はじめに
サイゼリヤ1000円カロリー問題が流行っているのを見て、SQLならもっとシンプルに記述できるんじゃないかなぁ(遅いだろうけど)と思い立ち作ってみました。
- サイゼリヤ1000円ガチャをつくってみた(Heroku + Flask + LINEbot
- 「サイゼリヤで1000円あれば最大何kcal摂れるのか」を量子アニーリング計算(Wildqat)で解いてみた。
- 「サイゼリヤで1000円あれば最大何kcal摂れるのか」をSMTソルバー(Z3)で解いてみた。
- 「サイゼリヤで1000円あれば最大何kcal摂れるのか」を整数計画法ソルバー(PuLP)で解いてみた。
- 「サイゼリヤで1000円あれば最大何kcal摂れるのか」をマルコフ連鎖モンテカルロで解いてみた。
- 「サイゼリヤで1000円あれば最大何kcal摂れるのか」をExcel のソルバーでで解いてみた。
- 【Excel】サイゼリヤ1000円で摂れるカロリーの最大値をVLOOKUP関数だけで求める方法
- 「サイゼリヤで1000円あれば最大何kcal摂れるのか」をTeX言語で計算する ~TeX言語で動的計画法(DP)~
- 「サイゼリヤで1000円あれば最大何kcal摂れるのか」をなでしこでDPで解いてみた。
環境
windows subsystem for windowsのUbuntu18.04で実行しました。PCのスペックは下記。
- CPU:Core i7-6700HQ
- Memory:8GB
セットアップ
postgresをインストールして起動。
$ sudo apt install postgresql postgresql-contrib
$ sudo /etc/init.d/postgresql start
テーブル作ってCSVをインポート。CSVは@hodaka0714さんのgitから拝借して「C:\temp」に配置
$ sudo su postgres -c 'psql'
CREATE TABLE menu (
id INTEGER
, name TEXT
, category TEXT
, type TEXT
, price INTEGER
, calorie INTEGER
, salt NUMERIC
, PRIMARY KEY (id)
);
\COPY menu FROM '/mnt/c/temp/menu.csv' CSV HEADER
SQL検討
直積で全パターンの組み合わせ作って不要なレコードをフィルターすれば良いんじゃないか?と思いまず書いたのがコレ。
SELECT a.name
, b.name
, a.price + b.price AS total_price
, a.calorie + b.calorie AS total_calorie
FROM menu AS a
CROSS JOIN menu AS b
WHERE a.price + b.price <= 1000
ORDER BY total_calorie desc
FETCH FIRST 10 ROWS ONLY;
結果はこちら。そうだよね、、、そりゃ重複するよね、、、
name | name | total_price | total_calorie
--------------------------------------+--------------------------------------+-------------+---------------
ラージライス | パルマ風スパゲッティ(Wサイズ) | 989 | 1854
パルマ風スパゲッティ(Wサイズ) | ラージライス | 989 | 1854
ラージライス | キャベツのペペロンチーノ(Wサイズ) | 989 | 1826
キャベツのペペロンチーノ(Wサイズ) | ラージライス | 989 | 1826
アーリオ・オーリオ(Wサイズ) | パルマ風スパゲッティ | 973 | 1820
パルマ風スパゲッティ | アーリオ・オーリオ(Wサイズ) | 973 | 1820
キャベツのペペロンチーノ | アーリオ・オーリオ(Wサイズ) | 973 | 1806
アーリオ・オーリオ(Wサイズ) | キャベツのペペロンチーノ | 973 | 1806
アーリオ・オーリオ(Wサイズ) | セットプチフォッカ付きミラノ風ドリア | 952 | 1769
セットプチフォッカ付きミラノ風ドリア | アーリオ・オーリオ(Wサイズ) | 952 | 1769
重複を排除するなら「a.name!=b.name」を追加すれば良いけど、これだと順番違いが含まれちゃいます。順番違いも含め重複を排除するイディオム的な書き方はこちら。CROSS JOINでWHEREに結合条件を書いても一緒。
SELECT a.name
, b.name
, a.price + b.price AS total_price
, a.calorie + b.calorie AS total_calorie
FROM menu AS a
INNER JOIN menu AS b
ON a.price < b.price
WHERE a.price + b.price <= 1000
ORDER BY total_calorie desc
FETCH FIRST 10 ROWS ONLY;
結合条件「a.price<b.price」の所の意味が一見しただけだと分かり辛いけど、絵にかくと良くわかる(気がする)
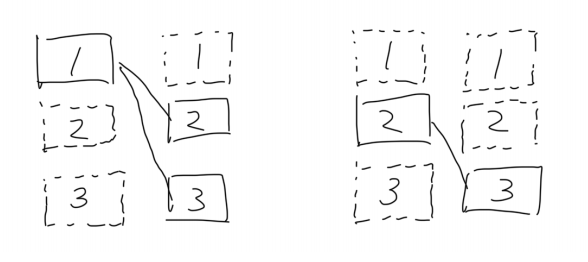
結果はそれっぽくなってきました。
name | name | total_price | total_calorie
--------------------------------------+-----------------------------------+-------------+---------------
ラージライス | パルマ風スパゲッティ(Wサイズ) | 989 | 1854
ラージライス | キャベツのペペロンチーノ(Wサイズ) | 989 | 1826
パルマ風スパゲッティ | アーリオ・オーリオ(Wサイズ) | 973 | 1820
キャベツのペペロンチーノ | アーリオ・オーリオ(Wサイズ) | 973 | 1806
セットプチフォッカ付きミラノ風ドリア | アーリオ・オーリオ(Wサイズ) | 952 | 1769
ポテトのグリル | パルマ風スパゲッティ(Wサイズ) | 969 | 1766
パンチェッタのピザ | アーリオ・オーリオ(Wサイズ) | 973 | 1766
半熟卵のミラノ風ドリア | アーリオ・オーリオ(Wサイズ) | 942 | 1752
ポテトのグリル | キャベツのペペロンチーノ(Wサイズ) | 969 | 1738
野菜ときのこのピザ | アーリオ・オーリオ(Wサイズ) | 973 | 1730
ただ上記だと2品の組み合わせだけなので、1000円以下を満たす複数の品の組み合わせを作る必要があります。
これは簡単で、3品以上も同様の考え方でINNER JOINを増やして行けば良いだけ。
SELECT a.name
, b.name
, a.price + b.price + c.price AS total_price
, a.calorie + b.calorie + c.calorie AS total_calorie
FROM menu AS a
INNER JOIN menu AS b
ON a.price < b.price
INNER JOIN menu AS c
ON b.price < c.price
WHERE a.price + b.price + c.price <= 1000
ORDER BY total_calorie desc
FETCH FIRST 10 ROWS ONLY;
一番安いトッピング半熟卵が69円なので、1000円以下とすると最大でも14品の組み合わせとなるため、上記のSQLを14品のパターンまで作ってunion allで纏めるだけ、、、ってさすがにやってられんわ!
でもそんな時は再帰を使えばOKです。postgresで良かった。
まとめ
最終的にこんな感じになりました。シンプル!とは言い難い、、、
WITH RECURSIVE cource(name_list, pre_id, total_price, total_calorie) AS (
SELECT a.name AS name_list
, a.id AS pre_id
, a.price AS total_price
, a.calorie AS total_calorie
FROM menu a
WHERE a.price <= 1000
UNION ALL
SELECT a.name_list ||','|| b.name AS name_list --カンマ区切りで商品名を保持
, b.id AS pre_id --次回の結合用に前回のidを保存
, a.total_price + b.price AS total_price
, a.total_calorie + b.calorie AS total_calorie
FROM cource a
INNER JOIN menu AS b
ON a.pre_id < b.id
WHERE (a.total_price + b.price) <= 1000
)
SELECT name_list , total_price, total_calorie
FROM cource
ORDER BY total_calorie desc
FETCH FIRST 10 ROWS ONLY;
結果は下記で先人達と同様と思われます。
name_list | total_price | total_calorie
----------------------------------------------------------------------------+-------------+---------------
ポテトのグリル,アーリオ・オーリオ(Wサイズ),ラージライス | 992 | 1940
フォッカチオ,セットプチフォッカ,アーリオ・オーリオ(Wサイズ),ラージライス | 991 | 1895
フォッカチオ,アーリオ・オーリオ,アーリオ・オーリオ(Wサイズ) | 992 | 1894
フォッカチオ,アーリオ・オーリオ(Wサイズ),トッピング半熟卵,ラージライス | 981 | 1878
アーリオ・オーリオ(Wサイズ),ライス,ラージライス | 962 | 1877
フォッカチオ,アーリオ・オーリオ(Wサイズ),ミラノ風ドリア | 992 | 1876
アーリオ・オーリオ,ミラノ風ドリア,ライス,ラージライス | 986 | 1859
パルマ風スパゲッティ(Wサイズ),ラージライス | 989 | 1854
セットプチフォッカ,アーリオ・オーリオ(Wサイズ),ラージライス,スモールライス | 991 | 1832
アーリオ・オーリオ,アーリオ・オーリオ(Wサイズ),スモールライス | 992 | 1831
実行計画はこんな感じ。約100万件の組み合わせをnestloopで作ってフィルターで抽出するという力業。約2分もかかっていて先人達のアルゴリズムの偉大さが良く分かる。
----------------------------------------------------------------------------------------------------------------------------------------------
Limit (cost=22445.22..22445.25 rows=10 width=40) (actual time=11209.001..11209.018 rows=10 loops=1)
CTE cource
-> Recursive Union (cost=0.00..16698.60 rows=138108 width=47) (actual time=0.018..8656.302 rows=1042164 loops=1)
-> Seq Scan on menu a (cost=0.00..3.44 rows=108 width=47) (actual time=0.015..0.077 rows=108 loops=1)
Filter: (price <= 1000)
Rows Removed by Filter: 7
-> Nested Loop (cost=0.14..1393.30 rows=13800 width=44) (actual time=1.371..908.944 rows=130257 loops=8)
-> WorkTable Scan on cource a_1 (cost=0.00..21.60 rows=1080 width=44) (actual time=0.031..95.031 rows=130270 loops=8)
-> Index Scan using menu_pkey on menu b (cost=0.14..1.01 rows=13 width=47) (actual time=0.003..0.004 rows=1 loops=1042164)
Index Cond: (a_1.pre_id < id)
Filter: ((a_1.total_price + price) <= 1000)
Rows Removed by Filter: 18
-> Sort (cost=5746.62..6091.89 rows=138108 width=40) (actual time=11208.999..11209.003 rows=10 loops=1)
Sort Key: cource.total_calorie DESC
Sort Method: top-N heapsort Memory: 27kB
-> CTE Scan on cource (cost=0.00..2762.16 rows=138108 width=40) (actual time=0.019..10605.978 rows=1042164 loops=1)
Planning time: 0.212 ms
Execution time: 11232.940 ms
(18 rows)
ちなみにこの記事は閉店間際のサイゼリヤで飲みながら書きました。
