はじめに
しまうまプリントについて
しまうまプリントはネットプリントサービスを提供しており、複数のアプリやフロントエンドを通じて写真に関する注文を受け付けています。
2018年頃よりAWSを中心としたクラウド環境に移行しました。クラウド移行後は、ソフトウェアエンジニアが自らクラウドサービスを構築・運用する機会を増やし、より柔軟で効率的な開発体制の実現を目指しています。
オブザーバビリティへの取り組み
現在は、AWSを活用したインフラ環境のもとで、SREチームが主導となりオブザーバビリティの向上に取り組んでいます。特に、New Relicを活用し、システムの信頼性とパフォーマンス向上を目指して日々改善を続けています。本記事では、しまうまプリントの具体的な取り組み事例についてご紹介します。
New Relicへの移行
Datadogの運用と課題
AWSへの移行後は、当時知見を持っていたDatadogを導入しました。
Datadogを使用して以下の監視を行いました。
- マネージドサービス監視
- ログ監視
- APM(アプリケーションパフォーマンス監視)
EC2の監視については、IDCFクラウド時代から運用していたZabbixを引き続き利用していました。
運用を続ける中で、ログの増加によるコストの膨張が課題となり、APMの全システム展開もコスト面で難しい状況でした。
New Relicへの移行プロセス
New RelicはPOC(概念実証)から実施しました。結果として、New Relicへの移行がコスト効率と機能面で優れていると判断し、全監視の移行を決定しました。
- ログ基盤の移行
- 最初に、コストが最も高かったログ基盤を移行しました。
- リソース監視の移行
- AWSリソースの監視をDatadogからNew Relicに移行しました。Firehoseの転送先を変更するだけでスムーズに移行できました。
- Terraformの活用
- Datadogで利用していたTerraformをNew Relicでも継続利用し、効率的な構築を行いました。
- Zabbixの統合
- 最終的に、EC2の監視もNew Relicに統合しました。
事例紹介
リソース監視
AWSリソースのメトリクスをNewRelicに集約しました。

Firehoseの転送先をDatadogからNewRelicに変更するだけなので、スムーズに移行することができました。
https://docs.newrelic.com/jp/install/aws-cloudwatch/
実現方法
-
構築
推奨されているCloudFormationを選択するとcfnのテンプレートが準備されるので、画面の指示に従うだけで手早く構築することができます。

CloudWatchの特定の名前空間に絞ってメトリクスを収集したかったので、テンプレートをダウンロードしてカスタマイズしました。
また、AWSアカウント別にインテグレーション状況を確認するダッシュボードがあるので、メトリクスが想定通りに収集できているか確認するために利用していました。 -
ダッシュボード作成
NewRelicのpre-built dashboardを利用し、必要に応じカスタマイズします。 -
アラート設定
閾値を超えるとSlack通知するようなアラートポリシーを作成します。
一部Terraformのコードを表示する機能があるので、設定のコード化が容易でした。
ログ送信基盤
従来はEC2にデプロイされているアプリケーションのログをKinesis Data Streams+LambdaでDatadogに送信していましたが、移行に合わせてKinesis Firehoseに切り替えました。
■移行前
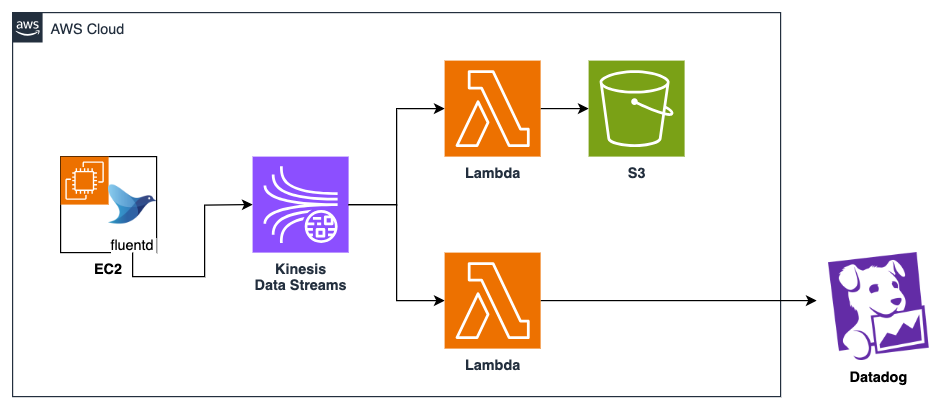
■移行後
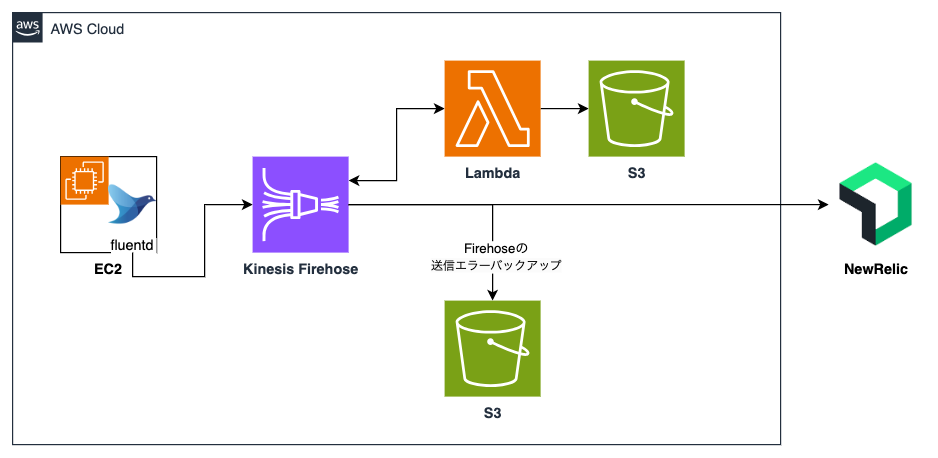
実現方法
-
EC2のfluentd設定
公式からKinesis用のプラグインが提供されているので、インストールして設定します。
NewRelicのLog APIの制約に合わせて対象のログは1MB以下にカット、圧縮してFirehoseに送信します。 -
データ変換Lambda
ログを整形するためのLambdaを作成します。
FirehoseへのアクセスとS3へのPUTを許可するポリシーを付与します。
S3へはAthenaの分析に利用するデータに変換したものをPUTしています。
Firehoseへは仕様に則った値を返さなければならないので、注意が必要です。 -
Firehoseの設定
NewRelicのLog APIの制約に合わせてバッファを1MBにして、GZIP圧縮に設定します。
データ変換Lambdaを実行するためのポリシーを付与して、作成したLambdaを紐づけます。
パラメータのキー/値を設定するとNewRelicのログレコードにタグとして反映されるので、ログの絞り込み(検索)がしやすくなります。
FirehoseからNewRelicへ送信するログが多くなるとスロットリングが発生してしまうことが判明したので、スループットクォータの引き上げを行いました。
Opsgenie連動の仕組み
ITシステムの監視・運用では、障害発生時に迅速な対応が求められます。今回、New RelicとOpsgenieを連携させ、特定の障害が発生した際にオンコール担当者の電話が鳴る仕組みを構築しました。

実現方法
-
New Relicのアラート設定
New Relicで障害のアラートポリシーを作成します。
デフォルトで全アラートはSLACK通知するようにしているのですが、即応が必要なアラート(例: 外形監視)のみopsgenieタグを設定します。
そして、opsginieタグのあるアラートのみopsgineへ連携するようにしました。 -
OpsgenieとNew Relicの連携
OpsgenieにNew Relic Integrationを設定します。 -
オンコールルールの設定
Opsgenieでオンコールスケジュールを設定し、特定のアラートが発生した場合にオンコール担当者に通知が届くようにします。電話通知を有効にするには、通知ルールで「電話」を最優先に設定します。 -
テスト実施
実際にアラートが正しくトリガーされ、電話通知が機能するかをテストします。
テストでは、アラート通知チャネルでテスト通知の送信を使用しました。
効果
この仕組みにより、以下のようなメリットを得られました。
- 重大な障害時にオンコール担当者が確実に気づける
- 問題の初動対応が迅速化
- チーム全体の安心感向上
まとめ
New RelicとOpsgenieを組み合わせることで、オンコール体制を強化し、システムの信頼性を高めることが可能です。特に、電話通知は障害対応における即応性を向上させるため、運用現場で非常に有用です。
今後の展望
SREチーム内でのNew Relic活用は進展しており、今後は開発チームへの展開を進める予定です。APMを開発段階から活用し、アプリケーションの品質向上を目指していきます。