CNN による画像分類を現実のアプリケーションで使う際には、限られた計算資源で推論をする必要があります。
推論を待って処理するような場合は latency が重要になり、バッチ処理でも throughput を最大化したいという要求があります。
各タスクで SoTA を達成しているようなモデルはとても Deep であり、毎回走らせるには大きすぎます。
とはいえ浅いネットワークでは精度に限界もあるので、速度と精度のトレードオフを常に考える必要があります。
計算量を抑えつつ精度を向上するネットワークを設計する、という方向で MobileNet や SqueezeNet などが提案されています。
今回紹介する論文は、ちょっと別のアプローチで計算資源の問題に立ち向かっています。
ひとことでまとめると 分類が十分に簡単だった場合は早期 exit し、難しいケースだけ深く計算する という構造をとります。

(この図の "easy" と書かれている行の画像は省エネで、 "hard" と書かれている行の画像は全力で予測する)
この記事は、Wantedlyの勉強会で取り上げられた論文・技術をまとめたものです。
2018年に読んだ機械学習系論文・技術まとめ at Wantedly Advent Calendar 2018 - Qiita
Reference
- Multi-Scale Dense Networks for Resource Efficient Image Classification
- Gao Huang, Danlu Chen, Tianhong Li, Felix Wu, Laurens van der Maaten, Kilian Q. Weinberger, et al., ICLR 2018 - https://arxiv.org/abs/1703.09844
文中の図表は論文より引用しています。
モチベーション
先にも書きましたが、DNN は計算量の大きなアルゴリズムであり、実際に利用するケースを考えると、その速度や計算効率が気になってきます。
現実の入力画像は様々な難易度のものがあるので、簡単な画像は浅いネットワークで解きたくなりますし、難しい画像は深いネットワークで解きたくなります。
こう表現すると単純そうに見えますが、これを実現するためには「この画像は簡単か(浅いネットワークで解くべきか)、難しいか(深いネットワークで解くべきか)」を決定しなければなりません。
実際に解く前に難易度を推定するのは難しく、事前に 2 つの model を定義しておく方法ではうまくいきません。
Multi-Scale Dense Networks は、ひとつのモデルで逐次的に推論結果を出しつつ、十分に精度が出せそうであれば早期に Exit し、それ以降の計算を省略します。
アーキテクチャ
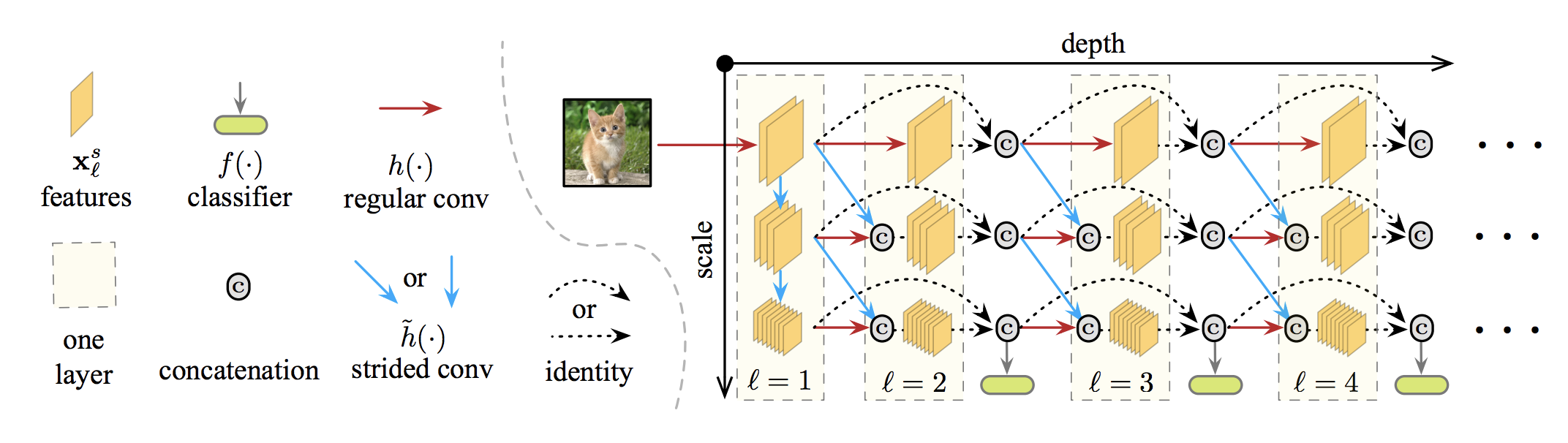
↑がモデルのイメージです。
classifier と書かれた module が複数回出てきているように、それぞれが逐次的な推論結果を出す module になります。
このような構造を単純にとると以下の2点が問題になります。
- 粒度の大きい特徴を捉えづらい
- 浅い層の classifier が深い層の classifier の精度を下げてしまう
粒度の大きい特徴を捉えづらい
典型的な画像分類のネットワークでは、浅い層で細かい粒度の特徴を獲得し、多くの Convolution や Pooling を経たあとの深い層で荒い粒度の特徴を獲得しています。
浅い層で分類をやってしまうと解像度の大きい特徴を獲得することができていないため、エラー率が高くなってしまいます。
次の図は、 ResNet や DenseNet の浅い層に分類器をつけて学習させた場合のエラー率をプロットしています。(損失関数は最終層の分類器の損失と浅い層の分類器の損失の和です。)

横軸は全体の深さに対して「どの深さに分類器をつけるか」を表しています。
浅い層につけた分類器ほどエラー率が高くなっていることがわかります。
receptive field を大きく取った視野の広い特徴を効率的に獲得するためには feature map の解像度を下げる operation (2x2, stride 2 の convolution や pooling など)がよく使われますが、浅いうちにそれらの operation をやってしまうと、細かい粒度の特徴を獲得しづらくなってしまいます。
解決策
Multi-Scale Dense Networks では、複数の解像度の feature map を各深さごとに用意するという解決方法をとっています。
アーキテクチャの全体像の図で縦に 3 種類のスケールの feature map が並んでいます。
各層では、以下の2つの operation の concatenate を分類器につなげます。
- 一つ前の層のもっとも解像度の低い feature map
- 一つ前の層の一段細かい feature map を畳み込んで解像度を荒くしたもの
これによって、細かい粒度の特徴の獲得を維持しつつ、視野の広い特徴を分類器に流すことを可能にしています。
浅い層の classifier が深い層の classifier の精度を下げてしまう

このグラフは ResNet や DenseNet の浅い層に分類器をつけたときの 最終層の分類器の精度 を表したものです。
縦軸は最終層の分類器のみで学習したときの精度の相対精度です。
特に ResNet で顕著ですが、浅い層に分類器をつけてしまうと 最終層の分類器の精度が悪くなる ことがわかります。
浅い層の分類器を最適化するために、細かい粒度の特徴が失われ、深い層にその特徴が伝わらないことが問題になっています。
解決策
Dense connectivity によってこの問題を解決しています。
Dense connectiviy は DenseNet で提案されたもので、あるブロック内の中間層をすべて concatenate するブロックです。
ResNet で提案された Residual Module は、入力とそれを convolution などに通したものを足し合わせるというものでしたが、更にその考えを推し進めたのが DenseNet です。
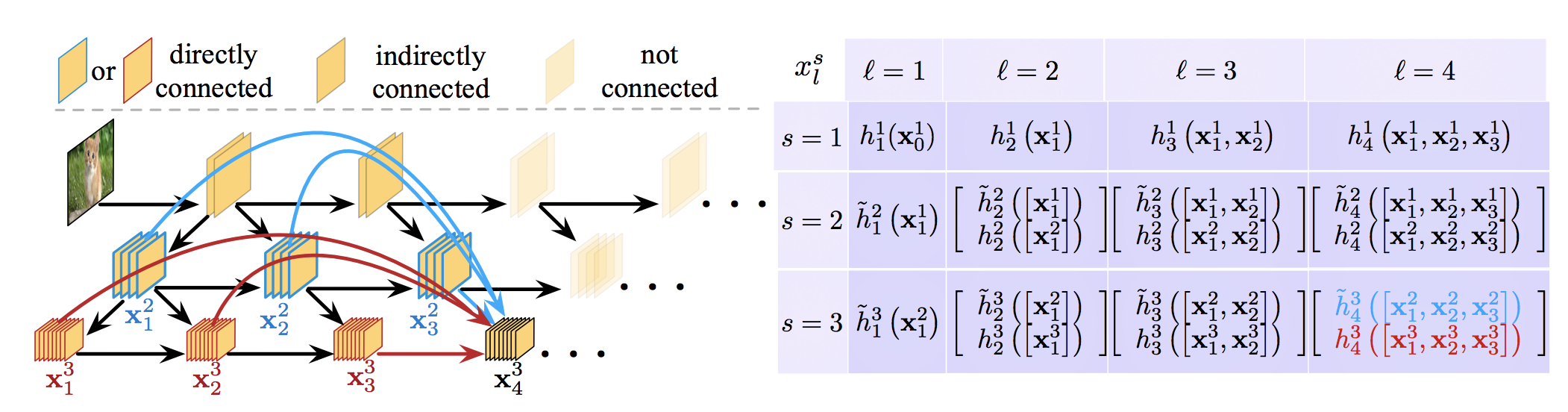
これによって、浅い層の結果がそのまま深い層に直結するため、一度細かい特徴を失っても浅い層の出力で recovery することができます。
まとめと感想
僕らも Wantedly People というスマートフォンのカメラを使ったアプリケーションを提供しているので、モバイル上での推論をしたいというモチベーションがあって読んだ論文でした。
DenseNet の特徴をきれいに活用していて面白い論文だなと思いました。
DenseBlock の有効性をちゃんと検証していてこの論文の提案のいいところがわかりやすいのも好きなところです。