以前、社内教育の一環として機械学習コンテストを行いました。
機械学習に馴染みのないメンバーもいるため、クラスを未経験者クラス、経験者クラスの二つに分けました。
未経験者クラスのお題は、教師あり学習の基本中の基本であるアヤメの分類です。
アヤメの分類とは、アヤメの4つの特徴量(がく片の長さ、がく片の幅、花びらの長さ、花びらの幅)から、アヤメの品種(Setosa、Versicolour、Virginica)を推定する課題です。
今回は、このアヤメの分類のお題を使って教師あり学習を行います。
教師あり学習
教師あり学習では、データの持つ特徴量と正解の組を入力として学習を行います。
教師あり学習には、分類と回帰の2つがありますが、今回は分類を扱います。
分類を簡単にイメージで説明すると、下図のようなデータを分類する境界線(通常データは2次元以上なので線ではなく超平面)の学習です。
この境界線を学習することにより、新規のデータに対してその分類を推論することができるようになります。
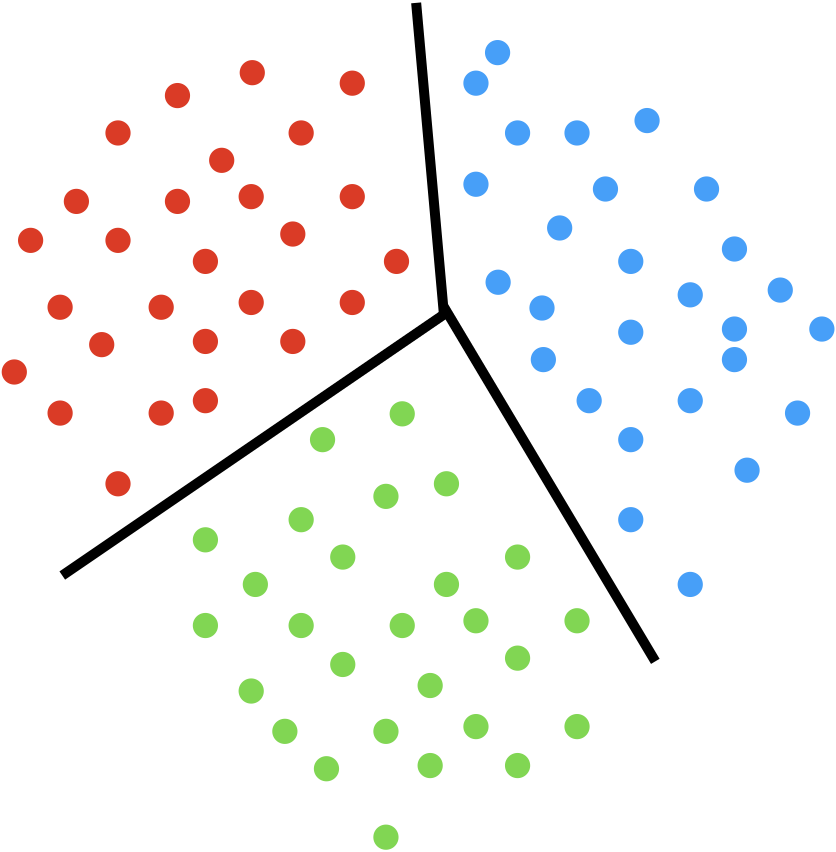
このようなデータの分類を行うアルゴリズムには色々なものがありますが、今回は代表的なものであるサポートベクトルマシン(SVM)を使います。
プログラム
データの作成
まずはじめに、UCI Machine Learning Repositoryから、Iris Data Setをダウンロードします。
ダウンロードしたファイルは、以下のような150行のCSVファイルで、各列が
- がく片の長さ
- がく片の幅
- 花びらの長さ
- 花びらの幅
- 品種
となっています。
5.1,3.5,1.4,0.2,Iris-setosa
4.9,3.0,1.4,0.2,Iris-setosa
...
7.0,3.2,4.7,1.4,Iris-versicolor
6.4,3.2,4.5,1.5,Iris-versicolor
...
6.2,3.4,5.4,2.3,Iris-virginica
5.9,3.0,5.1,1.8,Iris-virginica
このデータから、
- 学習に使う教師データ
- 検証に使うテストデータ
- 検証に使う正解データ
の3つのファイルを生成します。
データの作成は、scikit-learnのtrain_test_splitを使えば簡単にできるのですが、大したプログラムではないので今回は自作しました。
import sys
import csv
import random
import argparse
def main(args):
datas = _read_input(args.input_file)
random.shuffle(datas)
_create_training_data(datas, args.training_data_cnt,
args.training_file, args.test_file, args.answer_file)
def _read_input(path):
datas = []
with open(path, 'r') as f:
reader = csv.reader(f)
for row in reader:
datas.append(row)
return datas
def _create_training_data(datas, train_cnt, path_training, path_test, path_answer):
# 学習データ
with open(path_training, 'w') as f:
writer = csv.writer(f, lineterminator='\n')
for i in range(train_cnt):
writer.writerow(datas[i])
# テストデータ
with open(path_test, 'w') as f:
writer = csv.writer(f, lineterminator='\n')
for i in range(train_cnt, len(datas)):
writer.writerow(datas[i][:-1])
# 正解データ
with open(path_answer, 'w') as f:
writer = csv.writer(f, lineterminator='\n')
for i in range(train_cnt, len(datas)):
writer.writerow(datas[i][-1:])
if __name__ == '__main__':
parser = argparse.ArgumentParser(
description='create data')
parser.add_argument('-i', '--input_file', required=True,
help='input data path')
parser.add_argument('-t', '--training_file', required=True,
help='training data path')
parser.add_argument('-e', '--test_file', required=True,
help='test data path')
parser.add_argument('-a', '--answer_file', required=True,
help='answer data path')
parser.add_argument('-n', '--training_data_cnt', required=True,
type=int,
help='training data count')
args = parser.parse_args()
main(args)
学習と検証
機械学習のためのライブラリは多く存在していますが、今回はその中の一つであるscikit-learnを使います。
使い方は非常に簡単で、学習するときは
clf = svm.SVC(kernel='linear')
clf.fit(x_train, y_train)
推論するときは
pred = clf.predict(x_test)
とするだけです。
実際には様々なパラメーターを指定できますが、今回は簡単な課題なので、ほぼデフォルト値で実行します。パラメーターの詳細はこちらで確認できます。
学習、検証プログラムの全体はこのようになります。
from sklearn import svm
import csv
def main(args):
# 特徴ベクトルと正解ラベル
x_train, y_train = _load_train(args.training_file)
# 線形なSVMによる分類器(ソフトマージンにおける定数はC=1.)
clf = svm.SVC(kernel='linear')
# 訓練データによる学習(超平面の決定)
clf.fit(x_train, y_train)
# テストデータの分類を推論
x_test = _load_test(args.test_file)
pred = clf.predict(x_test)
# 結果を出力
with open(args.result_file, "w") as f:
for x in pred:
f.write("{}\n".format(x))
def _load_train(path):
attrs = []
classes = []
with open(path, 'r') as f:
reader = csv.reader(f)
for row in reader:
attrs.append(row[:-1])
classes += row[-1:]
return attrs, classes
def _load_test(path):
attrs = []
with open(path, "r") as f:
reader = csv.reader(f)
for row in reader:
attrs.append(row)
return attrs
if __name__ == '__main__':
parser = argparse.ArgumentParser(
description='training and test')
parser.add_argument('-t', '--training_file', required=True,
help='training data path')
parser.add_argument('-e', '--test_file', required=True,
help='test data path')
parser.add_argument('-r', '--result_file', required=True,
help='result data path')
args = parser.parse_args()
main(args)
結果
コンテストでは、アルゴリズムの指定は特にしなかったのですが、ほぼ全員がSVMを使って実装をし、簡単なデータセットだったこともあり正解率も100%でした(1名だけk-meansを使って実装していました)。
ちなみに経験者クラスには、被験者のもつ279個の属性(年齢、性別、身長、体重、心電図から得られる様々な特徴)を元に、その人が不整脈(14種類)、不整脈ではない、未分類のいずれかを推定するお題を出しましたが、こちらはデータが複雑なため100%の正解率には至りませんでした。
UCI Machine Learning Repositoryには様々なデータセットがあるので、いろいろと遊んでみるのも面白いかもしれません。