データサイエンスツールのプレビュー
科学技術計算やデータサイエンスのためにPythonを使う点において、ここからはねてさらにいきたいなら、あなたの人生をはるかにはやくするいくつかのパッケージがあります。この節は、より重要ないくつかのものを紹介して試すものです、そしてそれらが設計されるためのアプリケーションのタイプのアイデアを与えます。もしこのレポートのはじまりで提案されたAnacondaやMiniconda環境を使うなら、次のコマンドで関連パッケージをインストールできます:
$ conda install numpy scipy pandas matplotlib scikit-learn
順番にこれらそれぞれを簡単にみていきましょう。
NumPy: 数のPython
NumPyは、Pythonで多次元の多量の配列をためて操作する効果的な方法を与えます。Numpyの重要な特徴です:
それはベクトル、行列、そしてより高次のデータセットの効果的な保存と操作を可能とするndarrayの構造を供給します。単純な要素ごとの算術からより複雑な線形代数の演算まで、このデータで操作する可読的な効果的なシンタックスを供給します。最も単純な場合、Numpyの配列は多くのPythonのリストを見ます。例えば、ここには1から9まで(Pythonの組み込みのrange()を使うのとこれを比較しましょう)の範囲の数値を含んだ配列があります:
In [1]:
import numpy as np
x = np.arange(1, 10)
x
Out[1]:
array([1, 2, 3, 4, 5, 6, 7, 8, 9])
Numpyの配列は、データに対する要素ごとの効果的な演算と同時に、効果的なデータの保存両方を提供します。例えば、配列の各要素の累乗のために、直接配列に対して"**"演算子を適用できます:
In [2]:
x ** 2
Out[2]:
array([ 1, 4, 9, 16, 25, 36, 49, 64, 81])
同じ結果のために、はるかに明らかなPython形式のリストの内包表現と比較しましょう:
In [3]:
[val ** 2 for val in range(1, 10)]
Out[3]:
[1, 4, 9, 16, 25, 36, 49, 64, 81]
一次元に限定されるPythonリストと違って、Numpy配列は多次元になります。例えば、ここでx arrayを3x3 arrayにreshapeしましょう:
In [4]:
M = x.reshape((3, 3))
M
Out[4]:
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
二次元配列は行列の一つの表現で、Numpyは効果的に典型的な行列演算をする方法をわかっています。例えば、置換を.Tを使って計算できます:
In [5]:
M.T
Out[5]:
array([[1, 4, 7],
[2, 5, 8],
[3, 6, 9]])
もしくは行列ベクトルの積をnp.dotを使って:
In [6]:
np.dot(M, [5, 6, 7])
Out[6]:
array([ 38, 92, 146])
そして固有分解のようなより洗練された演算さえ:
In [7]:
np.linalg.eigvals(M)
Out[7]:
array([ 1.61168440e+01, -1.11684397e+00, -1.30367773e-15])
そのような線形代数操作は近代的なデータ分析の多くをピン留します、特に機械学習やデータマイニングの分野へくるときです。
NumPyのさらなる情報については、Resources for Further Learning を見てください。
Pandas: ラベルづけされるカラムを基にしたデータ
PandasはNumpyよりもはるかに新しいパッケージです、そして事実上その上に組み込まれます。Pandasが供給するのは、Rと関連する言語のユーザにとってはとても親しまれるであろうDataFrameオブジェクト形式の中で、多次元データのラベルづけされたインタフェースです。PandasにおけるDataFrameはこのような何かを見ます:
In [8]:
import pandas as pd
df = pd.DataFrame({'label': ['A', 'B', 'C', 'A', 'B', 'C'],
'value': [1, 2, 3, 4, 5, 6]})
df
Out[8]:
label value
0 A 1
1 B 2
2 C 3
3 A 4
4 B 5
5 C 6
Pandasインタフェースは、名前によって列を選択するようなことをするのを許します:
In [9]:
df['label']
Out[9]:
0 A
1 B
2 C
3 A
4 B
5 C
Name: label, dtype: object
文字列の登場を通じて文字列演算を適用しましょう:
In [10]:
df['label'].str.lower()
Out[10]:
0 a
1 b
2 c
3 a
4 b
5 c
Name: label, dtype: object
数の登場を通じて、数えてみましょう:
In [11]:
df['value'].sum()
Out[11]:
21
そして、多分もっとも重要なことに、効果的なデータベース形式のjoinとgroupingをしましょう:
In [12]:
df.groupby('label').sum()
Out[12]:
value
label
A 5
B 7
C 9
ここに、NumpyやcorePythonで提供されているツールよりもはるかにあきらか(そして、はるかに効果的ということではない)なものの、同じラベルを共有するすべてのオブジェクトの総計を計算する一行があります、
Pandasのさらなる情報は、Resources for Further Learning をみてください。
MatLabスタイルのMatplotlibの科学的な表現性
Matplotlibは現在最も有名なPythonにおける科学的可視化パッケージです。 そのインタフェースはときどき明らかにオーバーなことを許容する支持者さえいますが、広範囲のプロットを作るのに力強いライブラリです。
Matplotlibを使うために、notebookモード(Jupyter notebookで使われます)を有効にして、pltとしてパッケージをインポートすることによって開始できます
In [13]:
# run this if using Jupyter notebook
%matplotlib notebook
In [14]:
import matplotlib.pyplot as plt
plt.style.use('ggplot') # make graphs in the style of R's ggplot
さあ、いくつかのデータ(もちろんNumpy配列のように)を作って結果をプロットしましょう:
In [15]:
x = np.linspace(0, 10) # range of values from 0 to 10
y = np.sin(x) # sine of these values
plt.plot(x, y); # plot as a line
このコードをライブで実行するなら、あなたに探求したいデータをpan, zoom, scrollさせる双方向のプロットをみるでしょう、
これはMatplotlibのプロットについての最も単純な例です。利用できるplot typeの幅広いアイデアについて、"Resources for Further Learning."でリストされる他のリファレンスと同じように、Matplotlib のオンラインギャラリーを見てください。
SciPy: 科学的Python
SciPyはNumpyで組み立てられる科学的機能のコレクションです。よく知られる数値計算のためのFortranライブラリに対するPythonのラッパーの集合としてはじまり、現在まで成長しています。パッケージは、数値のアルゴリズムのいくつかのクラスを実装しているサブモジュールの集合としてまとまっています。ここに、データサイエンスのためのいくつかのより重要なものの不完全なサンプルがあります:
- scipy.fftpack: 高速フーリエ変換
- scipy.integrate: 数値積分
- scipy.interpolate: 数値補間
- scipy.linalg: 線形代数手続き
- scipy.optimize: 数理最適化関数
- scipy.sparse: 疎行列の保存と線形代数
- tscipy.stats: 統計的な解析手続き
例えば、いくつかのデータのスムーズな曲線を補間をみてみましょう
In [16]:
from scipy import interpolate
# choose eight points between 0 and 10
x = np.linspace(0, 10, 8)
y = np.sin(x)
# create a cubic interpolation function
func = interpolate.interp1d(x, y, kind='cubic')
# interpolate on a grid of 1,000 points
x_interp = np.linspace(0, 10, 1000)
y_interp = func(x_interp)
# plot the results
plt.figure() # new figure
plt.plot(x, y, 'o')
plt.plot(x_interp, y_interp);
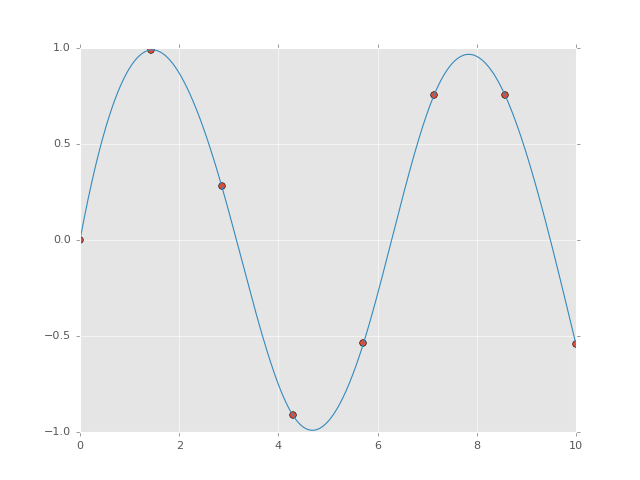
私たちが見ているのは点の間のスムーズな補間です。
他のデータサイエンスパッケージ
これらのツールからさらに組み立てられるのは、多くの他のデータサイエンスパッケージで、機械学習のためのScikit-Learn、画像分析のためのScikit-Image、統計モデルのためのStatsmodelsのような一般的なツールを含みます、同時により天文学や天体物理学のためのAstroPyのようなより問題固有のパッケージ、神経画像のためのNiPy、そしてより多くのものがあります。
あなたが直面する科学、数値、統計の問題の種類だろうと問題なく、それを解決するのを支えるPythonパッケージがそこにあるのがおそらくそうです。