センシンロボティクスのQiitaをご覧の皆さんこんにちは。サービスクオリティチーム/SREの安達(@adachin0817)です。前回では弊社の技術スタックや、文化について書きましたが、今回はセンシンに転職して8ヶ月目といったこともありますので、今までやってきたことを振り返ろうと思います。まずはチームでどのようにお仕事しているのかご紹介したいと思います。
チームで意識していること
- サービスクオリティチーム/SREの担当
- サービスの可用性やセキュリティに寄与する施策の提案、設計、実装
- システム全体の開発効率向上に関する施策の提案、設計、実装
- システム監視、アラートの設計、構築
- GitHub ActionでのCI/CD の構築、サポート
- Terraformでのクラウドインフラの運用の仕組みを構築
- 開発メンバーへの技術サポート
- システム全体を通した課題の見える化、優先順位付け
- ログ収集、解析基盤の設計、構築
- システムインシデントの一次対応
- 自動セキュリティテストの導入
- ID 基盤の設計、構築
現在サービスクオリティ/SREチームは3名、PMが1名、マネージャー1名がいます。Jiraを利用してスクラムでタスクをこなしています。とは言ってもガチガチのスクラムを運用しているわけではありません。スプリントは1週間でdailyは毎日14時から30分、振り返りと来週やることは毎週金曜日18時から1時間取って行っています。dailyの司会は毎日交代制で行っており、前日にやったことや、技術的に悩んでいることを共有します。PMは各開発メンバーの共有事項やマネージャーは他の部署での困り事をサービスクオリティチームが受け持つイメージとなります。
また、それ以外にも自分はチームメンバーとの1on1を実施しています。よくチームで人数が多くなってしまうと、フルリモートは他のメンバーとコミュニケーションが減ってしまう経験があったのと、チームビルディングも1回限りで終わってしまう印象でした。メンバーとの1on1とペアプログラミングで、今では心理的安全性を高めてお仕事をできている状態です。個人的にはメンバーとの1on1はかなり大事だなと感じましたし、フルリモートですが、出社する必要性がないくらいコミュニケーションできていると思っています。
- メンバーとの1on1を実施することの効果
- 何が技術的に得意で不得意なのかお互いを知れるきっかけに
- たくさん話すことで信頼関係をアップ
- 毎週チーム内で雑談とペアプロを行う
- わいたい楽しく仕事ができる
- 分報を作成して、関係者を招待し、盛り上げる
次は監視基盤についてお話しましょう。
監視基盤をSaaSに移行検討
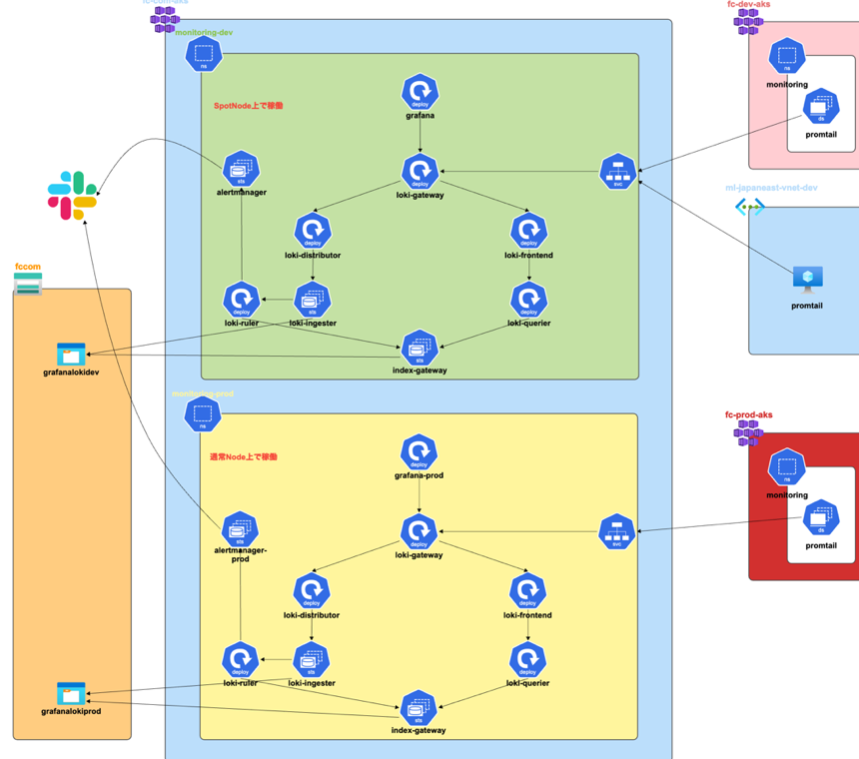
-
Azure/AKS
- Prometheus
- Grafana
- Grafana Loki
- Grafana Mimir
- Alertmanager
現行の監視基盤はAzure/AKSでGrafana + Prometheusを自前で運用しています。現在のコストは月10万円ほどですが、自前の監視基盤を運用することの懸念点としては自前自体のバージョンアップや運用などの工数が取られてしまうことです。そこで、センシンのサービスはマイクロサービス化しているため、コンテナ/Image数は本番、Dev、Stgが1000台以上存在します。SaaS(Datadog,NewRelic)に移行するとなると、どのくらいコストがかかるのか見積もりしてみたところ、3~5倍以上かかることが分かりました。一旦現行のまま運用することになりましたが、一部だけSaaSを使っても良さそうということもあるので、次回検討していきたいと思います。
旧監視基盤を現監視基盤へ移行
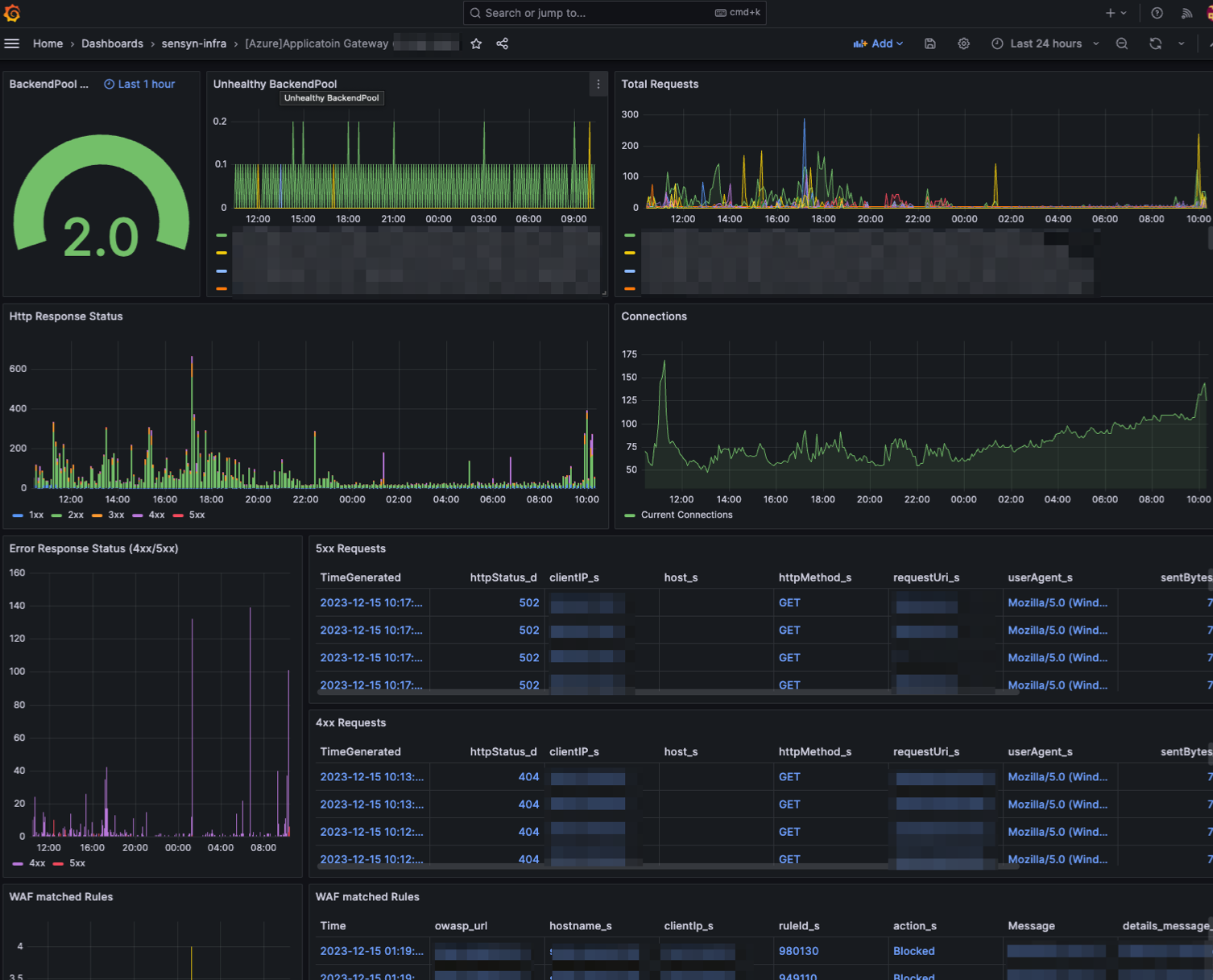
旧監視基盤ではGrafanaとPrometheusをVMで運用していました。アラートルールやダッシュボードなどを管理していたため、全て現監視基盤に移行しなければなりませんでした。また、Slackテンプレートも見やすくしたので、以下個人wikiを参考にしてみてください。移行したことにより、VMや不要なネットワーク周りの設定を削除したため、コスト削減することができました。
-
移行対象
- Dashboard
- Alert rules
- Contact points
- Notification
Grafanaアカウント作成CI/CD化とtfcmtの導入
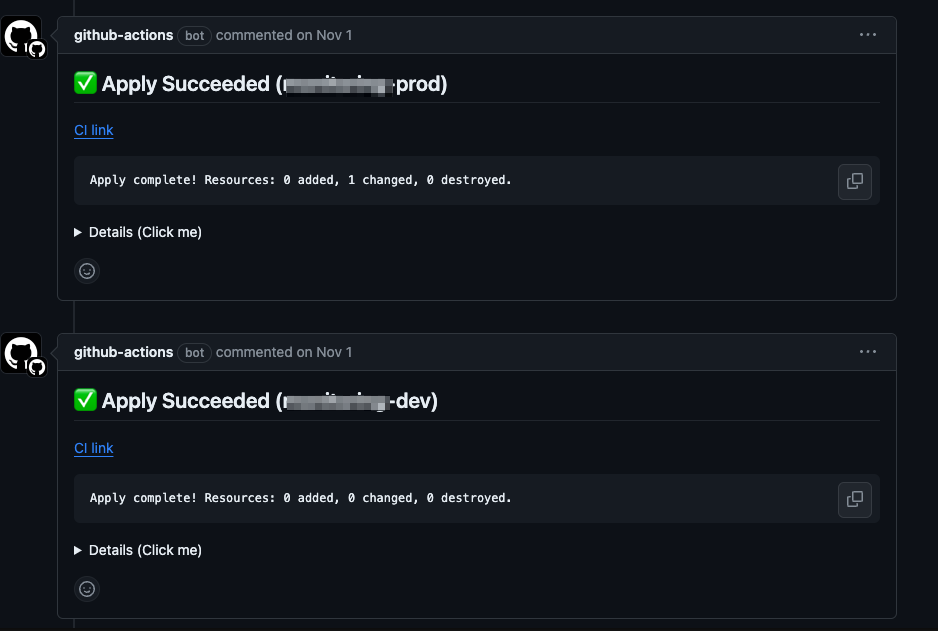
各メンバーのGrafanaアカウントはTerraform化されています。毎回メンバーを新規追加する場合はローカルでterraform applyを実行していました。ですが、適用漏れや証跡が残せないことがあるため、マージ後にCI/CDを動作させ、実行結果をtfcmtでプルリクエスト内のコメントとして上書きするようにしました。以下dev環境だけコードを貼っておきます
- terraform-cd-dev.yml
name: Dev Terraform CD
on:
push:
branches: [main]
paths:
- "grafana/dev/**"
permissions:
contents: read
pull-requests: write
jobs:
dev_terraform_cd:
name: Dev Terraform CD
runs-on: ubuntu-latest
steps:
- name: Checkout
uses: actions/checkout@v3
- name: Login to AKS
run: |
az login --service-principal -u ${AZURE_USER} -p ${AZURE_PASSWORD} --tenant ${AZURE_TENANT}
az aks get-credentials --resource-group hoge --name hoge
echo "GRAFANA_AUTH="admin:$(kubectl --context hoge -n hoge get secrets grafana -ojson | jq '.data["admin-password"] | @base64d' -r)"" >> $GITHUB_ENV
env:
AZURE_PASSWORD: ${{ secrets.FC_DEPLOY_CLIENT_SECRET }}
AZURE_TENANT: ${{ secrets.FC_DEPLOY_TENANT_ID }}
AZURE_USER: ${{ secrets.FC_DEPLOY_CLIENT_ID }}
- name: Setup Terraform
uses: hashicorp/setup-terraform@v2
with:
terraform_version: 1.4.0
- name: Setup tfcmt
uses: shmokmt/actions-setup-tfcmt@v2
with:
version: v4.6.0
- name: Terraform init
id: init
working-directory: ./grafana/dev
run: terraform init
env:
ARM_SUBSCRIPTION_ID: ${{ vars.ARM_SUBSCRIPTION_ID }}
ARM_TENANT_ID: ${{ vars.ARM_TENANT_ID }}
ARM_CLIENT_ID: ${{ vars.ARM_CLIENT_ID }}
ARM_CLIENT_SECRET: ${{ secrets.ARM_CLIENT_SECRET }}
- name: Terraform apply
id: apply
working-directory: ./grafana/dev
run: tfcmt -var "target:dev" apply -- terraform apply --auto-approve -no-color
env:
ARM_SUBSCRIPTION_ID: ${{ vars.ARM_SUBSCRIPTION_ID }}
ARM_TENANT_ID: ${{ vars.ARM_TENANT_ID }}
ARM_CLIENT_ID: ${{ vars.ARM_CLIENT_ID }}
ARM_CLIENT_SECRET: ${{ secrets.ARM_CLIENT_SECRET }}
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
GRAFANA_AUTH: ${{ env.GRAFANA_AUTH }}
Grafana Dashboard/Alert rulesをコード化
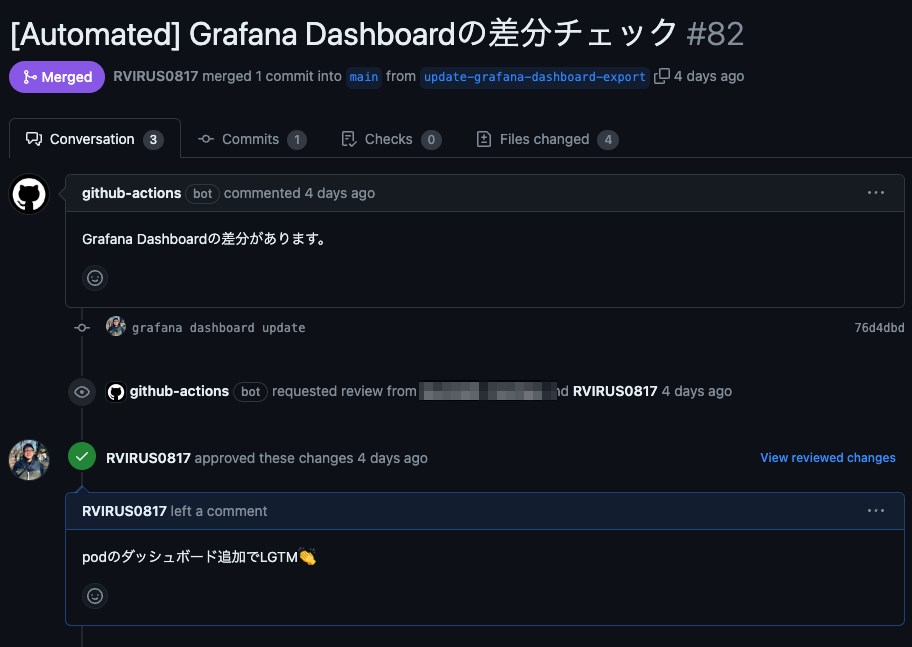
Grafanaのダッシュボードやアラートルールは手動で管理しています。本来はPrometheusでアラートの管理をした方がベストですが、開発メンバーが気楽にアラートを設定することができないため、Grafana側で管理することになりました。もちろんGrafanaはTerraformに対応していますが、JSONで管理しなければならず、設定項目が多すぎたため、断念しました。そこでGrafanaはAPIを提供しているため、JSONファイルを予めリポジトリ化し、GitHub Actionsで毎週1回バッチとしてシェルスクリプトで差分検知するようにしました。これで間違えて削除しても復元することができるようになりました。ダッシュボードだけ実装がややこしかったので、以下コードを貼っておきます。
-
Grafanaコード化対象
- Dashboard
- Alert rules
- notification templates
- notification policies
- contact points
- grafana-export.yml
name: Grafana Export
on:
schedule:
- cron: 0 1 * * 1
workflow_dispatch:
jobs:
grafana-dashboard-export:
timeout-minutes: 30
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: dev download api latest dashboard json
shell: bash
run: |
./scripts/dashboard-api.sh
env:
MONITORING_URL: https://hoge-dev
GRAFANA_API_KEY: ${{ secrets.DEV_GRAFANA_API_KEY }}
MONITORING_ENV: hoge-dev
- name: hoge-prod download api latest dashboard json
shell: bash
run: |
./scripts/dashboard-api.sh
env:
MONITORING_URL: https://hoge-prod
GRAFANA_API_KEY: ${{ secrets.PROD_GRAFANA_API_KEY }}
MONITORING_ENV: hoge-prod
- name: Create Pull Request
id: cpr
uses: peter-evans/create-pull-request@v5
with:
commit-message: "grafana dashboard update"
branch: update-grafana-dashboard-export
delete-branch: true
title: "[Automated] Grafana Dashboardの差分チェック"
body: |
Grafana Dashboardの差分があります。
reviewers: "hoge"
- name: Check outputs
if: ${{ steps.cpr.outputs.pull-request-number }}
run: |
cat <<'EOF' >> "$GITHUB_STEP_SUMMARY"
- Pull Request Number: ${{ steps.cpr.outputs.pull-request-number }}
- Pull Request URL: ${{ steps.cpr.outputs.pull-request-url }}
EOF
~省略~
- scripts/dashboard-api.sh
set -e -o pipefail
: "${MONITORING_URL:?}"
: "${GRAFANA_API_KEY:?}"
: "${MONITORING_ENV:?}"
# GrafanaのAPI URL
GRAFANA_API_URL="${MONITORING_URL}/api/search?type=dash-db&query=&starred=false"
# Grafana APIトークン
API_TOKEN="${GRAFANA_API_KEY}"
# APIリクエストを送信してJSONレスポンスを取得
response=$(curl -s -H "Authorization: Bearer ${API_TOKEN}" "${GRAFANA_API_URL}")
# ダッシュボードが保存される場所
dashboard_dir=grafana/${MONITORING_ENV}/dashboard
# 削除を追跡するために既存の保存されてるダッシュボードを削除
rm -rf "${dashboard_dir}"
# レスポンスからUIDを抽出してループ処理
uids=$(echo "${response}" | jq -r '.[] | .uid')
for uid in $uids; do
# ダッシュボードの詳細情報を取得
dashboard_info=$(curl -s -H "Authorization: Bearer ${API_TOKEN}" "${MONITORING_URL}/api/dashboards/uid/${uid}")
# タイトルを抽出
title=$(echo "${dashboard_info}" | jq -r '.dashboard.title')
# フォルダをスラッシュ区切りではなくハイフンに加工してuidを末尾に指定
dashboard_filename="$(echo "${title}" | tr '/' '-')"_"${uid}"
# ダッシュボードが所属するフォルダを取得
folder_title=$(echo "${dashboard_info}" | jq -r '.meta.folderTitle')
# フォルダ名として変数化
directory_path="${folder_title}"
# フォルダを作成
mkdir -p "${dashboard_dir}/${directory_path}"
# ダッシュボードの詳細情報をJSONファイルに保存
echo "${dashboard_info}" | jq '.dashboard' > "${dashboard_dir}/${directory_path}/${dashboard_filename}.json"
done
AKSバージョンアップとPlutoによるCI化
毎年恒例で行っているAKSバージョンアップですが、 v1.25からv1.28にバージョンアップを行いました。今まではreadmeでapiVersionのdeprecatedとremovedを目grepしていましたが、なかなか大変だったため、Plutoを導入してCI化を実装しました。detect-all-in-clusterはscheduleで毎月1日の10時に実行し、コンテナbuildする前にplutoを実行するようにしました。これで最新のバージョンにもすぐ対応できるため、バージョンアップの運用が楽になりました。
以下個人ブログ書いているので参考にしてみてください。
name: pluto CI
on:
schedule:
- cron: 0 1 1 * *
workflow_dispatch:
env:
SLACK_WEBHOOK: ${{ secrets.SLACK_WEBHOOK_URL }}
SLACK_USERNAME: pluto-ci
SLACK_CHANNEL: hoge-ci
SLACK_ICON: https://upload.wikimedia.org/wikipedia/labs/thumb/b/ba/Kubernetes-icon-color.svg/2110px-Kubernetes-icon-color.svg.png
jobs:
pluto_ci:
runs-on: ubuntu-latest
strategy:
matrix:
env: ["stg","prod"]
steps:
- name: Checkout
uses: actions/checkout@v3
- name: Login to AKS
run: |
az login --service-principal -u ${AZURE_USER} -p ${AZURE_PASSWORD} --tenant ${AZURE_TENANT}
az aks get-credentials --resource-group ${{ matrix.env }} --name ${{ matrix.env }}-aks
env:
AZURE_USER: ${{ secrets.HOGE_CLIENT_ID }}
AZURE_PASSWORD: ${{ secrets.HOGE_CLIENT_SECRET }}
AZURE_TENANT: ${{ secrets.HOGE_TENANT_ID }}
- name: Download Pluto
uses: FairwindsOps/pluto/github-action@master
- name: Run Pluto detect-all-in-cluster
run: |
{
echo '```'
pluto detect-all-in-cluster k8s=v1.28.3 -o wide
echo '```'
} | tee -a "$GITHUB_STEP_SUMMARY"
- name: Slack Success
if: ${{ success() }}
uses: rtCamp/action-slack-notify@v2
env:
SLACK_TITLE: Pluto CI Success
SLACK_COLOR: good
SLACK_MESSAGE: "Pluto CI Success🚀"
- name: Slack Failure
if: ${{ failure() }}
uses: rtCamp/action-slack-notify@v2
env:
SLACK_TITLE: Pluto CI Failure
SLACK_COLOR: danger
SLACK_MESSAGE: "<!subteam^hoge> Pluto CI Failure. Check deprecated/removed🚨"
SLI/SLO方針決めについて
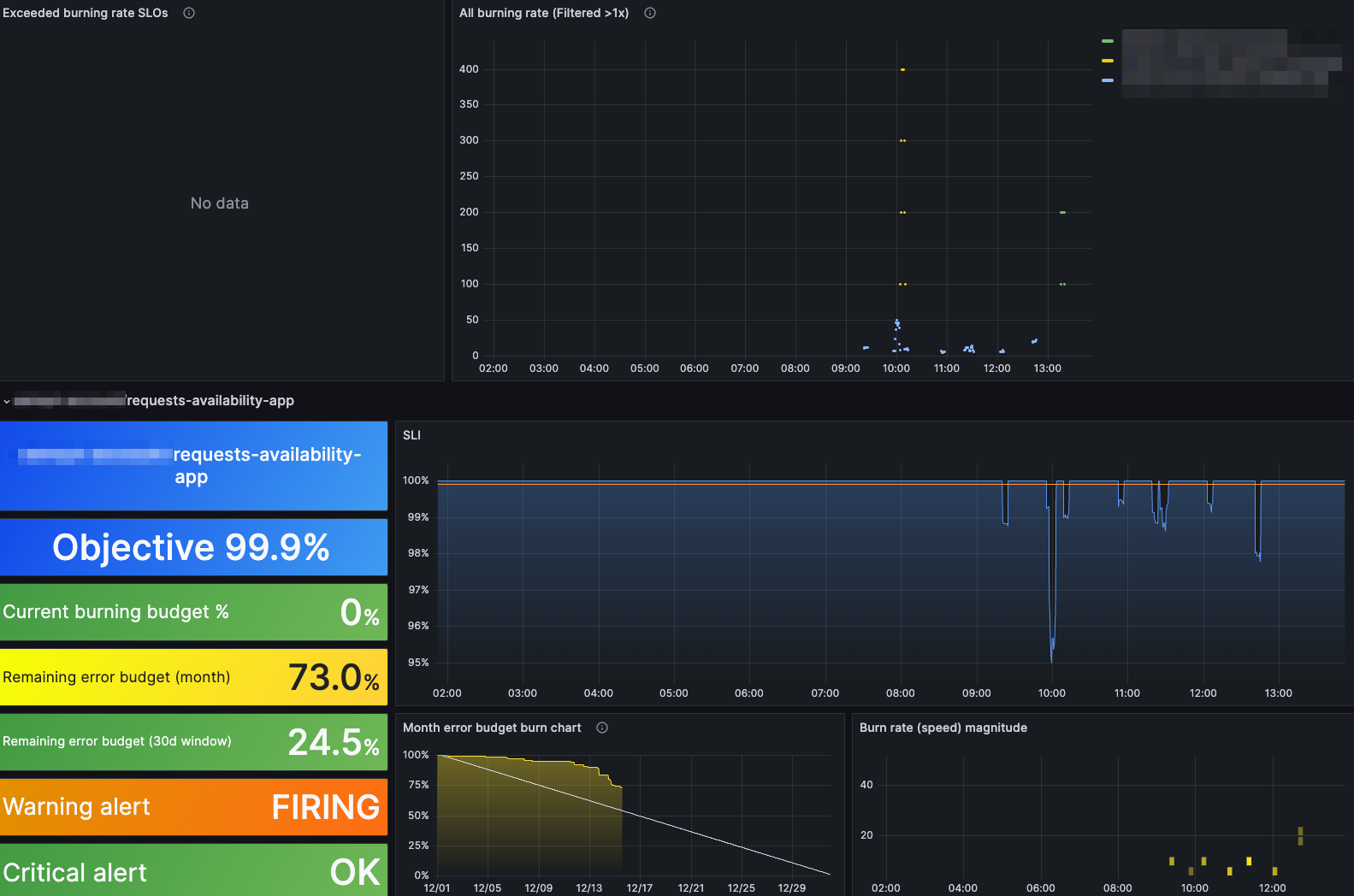
SLI/SLOは、テックリードとアプリケーションのレスポンスを元にSlothとpromitorで実装しています。また、弊社のサービスは多いため、SLI全てを管理するには難しい状況でした。初めはプロジェクト5つを対象にし、SLI/SLOの文化を小さく作り上げようとしています。まだ運用は開始していませんが、これから以下Sentryも導入することになったので改めて手法も変えていこうと思います。ちなみに上記Slothで作られたダッシュボードですが、グラフのレスポンスが結構悪いので色々と改善余地ありです。SLIの方針としては以下になります。
- アプリケーションのレスポンスを可視化
- リクエストの成功と失敗を検知
- メトリクスとログで検知する
- バッチ処理の成功と失敗を検知
- 予定通りに時間が終わっているか
- 除外
- インフラリソース
- CPU、メモリー、ネットワーク、ディスク
- 頻繁にアラートが出るためサービスの影響にはならない
- モニタリング方法
- 各エンジニア
- 開発チームごとのSLOアラートに入る
- サービスクオリティ/SREチーム
- 各チームのdailyに入ってダッシュボードを見ていく
- 振り返りを行う
- 各エンジニア
Sentry導入
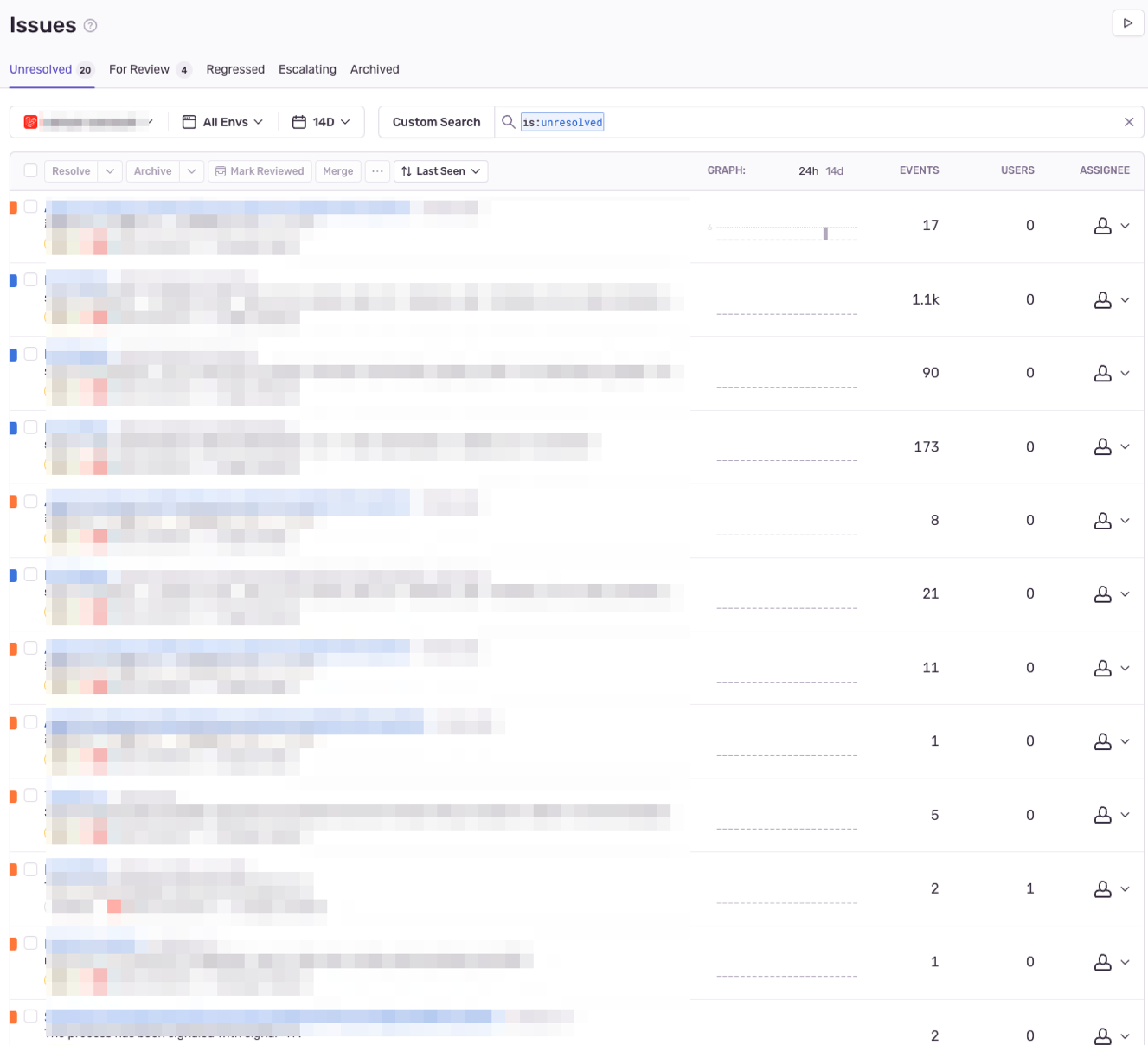
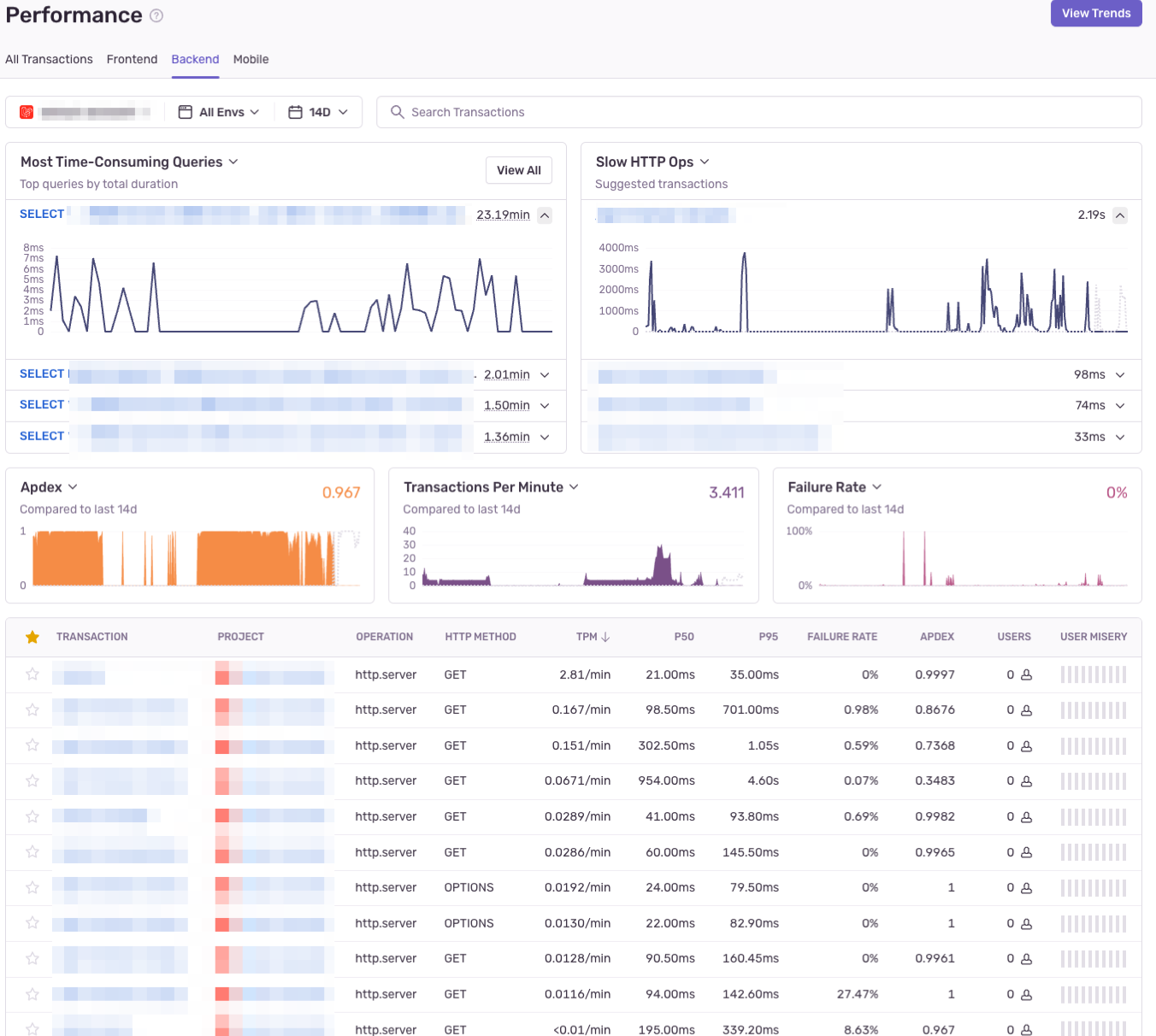
現監視基盤は障害時にGrafana Lokiでアプリケーションのエラーログから調査をしていたのと、原因特定までに時間がかかっている状態でした。そこで低コストでSentryを導入することが決まり、エラーログの優先順位付けや開発エンジニアが気づかないエラーをIssuesで確認できるようになりました。また、Sentryでは新機能としてAPMも新たに導入されていたので、アプリケーションの読み込みが遅いページを追跡でき、根本原因をより迅速に特定することができるようになりました。
その他バージョンアップについて
以下、Grafanaで利用するツール等は最新にバージョンアップして、Helmfile化をしました。Grafana Lokiはバージョンアップ時に手こずりましたが、使用していないautoscaleの機能も削除することができました。以下エラーの対応方法を個人wikiにまとめたので参考にしてみてください。
MySQL8化は今回ここでは詳しく話しませんが、Azure DMSを利用して各サービスのDBを一つずつバージョンアップしていきました。
- Grafana v10.0.2
- Helmfile化
- Grafana Loki v2.9.2
- Alertmanager v0.26.0
- MySQL5.7から8に
まとめ
ここで紹介していないタスクもありますが、印象に残っているタスクをピックアップさせていただきました。8ヶ月経ってみて、入社直後は監視周りの改善やAKSバージョンアップまで様々な改善をしたなと感じております。もちろん今まで自分はAWS/ECSをメインに経験してきましたが、全く違う技術スタック(Azure/Kubernetes)でアウトプットを出せるようになったのはチームの皆さんとマネージャーのおかげです。
まだまだやりたいことはありますが、個人的にはSLI/SLOを推進して、エンジニア全体でモニタリングできるような文化を作り上げたいと思っています。引き続き、チームで改善したことはアウトプットしていきますので、またセンシンのQiitaでお会いしましょう!
※最後に「UGV遠隔操作ソリューションRemoteBase」を紹介をします!