組み込みのデータ構造
Pythonのシンプルな型をみてきました、int, float, complex, bool, strなど。Pythonはまたいくつかの組み込みの複合の型をもっており、その他の型に対するコンテナとして動きます。これらの複合型です
Type Name Example Description
list [1, 2, 3] Ordered collection
tuple (1, 2, 3) Immutable ordered collection
dict {'a':1, 'b':2, 'c':3} Unordered (key,value) mapping
set {1, 2, 3} Unordered collection of unique values
見ているように、丸や四角、中括弧は、生み出されるコレクション型が現れるときに意味を区別するものです。これらのデータ構造をここで駆け足にとりあげていきます。
リスト
リストはPythonにおける基本的に順序付けされて変更可能なデータのコレクション型です。大カッコの間でカンマで区切られた値で定義されます。例えば、ここに最初のいくつかの素数のリストがあります。
In [1]:
L = [2, 3, 5, 7]
リストはそれらに利用できる使いやすいプロパティとメソッドがたくさんあります。さあ、より一般的で使いやすい例のいくつかをみてみましょう:
In [2]:
# Length of a list
len(L)
Out[2]:
4
In [3]:
# Append a value to the end
L.append(11)
L
Out[3]:
[2, 3, 5, 7, 11]
In [4]:
# Addition concatenates lists
L + [13, 17, 19]
Out[4]:
[2, 3, 5, 7, 11, 13, 17, 19]
In [5]:
# sort() method sorts in-place
L = [2, 5, 1, 6, 3, 4]
L.sort()
L
Out[5]:
[1, 2, 3, 4, 5, 6]
加えて、はるかに多くの組み込みのリストメソッドがあります。Pythonのオンラインドキュメントではよく網羅されています。
一つの型の値を含んだリストを示した一方で、Pythonの複合型の力強い機能は、任意の型または型の混合でさえのオブジェクトを含むことができます。例えば、
In [6]:
L = [1, 'two', 3.14, [0, 3, 5]]
この柔軟性はPythonの動的型システムの延長です。Cのような静的型付け言語の混合シーケンスのようなものを作ることは、はるかにたくさんの頭痛を生み出します!
リストは要素として他のリストさえ含むのです。そのような柔軟性はPythonコードが比較的早く簡単に書けることの本質的な部分です。
これまでのところ概してリストの操作を考えてきました、他の本質的な部分は個別の要素へのアクセスです。Pythonではインデックスとスライシングを経てなされます。次の見に行きましょう。
Listのインデックスとスライシング
Pythonは一つの要素のためのインデックス、複数の要素のためのスライシングを通して複合型の要素にアクセスします。わかるように、両方が大括弧のシンタックスで示されます。最初のいくつかの素数のリストに戻りましょう
In [7]:
L = [2, 3, 5, 7, 11]
Pythonはゼロベースのインデックスを使います、次のシンタックスを使って、最初と次の要素にアクセスしてみましょう。
In [8]:
L[0]
Out[8]:
2
In [9]:
L[1]
Out[9]:
3
リストの端の要素は、-1からはじまる、マイナスの数でアクセスできます、
In [10]:
L[-1]
Out[10]:
11
In [11]:
L[-2]
Out[11]:
7
このようにインデックスの構造を表せます。
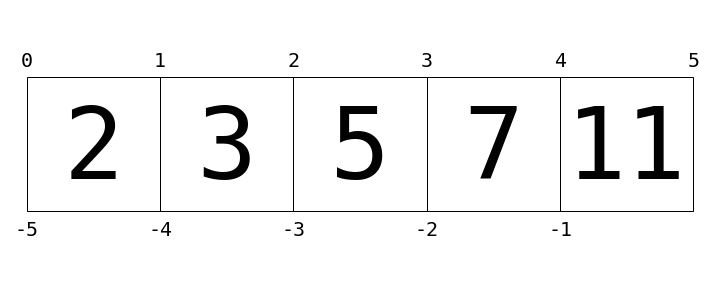
ここにリストの値が四角の中で大きい数値としてあらわされています。リストの索引は上下の小さい数字であらわされます。この場合L[2]は5を返します。なぜならインデックス2の隣の値だからです。
インデックスはリストから一つの値を取り出す意味ですが、スライシングはサブのリストで複数の値へアクセスすることを意味します。
下位の配列の最初の値(含まれる)と最後の値(含まれない)を示すためにコロンを使います。例えば、リストの最初の三つの要素を得るために、書きます:
In [12]:
L[0:3]
Out[12]:
[2, 3, 5]
先の図の0と3がある場所で、いかにスライスが単に索引の間の値をとってくるかということに留意しましょう。もし最初のインデックスをはずすなら、0とみなされます、ひとしくこのようにかけます:
In [13]:
L[:3]
Out[13]:
[2, 3, 5]
同様に、もし最後のインデックスをはずすなら、リストの長さまで維持されます。このように、最後の三要素が以下のようにアクセスされます:
In [14]:
L[-3:]
Out[14]:
[5, 7, 11]
最後に、ステップサイズを表現する三番目の数値を特定することができます。例えば、リストの要素を二つごとに選択するために、書きます:
In [15]:
L[::2] # equivalent to L[0:len(L):2]
Out[15]:
[2, 5, 11]
特に使いやすいやり方はマイナスのステップを指定することで、配列を逆から走査します:
In [16]:
L[::-1]
Out[16]:
[11, 7, 5, 3, 2]
インデックスとスライシングの両方はそれらへのアクセスと同じように要素のセットのために使われます。シンタックスは期待しているとおり:
In [17]:
L[0] = 100
print(L)
[100, 3, 5, 7, 11]
In [18]:
L[1:3] = [55, 56]
print(L)
[100, 55, 56, 7, 11]
とてもありふれたスライシングのシンタックスはまた、(導入で言及した)NumPyやPandasを含んだ、多くのデータサイエンス指向のパッケージで使われます。
いまや、Pythonのリストと順序付けされた複合型の要素にアクセスする方法がわかったので、先に言及した他の三つの標準的な複合データ型をみてみましょう。
タプル
タプルは、大括弧よりむしろ括弧で定義されますが、多くの点でリストに似ています。
In [19]:
t = (1, 2, 3)
それらはまた任意の括弧まったくなしでも定義されます。
In [20]:
t = 1, 2, 3
print(t)
(1, 2, 3)
前に話したリストのように、タプルは長さをもっていて、個別の要素は大括弧のインデックスを使って抽出できます。
In [21]:
len(t)
Out[21]:
3
In [22]:
t[0]
Out[22]:
1
主たるタプルの区別される機能は、変更できないということです。これは一度作られたら、それらのサイズと内容が変わらないということを意味します。
In [23]:
t[1] = 4
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-23-141c76cb54a2> in <module>()
----> 1 t[1] = 4
TypeError: 'tuple' object does not support item assignment
In [24]:
t.append(4)
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-24-e8bd1632f9dd> in <module>()
----> 1 t.append(4)
AttributeError: 'tuple' object has no attribute 'append'
タプルはしばしばPythonプログラムで使われます。特に一般的な場合は、複数の戻り値をもった関数の中にあります。例えば、浮動小数点のオブジェクトのas_integer_ratio() メソッド
は分子と分母を返します。この二つの戻り値はタプルの形式となります。
In [25]:
x = 0.125
x.as_integer_ratio()
Out[25]:
(1, 8)
これら複数の戻り値は、以下のように、個別に割り当てられます
In [26]:
numerator, denominator = x.as_integer_ratio()
print(numerator / denominator)
0.125
前のリストで網羅されたインデックスとスライシングの論理は、沢山の他のメソッドにそって、タプルで同じように動作します。これらのより完全なリストのためにオンラインのPythonドキュメントを参考にしてください。
辞書
辞書は、値へのキーの極度に柔軟なマッピングで、多くのPythonの内部実装の基本を規定します。中括弧の中で、キーとバリューのペアのカンマで区切られるリストを介して作られます。
In [27]:
numbers = {'one':1, 'two':2, 'three':3}
項目は、ここでは0ベースの順序でなく辞書の中で有効なキーのインデックスを除いて、リストとタプルで使われるインデックスのシンタックスでアクセスされ、セットされます。
In [28]:
# Access a value via the key
numbers['two']
Out[28]:
2
同じようにインデックスを使って辞書に新しい項目を追加できます。
In [29]:
# Set a new key:value pair
numbers['ninety'] = 90
print(numbers)
{'three': 3, 'ninety': 90, 'two': 2, 'one': 1}
辞書は入力のパラメータに対してのどんな順番も維持しないことを念頭においてください。これは設計によるものです。この順序の欠乏はとても効果的に辞書が実装されることになっています。そんなわけで、辞書のサイズにかかわらず(もしこれがどうやって動作するか興味をもつなら、ハッシュテーブルの概念について読んでください)、ランダムな要素へのアクセスはとても速いです。Pythonのドキュメントは辞書で利用できるメソッドの完全なリストを持ちます。
セット
4つめの基本のコレクションはセットで、唯一の項目をもつ順序付けされないコレクションを含んでいます。それらは、辞書の中括弧を使うことを除いて、リストとタプルのように定義されます。
In [30]:
primes = {2, 3, 5, 7}
odds = {1, 3, 5, 7, 9}
もし集合の数学について親しみがあるなら、あなたは和、積、差、対称差、その他他のような演算に親しみがあることでしょう。Pythonの集合はこれらの演算すべてを、メソッドや演算を通じて、組み込みでもっています。それぞれについて、二つの同等のメソッドを見せましょう:
In [31]:
# union: items appearing in either
primes | odds # with an operator
primes.union(odds) # equivalently with a method
Out[31]:
{1, 2, 3, 5, 7, 9}
In [32]:
# intersection: items appearing in both
primes & odds # with an operator
primes.intersection(odds) # equivalently with a method
Out[32]:
{3, 5, 7}
In [33]:
# difference: items in primes but not in odds
primes - odds # with an operator
primes.difference(odds) # equivalently with a method
Out[33]:
{2}
In [34]:
# symmetric difference: items appearing in only one set
primes ^ odds # with an operator
primes.symmetric_difference(odds) # equivalently with a method
Out[34]:
{1, 2, 9}
より多くのメソッドと演算が利用できます。たぶんすでに次にいうことを予測しているでしょう。完璧なリファレンスのためにPythonのオンラインドキュメントを参考にしてください。
より特化したデータ構造
Pythonは、役に立つとおもうかもしれない、いくつか他のデータ構造を含んでいます:一般的にこれらは組み込みのコレクションモジュールに見られます。コレクションモジュールはPythonのオンラインドキュメントで完全にドキュメント化されています。そして、そこで利用できる様々なオブジェクトについてより多く読めます。
特に、時折、次のがとても使いやすいのです:
- collections.namedtuple: タプルのようですが、各値は名前を持っています。
- collections.defaultdict: 辞書のようですが、不特定キーはユーザ特定のデフォルト値を持っています。
- collections.OrderedDict: 辞書のようですが、キーの順番が維持されません。
標準の組み込みのコレクション型がわかったなら、これらの拡張された機能性の使用はとても直感的です、そしてそれらの使用について読むことを提案します。