目標
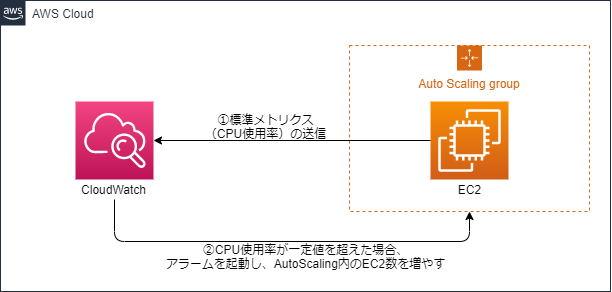
CloudWatchアラームにEC2の標準メトリクス(CPUUtilzation)を監視させ、それが一定値を超えた場合にアラームを起動することで、AutoScaling内のインスタンス数を増加させるシステムを構築する。
前提
・AutoScalingの基本的な概念や作成手順がある程度わかること。
(本記事ではAutoScalingの作成手順は要所のみとさせて頂いております)
CloudWatchとは
各AWSサービス(EC2、ELB、RDS、S3、EBS)のリソース情報(例としてはCPU使用率、ディスクIO、ネットワークIO等など。これをCloudWatchではメトリクスと呼びます。)収集を行い、
それをCloudWatchダッシュボード等で可視化させるサービスです。
CloudWatchアラームを利用することで、メトリクス情報を監視し、監視条件として指定したしきい値を超過した場合、
アラームを発砲しSNSによるメッセージ送信、AutoScalingアクション実行等の処理連携をすることが可能となります。
構成図
作業の流れ
| 項番 | タイトル |
|---|---|
| 1 | AutoScaling設定 |
| 2 | CloudWatchアラームの設定 |
| 3 | システム動作確認 |
手順
1.AutoScaling設定
要所のみの手順記載とさせて頂きます。
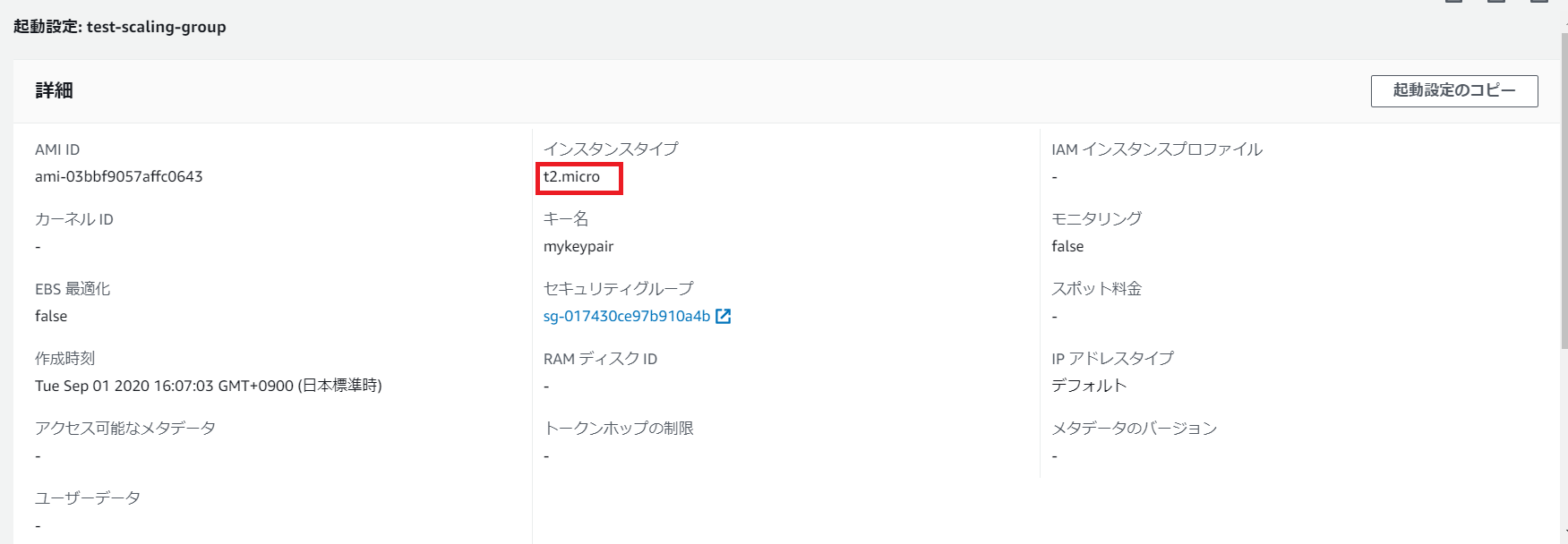
①起動設定の作成
どのような構成(利用するAMIやインスタンスタイプ等)のEC2インスタンスをAutoScalingで利用するかという設定を行うのが起動設定です(※)。
基本的に設定内容は自由ですが、安価かつCPU使用率を意図的に上げやすくするため低スペックのt2.microを利用しています。
※起動設定作成時の流れに関しては以下を参考
AWS Auto ScalingとELBの組み合わせ(オートヒーリング構築)(1. 起動設定(Launch Configuration)作成)
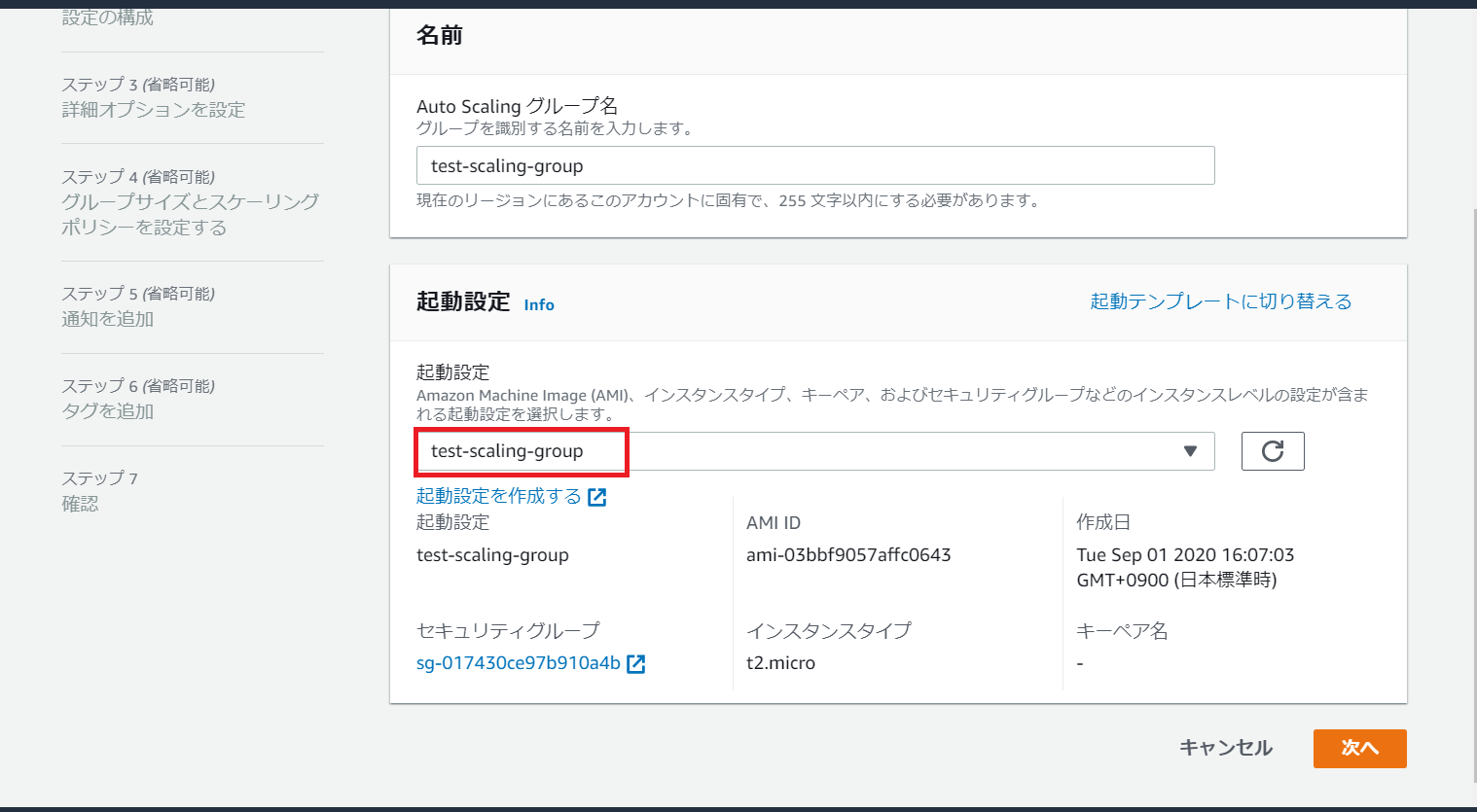
②AutoScalingグループの作成
どこ(どのVPCやAZに)にどんな規模(EC2インスタンスの台数等)のAutoScalingを構築するかという設定がAutoScalingグループとなります。
AutoScalingグループに紐づかせる起動設定は前手順①で作成した設定
本記事ではロードバランシングなしのAutoScalingとします。
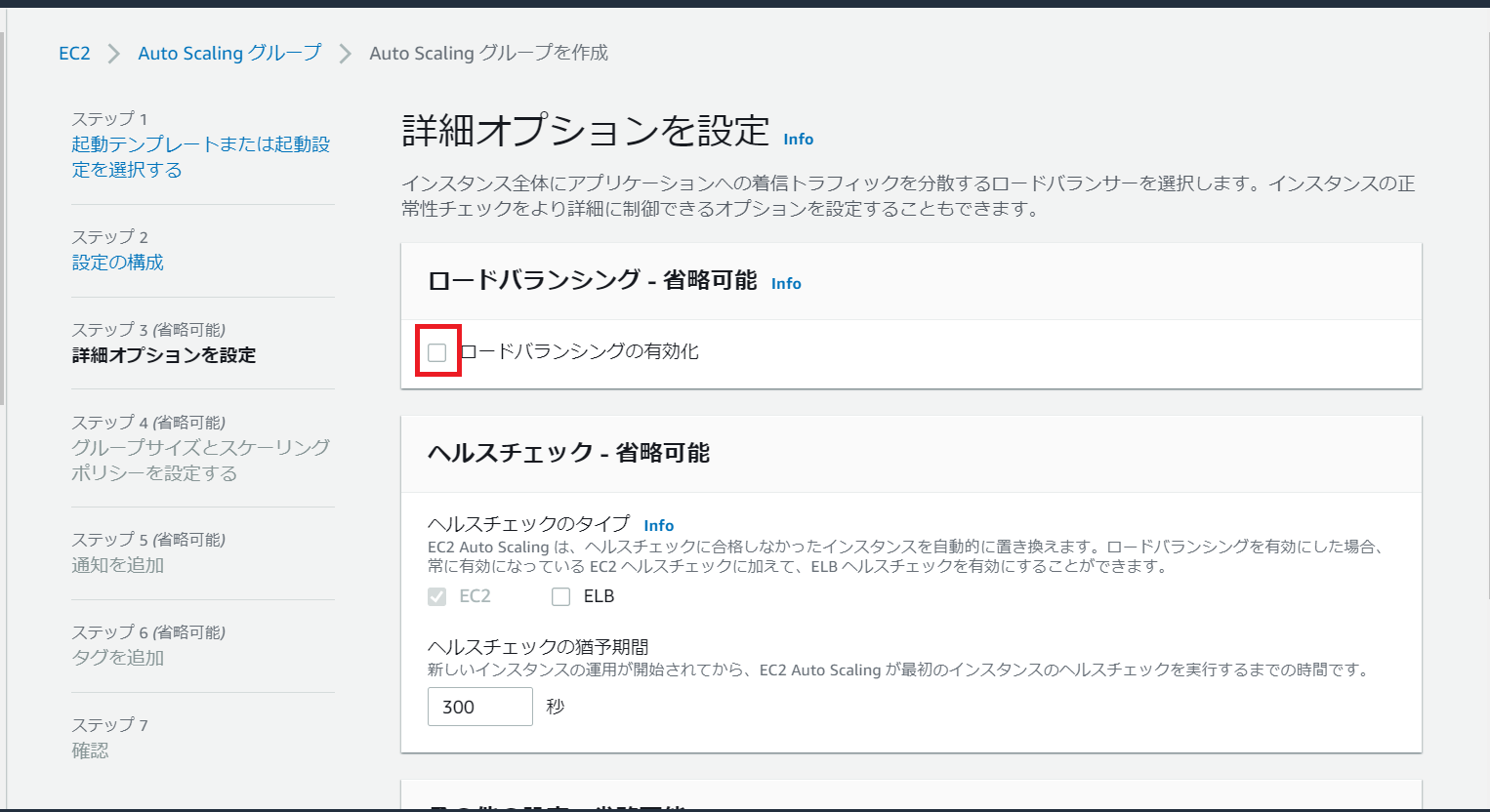
AutoScalingグループ内に起動するEC2インスタンスの数は1-2台とし、通常時は1台稼働としました。
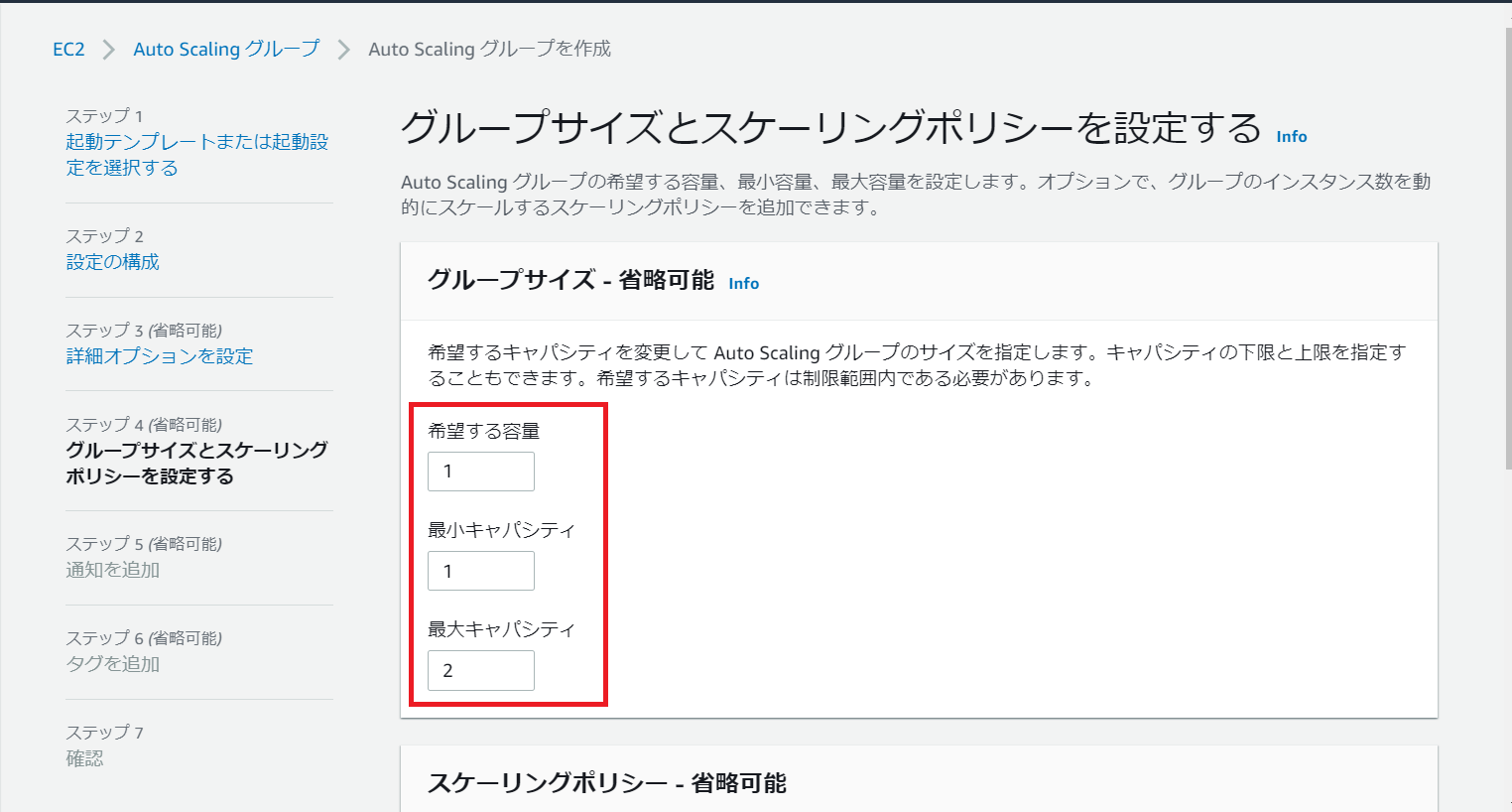
スケーリングポリシー(どのようなタイミングでグループ内のEC2インスタンス数を増加or減少させるか)はグループ作成後設定を行います。グループ作成前段階ではなしとします。
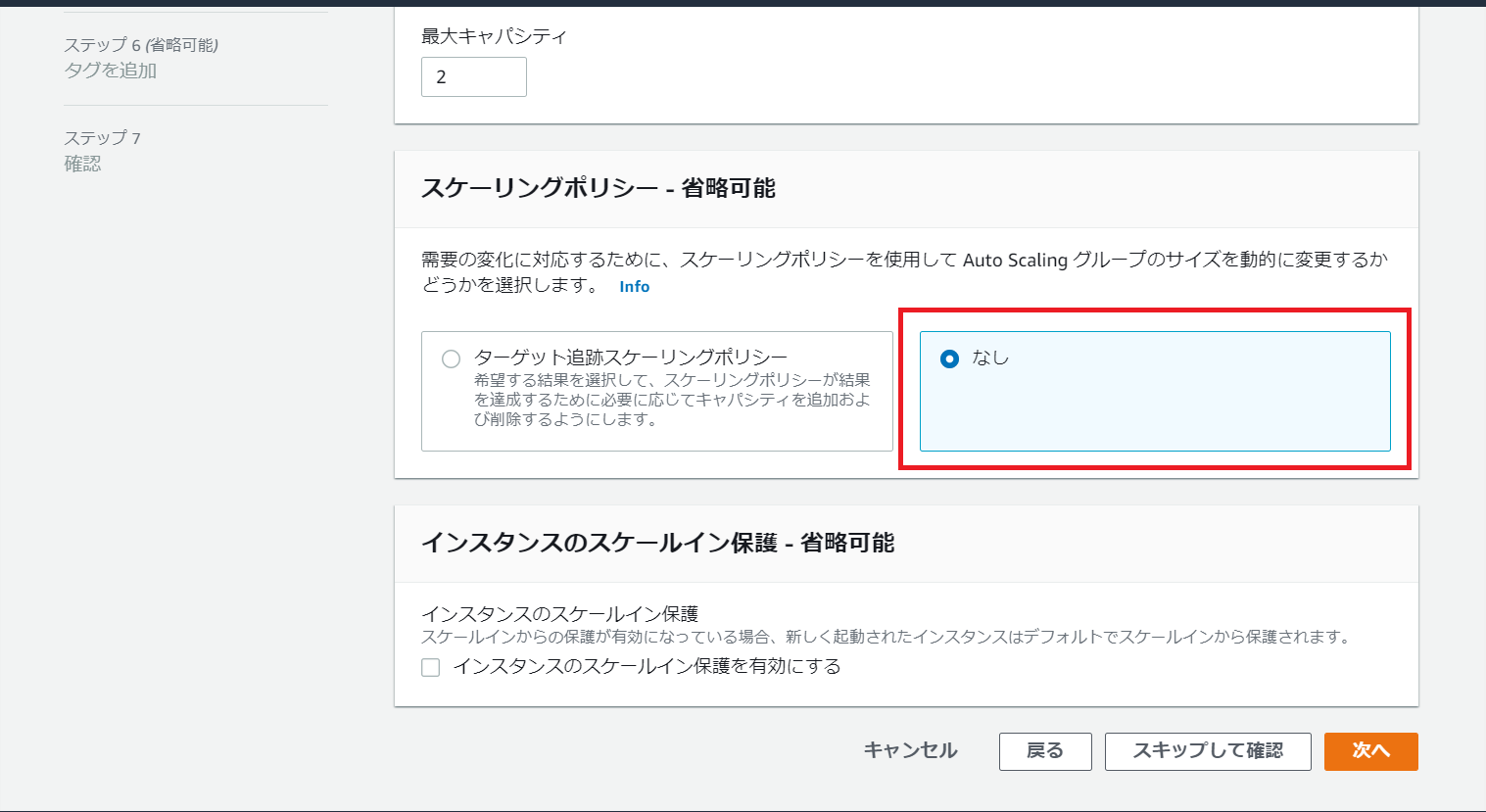
一通り作成を終えたら設定確認画面となりますので、問題なければAuto Scalingグループを作成
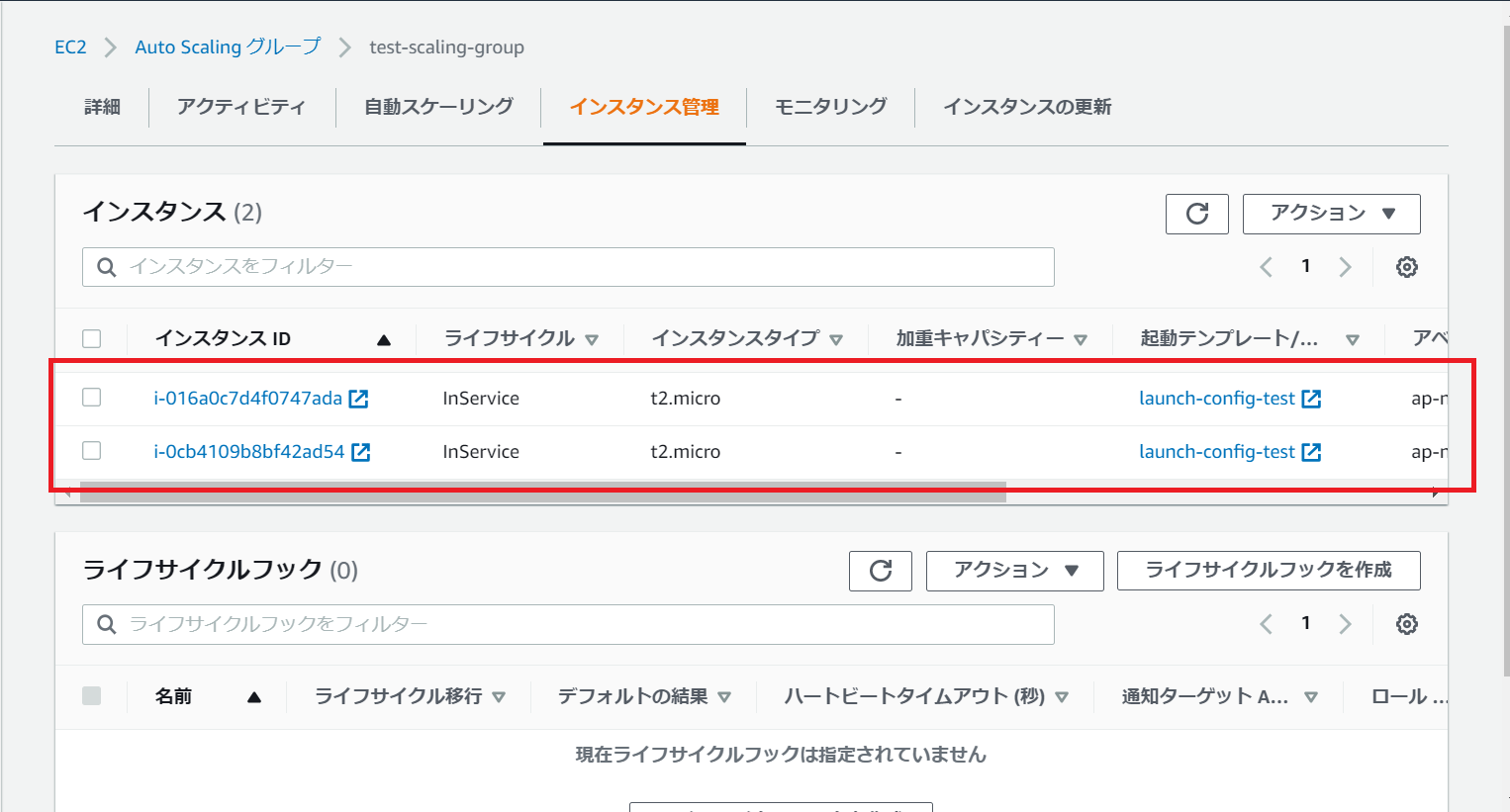
作成されたAutoScalingグループを選択し詳細画面遷移後、起動設定及びAutoScalingグループの設定が正しければ、
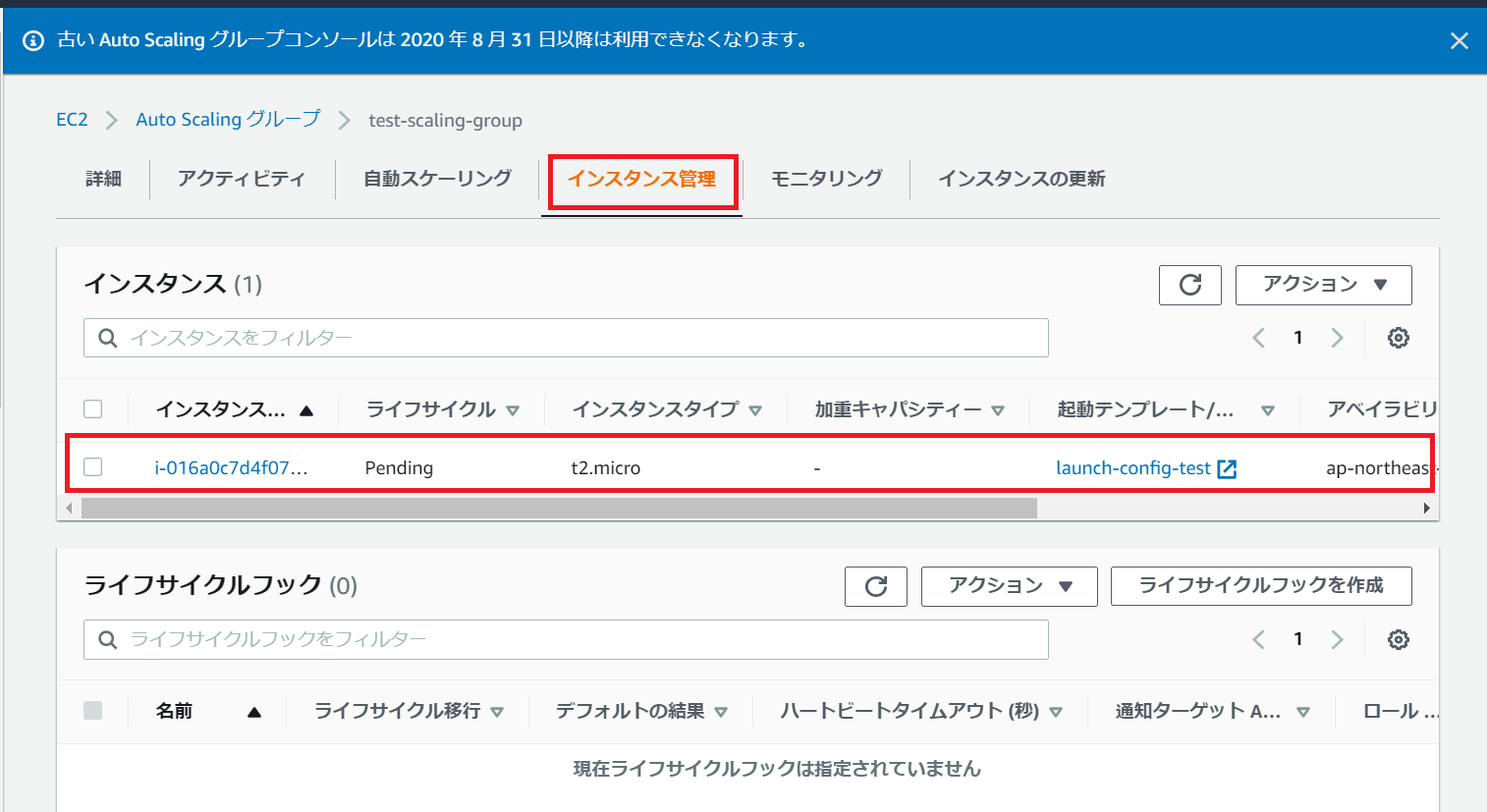
インスタンス管理画面で以下のようにEC2インスタンスが1台自動作成される想定です(※)。
※もし作成されない場合、以下画面内のアクティビティからAutoScalingのログを確認可能です(筆者は起動設定で適当に選んだAMIが対象のAZでサポートされてなく起動不可となってしまった事例あります。。)。
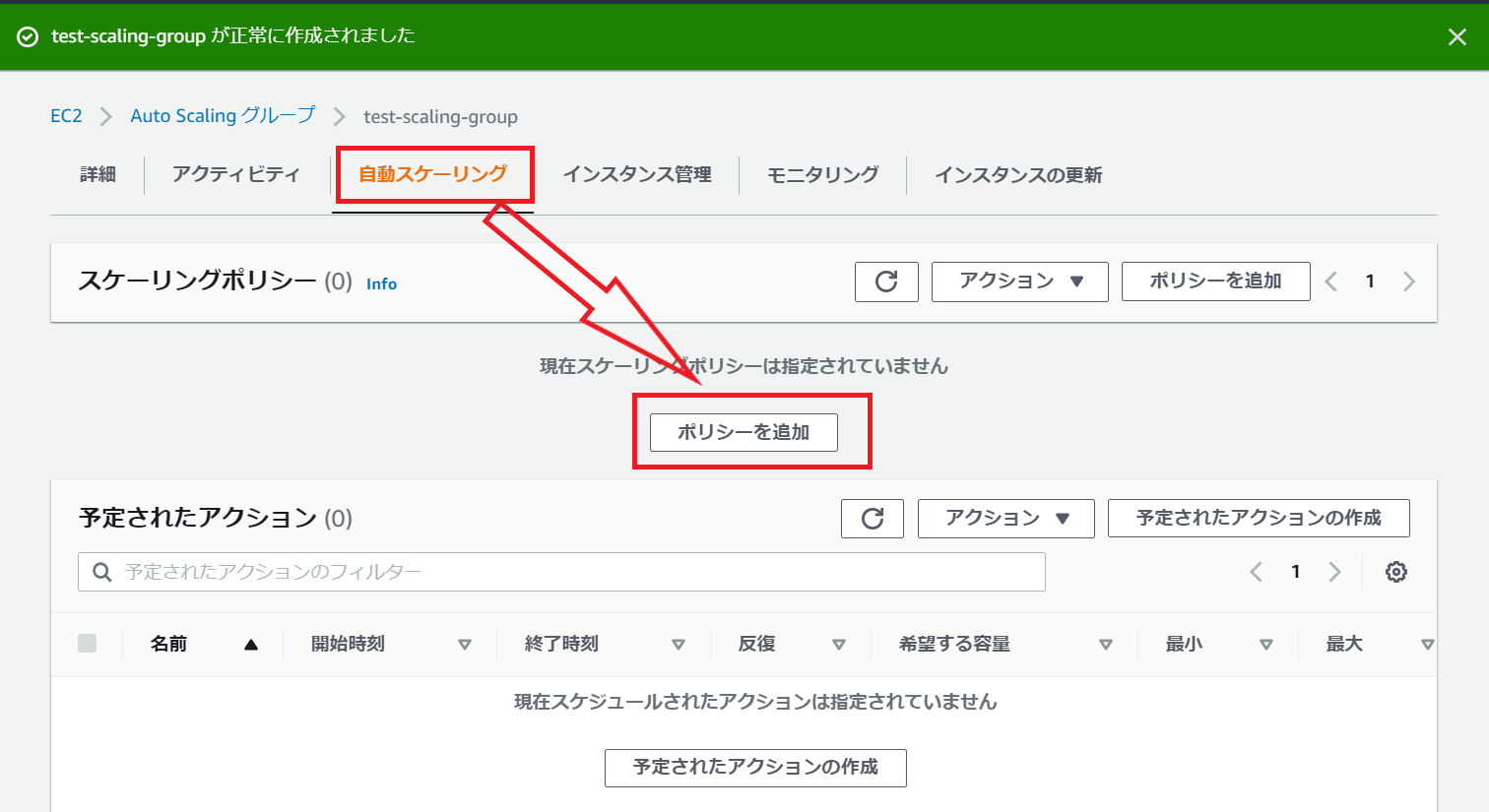
次に設定を保留したスケーリングポリシーの設定を行います。
作成されたAutoScalingグループを選択し詳細画面を表示後、自動スケーリング⇒ポリシーを追加をクリック
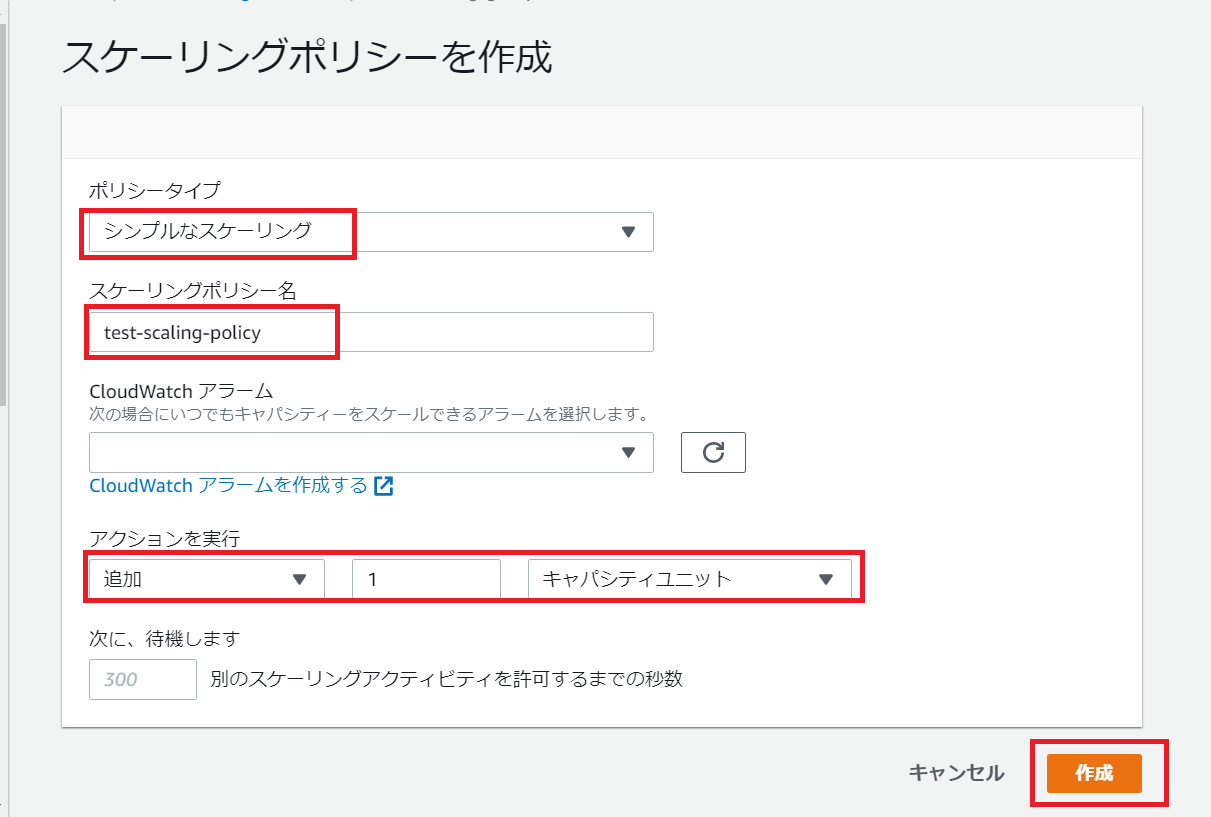
ポリシータイプをシンプルなスケーリングとし、スケーリング時のアクションは1キャパシティユニットを追加とします。
2.CloudWatchアラームの設定
①CloundWatchアラーム作成開始
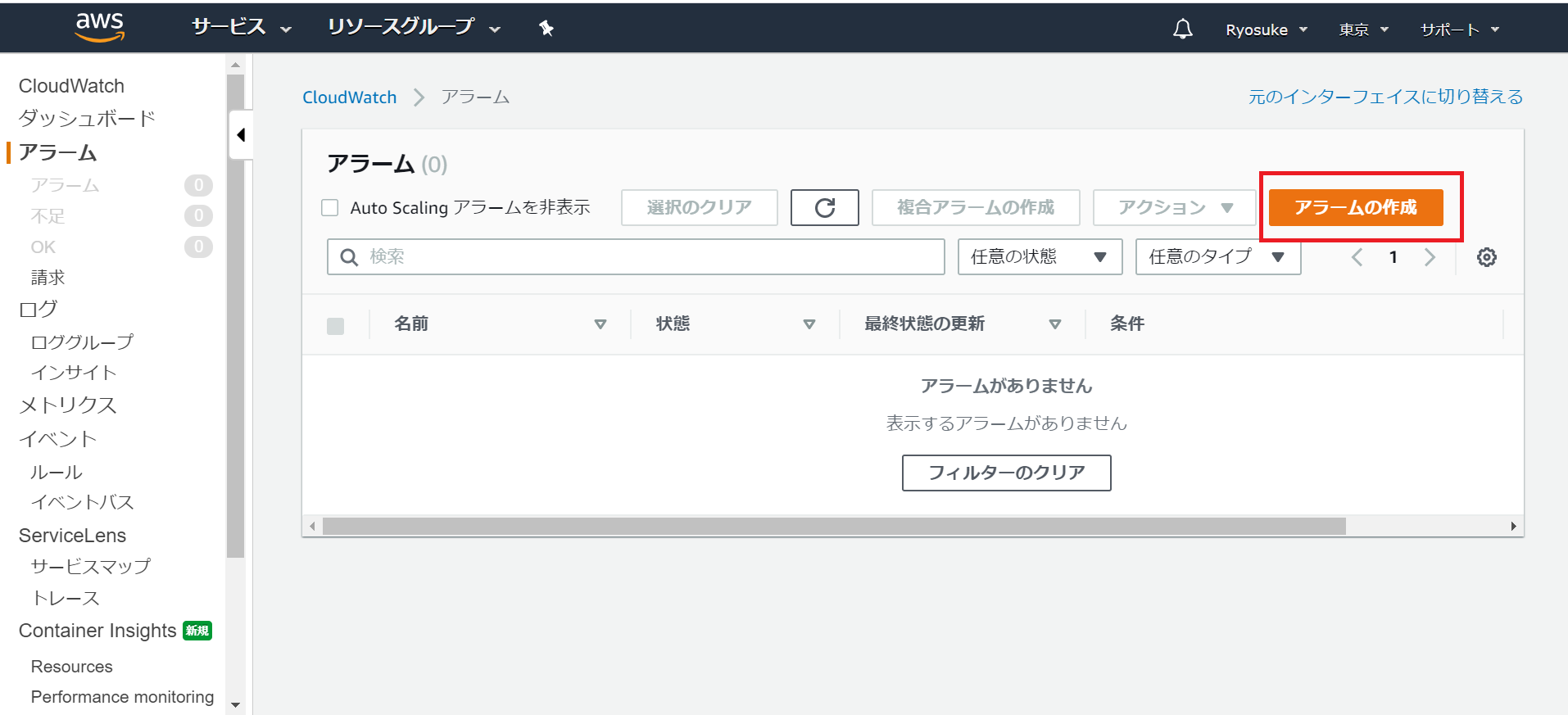
CloudWatchコンソールの左リスト内からアラームをクリック
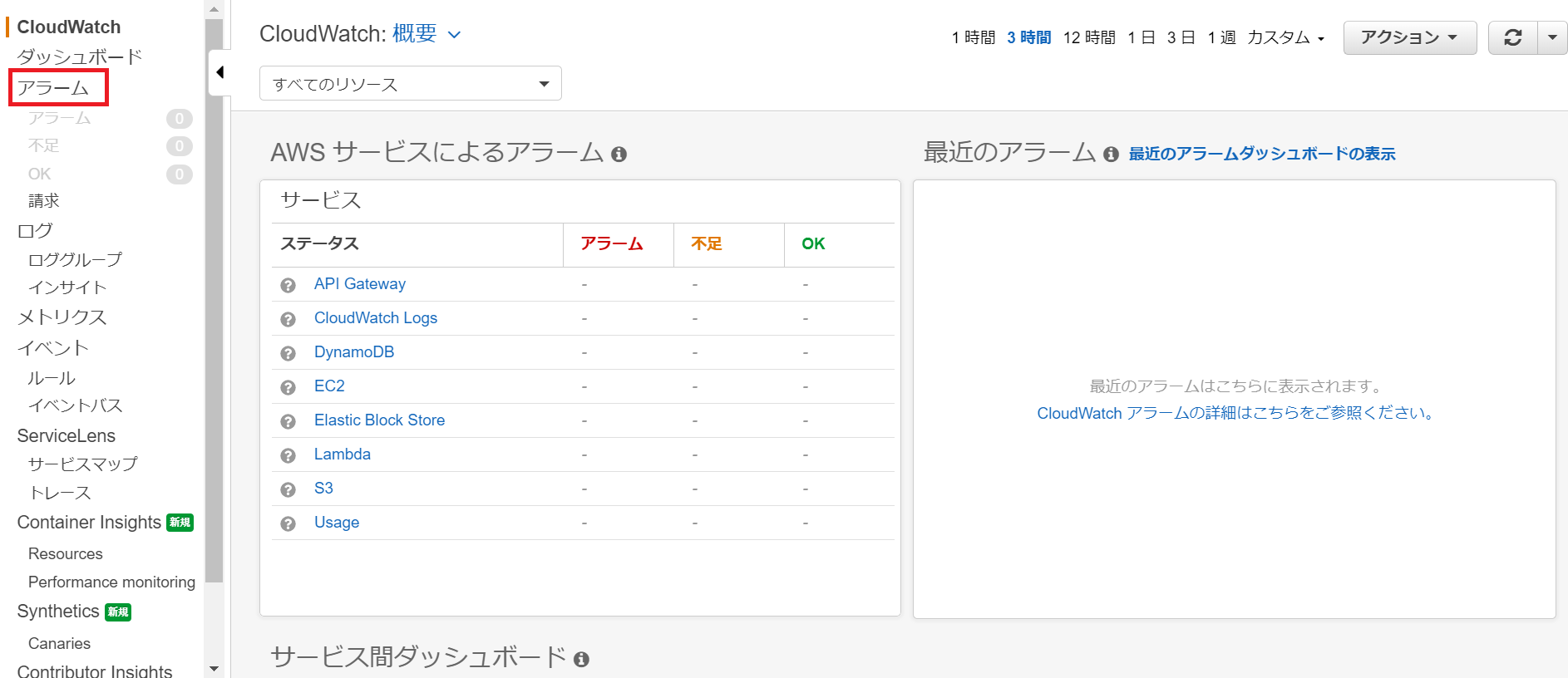
更にアラームの作成をクリック
②CloundWatchアラームの詳細設定
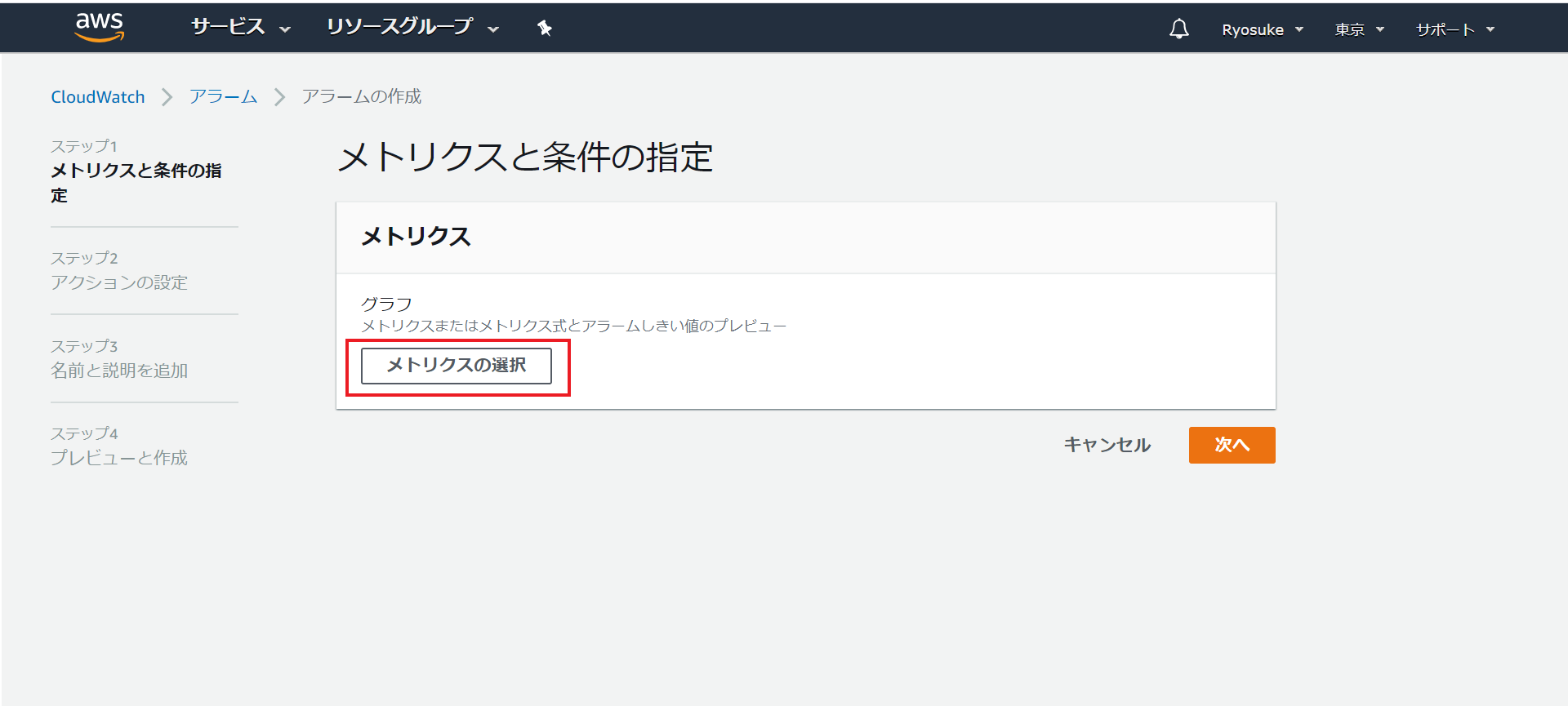
メトリクスと条件の指定
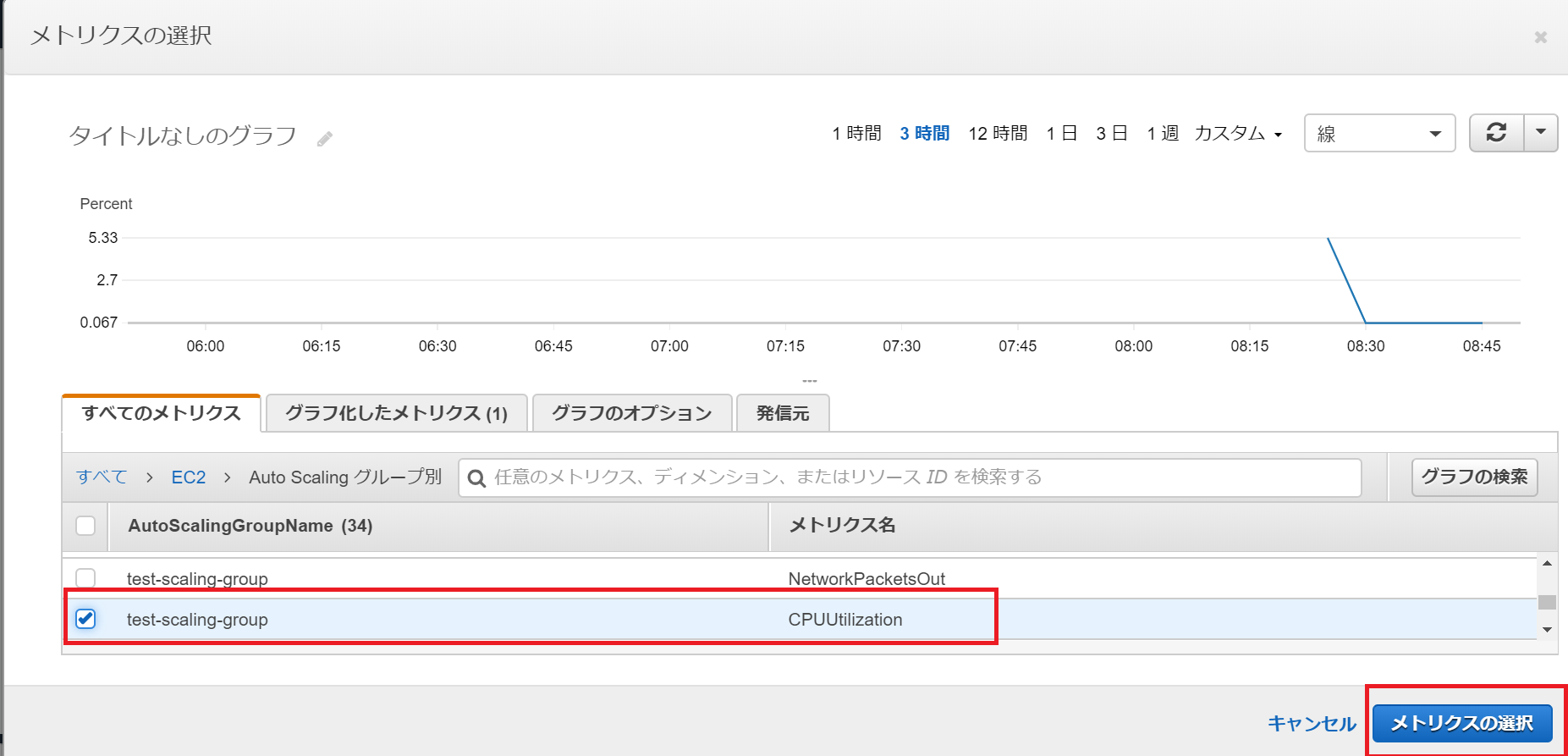
メトリクスの選択をクリック
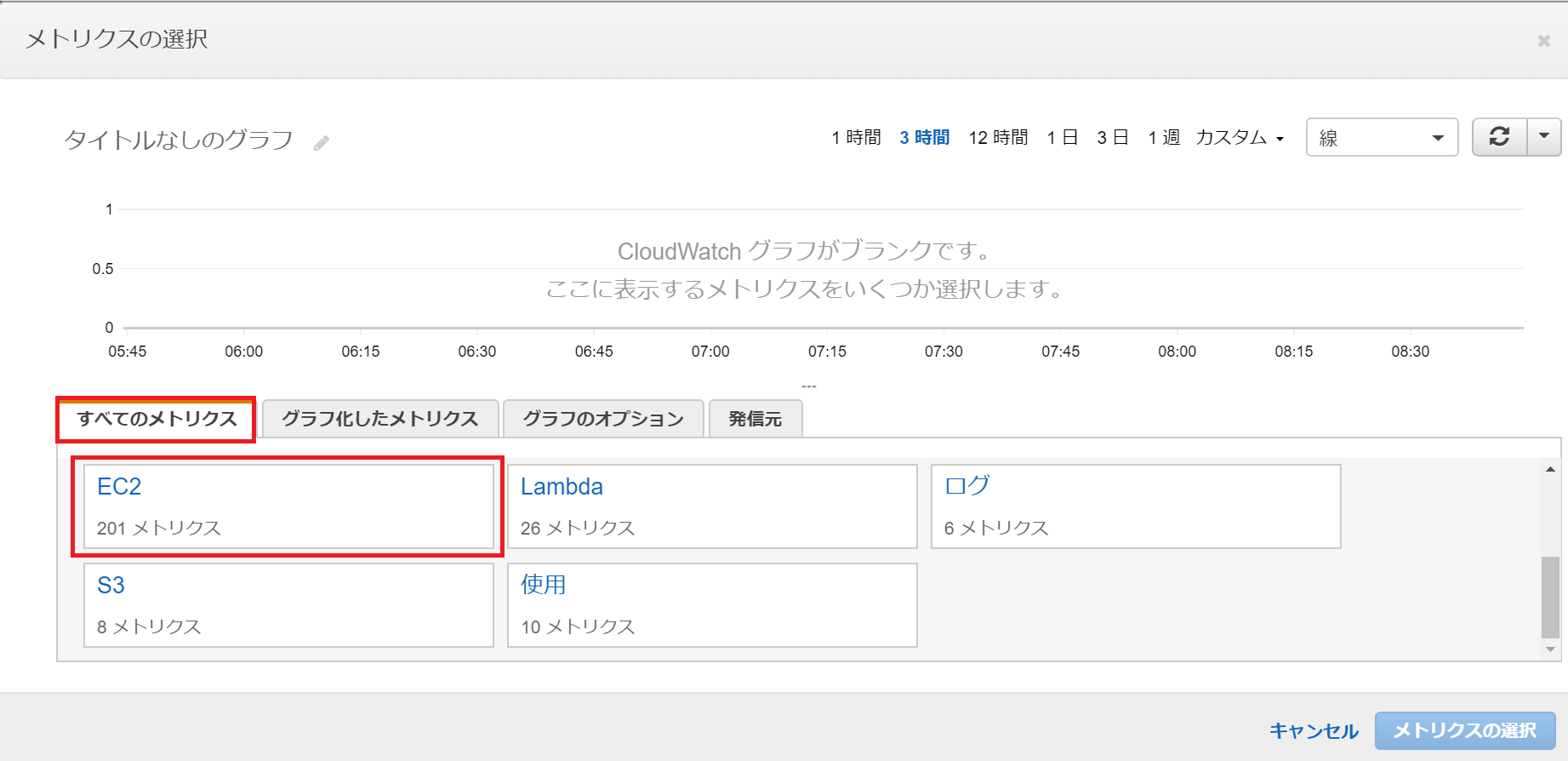
EC2用のメトリクスを監視します。
すべてのメトリクス内にあるEC2をクリック
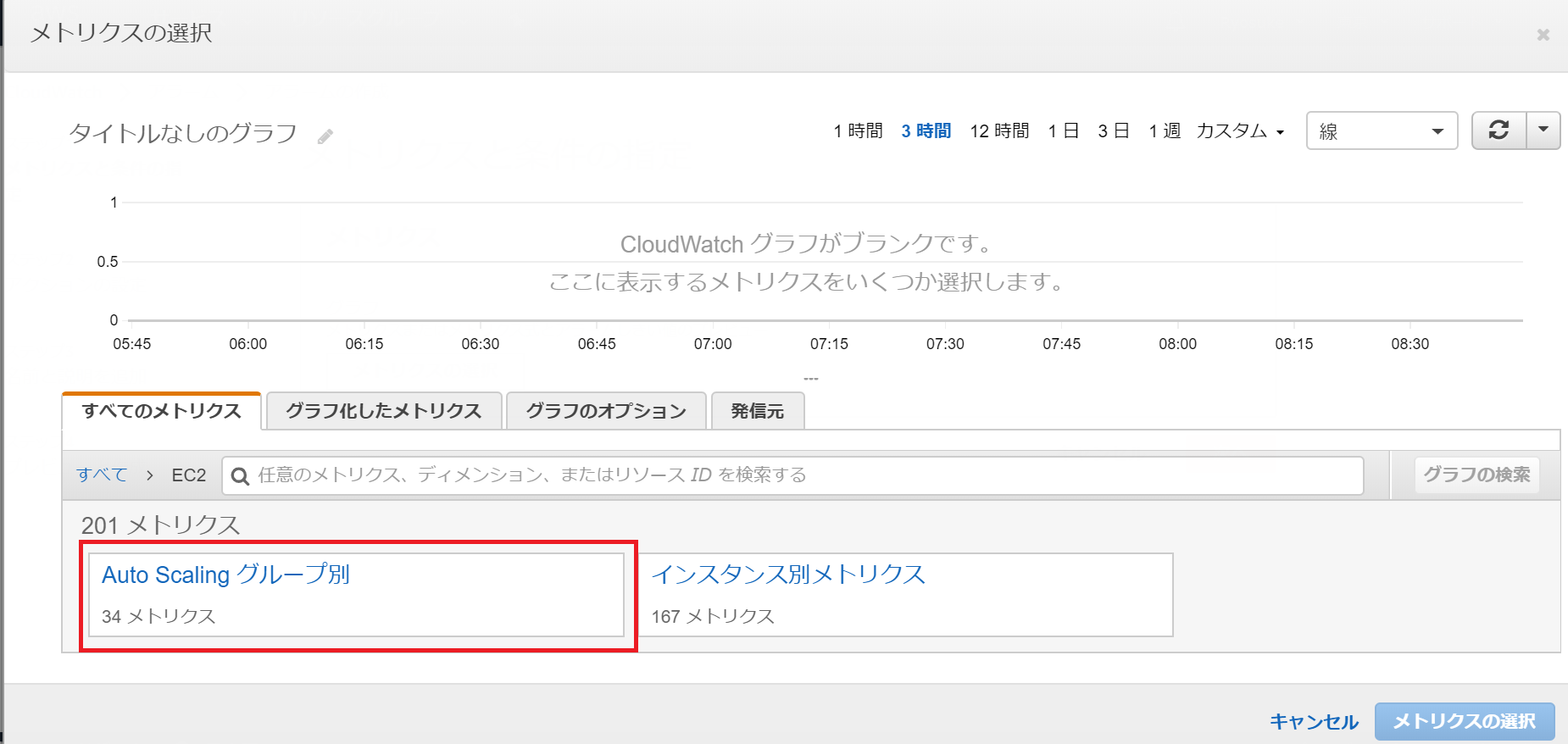
本記事ではAutoScalingグループ内に存在する全インスタンスのメトリクスを監視したいため、
Auto Scalingグループ別をクリック
作成したAutoScalingグループのメトリクスCPUUtilization(CPU使用率)をチェックし、CloudWatchアラームの監視対象として設定します。
チェックしたらメトリクスの選択をクリック
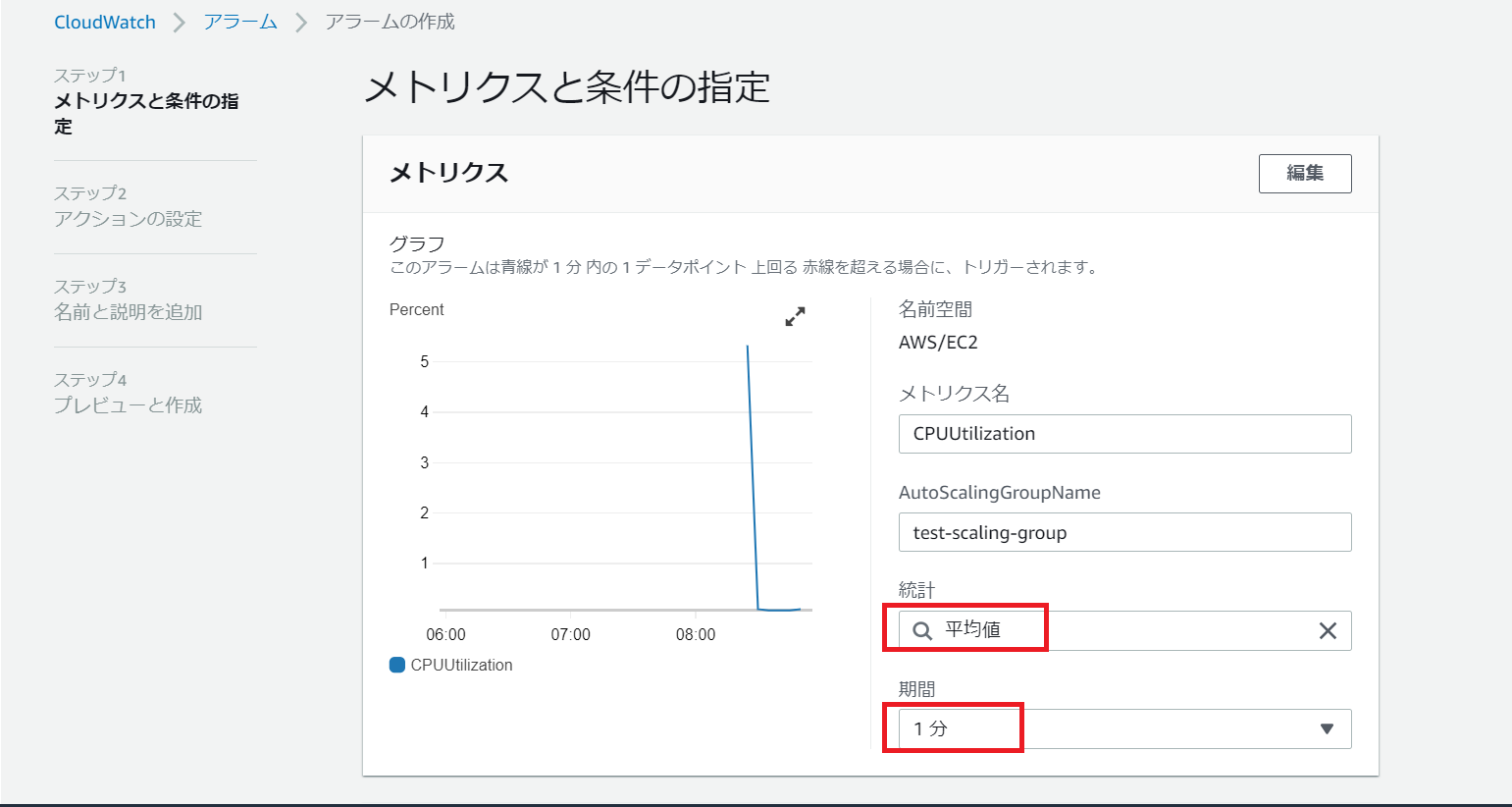
次にCloudWatchアラームを起動する際のトリガー条件を設定していきます。
今回は1分間の平均値をトリガーの基準とします。
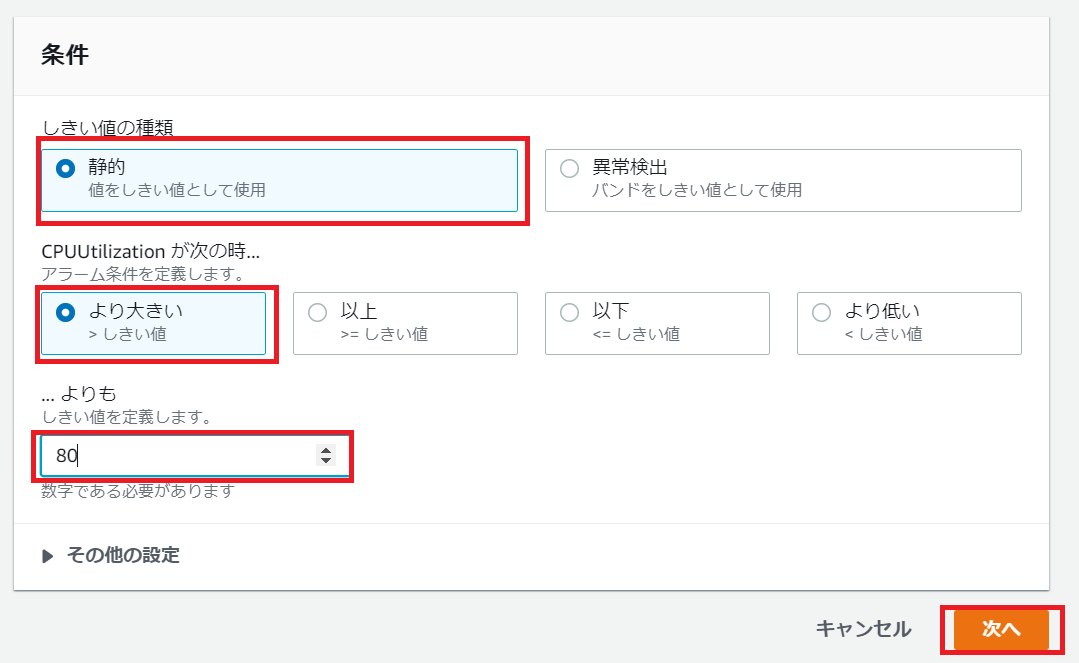
CPU使用率が80%よりも大きい場合というトリガー条件とします。
アクションの設定
CloudWatchアラームが起動した際にSNSによるメッセージ通知も可能ですが、今回は設定なしとします。
削除をクリック
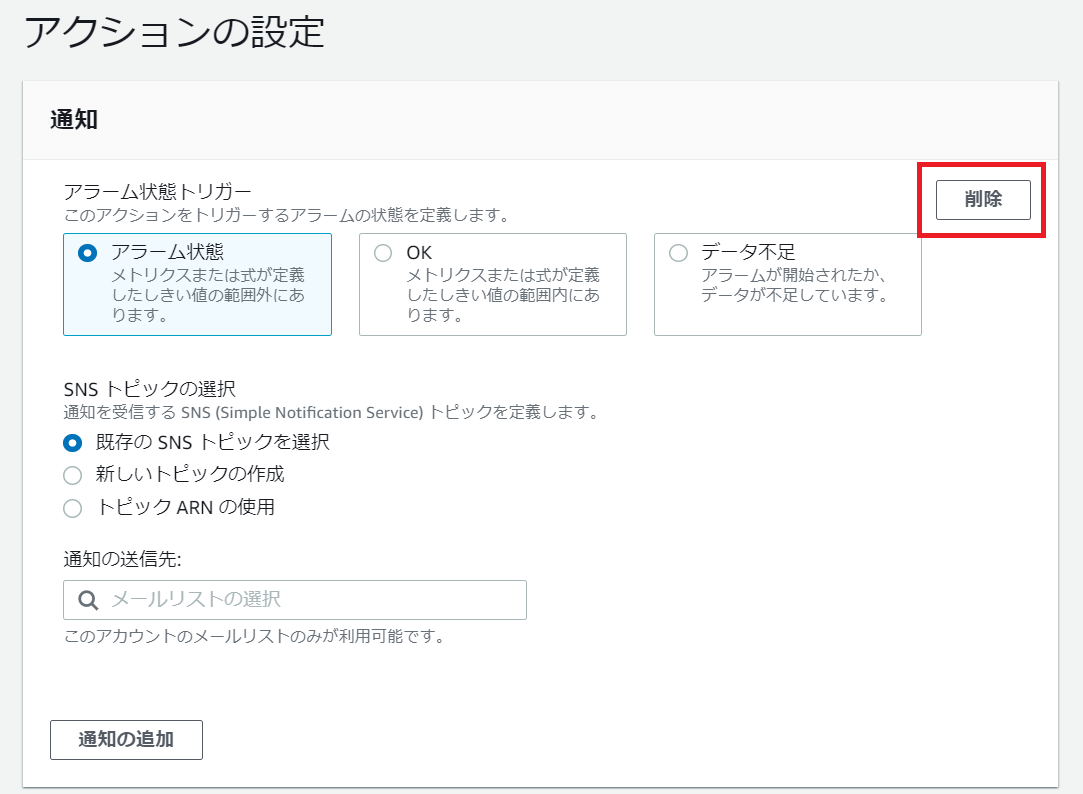
CloudWatchアラーム起動時のAutoScalingアクションを設定します。
Auto Scalingアクションの追加をクリック
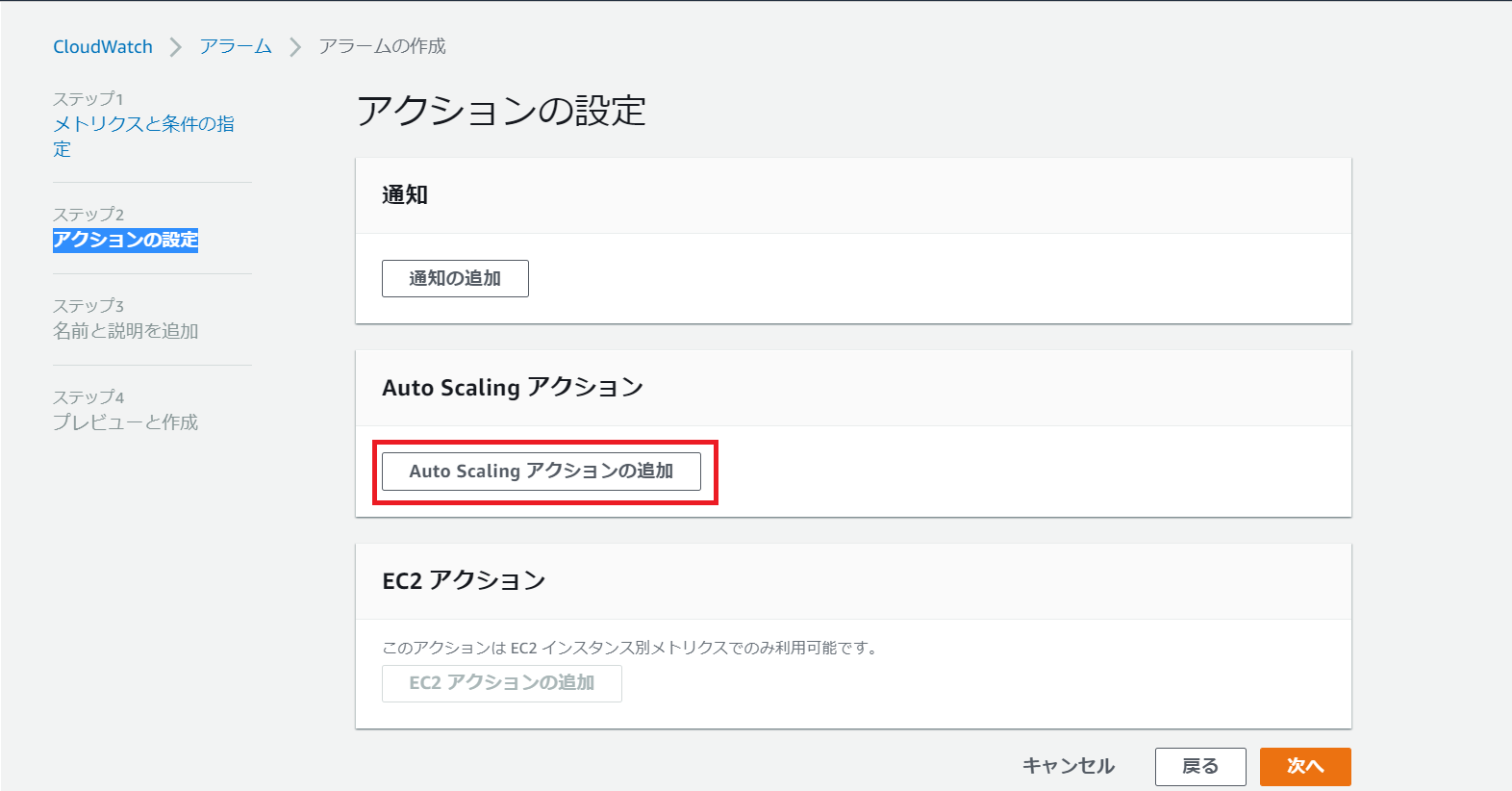
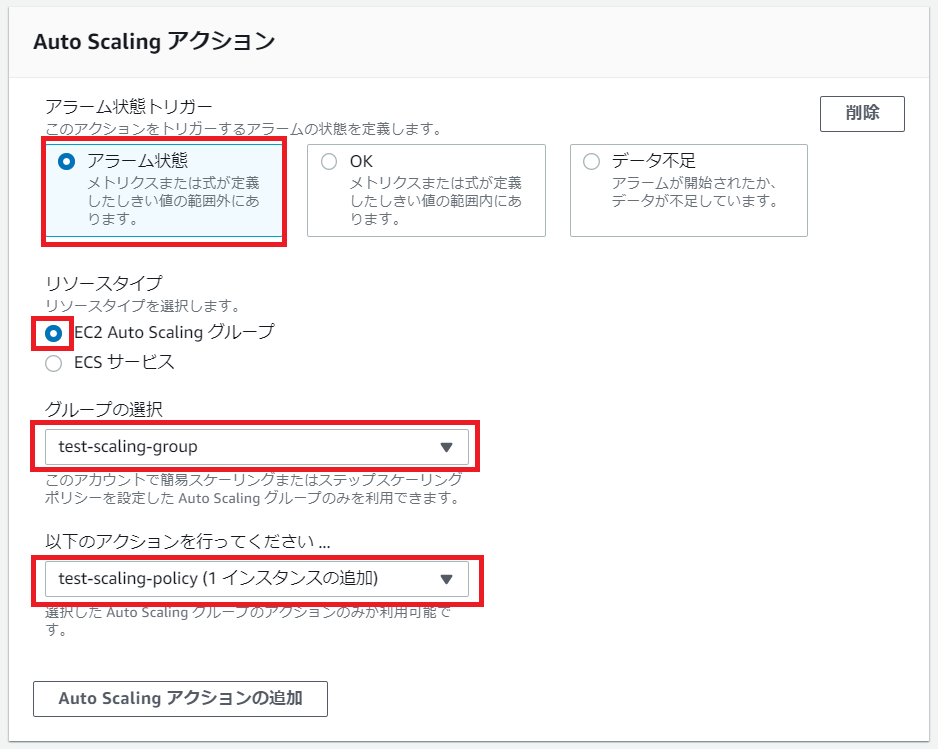
CloudWatchがアラーム状態のとき、前手順で作成したAutoScalingグループの1インスタンス追加アクションを実行するという設定をします。
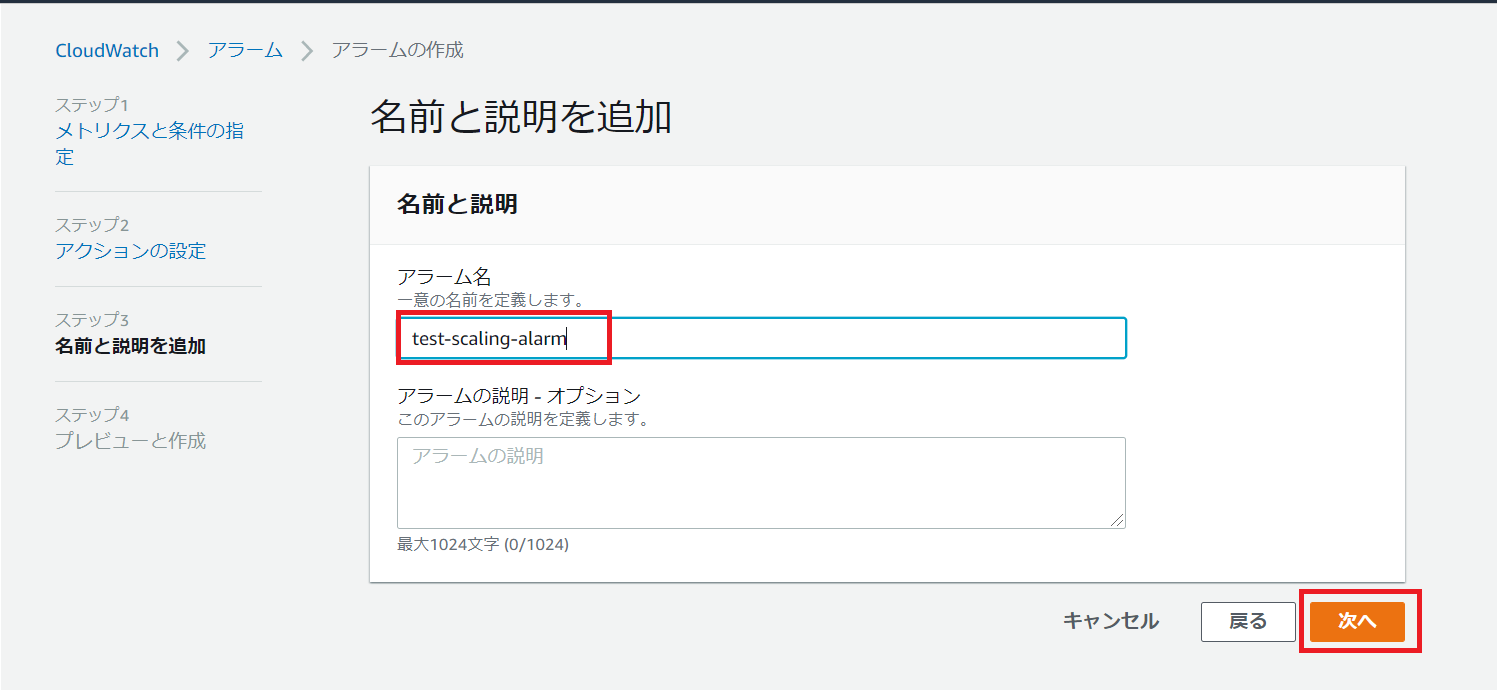
名前と説明を追加
任意のCloudWatchアラーム名を入力します。
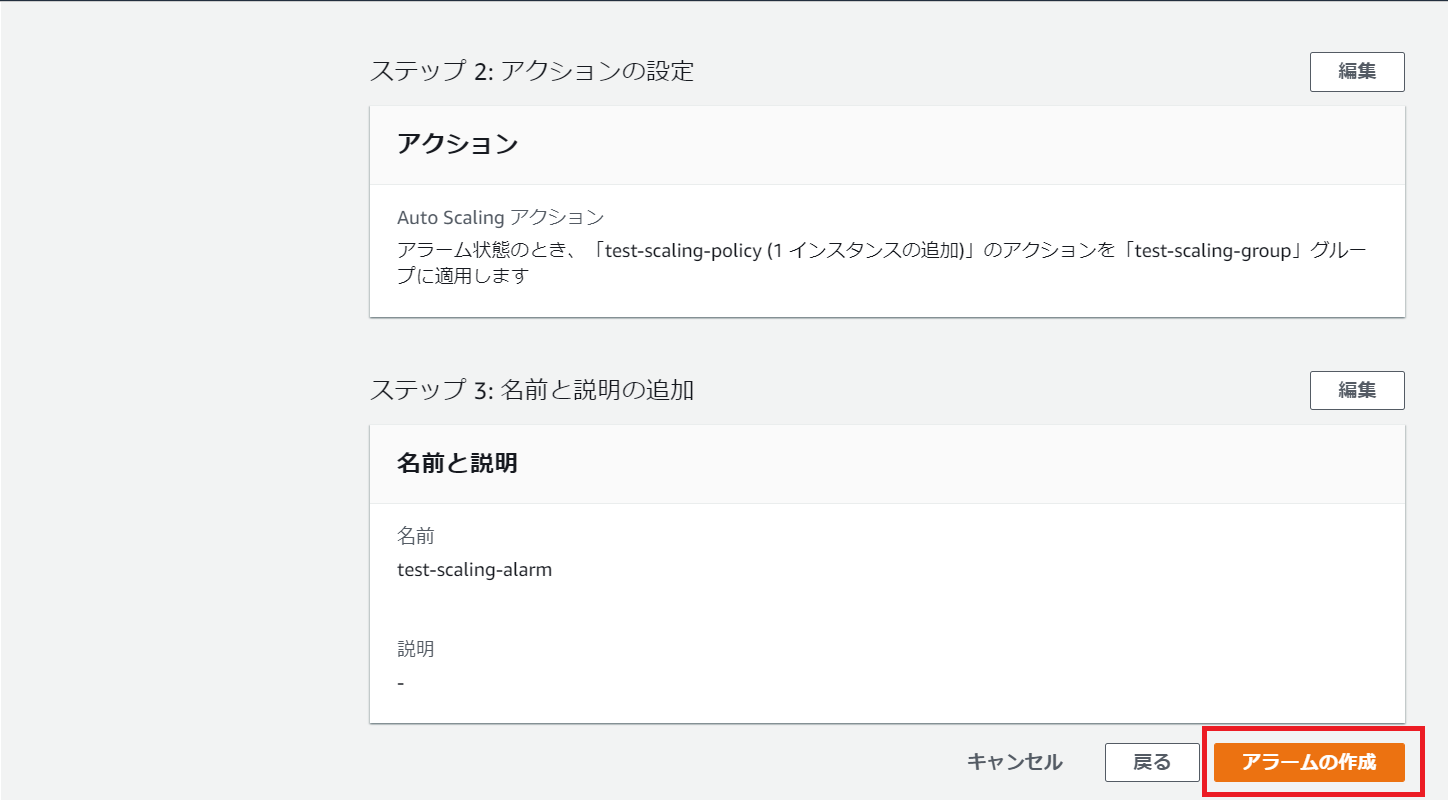
プレビューと作成
内容に問題なければアラームの作成をクリック
③アラームの簡単な動作確認
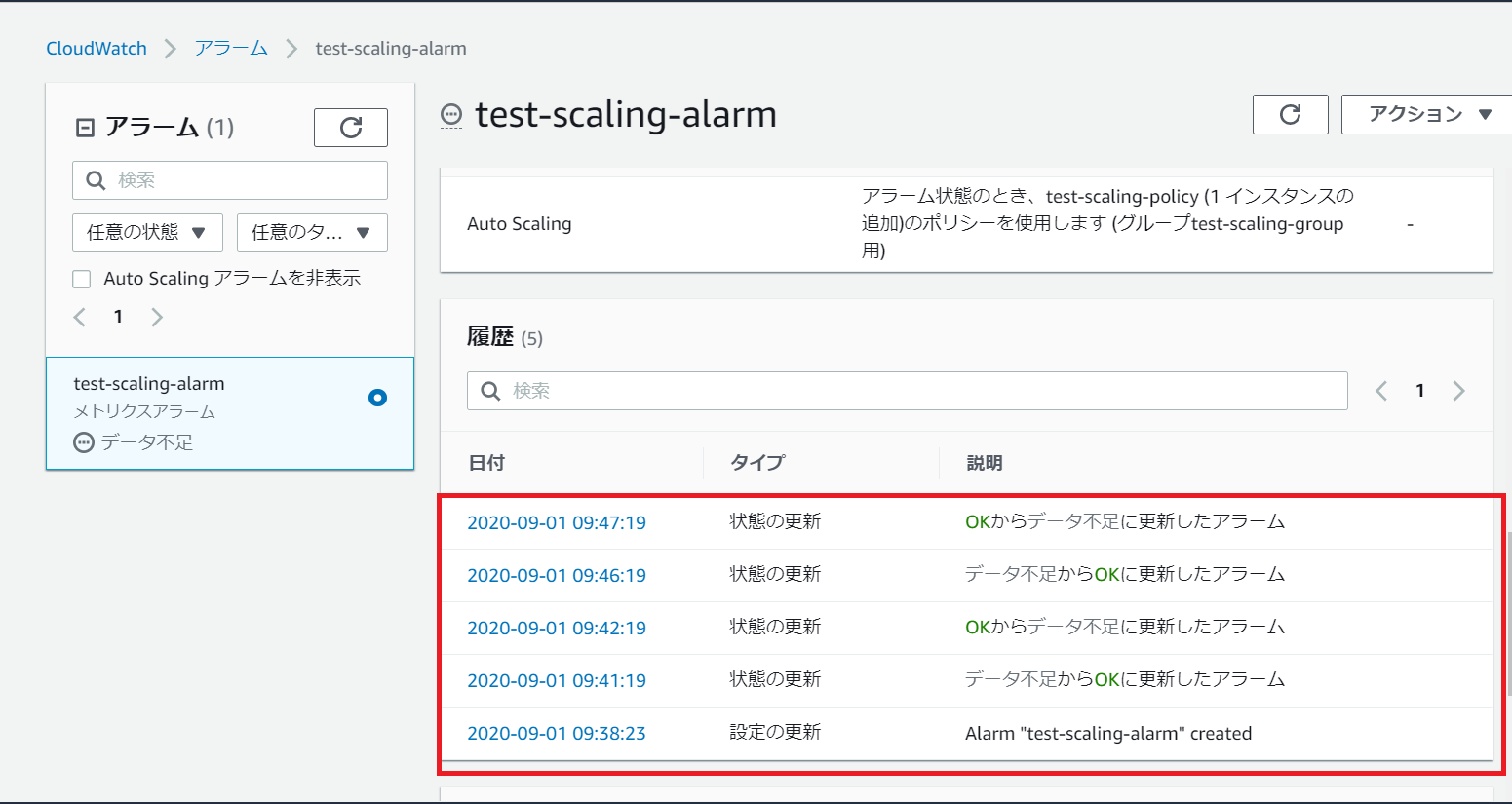
作成したCLoudWatchアラームの挙動を軽く確認します。
作成したCloudWatchアラーム詳細画面の履歴から対象アラームの動作履歴が確認可能です。
データ不足(アラームの状態を確定するためのデータが不十分であることを示す)とOK(アラームの監視条件として指定したしきい値をクリア(※)していることを示す)を行き来していれば問題ございません。
※今回で言えばAutoScalingグループ内の全EC2インスタンスのCPU使用率が80%以下
3.システム動作確認
①CPU使用率上昇用スクリプト実行
作成したAutoScalingグループ内に存在するEC2インスタンスにOSログイン後、以下のスクリプトを作成します。
# !/bin/bash
while true
do
# 存在しないコマンドを繰り返し実行
invalidcommand
done
スクリプト実行(実行後Command not foundが繰り返し出力されます。停止するにはctrl+Cを実行します)
source loop.sh
別ターミナルを開きvmstat 5を確認すると、ユーザプロセス(us)とカーネル(sy)のCPU使用率を合わせた値が100%となっていることが分かります。
[ec2-user@ip-172-31-33-157 ~]$ vmstat 5
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 492464 2088 432648 0 0 36 42 227 567 2 3 95 0 0
1 0 0 493180 2088 432648 0 0 0 4 5631 13709 34 66 0 0 0
1 0 0 491980 2088 432648 0 0 0 25 5572 13708 36 64 0 0 0
1 0 0 493056 2088 432648 0 0 0 0 5234 13960 36 64 0 0 0
1 0 0 492808 2088 432648 0 0 0 0 5709 13962 37 63 0 0 0
2 0 0 492808 2088 432648 0 0 0 0 5726 13955 35 65 0 0 0
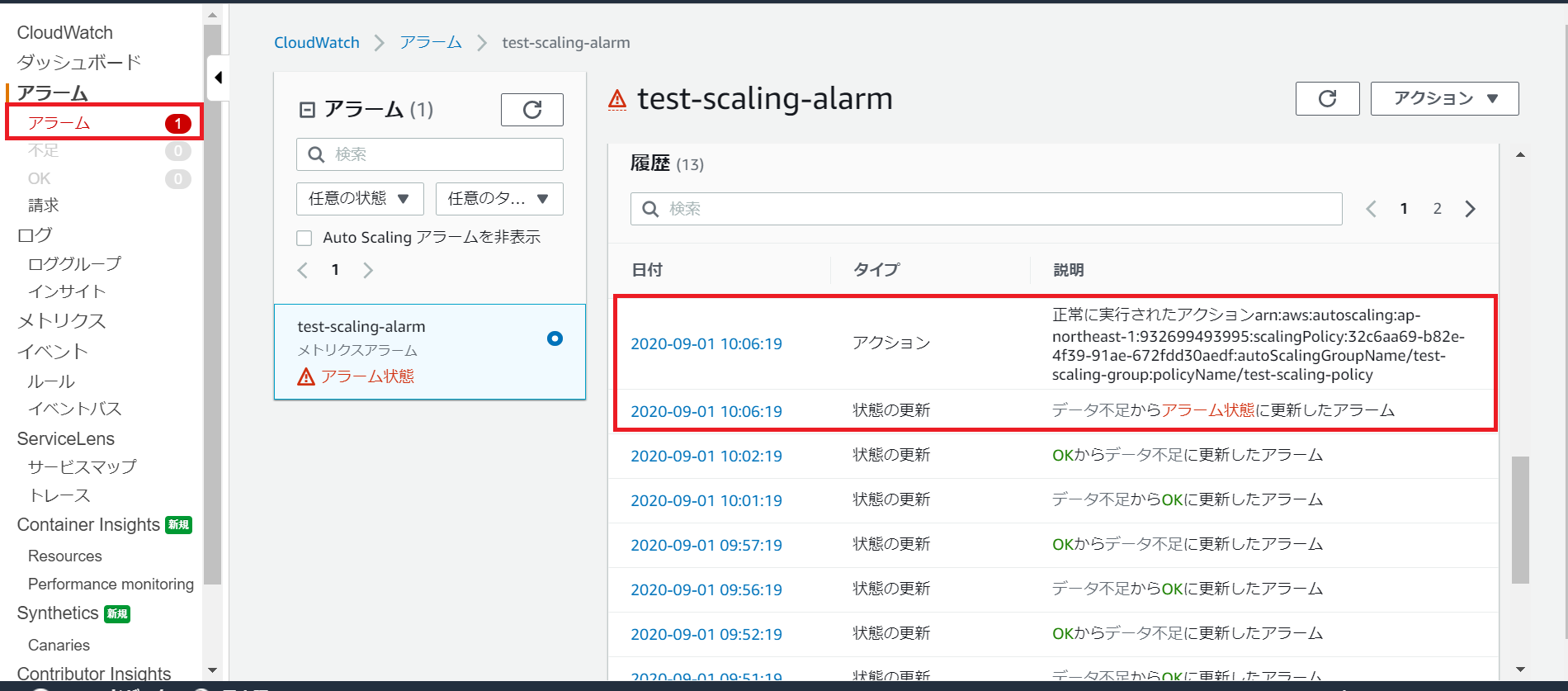
②CloudWatchアラームの確認
CloudWatchアラームを確認すると状態がアラーム(アラームの監視条件として指定したしきい値を超過していること)となり、履歴からそれに伴いAutoScalingアクションが実行されたことが分かります。
③AutoScalingグループ確認
一応AutoScalingグループも確認すると、AutoScalingアクションの実行によってグループ内のインスタンス数が1台から2台になっていることが確認できれば、システムの動作はOKです。