はじめに
ここのところ、Alteryxで色々なデータソースとつないでみています。
今回はRedshiftです。
Redshiftはビッグデータを扱うため、データを入れる方法としてInsert以外に、”S3においてあるファイルから読み込むCOPY”もありますが、それも対応していました。
Redshift
環境
VPC
RDSの時に作ったものを使います。
セキュリティグループ
Redshift用にインバウンドルールを許可します。

クラスターサブネットグループ
VPCを選んで、すべてのサブネットを追加するだけでした。


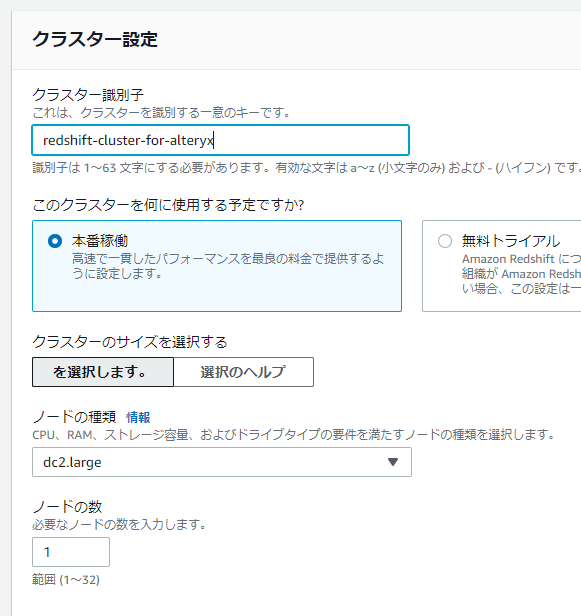
クラスター作成
なるべく安価になるように作っていきます。
追加設定でネットワークを指定します。
VPCとセキュリティグループ、先ほど作成したサブネットグループを指定します。

データベースはデフォルトのままで作ってもらいます。

これでクラスターを作成します。
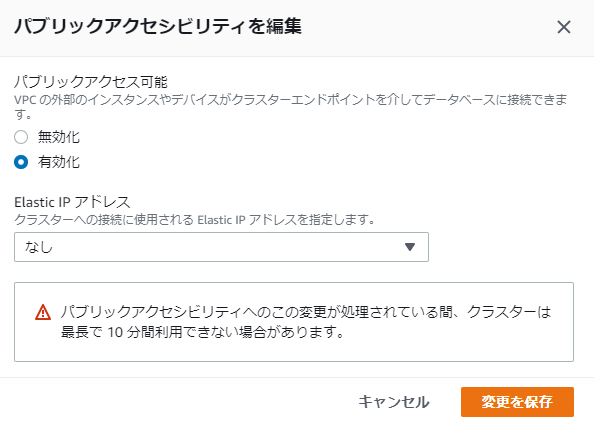
起動後に、クラスターにチェックを入れ、アクションからパブリックアクセス可能な設定を変更を選択し有効化します。
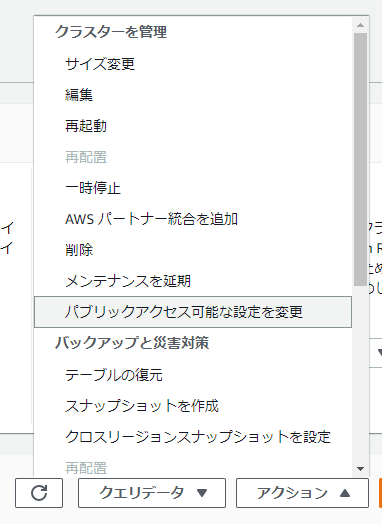
Elastic IPは未指定で問題なかったです。
ODBCドライバー
ドライバーは以下のページを参考にインストールできます。
Redshiftのエンドポイントは、一般的な情報の右に記載されています。
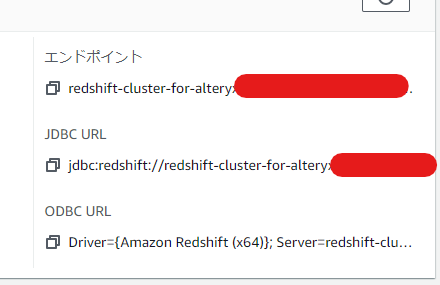
一番上のエンドポイントをコピーしましたが、末尾にポート番号とデータベース名がありますので、それら文字列をカットして使います。
設定値は以下の様になりました。Serverには、先ほど取得し文字列カットしたエンドポイントを設定します。

テーブル作成
Redshift query editorから、テーブルを作成します。
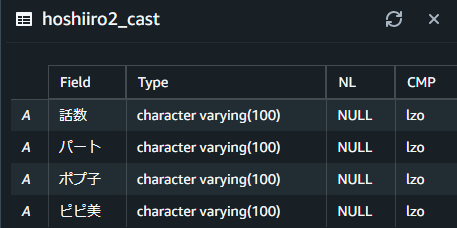
CREATE TABLE "public"."hoshiiro2_cast"(
話数 VARCHAR(100) ,
パート VARCHAR(100) ,
ポプ子 VARCHAR(100) ,
ピピ美 VARCHAR(100)
);

以下の様に作成されました。
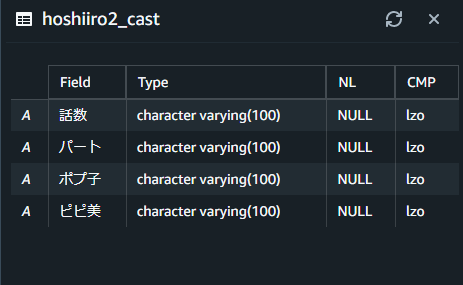
データも入れていきます。
INSERT INTO "public"."hoshiiro2_cast" VALUES
('第1話','前半','平野綾','茅原実里'),
('第1話','後半','井上和彦','堀川りょう'),
('第2話','前半','朴璐美','釘宮理恵'),
('第2話','後半','檜山修之','森川智之'),
('第3話','前半','大谷育江','犬山イヌコ'),
('第3話','後半','榎木淳弥','内田雄馬'),
('第4話','前半','潘めぐみ','伊瀬茉莉也'),
('第4話','後半','石丸博也','水島裕')
;
Redshift関連の準備はこれで完了です。
入力
Alteryxでデータ入力ツールをドラッグして、データソースにRedshiftを指定します。

作成したODBCの設定を指定して、ユーザー名/パスワードを入れます。
エディタ画面でクエリを作成して、OKを押します。

閲覧ツールをつなげて実行すると、テーブルのデータが取得できました。

出力(ODBC)
以下のCSVをAlteryxで取り込みます。
話数,パート,ポプ子,ピピ美
第5話,前半,皆川純子,甲斐田ゆき
第5話,後半,豊永利行,浅沼晋太郎
データ出力ツールと繋げて、データソースにRedshiftのODBCを指定します。

入力時と同じように設定します。

テーブル名に、作成済みのテーブル名を指定しました。

RDBのPasSと同じように、出力オプションが色々選べます。
「既存のものを付加する」から試してみます。

テーブルにデータが追加されました。

次は「データを削除して付加する」です。
前回と同様、既に入っていたものは無くなって、取り込みデータが入りました。
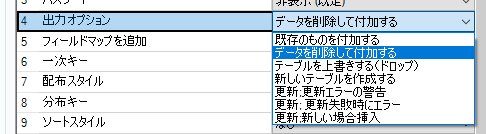

「テーブルを上書きする(ドロップ)」も前回と同様、テーブル定義が変わっています。
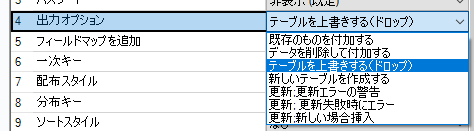

「新しいテーブルを作成する」も同様に、エラーになりました。


出力(バルク)
COPYに該当する出力方法もあるようなので試してみました。参考にしたページは以下になります。
参考のページによると、内部でS3にアップして、そのファイルに対してCOPYを行っているようなので、以下のCloudFormationのファイルでS3バケットと専用のユーザーを作成します。
AWSTemplateFormatVersion: 2010-09-09
Resources:
TargetBucket:
Type: AWS::S3::Bucket
AlteryxUser:
Type: AWS::IAM::User
Properties:
Policies:
- PolicyName: S3Access
PolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Action:
- s3:ListBucket
Resource:
- !Sub arn:aws:s3:::${TargetBucket}
- Effect: Allow
Action:
- s3:*Object
Resource:
- !Sub arn:aws:s3:::${TargetBucket}/*
その後、作成されたユーザーのアクセスキーを作成してダウンロードしておきます。
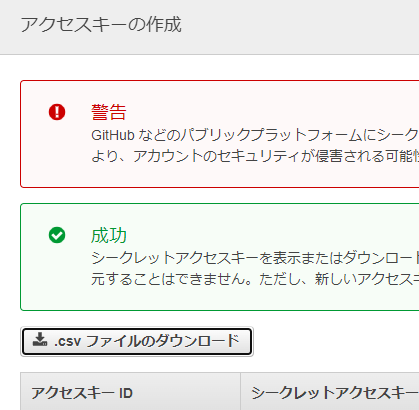
Redshiftのデータも、最初の状態に戻しておきます。

Alteryxに戻り、先ほどと同様出力ツールをドロップし、データソースから今度はRedshiftのバルクを選択します。

出てきた画面に情報を入力していきます。ユーザー名とパスワードは未指定でOKでした。

テーブル名も同様に指定しておきます。

出力オプションはODBC経由のものとは異なり更新で始まるオプションがありません。
「既存のものを付加する」から試してみます。

S3では途中でファイルが生成されており、完了後は削除されています。

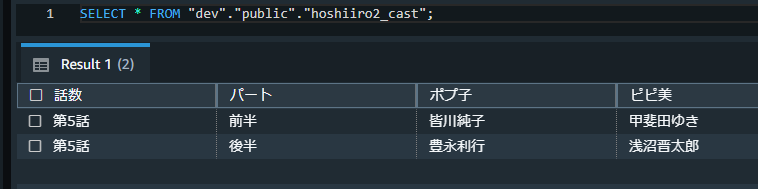
取り込まれたデータが挿入されています。

次に「データを削除して付加する」を試してみます。
ODBCの出力と同様に、取り込みデータのみになりました。

「テーブルを上書きする(ドロップ)」も同様にテーブル定義が変わっています。

「新しいテーブルを作成する」の結果も、同名のテーブルが存在するためエラーになりました。


おわりに
今回はAlteryxとAmazon Redshiftをつなげてみました。
Redshiftは大量データを入れる際にCOPYを使って入れていましたが、「TRUNCATEして、都度S3にアクセスして、ファイルを置いて…」と操作が面倒でした。
Alteryxを使えば、そのあたりの手間がだいぶ軽減できるかと思います。