグラム化し、様々な特徴量を抽出していきます(実際のところ、librosaにはあらかじめ様々なメソッドが用意されているので、そこまでスペクトグラムにデータを変換しているという意識はしなくて良いが)。
ラベル付けしてCSVとして出力
そうしたら、早速、全音声データから必要な特徴量を抽出し、CSV化していきましょう。
# ラベル付けしてCSVとして出力
# ヘッダーの定義
header = 'filename chroma_stft rmse spectral_centroid spectral_bandwidth rolloff zero_crossing_rate'
for i in range(1, 21):
header += f' mfcc{i}'
header += ' label'
header = header.split()
# data.csvを作成し、ヘッダーの追加
file = open('data.csv', 'w', newline='')
with file:
writer = csv.writer(file)
writer.writerow(header)
genres = 'blues classical country disco hiphop jazz metal pop reggae rock'.split()
for g in genres:
count = 0
print((os.listdir(f'{g}')))
#各音声ファイルからlibrosaを使って、特徴量を抽出
for filename in os.listdir(f'{g}'):
#if '_' in filename:
#filename = filename.split('_')[1]
songname = f'{g}/{filename}'
y, sr = librosa.load(songname, mono=True, duration=30)
chroma_stft = librosa.feature.chroma_stft(y=y, sr=sr)
spec_cent = librosa.feature.spectral_centroid(y=y, sr=sr)
spec_bw = librosa.feature.spectral_bandwidth(y=y, sr=sr)
rolloff = librosa.feature.spectral_rolloff(y=y, sr=sr)
zcr = librosa.feature.zero_crossing_rate(y)
mfcc = librosa.feature.mfcc(y=y, sr=sr)
rmse = librosa.feature.rmse(y=y)
to_append = f'{filename} {np.mean(chroma_stft)} {np.mean(rmse)} {np.mean(spec_cent)} {np.mean(spec_bw)} {np.mean(rolloff)} {np.mean(zcr)}'
for e in mfcc:
to_append += f' {np.mean(e)}'
to_append += f' {g}'
file = open('data.csv', 'a', newline='')
with file:
writer = csv.writer(file)
#各特徴量び値を追加
writer.writerow(to_append.split())
count+=1
この作業にはかなり時間がかかります。
終わったら、正しくcsvファイルができているか確認しましょう。
data = pd.read_csv('data.csv')
data.head(5)
ファイル名のカラムを消す
学習にファイル名はいらないので、csvから消します。
data = data.drop(['filename'],axis=1)
yの設定(ラベルの重複を削除し、数値化)
csvの一番右にlabelの値が入っているはずなので、そこを抽出し、数値化します。
# labelを抽出
genre_list = data.iloc[:, -1]
# labelの値を数値化
encoder = LabelEncoder()
y = encoder.fit_transform(genre_list)
特徴量の標準化
標準化をし、特徴量の重さ(weight)に偏りのないようにします。
# 特徴量の標準化
scaler = StandardScaler()
X = scaler.fit_transform(np.array(data.iloc[:, :-1], dtype = float))
分割
今回は全体の20%をテスト用のデータとして使います(train:800, test:200)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
print(len(y_train))
print(len(y_test))
モデルの定義
relu関数を活性化関数に使用した簡単なNNのモデルを作ります。(この場合5層ってこと?)
# 分類器の作成
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Dense(512, activation='relu', input_shape=(X_train.shape[1],)))
model.add(layers.Dense(256, activation='relu'))
model.add(layers.Dense(128, activation='relu'))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
学習
学習させます。
epochs数やbatch_sizeは適当です。(もっと最適なものがあると思われる)
# 学習
history = model.fit(X_train,y_train,epochs=30,batch_size=512)
自分の場合は、「loss: 0.4228 - acc: 0.8763」という値が最終的に出ました。
性能の評価
テストデータを
# 評価値
test_loss, test_acc = model.evaluate(X_test,y_test)
print('test_acc: ',test_acc)
学習データの際に、8割以上の正答率を出している一方、テストデータでは正答率が6.6割ほどなので過学習を起こしていることがわかります。
おわりに
今回は、NNで音声データを分類しましたが、別の手法としてCNNモデル(CRNNやResNetなど)で分類するという手法があります。
音声認識は個人的にかなり興味のある分野なので、今後はそちらにも挑戦していきたいです。
(音声生成が本当はしたい)
Twitter(@ahpjop)やっているのでもし個別で聞きたいことなどあればそちらから連絡ください。
それでは!