ニュースの推薦に "Knowledge Graph" を活用する論文です。
Microsoft Research Asia のチームが WWW 2018 に投稿しています。
この記事は、Wantedlyの勉強会で取り上げられた論文・技術をまとめたものです。
2018年に読んだ機械学習系論文・技術まとめ at Wantedly Advent Calendar 2018 - Qiita
Reference
- DKN: Deep Knowledge-Aware Network for News Recommendation
- Hongwei Wang, Fuzheng Zhang, Xing Xie and Minyi Guo, et al., WWW 2018
- https://www2018.thewebconf.org/proceedings/#indus-922
文中の図表は論文より引用しています。
概要
一般にニュース中の言葉は、常識的知識を仮定していて凝縮された文章になっています。
一方で推薦系の既存手法は ニュース中に現れない知識を取り扱えておらず、潜在的なニュース間の関係を活かした探索が出来ていないという問題がありました。
この論文は、knowledge graph を活用した content-based な recommendation framework である deep knowledge-aware network (DKN) を提案しています。
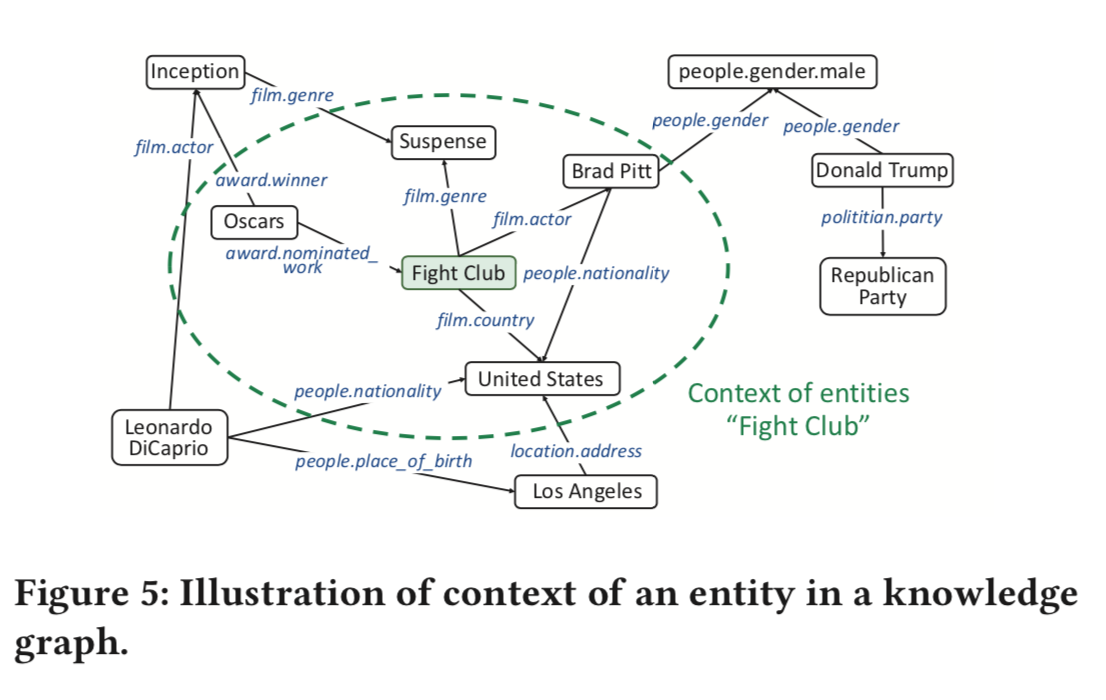
knowledge graph とは、様々なエンティティを様々なエッジでつないだ heterogeneous なグラフで、たとえば "モナリザ -[の作者」-> ダ・ヴィンチ" のような情報を溜め込んだ巨大なグラフです。
Google Search の裏でも活躍しているらしく、一般的な「知識」を構造化された形で表現する方法としてよく使われています。
knowledge graph を使うことで、 "Donald Trump" という単語そのものだけからはわからない、 "United States" という単語との関連、"Politician" という単語との関連などを導くことができます。
何が難しいか
この論文では、ニュース推薦の難しさとして以下のようなものを挙げています。
- news の推薦は movie などと違って、リアルタイム性が高い問題(いつ publish されたニュースかが重要)であり、news 間の関係性もすぐにダメになる。
- なので ID ベースの既存手法(協調フィルタリングなど)は効果が弱い
- news はユーザによって興味範囲が違うし、ユーザは複数の興味範囲を持っていることがほとんど。
- news の文言は凝縮されている。
- 常識、大量の既知の entity を仮定している。
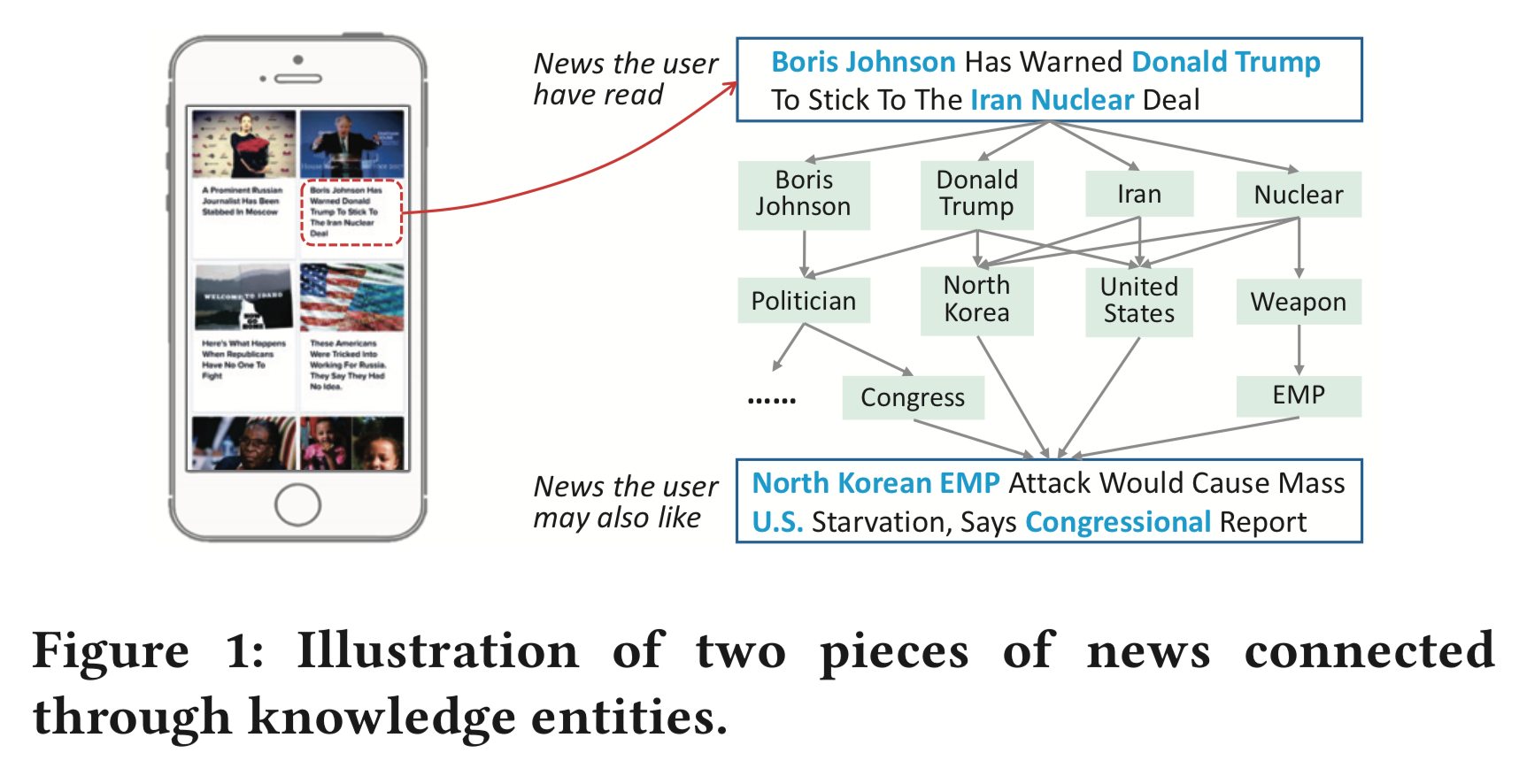
- “Boris Johnson Has Warned Donald Trump To Stick To The Iran Nuclear Deal" というニュースは “Boris Johnson”, “Donald Trump”, “Iran", “Nuclear” を知っている前提で書かれている
- ↑に興味のあるユーザはきっと “North Korean EMP Attack Would Cause Mass U.S. Starvation, Says Congressional Report” にも興味があるが、単語レベルでの関係性はほぼ無い
これらを Knowledge Graph を活用しつつ解決していきます。
Knowledge Graph Embedding
Knowledge Graph Embedding 自体はこの研究の contribution ではありませんが重要なので簡単に紹介します。
Knowledge Graph Embedding は、通常の network embedding に近い問題設定で、 knowledge graph における各エンティティとエッジの低次元な embedding を求めるという問題です。
(head, relation, trail) という triplet 構造をなるべく維持したまま、h, r, t それぞれを低次元空間で表現することが目標です。
DKN は translation-based knowledge graph embedding というのを使っています。
一番簡単な手法は h + r = t になるように embedding を定める手法です。
(他にもいくつか紹介、実験されているけど大体発想は同じなので省略。)
まずランダムな値で各エンティティ、エッジの embedding を初期化し、 h + r = t を満たすように gradient descent で embedding を微調整していきます。
これによって、エンティティやエッジ(=関係性)の低次元なベクトルを得ることができました。
Deep Knowledge-aware Network (DKN)
DKN 自体は
入力: 候補ニュースと、あるユーザの過去に見たニュースたち
出力: クリック率
となるような CTR 予測モデルです。
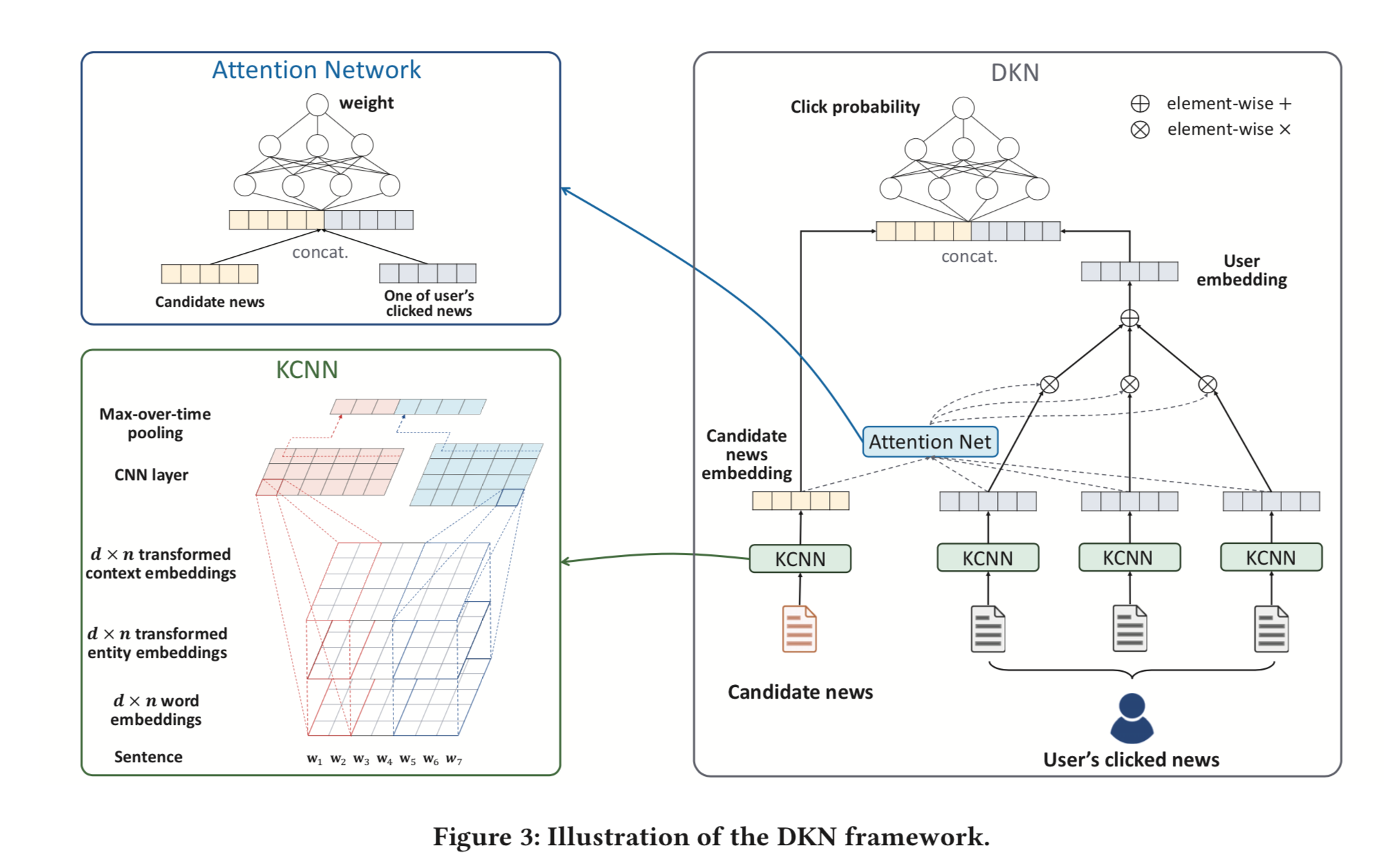
候補となるニュースの特徴量をベクトルとして得るために、通常であれば単語の embedding を RNN や CNN でまとめ上げて固定長のベクトルに変換します。
DKN ではここに Knowledge Graph Embedding によって得た特徴量を加えます。
出現する単語ごとに Knowledge Graph 上のエンティティを探し、もし見つかったならそのエンティティ自体の embedding + 周辺のエンティティ embedding の平均を context vector として単語レベルの embedding に concat します。
もしエンティティが見つからなければ 0 埋めでサイズをあわせます。
Attention-based User Interest Extraction
つぎに、「ユーザが過去に見た記事」という情報をどのように活用するかを考えます。(=ユーザの特徴をどのようにベクトル化するか)
記事ごとのベクトルは↑で求められたので、単純に過去クリックした記事のベクトルの平均値を使うという方法が考えられますが、ユーザの興味は複数にまたがりうるので単純に平均を取るのは適しているとは言えません。
(たとえば「プログラミング」「テニス」「ラーメン」の記事をクリックしたユーザに対して、「プログラミング」系の記事を推薦するのは多分良いはずだけど、平均をとってしまっているとその寄与が薄まる。)
「今推薦の候補に考えている記事」について過去見た記事それぞれがどう関わっているかを表現できる方法でなければならないと言っています。
そこで、 Attention Module をつかっています。
候補の記事と過去に見た記事たちとの間の attention を計算し、過去に見た記事たちのベクトルの重み付き和をとることで、興味分野が複数にまたがっていても候補記事との関連をうまく見出したベクトルが作り出せます。
Attention Module の入力は「候補記事のベクトル」と「過去に見た記事のベクトル」で、出力はその記事の寄与度になります。過去に見たすべての記事に対してそれぞれ network に入れて寄与度を計算し、softmax にかけたうで記事ベクトルの重み付き和をとっています。
感想
ニュースタイトルは単語数が少なく固有名詞も多いので、単純な単語の embedding ではなかなか扱いづらいという問題を抱えていたので、 knowledge graph を使うというのはすごく納得の行く選択だなと思いました。
ただ、結果を見てみると Gain に対して複雑さや Knowledge Graph 自体を用意するコストが見合うかというとやはり厳しいかなという印象があります。(Microsoft はすでに自前の knowledge graph を持っているので...)
Knowledge Graph Embedding については全く知らなかったのですが、面白い問題設定ですね。
色々工夫されているようですが、 h + r = t というわかりやすく単純な方法でもそれなりに上手く行っていて面白かったです。
また、ユーザごとのベクトル表現の作り方の部分は Knowledge Graph の活用部分よりも簡単かつ一般的なので、この部分だけでも応用できそうだなと思いました。