はじめに
この記事では、Aerospikeをご理解いただくため、様々な視点でAerospikeのアーキテクチャをご説明します。
クラスター構成
Aerospikeは、複数のサーバにデータを分散させた構成で利用されます。(1サーバでの利用も可能)
以下は5つのサーバで構成されたAerospikeの構成です。
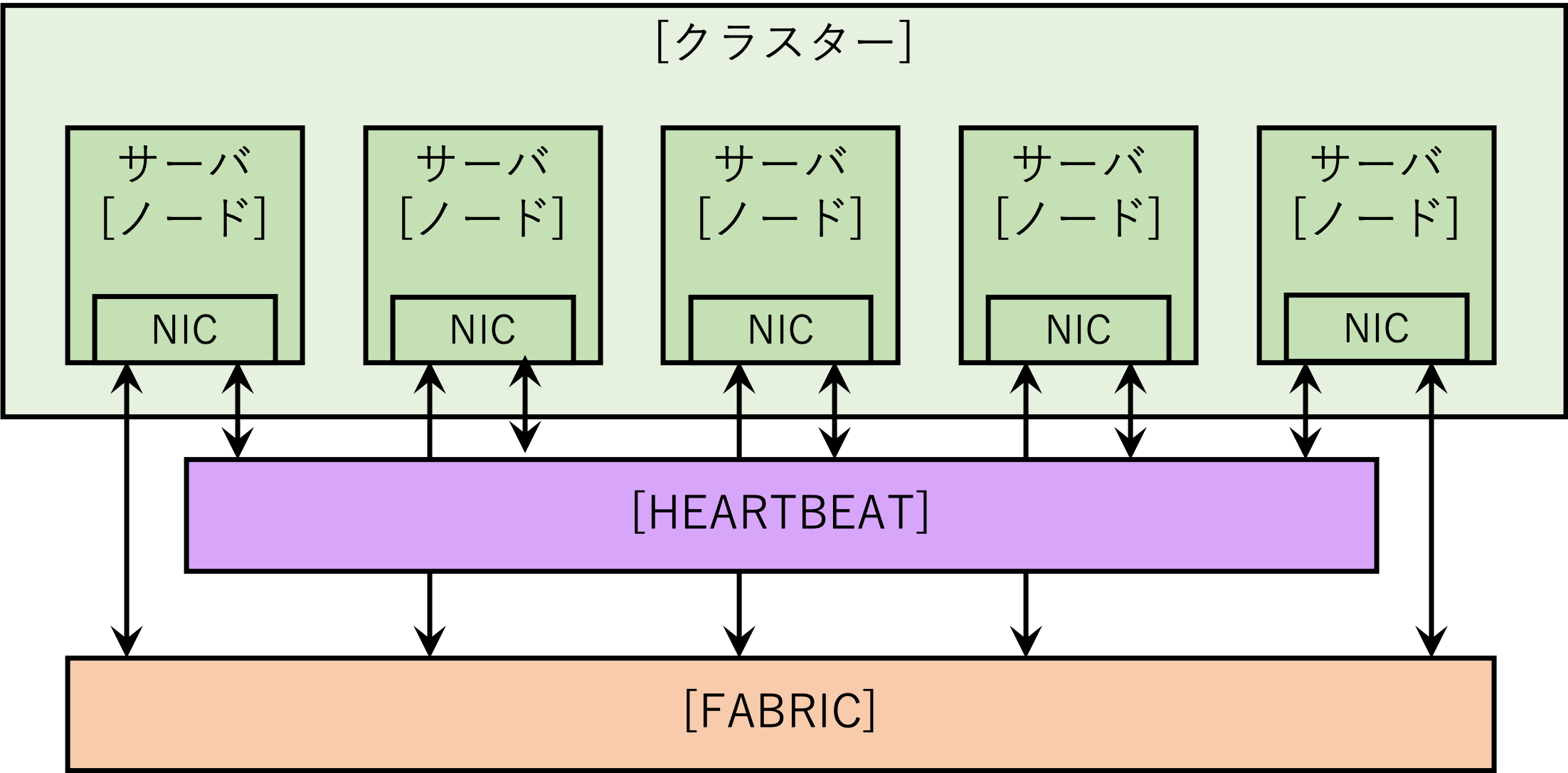
Aerospikeでは、サーバを ノード 、このノードをまとめた分散サーバ全体が クラスター です。
ノード間はネットワークで接続されます。この接続には2種類あります。
まず、ひとつが HEARTBEAT と呼ぶ、ノード間で存在チェックを行うネットワーク接続です。このHEARTBEATは、共通したネットワークアドレスへのマルチキャストか、他のノードのIPアドレスを指定するメッシュかのどちらかを使用します。
もうひとつが FABRIC と呼ぶ、データの送受信を行うネットワーク接続です。このデータの送受信とは、データを多重化(レプリケーション)するための送受信と、1つのノードが停止した場合や増加した場合に、再度データを分散させるための送受信です。
AerospikeはShared Nothing(何も共有しない)となっており、ノードの追加・削除が容易に行なえます。
参考:Aerospike公式サイト:Clustering
クライアントアクセス構成
Aerospikeにアクセスする場合、一般的にはユーザアプリケーション(Webアプリケーション等)から接続します。
Aersopikeでは、Java/C#/C/Go/Python等の言語でAerospikeのクラスターに接続するためのクライアントライブラリ(Aerospike Clinet Library)を提供しています。
参考:Aerospike公式サイト:Overview of Client Libraries
このクラスライブラリが提供するメソッド等を利用することで、Aerospikeのクラスターにアクセスできます。
以下は、このAerospikeのクラスターにアクセスする場合の、基本的な構成です。
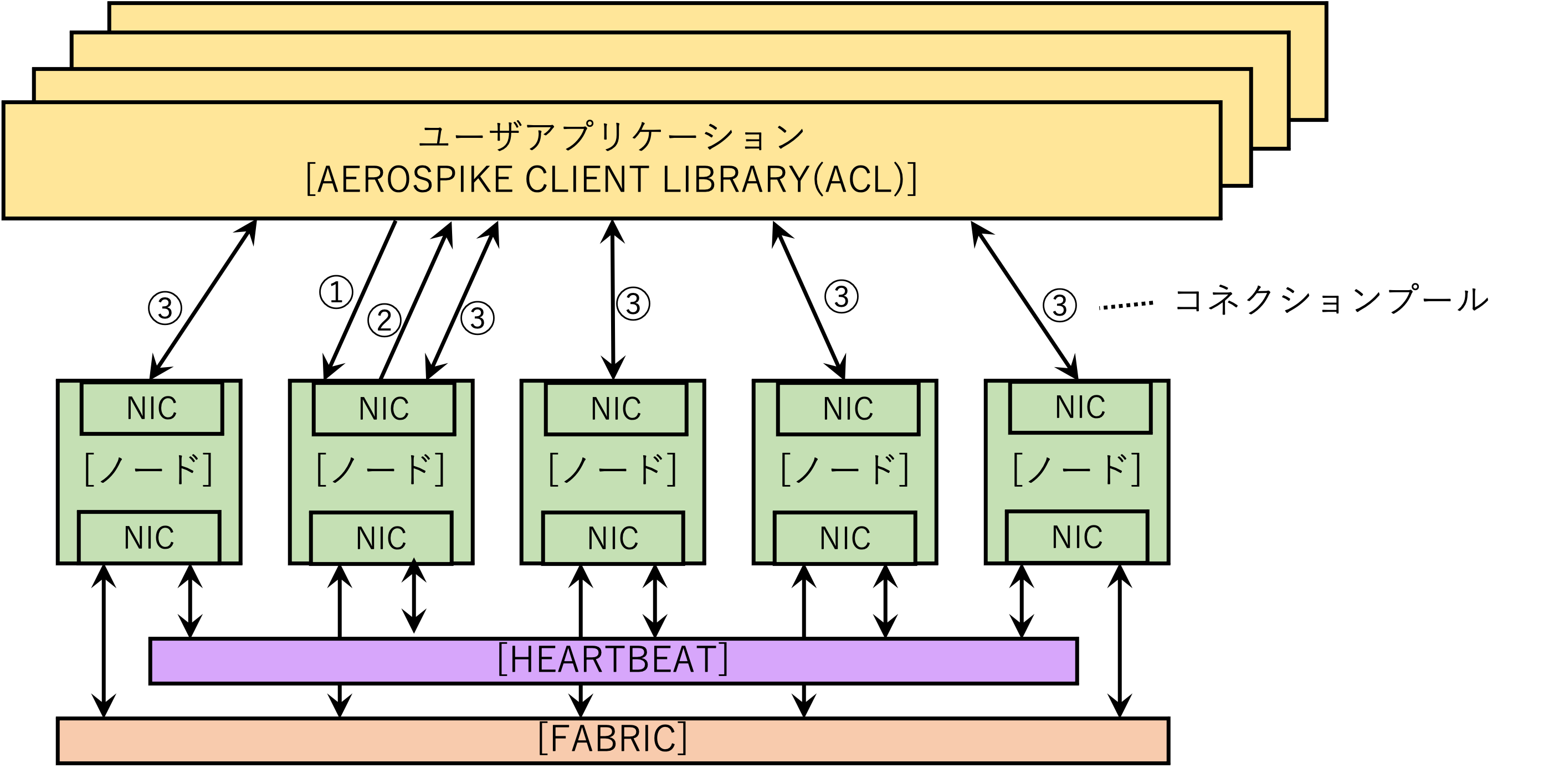
アクセスする手順は以下の通りです。
- クライアントからAerospikeのノードのホスト名やIPアドレスに対して、コネクションを作成します。(図の①)
- アクセスされたノードは、すべてのノードの情報をクライアントに送信します。(図の②)
- クライアントは、ノードから送信されたすべてのノードの情報から、すべてのノードにコネクションプールを作成します。(図の③)
- クライアントは、このコネクションを使用し、CRUDの操作を行います。
他にもコネクター等を使用したアクセスも可能です。
データ構成
Aerospikeでは、どのようにデータが構成されているか、ご説明します。
以下がデータの構成になります。
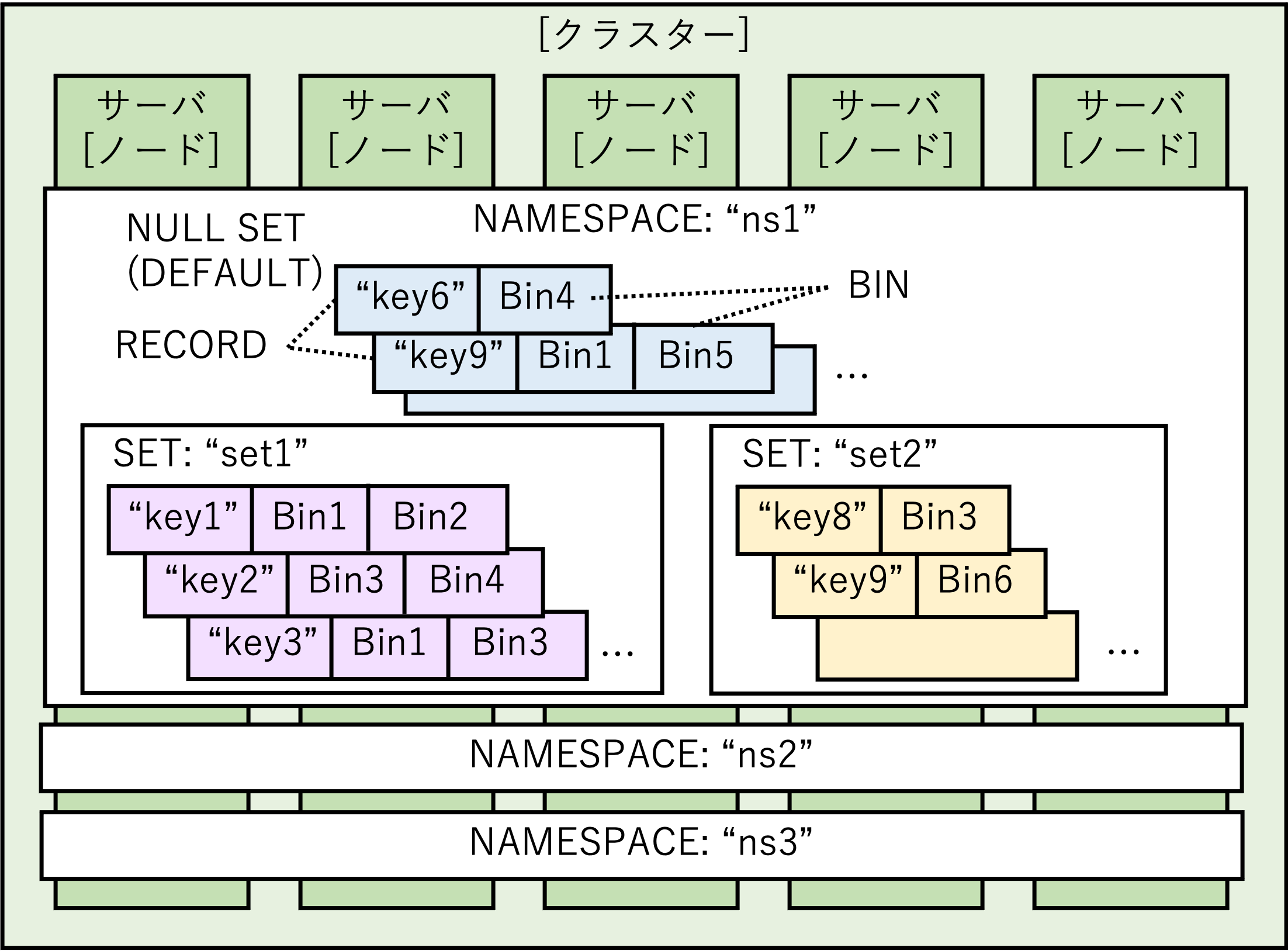
NAMESPACE
まず、データを保持する最大の単位がNAMESPACEになります。
これは、RDBではデータベース、テーブルスペースなどにあたります。
Aerospikeでは、このNAMESPACE毎にデータの保持方法やデフォルトのTTL(データの自動削除までの時間)、一貫性のモードなどを指定することができます。
SET
NAMESPACEの中には、データをグループ分けするために、SETを作成します。
ただし、SETが無い、NULL SETもデフォルトで存在します。
これは、RDBではテーブルにあたります。
RECORD(またはOBJECT)
データ自体は、RECORDという単位で作成されます。
これは、RDBではROWやRECORDにあたります。
RECORDは、キー、メタデータ、複数のBINで構成され、CRUD時にはこのキーを指定してRECORDの操作を行います。
図では、キーがレコードに保存しているように記載していますが、デフォルトではキーはRECORDには保存されず、後述するDIGESTという値が代わりに保存されています。
BIN
RECORDにデータを保存するのは、BINという単位になります。
これは、RDBではCOLUMNにあたります。
このBINには後述するデータタイプで説明するように、様々なデータを保存します。
RECORDにどのBINが存在するかは決まりがなく、BINの数もRECORDによって違ってきます。
また、同じ名称のBINであっても違うデータタイプのデータを保存することもできます。
注意
NAMESPACEの数、SETとBINの名称の数には上限があります。
SETおよびBINはクライアントから追加出来ますが、その名称を削除することはできないため、例えば日付や時間を名称にしてSETやBINを作成すると、上限に達してしまう場合がありますのでご注意ください。
データタイプ
BINには様々なデータタイプを保存できます。
参考:Aerospike公式サイト:Data Types
保存できるデータタイプは以下になります。
-
Scalar Data Type
- Integer
- Double
- String
- Boolean
- Blob/Bytes
-
Collections
- List
- Map
- GeoJSON
- HyperLogLog
Collectionsについては、List、Mapをネストすることが可能です。このデータについてはJSONとして詳細なアクセスが可能であり、Documentデータとして利用することができます。
ユーザアプリケーションからアクセスする場合、各言語のデータタイプにAerospike Client Libraryが変換してくれるため、ユーザ側でAerospikeのデータタイプを意識する必要はありません。
Graphデータについても、今後対応予定です。
データ構成と保存方法
Aerospikeでは、RECORDの データ を保存するだけではなく、そのRECORDのデータにアクセスするための情報をもつ インデックス を保持します。
参考:Aerospike公式サイト:Hybrid Storage
また、任意のBINに対して作成する セカンダリーインデックス もありますが、この記事には記載しません。参考
この データ と インデックス を保存する記憶媒体としては、以下が使用されます。
- NVMe Flash(日本では、SSDと呼ばれる場合が多い)
- DRAM(いわゆるメモリ)
- PMEM(Persistent Memory。HPEとIntelが提供している不揮発性メモリ)
これらを使用した、Aerospikeの代表的な構成は以下のとおりです。
| ALL FLASH | DRAM & FLASH |
ALL DRAM | PMEM & FLASH |
ALL PMEM | |
|---|---|---|---|---|---|
| インデックス | NVMe Flash | DRAM | DRAM | PMEM | PMEM |
| データ | NVMe Flash | NVMe Flash | DRAM | NVMe Flash | PMEM |
- ALL FLASH:インデックスとデータの両方を、NVMe Flashに保持
- メリット
- DRAMとPMEMに比べると安価で構築できる。
- インデックスが永続化されるため、再起動時、立ち上げに時間がかからない。
- 大量データの保持が可能。
- デメリット
- インデックスがDRAMやPMEMの場合に比べると遅くなるため、LatencyとThroughputの性能が大幅に落ちる。
- メリット
- DRAM & FLASH:インデックスをDRAM、データをNVME Flashに保持
- メリット
- LatencyとThroughput、価格のバランスが良い。
- 大量データの保持が可能。
- デメリット
- インデックスが永続化されないため、再起動時、インデックスの再作成が発生し、立ち上げに時間がかかる。(データが多いと数時間かかる。)
- メリット
- ALL DRAM:インデックスとデータの両方を、DRAMに保持
- メリット
- LatencyとThroughputの性能が高い。
- デメリット
- 大量データの保持が困難。
- 価格が高い。
- インデックスとデータともに永続化されない。
- 永続化のため、HDDのファイルシステムを利用する方法もあるが、立ち上げに、DRAM & FALSHよりもさらに時間がかかる。
- メリット
- PMEM & FLASH:インデックスをPMEM、データをNVME Flashに保持
- メリット
- 大量データの保持が可能。
- インデックスが永続化されるため、再起動時、立ち上げに時間がかからない。
- ALL FLASHよりLatencyとThroughputの性能が高い。
- デメリット
- DRAMとの価格差。
- メリット
- ALL PMEM:インデックスとデータの両方を、PMEMに保持
- メリット
- LatencyとThroughputの性能が高い。
- インデックスが永続化されるため、再起動時、立ち上げに時間がかからない。
- デメリット
- 大量データの保持が困難。
- 価格が高い。
- メリット
以上から、データ量が少なく永続化の必要が無い場合はALL DRAM、大量データが必要な場合はDRAM & FLASHの構成が多く使用されています。
今後、PMEMが広く使われるようになると、PMEM & FLASHやALL PMEMの使用が増えることが予想されます。
データ分散とレプリケーション
Aerospikeでは、前述の通りデータ分散が自動的に行われるのが特徴です。
また、ノードの障害時にレコードが消失しないようにレコードを複製して別のノードに保存する レプリケーション という機能も特徴です。多重化数を Replication Factor (以降、RFと記載)として設定できます。(2と設定すると、masterのレコードとコピーされたレコードの2つがクラスターに保存される。)
以下、データ分散のキーになる技術について説明します。
Digest
Aerospikeでは、レコードにアクセスするキーをそのまま利用するのではなく、Digestという20 BYTEのハッシュデータを使用します。
Digestの作成は、以下により作成します。
- 「キーの値 + キーのタイプ(String or Numeric) + Set名」の文字列を作成
- 「RIPEMD160」でハッシュ化
このハッシュの値は、現在ではユニークになると考えられていますので、違うキーから同じDigestが作成されることはありません。
RECORDにはこのDigestが保存されており、クライアントからアクセスする時も、Aerospike Client LibraryにてキーからDigestに変換されて送信されます。
DigestからParition IDの作成
Digestの特定の位置の12bitを10進数にしたものをParition IDとします。
つまり、Digestが決まると、Partition IDが決定します。
12bitですので、Partition IDは0から4095の4096個になります。
このPartition IDを使って、データを分散します。
Partition ID
Aerospikeでは、0から4095のPartion IDを各ノードに割り振ります。
RECORDは、Digestから割り出したPartition IDを割り振られたノードに保存されます。
この割り振りは、以下のような PARTITION TABLE を利用します。
以下は、ノードがA,B,C,D,Eの5つあり、RFが2の場合についてです。
各Partition IDに対して、ノードのAからEを、特定のルールに従って、R1からR5に割り振ります。
| Parition ID | R1 | R2 | R3 | R4 | R5 |
|---|---|---|---|---|---|
| 0 | B | D | E | A | C |
| 1 | E | C | A | D | B |
| : : |
: : |
: : |
: : |
: : |
: : |
| 4094 | C | B | A | E | D |
| 4095 | D | E | A | B | C |
RFが2であれば、このPARTITION TABLEのR1とR2を使用します。例えば、Partition IDが0のRECORDは、R1とR2に記載されているBとDに保存されます。
R1のノードがMASTER、R2のノードをPROLEといいます。RFが増えればR3、R4とRECORDを保存するノードが増えます。
PARTITION TABLE のうち、RFまでのテーブルを PARTITION MAP と呼びます。ここでは、R2までの情報がPARTITION MAPになります。
このPARTITION MAPはクライアントからのアクセスに使用されます。詳細は後述します。
ノードの増減とマイグレーション
ノードが減った場合、PARTITION TABLEが再作成されます。減ったノードがTABLEから削除され、ノードが左に詰める形になります。R1のノードが減った場合は、R2のノードがR1(MASTER)になり、R3のノードがR2(PROLE)になります。
この時、新しいR1のノードから新しいR2のノードに、FABRICを経由して、そのPartition IDに含まれるRECORDが送信され、新しいR2のノードに保存されます。
ノードBがなくなった場合は、以下のように変化します。
| Parition ID | R1 | R2 | R3 | R4 | R5 |
|---|---|---|---|---|---|
| 0 |
|
|
|
|
|
| 1 | E | C | A | D | |
| : : |
: : |
: : |
: : |
: : |
: : |
| 4094 | C |
|
|
|
|
| 4095 | D | E | A |
|
ノードが増えた場合、PARTITION TABLEが再作成されます。R6が追加され、特定のルールに従い、それぞれのPartition ID毎にR1からR6のどこかに新しいノードが挿入され、以降のノードが右にずれます。
R1かR2に追加されたノードが追加された場合は、挿入前のR1から追加されたノードに、FABRICを経由して、そのPartition IDに含まれるRECORDが送信され、新しいノードに保存されます。
ノードFが追加された場合は、以下のように変化します。
| Parition ID | R1 | R2 | R3 | R4 | R5 | R6 |
|---|---|---|---|---|---|---|
| 0 |
|
|
|
|
|
C |
| 1 | E | C | A | D | B | F |
| : : |
: : |
: : |
: : |
: : |
: : |
: : |
| 4094 | C | B | A |
|
|
D |
| 4095 | D |
|
|
|
|
C |
上記の、FABRICを経由したデータの送信および保存を マイグレーション(Migration) と呼びます。
クライアントアクセス方法およびサーバ処理
PARTITION MAPの取得
クライアントからアクセスするために、前述の PARTITION MAP が使用されます。
Aerospike Client Libraryはコネクションが作成されると、1秒毎にクラスターにアクセスしPARTITION MAPを取得しにいきます。PARTITION MAPに変更があると、新しいPARTITION MAPを取得します。
クライアントからクラスターにアクセスする時、アクセスするRECORDのキーからDigestを作成し、そこからPartition IDを割り出し、そして、PARTITION MAPを参照し、アクセスするノードの情報を取得します。
CRUDの動作
クライアントからのCRUDの操作およびサーバ側で行われる処理について説明します。
- CREATE、UPDATE(REPLACE)
- Aerospikeのクライアント側の操作は、CREATE/UPDATEの区別はありません。
- クライアントからのアクセスはMASTERのノードに対して行います。
- CREATE/UPDATE/REPLACE時には、クラアントからNAMESPACEとSETの名称、KEY(実際にはDIGEST)とBINのデータをサーバに送信します。
- サーバ側では、このKEYがサーバに存在する場合、RECORDをUPDATEまたはREPLACEします。存在しない場合、RECORDをCREATEします。
- UPDATEの場合は送信したBINの値を追加または変更し、REPLACEの場合は送信したBIN以外のBINは削除し、送信したBINのみ追加または変更します。
- UPDATEかREPLACEかは、アクセス時のPolicyの設定で決定します。
- Policyの設定で、CREATEの場合のみ実行、UPDATEまたはREPLACEの場合のみ実行とすることも可能です。
- CREATE時にサーバ側では新しいレコードを作成し、インデックスにそのレコードの参照を追加します。そして、PROLEノードにFABRICを経由してRECORDが送信されMATERと同様にCREATEされます。
- UPDATE時にサーバ側では、現在のRECORDをメモリに取り出し、そのRECORDのデータとクライアントから送信されたBINのデータを合わせて新しいRECORDを作成し、インデックスのRECORDの参照を新しいRECORDに変更します。そして、PROLEノードにFABRICを経由してRECORDが送信されMATERと同様にUPDATEされます。
- REPLACE時にサーバ側は、クライアントから送信されたBINのデータで新しいRECORDを作成し、インデックスのRECORDの参照を新しいRECORDに変更します。そして、PROLEノードにFABRICを経由してRECORDが送信されMATERと同様にREPLACEされます。
- READ
- クライアントからのアクセスはMASTERのノードに対して行います。
- クライアントからはREADしたいRECORDのKEY(実際にはDIGEST)をサーバに送信します。
- サーバ側では、インデックスを参照し、RECORDを取得しクライアントに送信します。
- DELETE
- クライアントからのアクセスはMASTERのノードに対して行います。
- クライアントからはDELETEしたいRECORDのKEY(実際にはDIGEST)をサーバに送信します。
- サーバ側では、インデックスのRECORDの参照を削除します。そして、PROLEノードにFABRICを経由してキー(Digest)が送信されMATERと同様にDELETEされます。
- データ自体は定期的に実行されるデフラグの処理により削除されます。
- デフラグの前にノードが再起動されると、再起動の方法とデータの保存方法によっては、DELETEしたレコードが復活することがあります。これを防ぐ方法も別途提供しています。(Enterprise Editionのみ)
最後に
以上が、Aerospikeのアーキテクチャの基本になります。
詳細の記述を省略している箇所もありますので、ご質問あればお気軽にコメントしてください。