はじめに
先日、分析によくつかわれるアプリケーションがインストール済みのインスタンスがすぐに使えるサービス Amazon Lightsail for Research が発表されました。
JupyterLabやR Studioなどが簡単に使えるようですが、そこにデータを持ってくる方法が気になったので調べてみました。
概要
- 小さいデータファイルなら、GUIが楽
- 公式のSCPの方法は面倒
- 大きいデータは、アクセスキーを発行して(Python)SDKでのやり取りがよさそう
- 「IAMロールをインスタンスにアタッチして」というようなのは無理そうです
- (おまけ)Polarisも動きそう
やったこと
インスタンス作成
以下のページが参考になります。
LightsailのTopの上部から専用の画面に遷移します。

リージョンと使いたいアプリケーションを選択します。
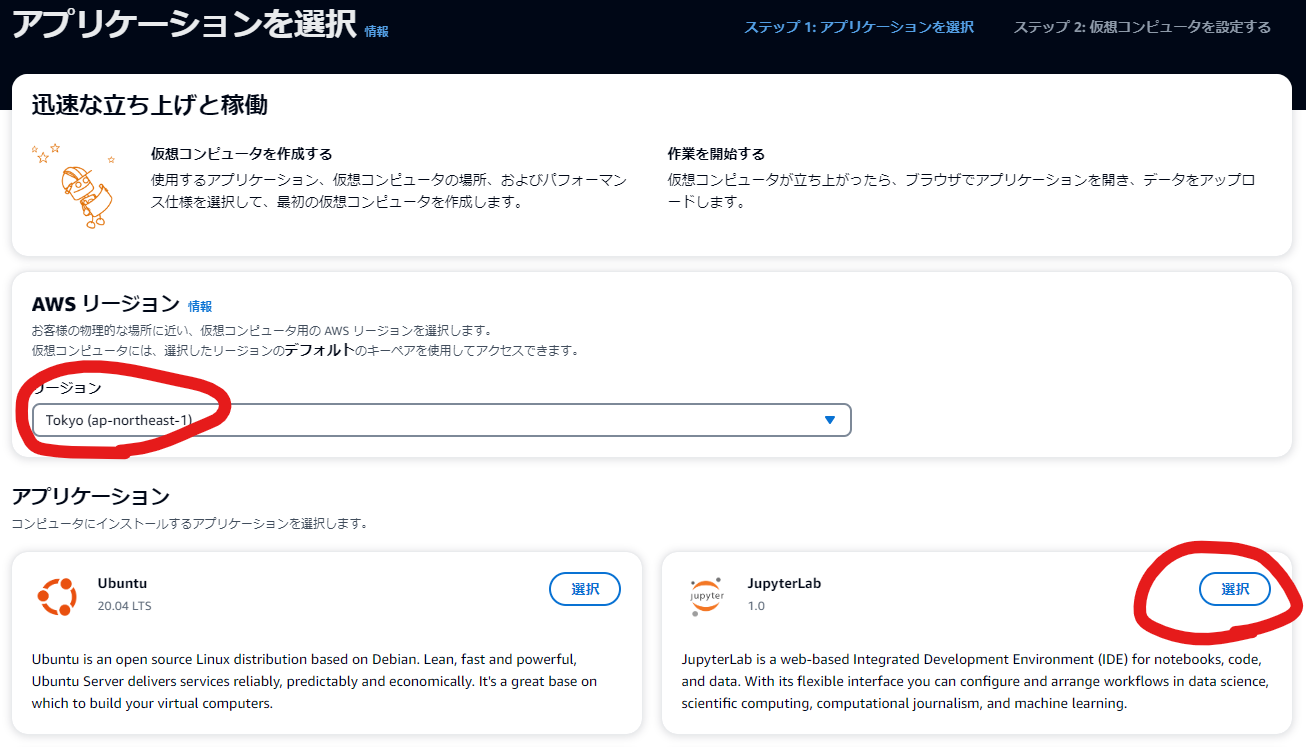
あとは名前を付ければ作成開始です。
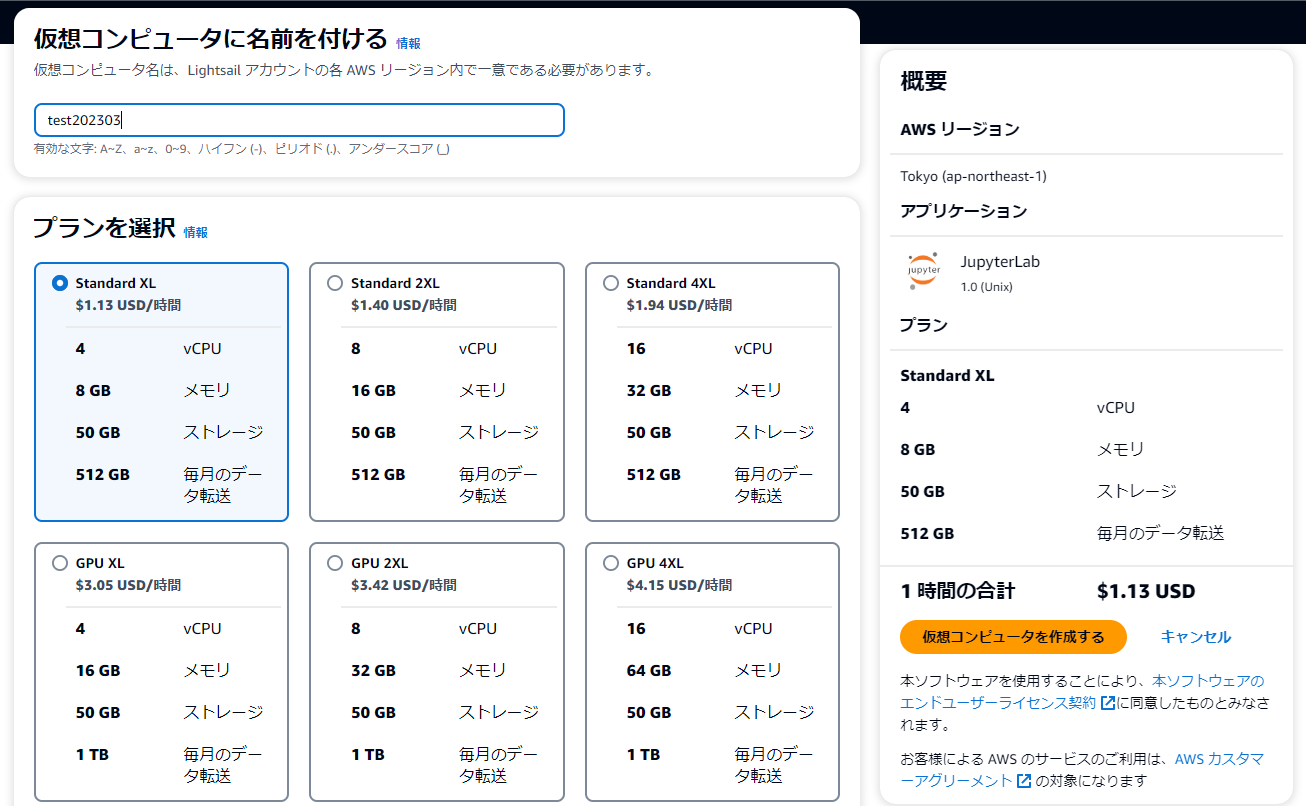
最低インスタンスで、起動までには6分くらいかかりました。ちょっと長いです。

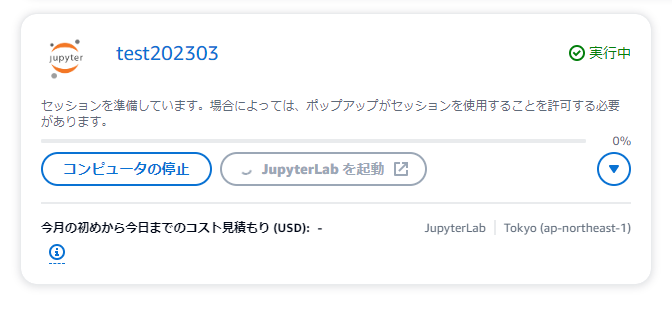
起動すると以下のようになります。

「JupyterLabを起動」を押すことで、ブラウザ上にJupyterLabの画面が表示されます。
コピペを確認する
まずはコピペがちゃんとできるか確認します。
うまくコピペできるようになると、画面左上のアイコンが以下のように吹き出しを表示するようになります。
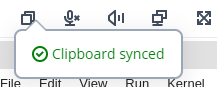
最初にうまくいかない場合はインスタンスを再起動しました。
SCP
公式の以下のページをなぞりました。
大変面倒でした。この後に試した方法をお勧めします。
ペアキーの取得
CloudShellにてLightsailのキーペアを取得します。
aws lightsail download-default-key-pair --region ap-northeast-1 > dkp-details.json
cat dkp-details.json | jq -r '.privateKeyBase64' > dkp_rsa
自PCにダウンロードします。


キーファイルの権限を変更する必要がありますが、Windowsで扱うならユーザ以下のディレクトリで作業すれば、権限変更は不要ですので、そこを作業場所としました。

一旦、Lightsailにアップロード
CloudShellで、インスタンスの接続情報を取得します。
# 2か所にでてくるので、変数格納して使う
REGNAME=ap-northeast-1 && echo $REGNAME
INSTNAME=test202303 && echo $INSTNAME
aws lightsail get-instance --region $REGNAME --instance-name $INSTNAME \
| jq -r ".instance.username" \
& aws lightsail get-instance --region $REGNAME --instance-name $INSTNAME \
| jq -r ".instance.publicIpAddress"
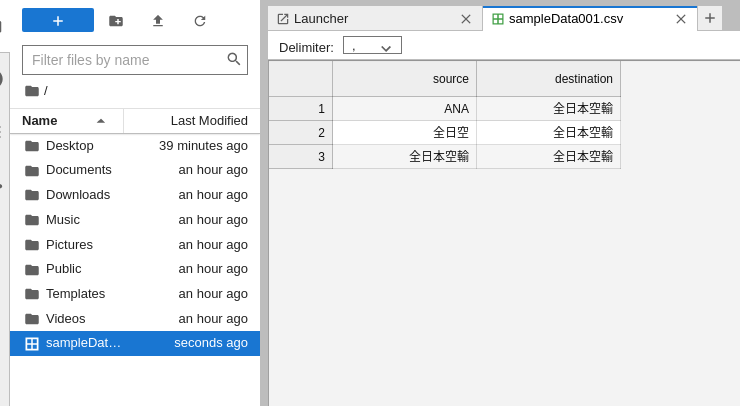
以下のCSVファイルのアップを試みます。
source,destination
ANA,全日本空輸
全日空,全日本空輸
全日本空輸,全日本空輸
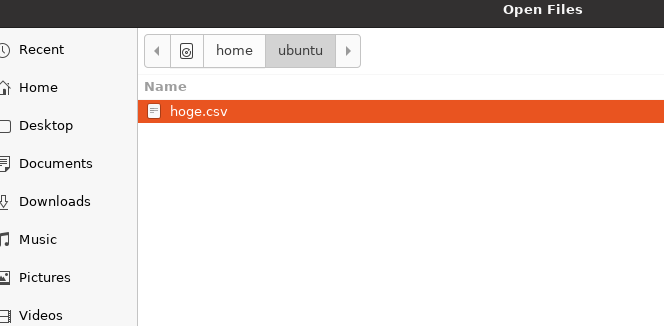
SCPでコピーですが、ユーザや権限などで、ubuntuユーザの以下の場所くらいにしか置けませんでした。
scp -i dkp_rsa sampleData001.csv ubuntu@xxx.xxx.xxx.xxx:/home/ubuntu/hoge.csv
JupyterLabで見える場所に移動
ubuntuユーザの場所から、JupyterLabで見える場所に移すためには画面操作が必要です。

やっとJupyterLabで開けるようになりました。

逆方向も同様の面倒さでした。
scp -i dkp_rsa ubuntu@xxx.xxx.xxx.xxx:/home/ubuntu/hoge.csv moge.csv

GUI
こちらのほうが楽です。ファイルが小さい場合はこちらをオススメします。
左上のアイコンでアップロードできます。

すぐに見れました。
ダウンロードも、ブラウザのダウンロード機能で落ちてきます、楽です。

S3経由
準備
以下のCloudFormationで、やり取り用のバケットとユーザを作成します。
AWSTemplateFormatVersion: 2010-09-09
Resources:
DataBucket:
Type: AWS::S3::Bucket
Properties:
BucketName: !Sub for-lightsail-${AWS::AccountId}-${AWS::Region}
BucketEncryption:
ServerSideEncryptionConfiguration:
-
ServerSideEncryptionByDefault:
SSEAlgorithm: 'AES256'
BucketKeyEnabled: false
PublicAccessBlockConfiguration:
BlockPublicAcls: true
BlockPublicPolicy: true
IgnorePublicAcls: true
RestrictPublicBuckets: true
AccessUser:
Type: AWS::IAM::User
Properties:
Policies:
- PolicyName: accesss3
PolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Action: s3:ListAllMyBuckets
Resource: arn:aws:s3:::*
- Effect: Allow
Action: s3:ListBucket
Resource: !Sub arn:aws:s3:::${DataBucket}
- Effect: Allow
Action: s3:*Object
Resource: !Sub arn:aws:s3:::${DataBucket}/*
アクセスキーを作成します。


次はインスタンス上で操作します。boto3は入っていないので、そのインストールからです。
!pip list
!pip install boto3
import boto3
ダウンロード
# clientなら
s3client = boto3.client('s3', aws_access_key_id='YOURACCESSKEY', aws_secret_access_key='YOURSECRETKEY')
s3client.get_object( Bucket='mybucket', Key='sampleData001.csv' )
body = response['Body'].read()
print(body.decode('utf-8'))
# resourceなら
s3resource = boto3.resource('s3',aws_access_key_id='YOURACCESSKEY', aws_secret_access_key='YOURSECRETKEY')
s3resource.meta.client.download_file('mybucket', 'sampleData001.csv', '/home/lightsail-user/hello.csv')
アップロード
# clientなら
response = s3client.put_object(
Body='/home/lightsail-user/hello.csv',
Bucket='mybucket',
Key='hello2.csv',
)
print(response)
# resourceなら
s3resource.meta.client.upload_file('/home/lightsail-user/hello.csv', 'mybucket', 'hello3.csv')
S3にアップされていることを確認しました。
Athena
S3でやり取りするのが現実的でないサイズのデータの場合を想定して、wranglerでAthenaを用いた方法も確認しました。
テーブル作成
以下のCloudFormationを実行します。
クリックで表示
アクセス用のユーザを作成します。出来合いのマネージドポリシーをあてがいます。
AWSTemplateFormatVersion: 2010-09-09
Resources:
AWSUser:
Type: AWS::IAM::User
Properties:
ManagedPolicyArns:
- arn:aws:iam::aws:policy/AmazonAthenaFullAccess
作成したらS3の時と同様、アクセスキーを作成します。
次に格納バケット、出力バケット、ワークグループ、データベースを作成します。Envパラメータには環境名を名付けて入れてください。
バケット名の接頭辞は、ユーザにあてがったポリシーで許可されている文字列ですので変更しないでください。
AWSTemplateFormatVersion: '2010-09-09'
Parameters:
Env:
Type: String
Resources:
RawDataBucket:
Type: AWS::S3::Bucket
Properties:
BucketName: !Sub athena-examples-${AWS::AccountId}-${AWS::Region}-${Env}
BucketEncryption:
ServerSideEncryptionConfiguration:
-
ServerSideEncryptionByDefault:
SSEAlgorithm: 'AES256'
BucketKeyEnabled: false
PublicAccessBlockConfiguration:
BlockPublicAcls: true
BlockPublicPolicy: true
IgnorePublicAcls: true
RestrictPublicBuckets: true
AthenaQueryResultBucket:
Type: AWS::S3::Bucket
Properties:
BucketName: !Sub aws-athena-query-results-${AWS::AccountId}-${AWS::Region}-${Env}
BucketEncryption:
ServerSideEncryptionConfiguration:
-
ServerSideEncryptionByDefault:
SSEAlgorithm: 'AES256'
BucketKeyEnabled: false
PublicAccessBlockConfiguration:
BlockPublicAcls: true
BlockPublicPolicy: true
IgnorePublicAcls: true
RestrictPublicBuckets: true
LifecycleConfiguration:
Rules:
-
Id: 'auto-delete'
Status: 'Enabled'
ExpirationInDays: 7
AthenaWorkGroup:
Type: AWS::Athena::WorkGroup
Properties:
Name: !Sub athena-work-group-${Env}
RecursiveDeleteOption: true
WorkGroupConfiguration:
ResultConfiguration:
OutputLocation: !Sub s3://${AthenaQueryResultBucket}/data
EncryptionConfiguration:
EncryptionOption: 'SSE_S3'
EnforceWorkGroupConfiguration: true
PublishCloudWatchMetricsEnabled: true
GlueDatabase:
Type: AWS::Glue::Database
Properties:
CatalogId: !Ref AWS::AccountId
DatabaseInput:
Name: !Sub glue-database-${Env}
Outputs:
RawDataBucket:
Value: !Ref RawDataBucket
Export:
Name: !Sub "${Env}-RawDataBucket-Name"
AthenaQueryResultBucket:
Value: !Ref AthenaQueryResultBucket
Export:
Name: !Sub "${Env}-AthenaQueryResultBucket-Name"
AthenaWorkGroup:
Value: !Ref AthenaWorkGroup
Export:
Name: !Sub "${Env}-AthenaWorkGroup-Name"
GlueDatabase:
Value: !Ref GlueDatabase
Export:
Name: !Sub "${Env}-GlueDatabase-Name"
最後に環境上にテーブルを作成します。Envは先と同じ文字列を入れます。
AWSTemplateFormatVersion: '2010-09-09'
Parameters:
Env:
Type: String
TableName:
Type: String
Description: Table name must not contain uppercase characters.
Resources:
GlueTable:
Type: AWS::Glue::Table
Properties:
CatalogId: !Ref AWS::AccountId
DatabaseName:
Fn::ImportValue:
!Sub "${Env}-GlueDatabase-Name"
TableInput:
Name: !Ref TableName
TableType: EXTERNAL_TABLE
Parameters:
skip.header.line.count: 1
has_encrypted_data: false
serialization.encoding: utf-8
EXTERNAL: true
StorageDescriptor:
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Columns:
- Name: source
Type: string
- Name: destination
Type: string
InputFormat: org.apache.hadoop.mapred.TextInputFormat
Location:
Fn::Join:
- ''
- - 's3://'
- Fn::ImportValue: !Sub "${Env}-RawDataBucket-Name"
- '/data'
SerdeInfo:
Parameters:
field.delim: ","
serialization.format: ","
SerializationLibrary: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
dataフォルダ以下をテーブルの場所としていますので、フォルダを作って先のCSVを置きます。

後はwranglerを使って、アクセスキーを指定して、クエリを実行するだけです。
!pip install awswrangler
import awswrangler
session = boto3.session.Session(
aws_access_key_id=ACCESS_KEY,
aws_secret_access_key=SECRET_ACCESS_KEY,
region_name='ap-northeast-1',
)
df = awswrangler.athena.read_sql_query(
sql = 'SELECT * FROM sampletable' ,
database='glue-database-lfr',
boto3_session=session,
)
ちゃんと読めました。

(おまけ)Polarisも動きました
昨今話題のPolarisも確認してみました。
以前やったように、10行サンプルと、100本ノックの最初の10問を動かしてみました。
!pip install polars
10行の例
import polars as pl
df = pl.read_csv("https://j.mp/iriscsv") # データ読み込み
df_agg = (
df
.select([pl.col("^sepal_.*$"), pl.col("species")]) # 列の選択
.with_columns((pl.col("sepal_width") * 2).alias("new_col")) # 列の追加 with_column から変更
.filter(pl.col("sepal_length") > 5) # 行の選択
.groupby("species") # グループ化
.agg(pl.all().mean()) # 全列に対して平均を集計
)

100本ノックから
データの読み込みは、以前の記事をそのまま使っています。
以下、実行結果の画像です。


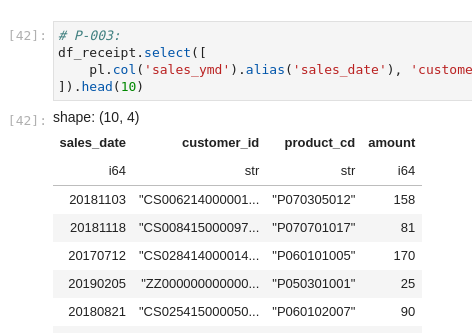







特にエラーもなく動きました。
おわりに
Amazon Lightsail for Researchとどうやってファイルをやり取りするのかを数例やってみました。
インスタンスのスペックが高いため、扱うデータのサイズも大きいものになると思われましたので、いつか使う際の予習のつもりで調べました。どなたかのご参考になれば幸いです。