Aidemy premium planを受講しているa_b_eと申します。
普段は、IT関係とは接点のない仕事をしていますが、体調を崩し休職している間の時間を使って興味のある分野を勉強しようと思い受講しています。
Aidemyでは学習プログラムの中に学んだ事をブログ等の記事にするというのがありまして、何を書こうかと思い身近で自身の興味があるテーマがいいなというわけで
テーマは「福岡ブラックホール説をデータ分析してみた」
私が住んでいる福岡は転勤で来る人が「福岡住みやす過ぎて前の所に戻れないwww」と言って定住してしまう「福岡ブラックホール説」がまことしやかに言われています。
参考:西日本新聞「転勤者飲み込む「福岡ブラックホール」 力の源は食にあり」
確かに周りにもブラックホールに飲み込まれてしまった人はいるのですが、この福岡ブラックホールは今後どれだけ人口を吸収していくのか?
福岡ブラックホールはこのまま人口を吸収し続け日本を吸収してしまわないか???
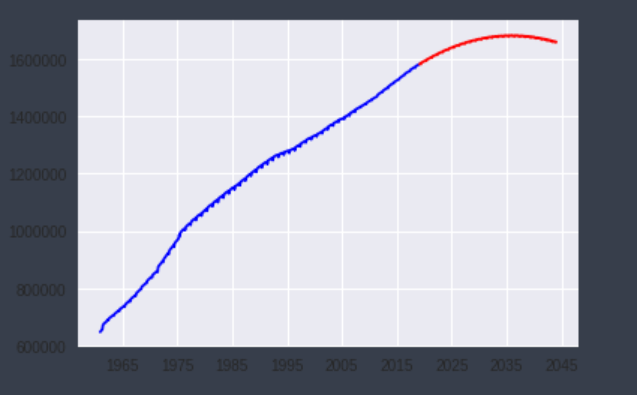
というのは杞憂でこの記事で行った分析結果では160万人を超えたあたり頭打ちになりました。
以下、福岡ブラックホール説の謎を解く!
データ集め~スクレイピング~
Aidemyや他の機械学習系の本ではデータ分析に使うデータはある程度綺麗にまとまっているものがほとんどだと思いますが、この課題では今後仕事に復帰した後にも使うであろうwebスクレイピングを使ってデータを集めたいと思います。
福岡県ではなく福岡市を選んだ理由は、福岡県内で一番人口が多くかつ人口増加傾向にあり、新聞等の記事で取り上げられるのが福岡市という事で選びました。
スクレイピングするサイトは福岡市の推計登録人口のページ
import requests
import time
import os
from bs4 import BeautifulSoup
# 対象のURL
urls = [
"http://www.city.fukuoka.lg.jp/soki/tokeichosa/shisei/toukei/jinkou/jinnkousokuhou.html"
]
# 取得したいファイル形式
extention = ".xlsx"
# URLの情報を取得
for url in urls:
download_urls = []
r = requests.get(url)
soup = soup = BeautifulSoup(r.content)
links = soup.find_all("a")
# URLの抽出
for link in links:
href = link.get("href")
#hrefの中から取得したいファイル形式だけ抽出
if href and extention in href:
download_urls.append(href)
print(href)
抽出結果
/data/open/cnt/3/13385/1/H3012suikeijinkou.xlsx?20181207144024
/data/open/cnt/3/13385/1/H3011suikeijinkou.xlsx?20181207144024
/data/open/cnt/3/13385/1/H3010suikeijinkou.xlsx?20181207144024
/data/open/cnt/3/13385/1/H3009suikeijinkou.xlsx?20181207144024
/data/open/cnt/3/13385/1/H3008suikeijinkou.xlsx?20181207144024
/data/open/cnt/3/13385/1/H3007suikeijinkou.xlsx?20181207144024
・
・
・
import urllib
# ファイルのダウンロード([始値:終値])
for download_url in download_urls[:32]:
# 一秒スリープ
time.sleep(1)
file_name = "http://www.city.fukuoka.lg.jp" + download_url
#?以降を取り除く
position = file_name.find("?")
file_name = file_name[:position]
# リクエスト成功
if r.status_code == 200:
#ダウンロード実行
#urllib.request.urlretrieve(''ダウンロード対象のURL, '保存先のパス')
urllib.request.urlretrieve(file_name, file_name[54:])
スクレイピングには手こずり、担任とslack上で多くのやり取りをして出来ました
手こずった一番の原因は、ファイルURLの.xlsx以下の?20181207144024が邪魔をしていた事でした
取得したExcelファイルから必要なデータを取り出したいわけですが、pandasのread_excelを使って読み込むとこんな感じで出力されました。
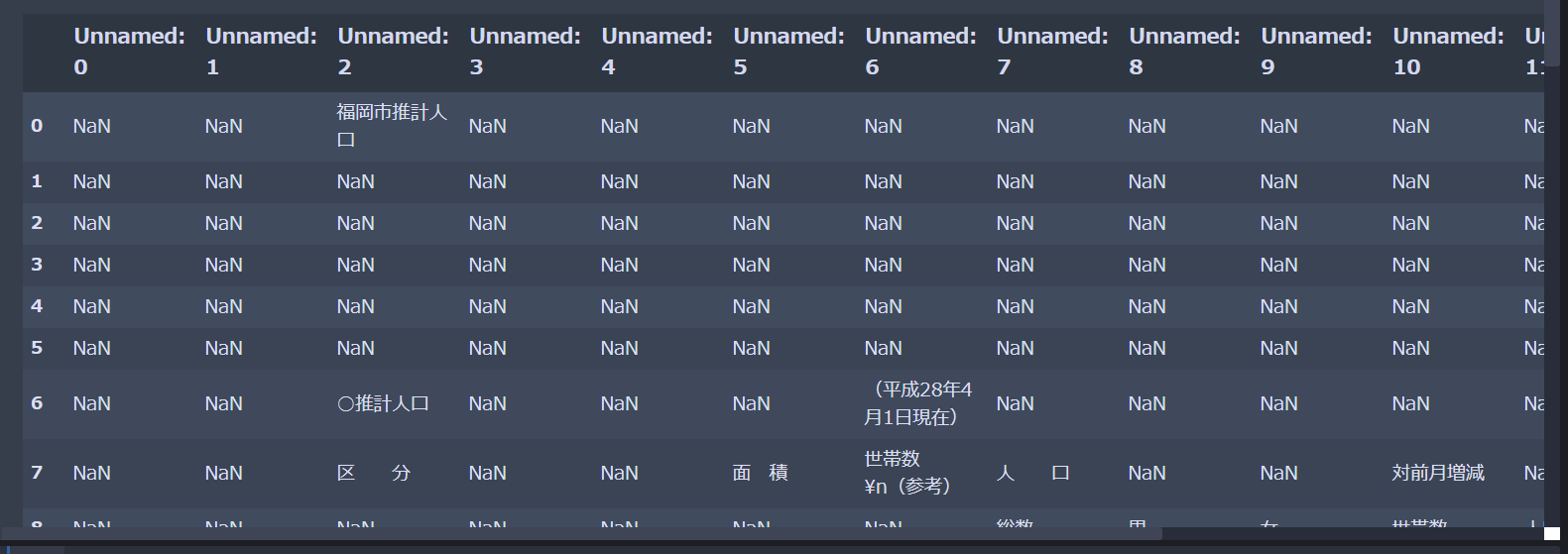
このExcelの中から必要な情報を取り出してDataFrameに格納したいけど難しい…
何もPythonにこだわらなくてもいいのでは??と思い仕事でも使っているExcelVBAで必要なデータを取得してデータの形を整える事にしました。
データ加工~ExcelVBA~
福岡市の人口統計Excelファイルの中身はこんな感じ

必要なデータは日付(セルG9)と人口総数(セルH14)
Sub 福岡人口()
'Excelの画面描写停止 気持ち動作が早くなるかも
Application.ScreenUpdating = False
Dim folder As String
Dim file As String
Dim book As Workbook
Dim i As Integer
i = 2
#フォルダの選択
With Application.FileDialog(msoFileDialogFolderPicker)
If .Show = True Then
folder = .SelectedItems(1)
End If
End With
file = Dir(folder & "\*.xlsx")
Do While file <> ""
Set book = Workbooks.Open(folder & "\" & file)
#コピーしたいセルを選択
ThisWorkbook.Worksheets("Sheet1").Range("A" & CStr(i)).Value = book.Worksheets("推計人口").Range("G9").Value
ThisWorkbook.Worksheets("Sheet1").Range("B" & CStr(i)).Value = book.Worksheets("推計人口").Range("H14").Value
file = Dir()
i = i + 1
book.Close
Loop
End Sub
参考引用:https://route40.me/excel-macro-shukei/
これで出来たものが
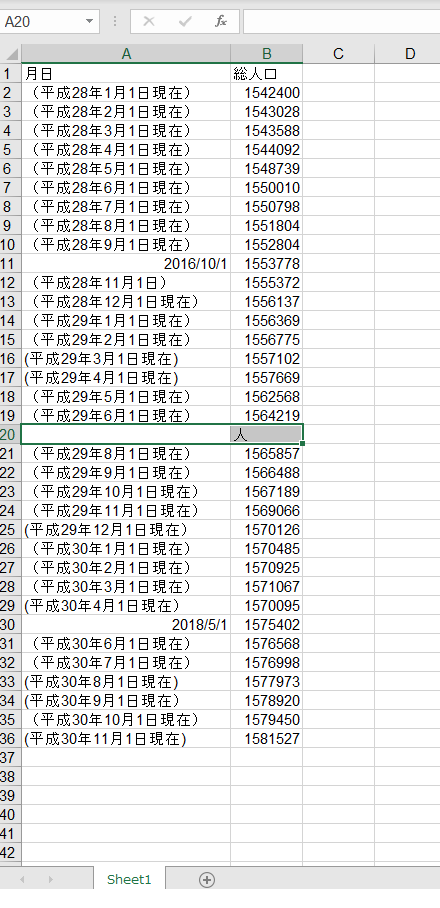
よく見ると平成29年7月分だけセルが1行ずれていて正しくデータを取得出来ていませんでした。
このままでは、データとして使えないので日付を「2018/11/1」の形に整え、人口数もユーザー定義の書式が適用されていたので、書式設定を数値にしてようやく機械学習がしやすいデータの完成
ここで注意したいのが、書式設定を数値にしていないとこの後データを読み込んだ際に数値を正しく読み込めずエラーが返ってくる。
時系列分析してみる
季節変動があるか確認してみる
import pandas as pd
import matplotlib.pyplot as plt
import statsmodels.api as sm
from pandas import datetime
import numpy as np
# データの読み込み
fukuoka_population = pd.read_excel("populationdata/fukuoka_population.xlsx",encoding="SHIFT-JIS")
# 季節調整とグラフのプロット
res = sm.tsa.seasonal_decompose(fukuoka_population,freq=12)
fig = res.plot()
plt.show()
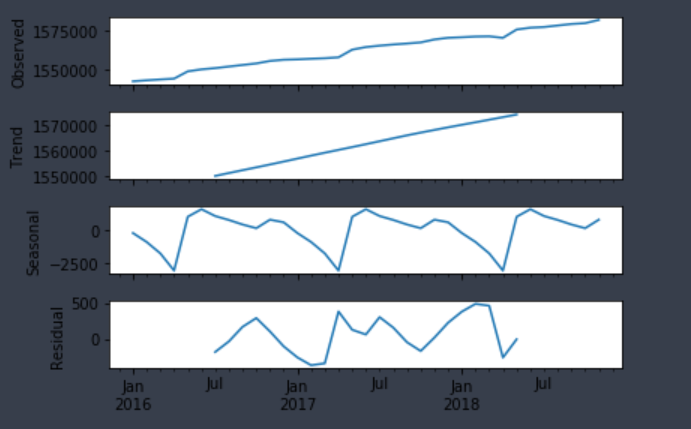
上から、原形列、トレンド、季節変動、不規則変動(残差)
季節変動は、4月の影響が大きいように見えるが10月の人口増も見逃せない
福岡ブラックホールが大きく成長する時期は4月と10月
季節変動がある事は分かったが福岡ブラックホールは今後どれだけ大きくなるのか、次は予測モデルを使って将来人口推計を出してみる。
SARIMAモデル
SARIMAモデルは中長期的予測が出来るモデルなので、これを使って今後の人口がどう推移するかを見てみる。
まずはSARIMAモデルのパラメータを決めるために、以下のコードで最適なパラメータを出してみる。
# パラメーターの決定
import warnings
import itertools
import pandas as pd
import numpy as np
import statsmodels.api as sm
# データの読み込みと整理
fukuoka_population = pd.read_excel("populationdata/fukuoka_population.xlsx",encoding="SHIFT-JIS")
index = pd.date_range("2016-01-01","2018-11-01",freq="M")
# 半年間分のデータにしています
fukuoka_population = fukuoka_population[:6]
# 関数の定義
def selectparameter(DATA,s):
p = d = q = range(0, 2)
pdq = list(itertools.product(p, d, q))
seasonal_pdq = [(x[0], x[1], x[2], s) for x in list(itertools.product(p, d, q))]
parameters = []
BICs = np.array([])
for param in pdq:
for param_seasonal in seasonal_pdq:
try:
mod = sm.tsa.statespace.SARIMAX(DATA,
order=param,
seasonal_order=param_seasonal)
results = mod.fit()
parameters.append([param, param_seasonal, results.bic])
BICs = np.append(BICs,results.bic)
except:
continue
return parameters[np.argmin(BICs)]
# 周期を埋めて最適なパラメーターを求める
selectparameter(fukuoka_population,6)
結果
[(0, 0, 0), (0, 1, 0, 6), nan]
出力されたパラメータの内容は左の括弧から
・モデルが直前0個の値を用いて予測される(自己相関度)
・時系列データを定常にするために0次の階差が必要(誘導)
・モデルが直前0個の値に影響を受ける(移動平均)
・モデルが直前0個の値を用いて予測される(季節性自己相関)
・時系列データを定常にするために1次の階差が必要(季節性導出)
・モデルが直前0個の値に影響を受ける(季節性移動平均)
s=6(パラメータの周期は6か月)
今回データの個数が32か月分しか無かったので周期は半年にしています。
ここで出力されたパラメータをモデルに当てはめてみます。
import pandas as pd
import matplotlib.pyplot as plt
import statsmodels.api as sm
from pandas import datetime
%matplotlib inline
import numpy as np
# データの読み込みと整理
fukuoka_population = pd.read_excel("populationdata/fukuoka_population.xlsx",encoding="SHIFT-JIS")
# モデルの当てはめ
SARIMA = sm.tsa.statespace.SARIMAX(fukuoka_population,order=(0, 0, 0),seasonal_order=(0, 1, 0, 6), enforce_stationarity = False, enforce_invertibility = False,trend = "n").fit()
# predに予測データを代入する
print(SARIMA.summary())
pred = SARIMA.predict()
forecast = SARIMA.forecast(100)
# predデータともとの時系列データの可視化
plt.plot(fukuoka_population)
plt.plot(pred, color="r")
plt.plot(forecast,color="g")
plt.ylim([1550000, 1600000])
plt.show()
結果
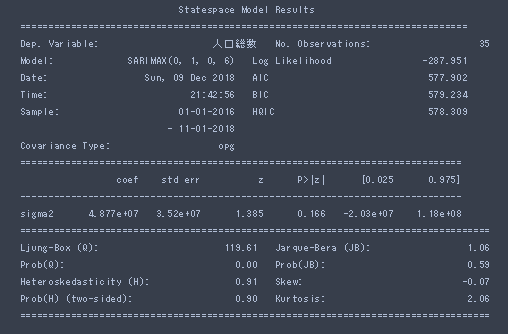
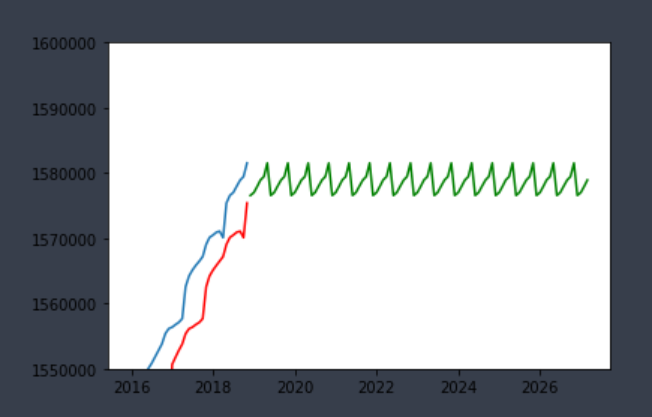
弁当に入ってるバランのような予測線になってしまいました。
データの個数も2016年~2018年11月までの35個と少なかったのが原因かもしれない
データを増やしてみた
なら、データを増やせばいいのではという事で昭和35年10月から平成30年12月までのデータを用意した。
福岡市過去の推計人口
http://www.city.fukuoka.lg.jp/soki/tokeichosa/shisei/toukei/jinkou/suikei.html
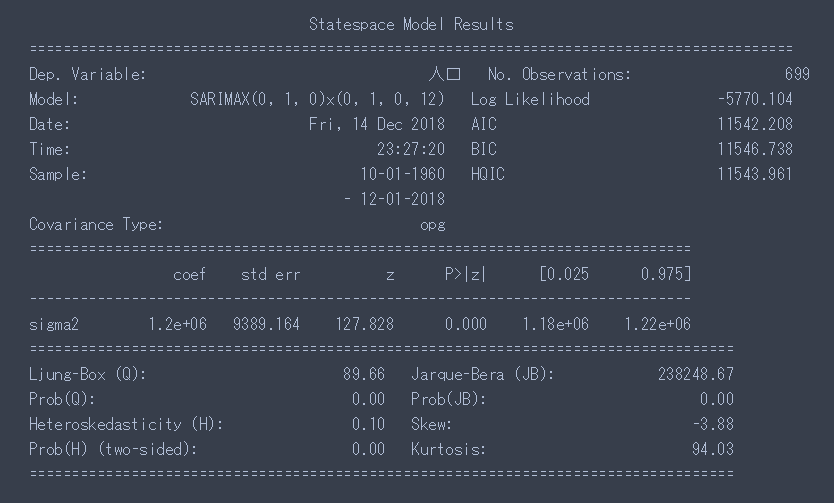
モデルのパラメータは(0, 1, 0), (0, 1, 0, 12)
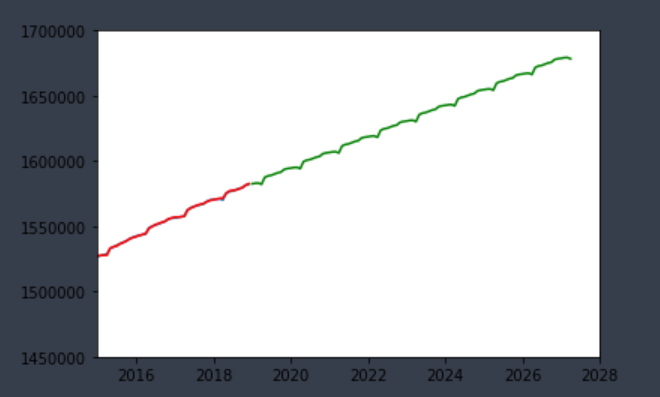
右肩上がりに上昇していますね
AIC、BICは数値が小さい程いいそうなので、このパラメーターではイマイチな模様
正規化してパラメーターを調整してみた
正規化してADF検定と自己相関係数まで行ってみる
import numpy as np
import pandas as pd
import statsmodels.api as sm
data = pd.read_csv("fukuoka.csv",encoding="SHIFT-JIS")
data = data.rename(columns={"年月":"date","人口":"population"})
data.index = data["date"]
del data["date"]
# 2回差分を取る
tmp = data["population"].diff()
tmp = tmp.diff()
# ADF検定
adf_result = sm.tsa.stattools.adfuller(tmp.fillna(method='bfill'),autolag='AIC')
adf = pd.Series(adf_result[0:4], index=['Test Statistic','p-value','#Lags Used','Number of Observations Used'])
print(adf)
# 正規化
medium = data["population"].mean()
std = data["population"].std()
data["population"] = (data["population"] - medium)/ std
ADF検定の結果
p値が0で p < 0.05なので単位根は無いと言える
参考:時系列データへの回帰分析
Test Statistic -21.733079
p-value 0.000000
# Lags Used 11.000000
Number of Observations Used 687.000000
dtype: float64
自己相関係数も見てみると
import statsmodels.api as sm
import matplotlib.pyplot as plt
%matplotlib inline
fig=plt.figure(figsize=(12, 8))
ax = fig.add_subplot(212)
sm.graphics.tsa.plot_acf(data["population"], lags=80,ax = ax)
plt.plot()
plt.show()
結果
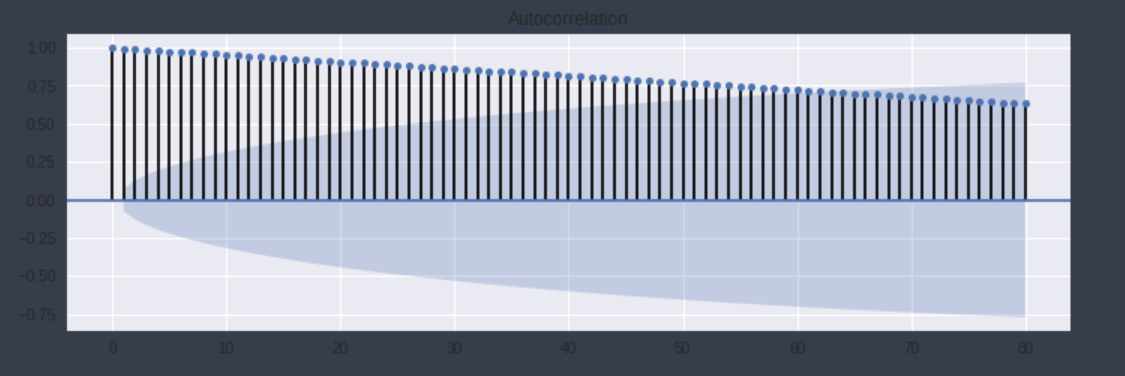
かなり前のデータが影響している様ですね
なるべく直近のデータの影響を受けるようにパラメータを調整し
・モデルが直前1個の値を用いて予測される(自己相関度)
・時系列データを定常にするために2次の階差が必要(誘導)
・モデルが直前1個の値に影響を受ける(移動平均)
・モデルが直前1個の値を用いて予測される(季節性自己相関)
・時系列データを定常にするために2次の階差が必要(季節性導出)
・モデルが直前1個の値に影響を受ける(季節性移動平均)
s=12(パラメータの周期は12か月)
(1,2,1)(1,2,1,12)で実行してみると結果は以下の通りになりました。
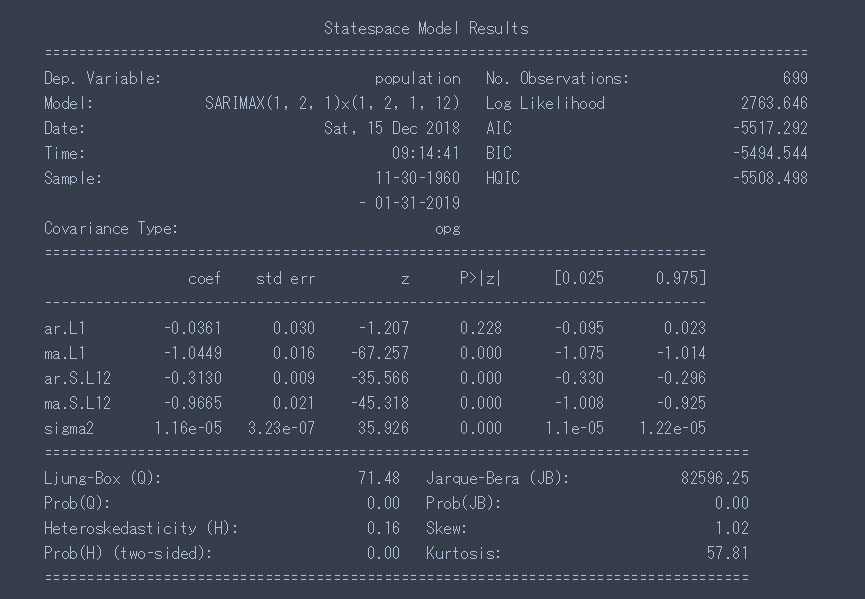
人口は160万人を超えはするが、その後人口は増えず緩やかに減少する結果になりました。
福岡市がコーホート要因法で予想しているような図に似た結果となりました。
結果
福岡ブラックホールは今後も勢力を強め拡大していき2023年あたりで160万人都市にはなりそうだがその後は緩やかに人口減少していく。
おわりに~機械学習を学んでみた感想~
一通りAidemyで機械学習の入り口を叩いてみた感想は、機械学習の世界奥深い…
まだまだ、機械学習の入り口にようやく立った程度なのでこれから仕事でも使えるように継続して学習していこうと思います。
後は、自身の数学的知識の足りなさは痛感しました笑
高校生の時に「数学なんてうるせ~~~!知らね~~~~~!!」と言ってろくに聞いていなかった代償が今になって帰ってきて、数学は勉強しなおそうというモチベーションに繋がりました。
今後はデータベースについても学んだりKaggle挑戦してみたりしたいと思います。