Object Detection は、一枚の画像中の「どこに」「なにが」うつっているかを当てるタスクです。
典型的な手法では、オブジェクトごとの bounding box を予測し、それぞれがどのクラスに分類されるかを個別で予測します。
また、ひとつのオブジェクトに対してすこしずつ座標のずれた box を複数予測してしまう可能性があるという問題があり、1 object 1 box になるように重複を削除しなければなりません。
これには nox maximum supression という方法を使うことが多いですが、これはヒューリスティックに基づく後処理になってしまっています。
この論文では、予測した box 間の関係に着目することで、分類精度を向上し、後処理 0 の完全 End-to-End での物体検出ネットワークを構築しています。

(青い box について分類する際に、オレンジの box との関連が強く活用されている)
この記事は、Wantedlyの勉強会で取り上げられた論文・技術をまとめたものです。
2018年に読んだ機械学習系論文・技術まとめ at Wantedly Advent Calendar 2018 - Qiita
Reference
- Relation Networks for Object Detection
- Han Hu, Jiayuan Gu, Zheng Zhang, Jifeng Dai, Yichen Wei, et al., CVPR 2018
- https://arxiv.org/abs/1711.11575
文中の図表は論文より引用しています。
モチベーション
自然言語処理の世界では、Attention module が非常に強力な武器として大活躍しており、特に Transformer1 以降の SoTA モデルたちは大体 Attention の仕組みを組み込んでいるといっても良いくらいの活躍ぶりです。
そこで、Attention を Object Detection の世界にもってこよう、というのがこの論文です。
Attention module を用いて box 間の関係性を表し、object detection の精度向上を達成しています。
End-to-End
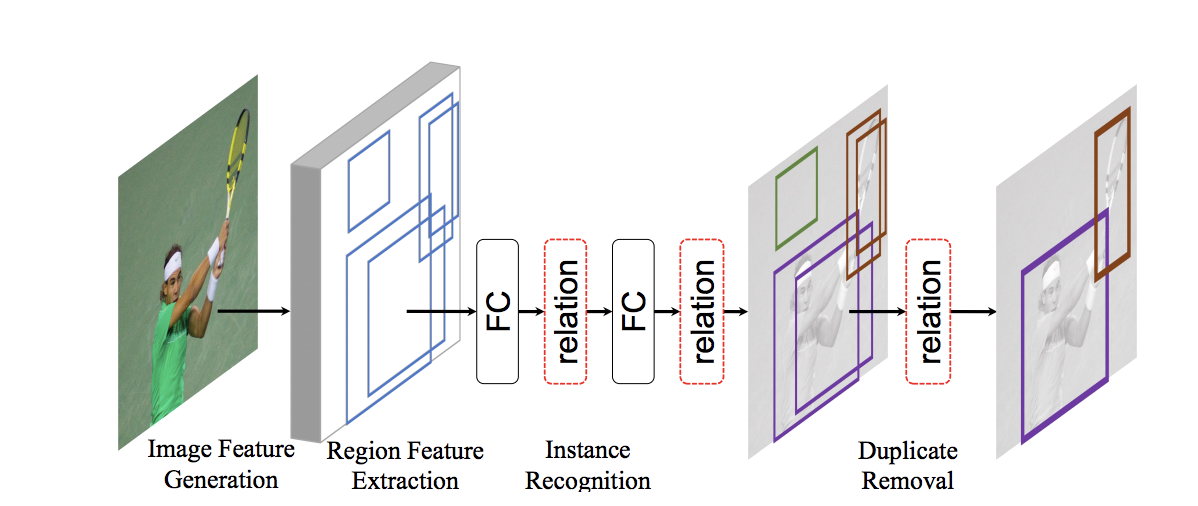
概観でいうと Region Proposal network + RoI Pooling + relation module という構造を採用しています。
relation module は box 間の attention をとる module です。
完全に後処理をなくすためには、大量の box のなかから採用すべき box だけを残す必要があります。(通常は non maximum supression で、スコアの高い box を優先的に残しつつ、重複した領域の大きい box はすてる)
そこでこの論文では、Attention module をいくつか通したのち、box ごとに 0~1 の値を出力し、残すべき box は 1 になり捨てるべき box は 0 になるように学習します。
Object Relation Module
物体間の関係には 2 つの意味があります。1 つは意味的な関連で、もう一つは座標的な関連です。
ボールっぽいものとバットっぽいものがあったとしても、ものすごく離れた場所にあるのであれば無関係かもしれないですが、近くにあればきっとボールとバットのペアと予測するのが正しそうです。
しかし、通常の attention は、意味的な関連しか扱えていません。すべての box をなんらかの vector にしてしまっていますし、convolution や pooling は座標に依存しない操作なのでその vector に座標そのものの情報は埋め込まれません。
そこでこの論文ではふつうの Attention をちょっといじった object relation module というものを提案しています。
物体 m, n 間の attention を算出する式を見てみます。

$\omega_A^{mn}$ は通常の Attention と同じで、object m と n を表すベクトル(を線形変換したもの)の内積です。
$\omega_G$ の部分を無視すれば、この式は単に各 object ごとに内積をとったものを softmax にかけている = ふつうの Attention の計算式と一致します。
$\omega_G$ は、座標的な関係を考慮するためのパラメータです。

$f_G^m$ は object m の座標情報 (x,y, w, h) を表します。
$\varepsilon_G$ はふたつの object の座標情報からそれらの座標的関係を計算する関数です。
\varepsilon(f_G^m, f_G^n) = (\log(\frac{|x_m - x_n|}{w_m}), \log(\frac{|y_m - y_n|}{h_m}), \log(\frac{w_n}{w_m}), \log(\frac{h_n}{h_m}))
さらに、 $max{0, ...}$ をとることで、ReLU 的な働きをし、まったく座標的に関係のない object からの影響を 0 にしています。
まとめと感想
実験と結果はもと論文を読むのが一番くわしいのでそちらを参照ください。
「一枚の画像から X を取得したいが、画像の主体となるような X だけを取りたい」といったケースにも応用できる手法かなと思っていて、実験してみたいと思いつつ、本当に end-to-end でやるのはちょっと大変そうすぎるという印象もあります。
(また論文中には end-to-end が 0 から学習する際の問題にも触れられています。)
とはいえ完全に end-to-end というのはやっぱり夢があって好きです。
-
https://arxiv.org/abs/1706.03762
雑に言えば Attention は、ある entity と他の entity の関係性を 0~1 で出力し、その値をもとに entity を表す何らかのベクトルの加重和をとるといった操作をします。関係性を表す 0~1 を計算するためのパラメータも学習されます。
また画像に対応するタイトルを自動生成する Image Captioning の世界でも Attention は活躍しており、活用されるフィールドがどんどん増してきています。 ↩