はじめに
AWSの機械学習サービスであるAWS RekognitionのDetectLabels APIを使ってみました。
簡単に物やシーンの識別が出来るみたいなので簡単な画像抽出アプリを作成・使用してみました。
AWS Rekognitionとは?
AWSが提供している機械学習サービスで、画像分析やビデオ分析等の画像認識が手軽に行うことができます。
具体的には、以下のようなAPIが提供されています。
- DetectLabels API(画像から物体やシーンを検出)
- DetectFaces API(画像から人間の顔の表情やパーツの配置を検出)
- CompareFaces API(2つの顔画像の類似率を算出)
- IndexFaces/SearchFacesByImage API(顔画像にインデックスを貼り付け、検索することが可能)
DetectLabels APIとは?
DetectLabels API を利用すると、画像から識別した車、ペット、家具など、数千もの物体にラベルを付け、信頼スコアを取得できる
信頼スコアは 0~100 の値で示され、識別結果が正しいかどうかの可能性を意味する
AWS Rekognitoion Black beltより引用
上記の引用の通り、入力画像からラベリングを行えるAPIで、マネジメントコンソールからも以下の様にラベリングの結果を確認することができます。
3匹の猫がしっかり識別されていることがわかりますね!
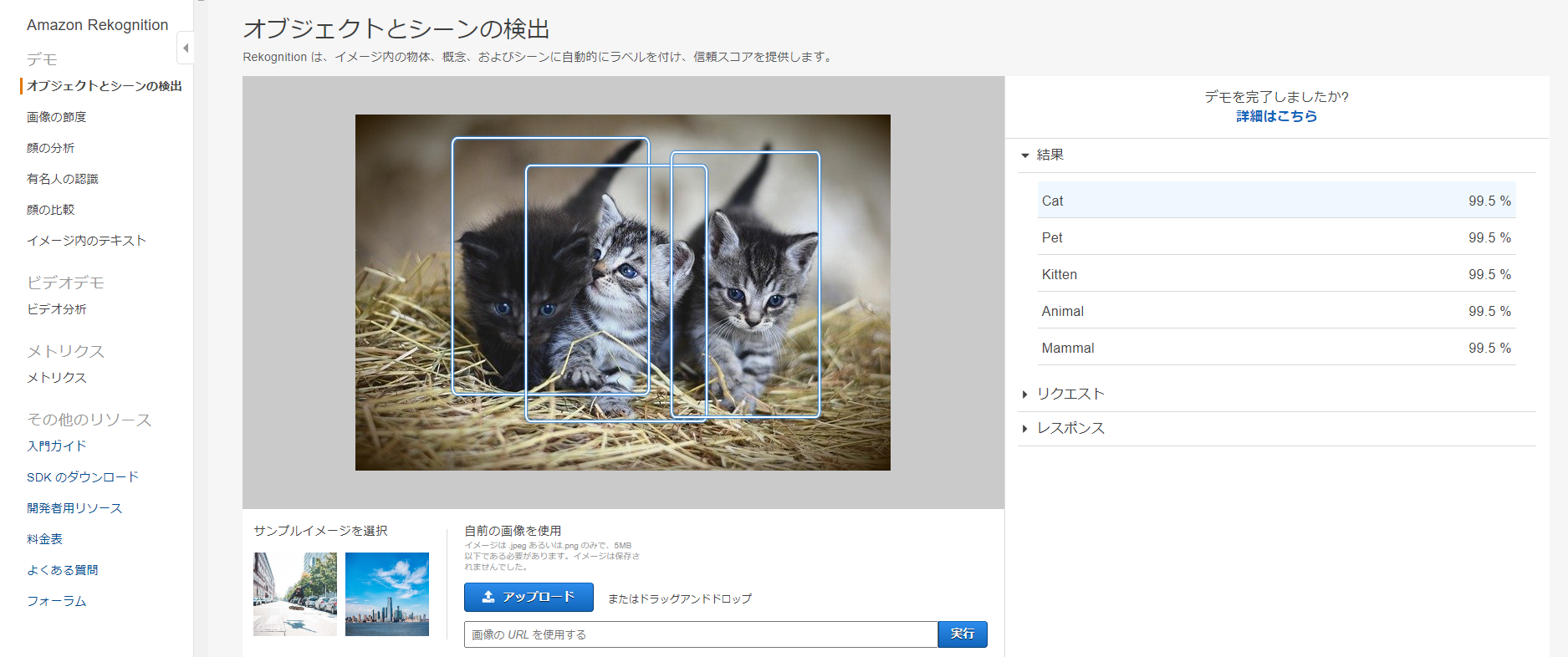
※入力した猫画像はbixabayより取得
DetectLabels APIへのリクエストは、上記の猫画像を入力例に以下の通りで、
{
"Image": {
"Bytes": "(入力画像のバイト列)"
}
}
レスポンスとしては、以下のJSONを返します。構造としては、ラベル情報の配列で、ラベル情報は以下の物を持っています。
- ラベル名
- ラベルの信頼度
- ラベルと識別した入力画像の範囲(0.0~1.0)
- そのラベルの親ラベル情報
{
"Labels": [
{
"Name": "Cat",
"Confidence": 99.57831573486328,
"Instances": [
{
"BoundingBox": {
"Width": 0.369978129863739,
"Height": 0.7246906161308289,
"Left": 0.17922087013721466,
"Top": 0.06359343975782394
},
"Confidence": 92.53639221191406
},
{
"BoundingBox": {
"Width": 0.3405080735683441,
"Height": 0.7218159437179565,
"Left": 0.31681257486343384,
"Top": 0.14111439883708954
},
"Confidence": 90.89508056640625
},
{
"BoundingBox": {
"Width": 0.27936506271362305,
"Height": 0.7497209906578064,
"Left": 0.5879912376403809,
"Top": 0.10250711441040039
},
"Confidence": 90.0565414428711
}
],
"Parents": [
{
"Name": "Mammal"
},
{
"Name": "Animal"
},
{
"Name": "Pet"
}
]
},
{
"Name": "Pet",
"Confidence": 99.57831573486328,
"Instances": [],
"Parents": [
{
"Name": "Animal"
}
]
},
{
"Name": "Kitten",
"Confidence": 99.57831573486328,
"Instances": [],
"Parents": [
{
"Name": "Mammal"
},
{
"Name": "Cat"
},
{
"Name": "Animal"
},
{
"Name": "Pet"
}
]
},
{
"Name": "Animal",
"Confidence": 99.57831573486328,
"Instances": [],
"Parents": []
},
{
"Name": "Mammal",
"Confidence": 99.57831573486328,
"Instances": [],
"Parents": [
{
"Name": "Animal"
}
]
}
],
"LabelModelVersion": "2.0"
}
作ってみる
作るもの
S3バケットにアップロードした画像からラベリングを行い、画像内のラベリングされた範囲を抽出し、他のS3バケットにその抽出した画像をタグ「ラベル名」=「信頼度」を付与して出力する物を作ってみました。
構成図
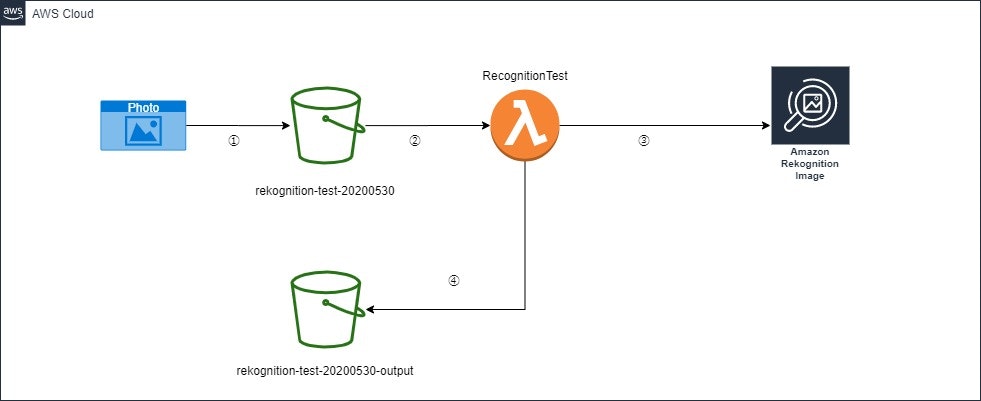
①.バケット「rekognition-test-20200530」に画像ファイルをアップロード
②.バケットのファイル作成イベントをトリガーにLambda「RecognitionTest」が起動
③.Lambda「RecognitionTest」はS3にアップロードした画像ファイルを入力にDetectLabel APIを呼び出す
④.Lambda「RecognitionTest」はDetectLabel APIのレスポンスを元に、
1. ラベルに対象範囲指定がついている物に対して、その対象範囲をアップロードした画像から抽出
2. 抽出した画像にS3のタグ「ラベル名」=「ラベルの信頼値」を付与
3. バケット「rekognition-test-20200530-output」に出力
各AWSリソースの設定
S3
| バケット名 | 設定 |
|---|---|
| rekognition-test-20200530 | ・バケットの作成 ・S3にファイル作成イベント時のLambda「RecognitionTest」へのトリガー設定 |
| rekognition-test-20200530-output | ・バケットの作成 ・Lambda「RecognitionTest」のIAM Roleに書き込み権限を与えるバケットポリシー追加 |
Lambda Layer
画像の抽出にPillowを使用しているため、こちらのブログを参考にLambda Layerを登録しました。
1.Amazon LinuxのEC2を起動
2.EC2上にPillowをインストール
3.Pillowをインストールしたフォルダをzip
4.zipファイルをダウンロードして、そのzipファイルをLambda Layerに登録
※ 今回の使ってみた記事ではPython2.7を使用しているため、pip install pillowでインストールしています。
Lambda
ランタイム:python2.7
# coding: utf-8
import json
import boto3
from PIL import Image
import uuid
from io import BytesIO
def lambda_handler(event, context):
# イベント発生したS3とオブジェクト取得
s3 = boto3.client('s3')
# イベント発生したバケット名
bucket = event['Records'][0]['s3']['bucket']['name']
# イベント発生したオブジェクトキー
photo = event['Records'][0]['s3']['object']['key']
try:
# S3イベント発生した画像ファイル取得
target_file_byte_string = s3.get_object(Bucket=bucket, Key=event['Records'][0]['s3']['object']['key'])['Body'].read()
target_img = Image.open(BytesIO(target_file_byte_string))
# 画像ファイルの幅と高さ取得
img_width, img_height = target_img.size
# Rekognitionクライアント
rekognition_client=boto3.client('rekognition')
# DetectLabels API呼び出しとラベリング結果取得
response = rekognition_client.detect_labels(Image={'S3Object':{'Bucket':bucket,'Name':photo}}, MaxLabels=10)
for label in response['Labels']:
# 範囲が指定されているラベルに対して、画像の抽出とS3への出力を行う
for bounds in label['Instances']:
box = bounds['BoundingBox']
# 画像の抽出範囲を決定
target_bounds = (box['Left'] * img_width,
box['Top'] * img_height,
(box['Left'] + box['Width']) * img_width,
(box['Top'] + box['Height']) * img_height)
# 画像の抽出
img_crop = target_img.crop(target_bounds)
imgByteArr = BytesIO()
img_crop.save(imgByteArr, format=target_img.format)
# S3のオブジェクトタグ指定
tag = '{0}={1}'.format(label['Name'], str(label['Confidence']))
# S3への出力
s3.put_object(Key='{0}.jpg'.format(uuid.uuid1()),
Bucket='rekognition-test-20200530-output',
Body=imgByteArr.getvalue(),
Tagging=tag)
except Exception as e:
print(e)
return True
使ってみた!
- 入力画像

※bixabayより
上記の入力画像(ファイル名はanimal5.jpg)をS3にアップロードしてみます。
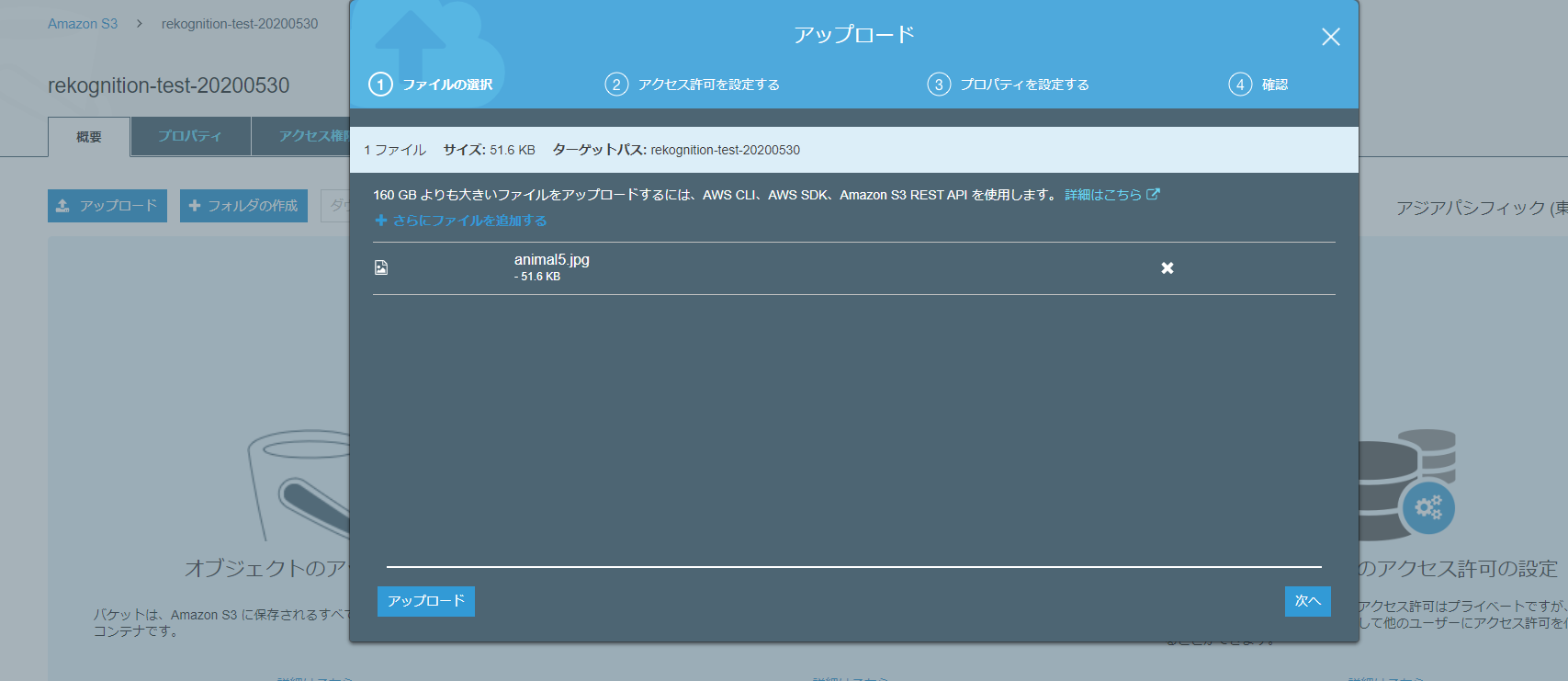
アップロードが完了しました。
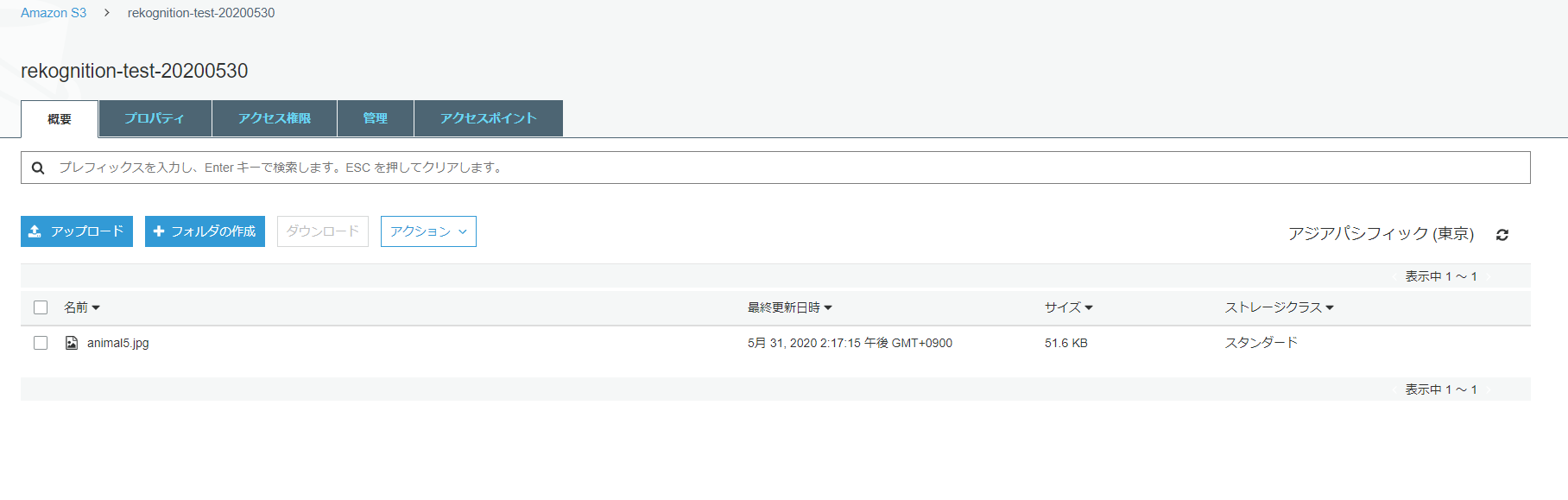
少し待って、S3に抽出した画像が出力されました!
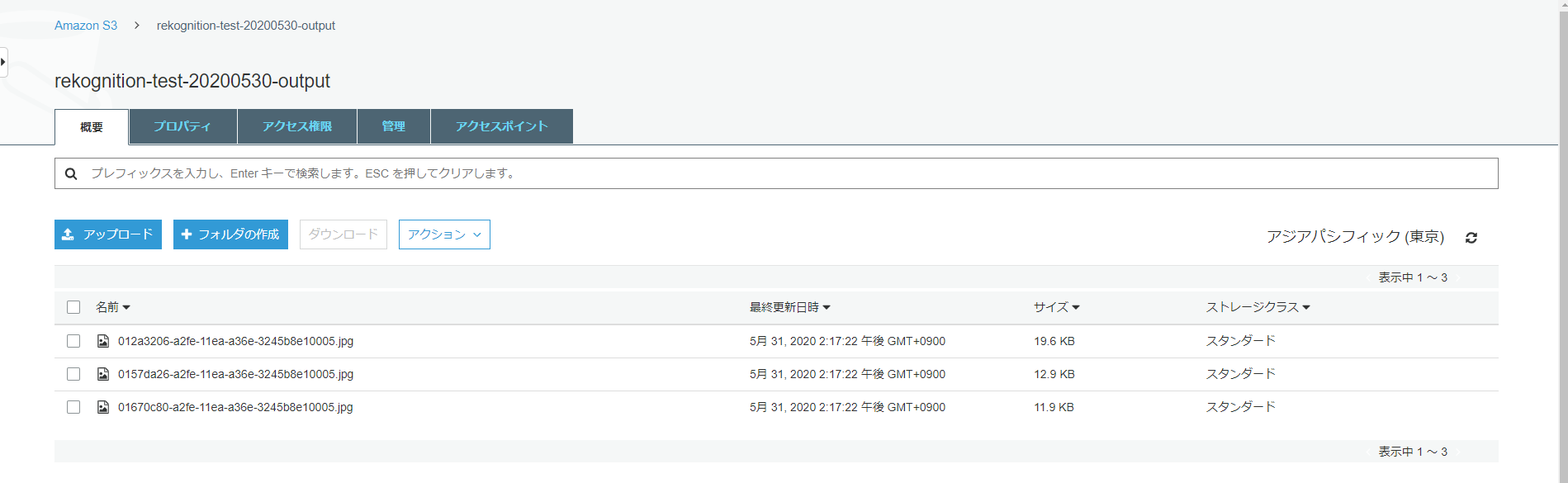
画像のタグを1つ確認してみましょう。
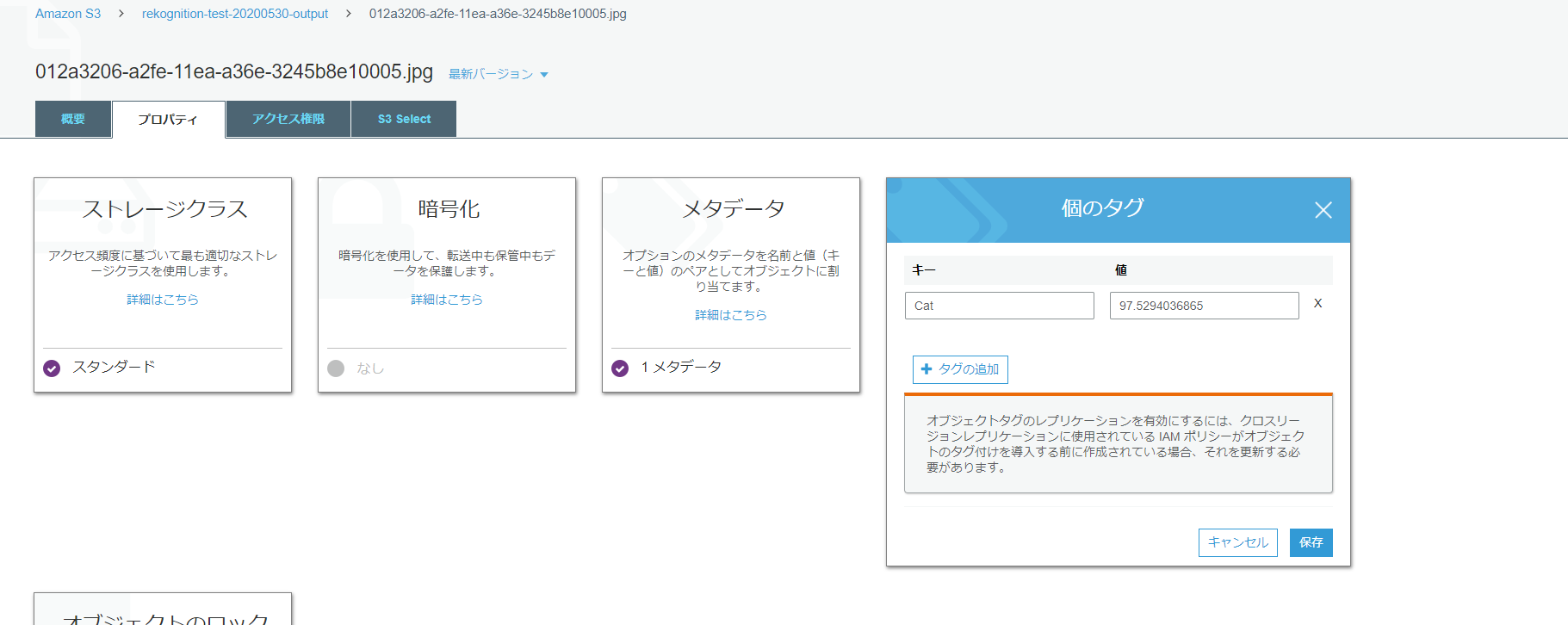
しっかり、タグ付けされてますね。
S3に出力された画像の中身をそれぞれ確認してみます。
-
012a3206-a2fe-11ea-a36e-3245b8e10005.jpg
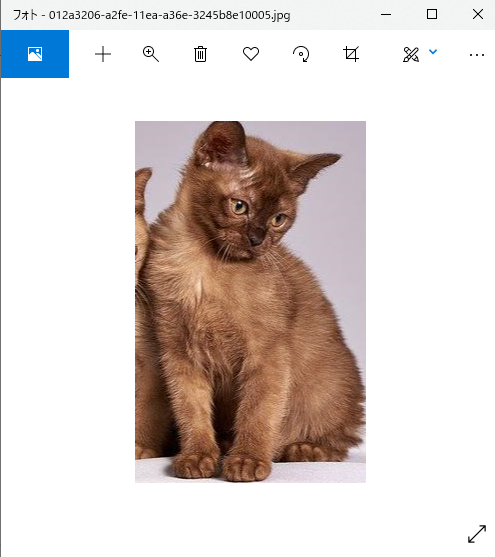
-
0157da26-a2fe-11ea-a36e-3245b8e10005.jpg
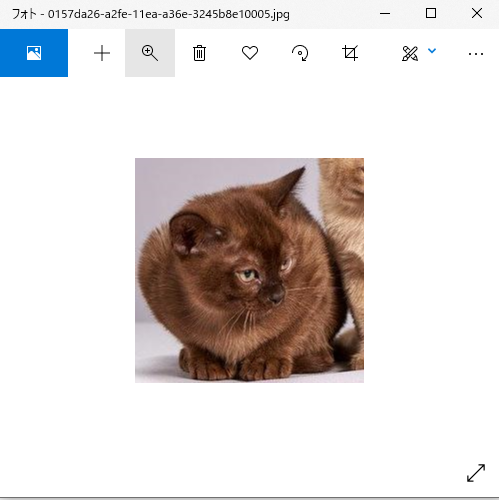
-
01670c80-a2fe-11ea-a36e-3245b8e10005.jpg
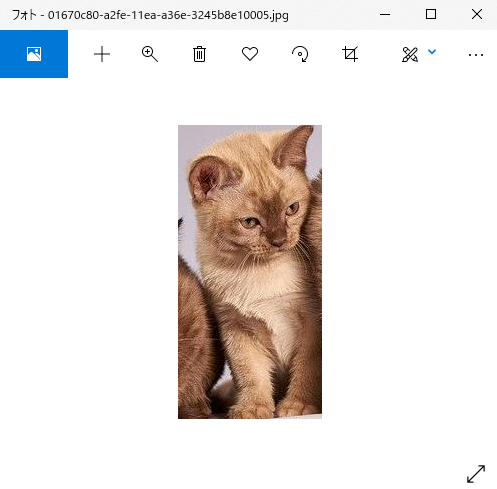
無事に抽出できました!