はじめに
本エントリーは某社内で実施するデザインパターン勉強会向けの資料となります。
本エントリーで書籍「SQL アンチパターン」をベースに学習を進めます。書籍上でのサンプルコードはMySQLですが、本エントリーでのサンプルコードはT-SQLに置き換えて解説します。
ジェイウォークパターン とは
ジェイウォークパターンは、1つの列に複数の値を格納するアンチパターンです。たいていの場合「1対多の関係をサポートしたい」などの理由で利用されます。
例)他テーブルの主キー項目に紐づく値を、○○区切りのリストで格納する など
| product_id | product_name | account_id |
|---|---|---|
| 1 | Visual TurboBuilder | 12,34 |
| 2 | Visual TurboBuilder2 | 5,6,7 |
ジェイウォークパターン のデメリット
ジェイウォークパターンを利用することで、以下の操作でデメリットが発生します。
- 特定の値を持つ行の検索
- 紐づく値を持つテ-ブルとの結合
- 集約クエリの作成
- 特定の値を持つ列の更新
- 投入データの妥当性検証
また、データ構造上の以下の不具合も発生します。
- 区切り文字の識別
- 列の長さに起因するデータ格納上限
特定の値を持つ行の検索
外部キーにあたるデータを1つの列にまとめて格納すると、等価性による比較が行えません。そのため、パターンマッチを行う必要があります。
例)特定のaccount_idを持つ行を検索
SELECT * FROM Products
WHERE
account_id LIKE '%,12,%' -- カンマ区切りの内部に12を含む
このクエリは、以下の面から不適切です。
- 書き方によっては、意図した検索結果とならない
上の例では、先頭または末尾に12が含まれる場合が検索から漏れる
--正しい検索
SELECT * FROM Products
WHERE
account_id LIKE '%,12,%' -- カンマ区切りの内部に12を含む
OR
account_id LIKE '12,%' -- カンマ区切りの先頭に12を含む
OR
account_id LIKE '%,12' -- カンマ区切りの末尾に12を含む
- クエリが煩雑
- インデックスが適用されないので、検索が遅い
- クエリが利用するミドルウェアに依存する
例)MySQLのREGEXPはT-SQLでは利用不可
紐づく値を持つテ-ブルとの結合
[特定の値を持つ列の検索]と同じく、以下の面から不適切です。
- 書き方によっては、意図した結合結果とならない
- クエリが煩雑
- インデックスが適用されないので、検索が遅い
- クエリが利用するミドルウェアに依存する
集約クエリの作成
集約関数(COUNT, SUM, AVGなど)は、複数の行に対して利用される前提で設計されているため、1つの列に複数の値が含まれている場合は利用できません。
-- 例)集約関数を利用せずにproduct_id毎のaccount_idを集計
SELECT
product_id,
-- account_id列の総文字数からカンマを削除した文字数を引きカンマの文字数を算出
-- カンマの文字数+1が、格納されているaccount_idの数となる
LEN(account_id)-LEN(REPLACE(account_id, ',', '')) + 1 AS contacts_per_product
FROM Products
特定の値を持つ行の更新
列を文字列連結することで、新たな値を列の末尾に追加できますが、ソート順までは担保されません。
--例 )末尾に値をそのまま追加
UPDATE Products
SET account_id = account_id + ',56'
WHERE
product_id = '123'
実行前
| product_id | product_name | account_id |
|---|---|---|
| 1 | Visual TurboBuilder | 123 |
実行後
| product_id | product_name | account_id |
|---|---|---|
| 1 | Visual TurboBuilder | 123,56 |
値の削除には、元の値リストの取得と、更新したリストの保存の2操作が必要です。
CREATE PROCEDURE [dbo].[RemoveAccountId]
@product_id BIGINT, -- 対象のプロダクトID
@delete_account_id BIGINT -- 削除対象のアカウントID
AS
BEGIN
DECLARE @account_id as varchar(100)
DECLARE @new_account_id as varchar(100)
DECLARE @splited_account_id as varchar(100)
DECLARE @Delimiter VARCHAR(MAX) = ','
SET @new_account_id = ''
-- 古いリストの取得
SELECT
@account_id = account_id -- 変更対象のアカウントID群を全件取得
FROM Products
WHERE
product_id = 1
AND
(
account_id LIKE CONCAT('%', ',', cast(@delete_account_id as varchar), ',', '%') -- カンマ区切りの内部に削除対象のアカウントIDを含む
OR
account_id LIKE CONCAT(cast(@delete_account_id as varchar), ',', '%') -- カンマ区切りの先頭に削除対象のアカウントIDを含む
OR
account_id LIKE CONCAT('%', ',', cast(@delete_account_id as varchar)) -- カンマ区切りの末尾に削除対象のアカウントIDを含む
)
-- リストの更新
-- 共通テーブル式を利用し、カンマ区切り文字列を分割
DECLARE crList CURSOR FOR
WITH Split(stpos,endpos)
AS(
SELECT
0 AS stpos,
CHARINDEX(@Delimiter,@account_id) AS endpos
UNION ALL
SELECT endpos+1, CHARINDEX(@Delimiter,@account_id,endpos+1)
FROM Split
WHERE endpos > 0
)
SELECT
SUBSTRING(@account_id,stpos,COALESCE(NULLIF(endpos,0),LEN(@account_id)+1)-stpos) as Data
FROM Split
WHERE
-- 削除対象のアカウントIDを除く全件を取得
SUBSTRING(@account_id,stpos,COALESCE(NULLIF(endpos,0),LEN(@account_id)+1)-stpos) <> CAST(@delete_account_id as varchar)
OPEN crList
FETCH NEXT FROM crList INTO @splited_account_id -- 分割したデータ群をカーソルに格納
--
WHILE @@FETCH_STATUS = 0
BEGIN
SET @new_account_id = @new_account_id + @splited_account_id + ',';
FETCH NEXT FROM crList
INTO @splited_account_id;
END
CLOSE crList;
DEALLOCATE crList;
-- 末尾のカンマを削除
SET @new_account_id = LEFT(@new_account_id,LEN(@new_account_id)-1)
-- 更新したリストのテーブルへの反映
UPDATE Products
SET account_id = @new_account_id
WHERE
product_id = @product_id
AND
(
account_id LIKE CONCAT('%', ',', cast(@delete_account_id as varchar), ',', '%') -- カンマ区切りの内部に削除対象のアカウントIDを含む
OR
account_id LIKE CONCAT(cast(@delete_account_id as varchar), ',', '%') -- カンマ区切りの先頭に削除対象のアカウントIDを含む
OR
account_id LIKE CONCAT('%', ',', cast(@delete_account_id as varchar)) -- カンマ区切りの末尾に削除対象のアカウントIDを含む
)
END
GO
投入データの妥当性検証
複数の値を1列に格納する場合、たいていは文字列リストの形で格納することになります。そのため、列定義による無効文字の制限が利用できません。データの新規登録・更新時に煩雑な制御を掛けるか、無効文字の混在を許容することになります。
例)account_idに数字のみを格納するはずが、文字が紛れている
| product_id | product_name | account_id |
|---|---|---|
| 1 | Visual TurboBuilder | 12,34 |
| 2 | Visual TurboBuilder2 | 5,foo,7 |
区切り文字の識別
区切り文字によっては、格納されている値の区切り文字が項目の値と判別できない場合があります。
例)末尾の1,000は、1と0かもしれないし、1000を意図した打ち間違いかもしれない
| product_id | product_name | account_id |
|---|---|---|
| 1 | Visual TurboBuilder | 12,34,1,000 |
列の長さに起因するデータ格納上限
複数の値を1列に格納する場合、格納できるデータの個数は以下の2つに依存します。
- 列の長さ
- 格納する値の文字数
IDなどを格納する場合、IDに利用する数字が大きくなるほど(≒多く利用されるほど)格納できるデータ数は少なくなります。
例)account_idがvarchar(10)の場合
| product_id | product_name | account_id |
|---|---|---|
| 1 | Visual TurboBuilder | 1,2,3,4,5 |
| 2 | Visual TurboBuilder2 | 12345,6789 |
アンチパターンによらない解決策
ジェイウォークパターンは、以下の場合に利用されがちです。
- 1対多の関係をサポートしたい
この要望への対応法として、交差テーブルの作成が推奨されます。
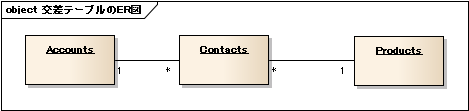
Productsテーブルに紐づけたいAccountsのID情報は、Contactsテーブルに格納します。ProductsまたはAccountsテーブルから、他方の情報を参照したい場合、検索対象のテーブルとContactsテーブルを結合し、これにもう片方のテーブルを結合することで実現できます。以下に、ジェイウォークパターンを利用した場合に生じた問題点がどう解消されたかを示します。
特定の値を持つ行の検索/紐づく値を持つテ-ブルとの結合
ProductsテーブルとContactsテーブルを結合し、これにAccountテーブルを結合することで実現できます。
-- 特定の値を持つ行の検索
SELECT p.*
FROM Products AS p
INNER JOIN Contacts AS c
ON
p.product_id = c.product_id
WHERE
c.account_id = 34
-- 紐づく値を持つテ-ブルとの結合
SELECT p.*
FROM Products AS p
INNER JOIN Contacts AS c
ON
p.product_id = c.product_id
INNER JOIN Accounts AS a
ON
c.account_id = a.account_id
WHERE
c.product_id = 123
このような設計とすることで、問題点は以下のように解決されます。
| 問題点 | 解消後 |
|---|---|
| パターンマッチの書き方によっては、意図した結合結果とならない | パターンマッチが不要なので、検索条件の不備が少ない |
| クエリが煩雑 | 等価性による検索が実施できるので、パターンマッチが不要 |
| インデックスが適用されないので、検索が遅い | インデックスが適用される |
| クエリが利用するミドルウェアに依存する | パターンマッチが不要なので、ミドルウェア依存が少ない |
集約クエリの作成
1行に1つのデータを格納し、複数の行で紐づきを表現しているので、集約関数が利用可能です。
-- 例)集約関数を利用しproduct_id毎のaccount_idを集計
SELECT product_id, COUNT(*) AS accounts_per_product
FROM Contacts
GROUP BY product_id
特定の値を持つ列の更新
交差テーブルへの追加・削除により実現できます。
--例 )紐づきを追加
INSERT INTO Contacts (product_id, account_id)
VALUES (456, 34)
--例 )紐づきを削除
DELETE FROM Contacts
WHERE
product_id = 456
AND
account_id = 34
投入データの妥当性検証
文字列による紐づきの表現を行わないため、SQLのデータ型による入力内容の制御が可能です。
また、ContactsテーブルからAccountsテーブルに外部キーを設定することで、Accountsテーブルに存在するデータのみを格納する制御を掛けることも可能です。
区切り文字の識別
文字列による紐づきの表現を行わないため、区切り文字の識別は不要になります。
列の長さに起因するデータ格納上限
文字列による紐づきの表現を行わず、個別の行で紐づきを表現するため、データ格納上限はほぼありません。
その他
交差テーブルの利用により、データの紐づきにさらに属性を付加することができます。
例)紐づきが発生した日付を付加
| product_id | account_id | update_date |
|---|---|---|
| 1 | 12 | 2000-01-01 00:00.000 |
| 1 | 34 | 2000-12-31 00:00.000 |
ジェイウォークパターンの利用が許容される場合
ジェイウォークパターンの利用が許容される場合もあります。
- 非正規化による、特殊なクエリのパフォーマンス向上のため
- ○○区切りリストの出力が必須で、かつテーブルに格納された○○区切りリストの個別要素の検索を行わない
ただし、非正規化目的での利用については、正規化データでの代用を十分に検討した後に実施したほうが良いでしょう。
まとめ
- ひとつひとつの値は個別の行・列に格納すべき