はじめに
こんにちは
自然言語処理の話をします。
自然言語処理の技術は近年急激に進化しています。2020年も色々躍進がありました。
いきなりそれらの技術を理解しようとすると挫折します。
今回は機械学習の入力に使われる自然言語をどうやって扱うか(ベクトル化)についてやっていきます。
また今回各所にpythonコードを書いています。
jupyter notebookやGoogle Colaboratoryで動きますので
ぜひ試してみて下さい。
用語の定義と使う文書集合について
本題に入る前に本記事で使う用語と言語資源について書きます。
本記事では文書と文書集合といった用語を用いますが最初はちょっと混乱すると思いますので定義します。
- 文書: 何らかの文字列 (QAサイトの一問、ニュース記事、Wikipediaの1記事 etc)
- 文書集合: 文書の集合 (QAサイトのページ、ニュースサイト、Wikipedia全文 etc)
文書や文書集合は例に上げているようにそれぞれの大きさはバラバラです。
それぞれWebサイトをクローリングしたり、自社のデータベースから取得したりして取得します。
自然言語処理にかけたい文書を集めること自体が困難なケースもままありますが・・・
今回利用する文書集合は青空文庫で公開されている本を使うことにしました。
また用いる文書は改行されるまでを文書とします。
以下のスクリプトでダウンロードできます。
(用意できる方は別なデータでも構いません。)
import urllib.request
from bs4 import BeautifulSoup
# 青空文庫 芥川龍之介著 「羅生門」
url = "https://www.aozora.gr.jp/cards/000879/files/127_15260.html"
data = urllib.request.urlopen(url)
soup = BeautifulSoup(data, 'html.parser')
# 本文のみを利用する
documents = soup.find('div', class_="main_text").get_text().split()
# 読みがなを削除する(作品によっては不要であったりするので元データを観察してみて下さい)
documents = [re.sub(r'(.*?)', '', line) for line in documents]
まずは単純なベクトル化手法であるBOWについて説明します。
BOWについて
BOWとはBag Of Wordsの略です。
日本語訳すると"単語のバッグ"です。
その名の通り大きなバッグの中に単語がガサっと入っているようなイメージです。
単語の前後の繋がり(係り受け)は無視されます。
そして単語のある無しでベクトルを作成します。
実際の行列を見たほうが理解が早いと思うのでpythonでコードを書いて実際にやってみます。
以下のコマンドで形態素解析機をインストールして下さい。
!apt install aptitude
!aptitude install mecab libmecab-dev mecab-ipadic-utf8 -y
!pip install mecab-python3>=1.0.3 ipadic
そしてBOWへの変換はscikit-learnを使えば以下のように書けます。
import numpy as np
import MeCab
from sklearn.feature_extraction.text import CountVectorizer
def parse_text(text):
tagger = MeCab.Tagger()
words = []
for c in tagger.parse(text).splitlines()[:-1]:
surface, feature = c.split('\t')
pos = feature.split(',')[0]
if pos == '名詞' or pos == '動詞':
words.append(surface)
return words
parsed_documents = [" ".join(parse_text(line)) for line in documents]
doc_array = np.array(parsed_documents)
cv = CountVectorizer()
bow = cv.fit_transform(doc_array)
features = cv.get_feature_names()
print('次元数:', len(features))
print('元の文書:', documents[0])
print('BOW変換後:',bow.toarray()[0] )
今回は名詞と動詞に限定してベクトル化します。
他に使いたくない単語(頻出語等)はストップワードとして登録する等がありますが今回は省略します。
実行すると以下のようになると思います。
行列の列はそれぞれ単語の計数の数を表しています。(この文書は複数回表示されている単語が無いので0と1しかありませんが・・・)
今回は462次元のベクトルとなったようです。
次元数: 462
元の文書: ある日の暮方の事である。一人の下人が、羅生門の下で雨やみを待っていた。
BOW変換後: [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
BOWの問題点について
BOWの問題として単純な単語の計数としているため、その単語が文書集合の中でどのくらい重要であるのか、
といった情報が欠録しています。
そのため単純に文書が長いほうが有利になると行った問題点があります。
そこで文書集合全体をみて重みをつけるTF-IDFが考案されました。
TF-IDFについて
TF-IDFはTerm Frequency - Inverse Document Frequencyの略です。
日本語訳すると"単語頻度と逆文書頻度"です。
簡単に説明すると文書の中で頻度の高い単語と文書集合の中で頻度が低い単語に重みをつける手法です。
こちらもscikit-learnで簡単にかけるので書いてみます。
from sklearn.feature_extraction.text import TfidfTransformer
tfidf = TfidfTransformer(use_idf=True, norm='l2', smooth_idf=True)
np.set_printoptions(precision=2)
tf_idf = tfidf.fit_transform(bow)
# IDFを確認する
print('元の文書:', documents[0])
print('TF-IDF 変換後:', tf_idf.toarray()[0])
今回の文書集合ではこんな感じになりました。
元の文書: ある日の暮方の事である。一人の下人が、羅生門の下で雨やみを待っていた。
TF-IDF 変換後: [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.47 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.21 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.51 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0.57 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0.39 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. ]
BOWとは違って別の重み付けになっていることが見てとれると思います。
TF-IDFの問題点について
BOWよりはましになったとはいえ、文書集合中に長い文書と短い文書が混在するようだと極端な扱いにくい
重みになってしまいます。
現在ではTF-IDFの式を少し変更したOkapi BM25が使われることが多いようです。
Okapi BM25について(wikipedia): https://ja.wikipedia.org/wiki/Okapi_BM25
Okapi BM25について簡単に説明すると文書集合の単語数の平均を加味することでこの問題を避けています。
ベクトルの類似度計算方法
今まで文書のベクトル化の手法についての話をしてきました。
ただ、ベクトル化するとどんな処理ができるかについてはほとんど解説していません。
ちょっと脱線して文書間の類似度の計算をどのようについてやるかについて解説します。
コサイン類似度
三角関数のコサインを覚えていますでしょうか?
コサインは三角形の二辺の成す角度が90°のときに値が0、0°のときに1となる関数です。
この角を挟む二辺がベクトルだったと考えましょう。
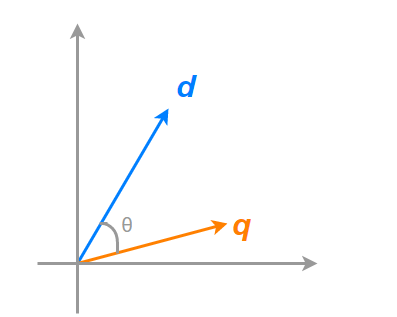
この場合、2つのベクトルの成す角度が0°の場合、ベクトルが重なるわけですから同じベクトルであるといえ、
2つのベクトルの成す角度が90°である場合、ベクトルは重ならないので別のベクトルであるといえます。
すなわち2つのベクトルの類似度はそのままコサインの値が使えます。
これがコサイン類似度です。
BOW, TF-IDFでのコサイン類似度計算
コサイン類似度の計算なのですが、こちらもsckit-learnを使えば簡単にかけます。
これまで書いたコードの下に以下のコードを追加して書いてみて下さい。
from sklearn.metrics.pairwise import cosine_similarity
print('cos類似度 BOW')
sim_bow = cosine_similarity(bow[0], bow)[0] #1行目との比較
bow_sim_top5 = np.argsort(sim_bow)[::-1][:5] #1行目との類似度上位5計算
for i in bow_sim_top5:
print("score: {:.2f} {}".format(sim_bow[i], documents[i]))
print()
print('cos類似度 TF-IDF')
sim_tfidf = cosine_similarity(tf_idf[0], tf_idf)[0]
tfidf_sim_top5 = np.argsort(sim_tfidf)[::-1][:5]
for i in tfidf_sim_top5:
print("score: {:.2f} {}".format(sim_tfidf[i], documents[i]))
結果は以下のようになります。
cos類似度 BOW
score: 1.00 ある日の暮方の事である。一人の下人が、羅生門の下で雨やみを待っていた。
score: 0.45 作者はさっき、「下人が雨やみを待っていた」と書いた。しかし、下人は雨がやんでも、格別どうしようと云う当てはない。ふだんなら、勿論、主人の家へ帰る可き筈である。所がその主人からは、四五日前に暇を出された。前にも書いたように、当時京都の町は一通りならず衰微していた。今この下人が、永年、使われていた主人から、暇を出されたのも、実はこの衰微の小さな余波にほかならない。だから「下人が雨やみを待っていた」と云うよりも「雨にふりこめられた下人が、行き所がなくて、途方にくれていた」と云う方が、適当である。その上、今日の空模様も少からず、この平安朝の下人の
score: 0.28 下人には、勿論、何故老婆が死人の髪の毛を抜くかわからなかった。従って、合理的には、それを善悪のいずれに片づけてよいか知らなかった。しかし下人にとっては、この雨の夜に、この羅生門の上で、死人の髪の毛を抜くと云う事が、それだけで既に許すべからざる悪であった。勿論、下人は、さっきまで自分が、盗人になる気でいた事なぞは、とうに忘れていたのである。
score: 0.26 下人の行方は、誰も知らない。
score: 0.23 下人は、老婆が死骸につまずきながら、慌てふためいて逃げようとする行手を塞いで、こう罵った。老婆は、それでも下人をつきのけて行こうとする。下人はまた、それを行かすまいとして、押しもどす。二人は死骸の中で、しばらく、無言のまま、つかみ合った。しかし勝敗は、はじめからわかっている。下人はとうとう、老婆の腕をつかんで、無理にそこへじ倒した。丁度、鶏の脚のような、骨と皮ばかりの腕である。
cos類似度 TF-IDF
score: 1.00 ある日の暮方の事である。一人の下人が、羅生門の下で雨やみを待っていた。
score: 0.29 作者はさっき、「下人が雨やみを待っていた」と書いた。しかし、下人は雨がやんでも、格別どうしようと云う当てはない。ふだんなら、勿論、主人の家へ帰る可き筈である。所がその主人からは、四五日前に暇を出された。前にも書いたように、当時京都の町は一通りならず衰微していた。今この下人が、永年、使われていた主人から、暇を出されたのも、実はこの衰微の小さな余波にほかならない。だから「下人が雨やみを待っていた」と云うよりも「雨にふりこめられた下人が、行き所がなくて、途方にくれていた」と云う方が、適当である。その上、今日の空模様も少からず、この平安朝の下人の
score: 0.14 広い門の下には、この男のほかに誰もいない。ただ、所々丹塗の剥げた、大きな円柱に、蟋蟀が一匹とまっている。羅生門が、朱雀大路にある以上は、この男のほかにも、雨やみをする市女笠や揉烏帽子が、もう二三人はありそうなものである。それが、この男のほかには誰もいない。
score: 0.11 下人には、勿論、何故老婆が死人の髪の毛を抜くかわからなかった。従って、合理的には、それを善悪のいずれに片づけてよいか知らなかった。しかし下人にとっては、この雨の夜に、この羅生門の上で、死人の髪の毛を抜くと云う事が、それだけで既に許すべからざる悪であった。勿論、下人は、さっきまで自分が、盗人になる気でいた事なぞは、とうに忘れていたのである。
score: 0.10 それから、何分かの後である。羅生門の楼の上へ出る、幅の広い梯子の中段に、一人の男が、猫のように身をちぢめて、息を殺しながら、上の容子を窺っていた。楼の上からさす火の光が、かすかに、その男の右の頬をぬらしている。短い鬚の中に、赤く膿を持った面皰のある頬である。下人は、始めから、この上にいる者は、死人ばかりだと高を括っていた。それが、梯子を二三段上って見ると、上では誰か火をとぼして、しかもその火をそこここと動かしているらしい。これは、その濁った、黄いろい光が、隅々に蜘蛛の巣をかけた天井裏に、揺れながら映ったので、すぐにそれと知れたのである。この雨の夜に、この羅生門の上で、火をともしているからは、どうせただの者ではない。
BOWとTF-IDFでスコアや順位が異なりますね。
BOWはやはり長い文書が有利になりがちですが、TF-IDFは"下人"が文書集合中の頻出単語であるため、IDFが低くなっているようです。
BOW, TF-IDFの問題点
さてBOW、TF-IDFといった手法でどのような問題点があるかというと
それぞれ単語自体の類似はわからないといった問題があります。
そこで離散的な次元でなく、連続的な次元に単語を射影するといった試みが行われてきました。
このアプローチで成功した事例がWord2vecです。
Word2Vec
Word2Vecを簡単に説明すると単語をベクトルにマッピングする技術です。
BOWやTF-IDFでは文書集合中に出てきた単語はそれぞれ別の次元としてマッピングされていました。
なので文書同士の比較はできても単語同士の比較はできませんでした。
Word2Vecでは同じ次元にマッピングします。
これにより、単語同士の類似度を求めることができます。
動作原理をざっくり説明します。(詳しくはぜひ検索して見下さい)
BOWの説明では単語のつながりは無視してバッグに入れるといった説明をしました。
Word2Vecでは以下の2つのモデルを使います
- 前後の単語の連なりから来る単語を予測する(CBOW: Continus Bag Of Words)
- 単語から前後の単語の連なりを予測する(Skip-gram)
この2つをニューラルネットワークを利用して学習したものの重みを使うことによってWord2Vecは
実現されています。
簡単に言うと"狼が家畜した動物はXXXである"のXXXを当てるといった作業とXXXから狼、家畜、動物を当てる
ような学習を行います。
こちらも実際にやってみましょう。まずgensimをupgradeします。
pip install --upgrade gensim
通常WikiPediaのような巨大な文書集合で学習を行ったりするのですが、学習のために自分で用意した例の文書集合を使ってみます。
sizeを200(射影する次元数),min_countを5(学習する単語の最低頻度),windowを5(前後5単語を見る)
としています。
from gensim.models import word2vec
words_list = [parse_text(line) for line in documents]
model = word2vec.Word2Vec(words_list, size=200,min_count=5,window=5)
作成された単語のベクトルを見てみましょう.
model.wv["下人"]
結果はこんな感じです。BOWやTF-IDFと違いスパースなベクトルでないことが見てとれると思います。
array([ 9.07e-04, -1.01e-03, 4.41e-04, 6.04e-04, 1.54e-03, 4.16e-04,
2.15e-03, -4.62e-04, -2.46e-04, -1.08e-03, -1.71e-03, 1.33e-03,
1.89e-03, -2.32e-03, -1.97e-03, -1.87e-03, 2.72e-03, -2.64e-03,
1.32e-03, 1.68e-03, 6.25e-04, -8.69e-04, -9.66e-04, -1.50e-03,
1.99e-03, -1.56e-03, 1.98e-03, -1.44e-03, -1.45e-03, 2.31e-03,
4.03e-04, -7.59e-04, -2.03e-03, -6.47e-04, -3.46e-04, 5.33e-05,
-4.87e-04, 2.11e-03, 6.16e-04, 1.48e-03, -2.28e-03, -2.67e-03,
-1.24e-03, 1.61e-03, 7.38e-04, 1.42e-03, 1.70e-03, -1.69e-03,
-1.34e-03, 2.38e-03, -1.12e-03, -6.97e-04, -2.66e-03, 4.19e-04,
1.26e-03, -2.17e-03, -1.40e-03, 1.41e-03, 1.87e-03, 2.00e-03,
1.53e-03, 3.73e-04, 1.38e-03, -4.63e-04, -2.40e-03, 1.06e-03,
-1.79e-03, -6.33e-04, -2.17e-03, 1.91e-03, -2.00e-03, 1.70e-03,
8.74e-04, -2.51e-03, 1.28e-03, -1.92e-05, 1.75e-03, -8.69e-04,
-2.16e-03, 7.66e-04, 6.74e-04, -1.46e-03, 1.03e-03, 1.93e-03,
-2.15e-03, -7.70e-04, -2.70e-03, 5.16e-04, 1.16e-03, -1.64e-03,
-9.70e-05, 1.25e-03, 2.57e-03, -2.25e-03, -2.03e-03, 1.31e-03,
-1.41e-03, 2.03e-03, -1.39e-03, -2.81e-03, 2.44e-03, -2.59e-03,
2.25e-04, 1.90e-03, 9.62e-04, 2.03e-03, -1.69e-03, -1.78e-03,
1.04e-03, -2.57e-03, 2.24e-03, -6.33e-04, 4.83e-04, 2.04e-03,
-6.15e-04, -1.41e-03, 6.49e-04, 5.43e-04, -1.34e-03, -6.06e-04,
2.24e-03, 2.55e-04, 1.54e-04, -2.48e-03, -1.46e-03, -1.26e-03,
-2.03e-03, -7.37e-04, 9.71e-04, -2.37e-03, 1.98e-03, 3.85e-04,
3.88e-04, -2.17e-03, -7.80e-05, 1.19e-03, 1.41e-03, 1.82e-03,
-4.96e-04, 4.15e-04, -1.35e-03, -1.02e-03, -3.01e-04, -7.21e-04,
1.58e-03, -1.68e-03, -1.21e-03, -1.65e-03, 1.24e-03, -9.10e-04,
-1.26e-03, 1.04e-03, -2.19e-03, 1.67e-03, 2.14e-03, -2.28e-03,
-6.61e-05, 1.27e-03, 5.27e-04, -1.78e-03, -2.46e-03, 1.97e-04,
-2.32e-03, -2.10e-03, 1.43e-03, -1.74e-03, -5.92e-04, 4.64e-04,
-2.07e-03, -3.15e-04, -2.45e-03, 1.16e-03, 2.26e-03, -7.14e-04,
1.66e-03, 2.26e-03, 1.20e-03, 4.06e-04, 2.59e-03, 9.26e-05,
1.91e-03, 1.10e-03, -2.19e-04, 8.31e-04, -6.25e-04, -2.09e-03,
-1.47e-03, -1.90e-04, -1.57e-03, 1.37e-03, 1.21e-03, 9.01e-04,
1.48e-03, 1.79e-03, 2.04e-03, 1.53e-03, 1.11e-03, -1.27e-03,
7.40e-04, -8.48e-04], dtype=float32)
ただ、今までと違ってベクトルを単体を見て何かわかるって感じでは無いですね・・・
他のベクトルと比べて確認しましょう。コサイン類似度を使って他の単語との類似度を見ます。
コードはこんな感じです。
sim_words = model.wv.similar_by_word("下人", topn=5)
#コサイン類似度の上位5単語を算出
print(*sim_words,sep="\n")
結果はこんな感じです
('火', 0.2055829018354416)
('勇気', 0.16842660307884216)
('上っ', 0.1525217741727829)
('男', 0.1379103660583496)
('鴉', 0.13509711623191833)
文書が足りないのかあまり良い結果ではありませんね・・・
ただ"下人"の周辺語や"男"といった単語が取れているのが見てとれます。
Word2Vecの問題点
先の部分での説明の通り、Word2Vecは前後の単語から予測するといったことを行います。
なので同じ文脈で使われる単語について同じだと認識してしまいます。
また同じ多義語として使われるような単語についてもあまり良い学習ができません。
対策としては学習に用いる文書集合のトピックを限定するなどありますが、効果についてはやってみなくてはわからない
といった感じです。
なのでWord2vecも決して万能ではありません。
日本語WordNetやConceptNet等の類義語辞書も必要に応じて使っていきましょう。
(もちろん手動での類似語辞書の拡張は必須です)
未来へ
今回の記事は自然言語処理のベクトル化についてまとめました。
これらベクトルを利用して機械学習や検索等が行われています。
ここから自然言語処理の機械学習について学ぶのであれば
CNN, RNN, LSTM, Attention, BERTといった順序で学ぶとわかりやすいと思います。
近年、自然言語処理は計算機のパワーに依存するようなことが多くなりましたが、
何らかのドメインやトピックに特化した文書を持っていることも非常に大事です。
皆様も今回の例で使った文書を増やしてみたり、別の本をにしたり等して色々実験してみて下さい。
何かしらの理解の助けになれば幸いです。
それでは皆様良い自然言語処理ライフを。