株式会社 ACCESS の Advent calendar へようこそ。僕は ACCESS 従業員の三原と申します。
この記事は、僕がプログラミングしたことがない、みなさまも当分プログラミングすることがないであろう命令セットの話です。面白いかはわかりませんが、おつきあい願います。
Arm SVE命令セットってなんじゃらほい?
近年話題に上がっていて、まあ話題に上がっただけで実際には進んでいないのですが、Arm命令セットのCPUがサーバに進出するのではないかと言われてきました。
そんなサーバ向けのCPUを作るためにArm社が策定したSVE命令セットは、そのアーキテクチャがちょっと面白いです。その面白みを伝えてみよう、というのがこの記事の主旨です。
なお、Arm SVE命令セットを最初に採用するCPUは、富士通と理研がポスト「京」コンピュータ向けに開発した「A64FX」です。と聞くと「どうせArmの技術でしょw」と思う方も多いと思います。でもAMDがx86互換CPUを開発したときに「どうせIntelの技術でしょw」と思うでしょうか。AMDが独自の回路設計でx86互換CPUを開発しているように、富士通は独自の回路設計でArm互換CPUを開発しました。それはIntel XeonやAMD EYPCにも負けない、絶対にスマホには載らないお化けCPUです。詳しい話は富士通がHotChips 30で発表したプレゼン資料をご覧願います。たまげますよ。
Scalable な Vector ってなんじゃらほい?
Arm SVE命令セットは略す前は "Scalable Vector Extension" と言います。ScalableなVectorとはどういうことか。Arm社のブログに説明があります。
Adoption of the VLA paradigm allows you to compile or hand-code your program for SVE once, and then run it at different implementation performance points, while avoiding the need to recompile or rewrite it when longer vectors appear in the future.
ベクタ長が可変で、将来にベクタ長が長いCPUが現れたときに既存のソースコード・実行バイナリが改変なしで動作するというのです。具体的にはベクタ長が128bit~2048bitのケースに対応できます。
どうしてベクタ長を可変にしたのか。その理由は開発者向けドキュメントにあります。
Therefore, any CPU vendor can implement the extension by choosing the vector register size that better suits the workloads the CPU is targeting.
https://developer.arm.com/products/software-development-tools/hpc/sve
Arm CPUは適用範囲が広い(組み込みからHPCまで広がっていく、予定)ので、分野によって適切なベクタ長が異なります。この状況で適用分野に最適なベクタ長をCPUに実装できるよう、命令セットレベルではベクタ長を固定しなかったというのです。
そんなことができたら素晴らしい。でも、どうやって実現しているのでしょう?
Predicate-centric Approachってなんじゃらほい?
ここから論文 https://arxiv.org/abs/1803.06185 をベースに話を進めていきます。
Arm SVE命令セットの大きな特徴は "Predicate-centric Approach" だと言います。
これは、大幅に意訳して短くすると
- ベクタ内の要素に演算を適用するか否かを記す専用のレジスタを設けて、飛び地の特定の要素にだけ演算を適用できる
- ベクタ長に応じて while 文を自動で回す分岐命令を導入している
- 結果、任意の長さのデータに任意の長さのベクタ長でループを回して、終わったところで抜けることができる
というものです。
実際のところを論文から引きます。
次のC言語関数があるとします。
void daxpy(double *x, double *y, double a, int n)
{
for (int i = 0; i < n; i++) {
y[i] = a*x[i] + y[i];
}
}
配列yの各要素に対して、配列xの各要素に係数aをかけた値を足す、という処理です。
これをスカラーなArm v8-A命令セットにコンパイルすると次のようになります。
1 // x0 = &x[0], x1 = &y[0], x2 = &a, x3 = &n
2 daxpy_:
3 ldrsw x3, [x3] // x3=*n
4 mov x4, #0 // x4=i=0
5 ldr d0, [x2] // d0=*a
6 b .latch
7 .loop:
8 ldr d1, [x0, x4, lsl #3] // d1=x[i]
9 ldr d2, [x1, x4, lsl #3] // d2=y[i]
10 fmadd d2, d1, d0, d2 // d2+=x[i]*a
11 str d2, [x1, x4, lsl #3] // y[i]=d2
12 add x4, x4, #1 // i+=1
13 .latch:
14 cmp x4, x3 // i < n
15 b.lt .loop // more to do?
16 ret
配列xの要素に係数aをかけて配列yの要素に足す処理が素直に記述されています。
これがArm SVE命令セットにコンパイルされると次のようになります。
1 // x0 = &x[0], x1 = &y[0], x2 = &a, x3 = &n
2 daxpy_:
3 ldrsw x3, [x3] // x3=*n
4 mov x4, #0 // x4=i=0
5 whilelt p0.d, x4, x3 // p0=while(i++<n)
6 ld1rd z0.d, p0/z, [x2] // p0:z0=bcast(*a)
7 .loop:
8 ld1d z1.d, p0/z, [x0, x4, lsl #3] // p0:z1=x[i]
9 ld1d z2.d, p0/z, [x1, x4, lsl #3] // p0:z2=y[i]
10 fmla z2.d, p0/m, z1.d, z0.d // p0?z2+=x[i]*a
11 st1d z2.d, p0, [x1, x4, lsl #3] // p0?y[i]=z2
12 incd x4 // i+=(VL/64)
13 .latch:
14 whilelt p0.d, x4, x3 // p0=while(i++<n)
15 b.first .loop // more to do?
16 ret
コメントを見るとスカラーな命令セットとほとんど変わりません。これがどこがベクタになるのでしょう。
https://community.arm.com/arm-research/b/articles/posts/the-arm-scalable-vector-extension-sve に分かりやすい図があるので、著作権法的にはグレーな行為ですが、引用します。
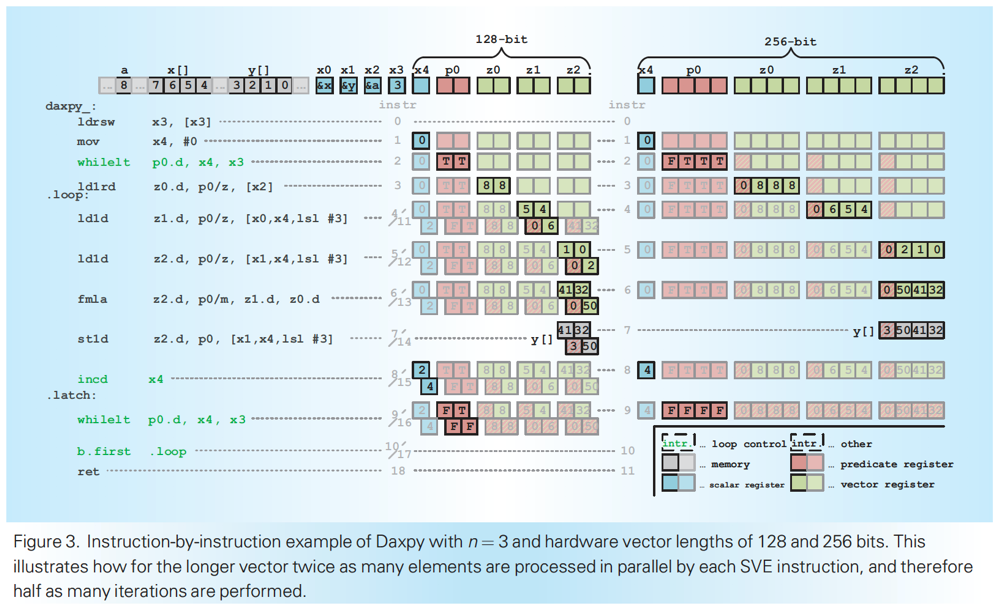
この図では、演算を適用するデータが3要素の場合が記されています。
まず右側の、ベクタ長が256bitの場合から見るのが分かりやすいです。赤いp0の4マスが、演算をベクタ内の要素に適用するか否かを決めるレジスタです。左側のソースコードで while lt ... が緑色になっているのが見えますが、if文がwhile文になり3オペランド形式になっているのがミソです。現在のインデックスとデータの末尾を比較して、演算を適用する要素に対してはtrueが、適用しない要素に対してはfalseが設定されます。ベクタ長256bitのケースでは3つtrueで1つfalseです。以降のload/store命令やfmla命令に対しては、演算を適用するとされた要素にのみ演算が実行されます。ひととおりループ内の演算が終わった後でincd x4とあるのは、ベクタの要素数をレジスタの値に加算しています。格納される値はCPUのベクタ長に依存しており、ベクタ長が256bitの場合は4(64bit浮動小数点数値が4要素)ほど加算されています。インデックスが4進んだところで再びwhile文を実行すると、全ての要素が演算の適用外となり、適用する要素がなくなったのでループを抜けます。
これがベクタ長が128bitになると、要素数が2になり、1回ループ内を実行したところで演算を適用する要素がまだ残っています。そこで分岐命令でループの先頭に戻りループが回るのです。
このような仕組みで、ベクタ長が異なるCPUで同様に動作するプログラムを定義できるのです。
結局、Arm SVE命令セットって美味しいの?
上に見たように、SIMD命令ですから自由度は低いですし、あえて抽象化している分だけCPUの実装に応じた最適化が極めて難しいことが予想されます。
しかし、大量のデータに同じ処理を繰り返すコードは確実にベクタ化できますし、一度書いたプログラムが長期間にわたって使用できることも利点です。
得意な型にはまれば、きちんと美味しいと言えると思います。
この命令セットがスマホ向けCPUコアに実装される日は来るのでしょうか。そこは見通せません。
明日も株式会社ACCESS Advent Calendarをお楽しみに。