【Web版】ONNX.jsで公開しました。
オート般若心経
【追記】漢字版もやってみました
オート手書き写経の漢字版できた。https://t.co/jcqeKtzZQg pic.twitter.com/aHONamRv2G
— a2kiti (@a2kiti) May 3, 2020

写経と自動化
こんなご時世ですし、家に籠もっているとどんどんストレスが溜まってしまいます。
心を落ち着かせるためには時間をかけて紙にお経を書き写していく写経が良いそうです。
しかし家に居るとはいえ、現代ではテレワークのおかげでいくらでも仕事はできますし、積まれた本やゲームを消化するのに忙しく,一字一句写経している時間はなかなか取れないかと思います。
般若心経F*ck、コピペで徳を高める話
そのような中,上記の記事ではコピペをすることで時間のない中でも写経をしようとする試みがなされています。
「写経」を自動化し、オートで功徳を積める仕組みを作ってみたのでございます。
さらにこの記事では効率化を求めて自動化しつつも、真心を込めてキーボードを一字一句打ち込んでいき徳を積むという、素晴らしい技術が紹介されています。
得られる徳の改善
ここで、一度により多くの徳を稼げないか考えてみます。
キーボードを一字一句真心込めて打ち込むといっても、やはり打ち終わって出来た成果物はテキストデータです。
誰がやっても同じものが出来てしまうというのは味気ないというか、少々得られる徳が少ないのではないかと感じてしまいます。
筆跡はその人の性格を表してるとも言いますし、やはり手書きの自分の字で書いたほうが徳が多そうです。
とはいってもこれはただの私の仮説ですし、得られる徳の量を判定するのは神(仏?)です。
ところでこんな本があります。
AIが神になる日
読んでないので詳細は分からないのですが、そのうちAI=神になるということでしょう。
つまり神(AI)が手書きだと判定する字で写経ですれば高い徳を得られることになります。
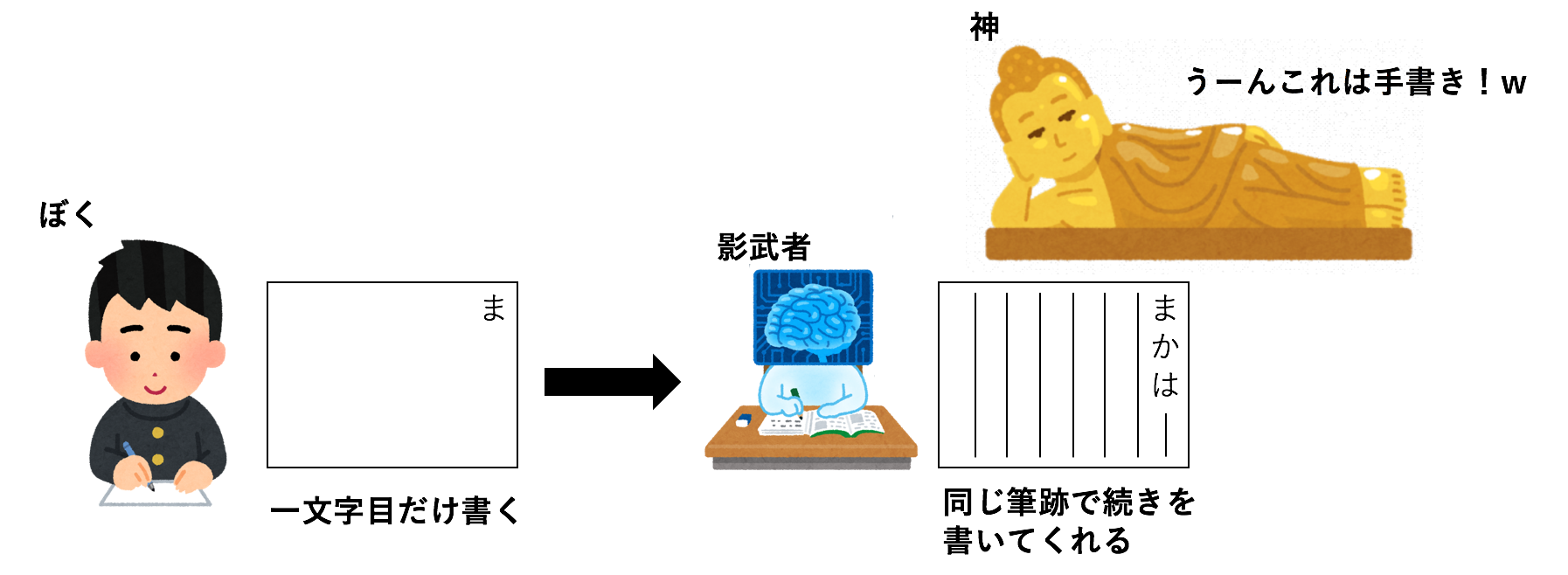
自動化するならば、最初の一文字目を自分で書くと同じ筆跡で残りを勝手に書いてくれることが理想と言えるのではないでしょうか。
GANによる文字生成
じゃあどうやってAIが手書きと思う字を作るかですがGAN(Generative Adversarial Network)というディープラーニングの技術を用います。
公開されている手書き文字の画像データとしてETL文字データベースというものがあります。

※ひらがな,カタカナ,漢字の画像データが含まれていますが,漢字はそこまで種類が多くないため般若心経の漢字が含まれていないものもあり難しそうなので今回はひらがなを対象とします。
般若心経といえば漢字ですが子供向けにひらがなで写経するものもあるみたいです。
https://www.ippoippodo.com/?pid=90428579
ひらがなか漢字かというのは問題ではなく大事なのは手書きかどうかでしょう。
この手書き画像から般若心経の文字を選んで並べてやれば完成と言うわけではもちろんありません。
これは他の誰かが書いた字ですし,適当に並べるだけでは筆跡も文字ごとにバラバラになってしまい,自分で書いていないのがバレバレです。
なのでこのデータを使って自分の筆跡の文字を生成したいと思います。
GANを簡単に説明すると,手書き文字を生成するAI①(Generator)と生成された字が偽物か本物か判断するAI②(Discriminator)を使うモデルです。
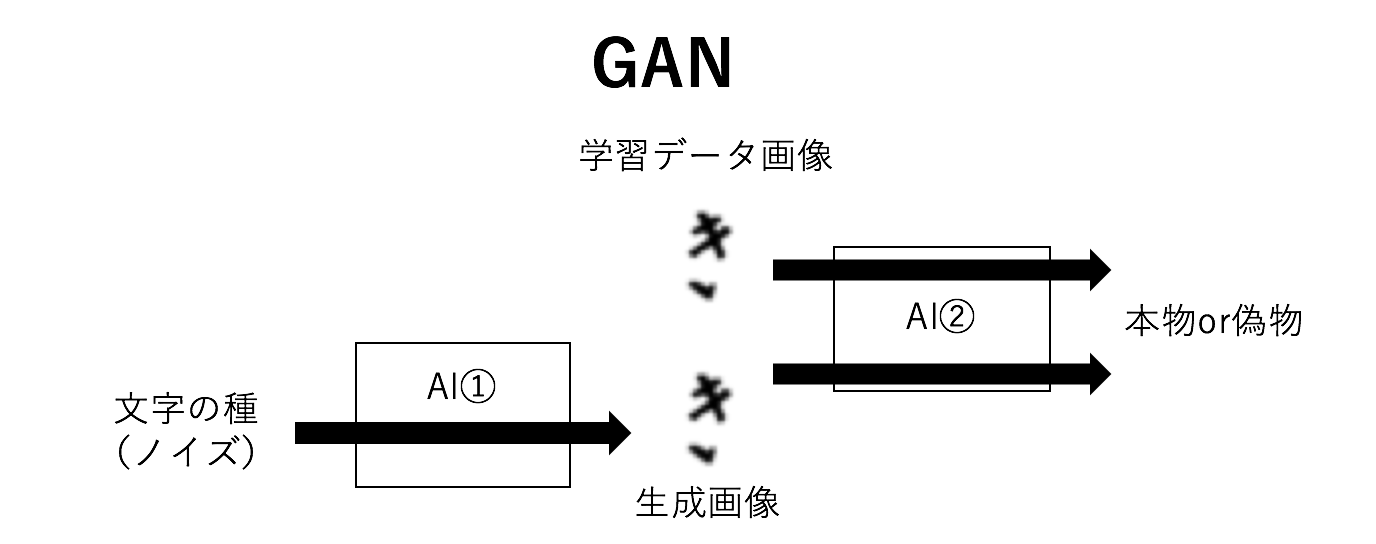
ここで本物とは学習データとして用意したたくさんの手書き文字画像のことで,偽物とはAI①が生成した手書き文字画像とします。
AI②は入力された画像が学習データに存在する本物の手書き画像か、AI①が生成した偽物か見分けるように学習していきます。一方、AI①はAI②が本物の手書き画像と騙されるような画像を生成するように学習していきます。
本記事の最初の画像において,般若心経の続きを書いてくれる影武者がAI①,神がAI②に当たります。2つのAIが競い合うように切磋琢磨して学習いくことで、影武者(AI①)は神(AI②)が本物の手書き画像と判定するような画像を生成することができるようになります。
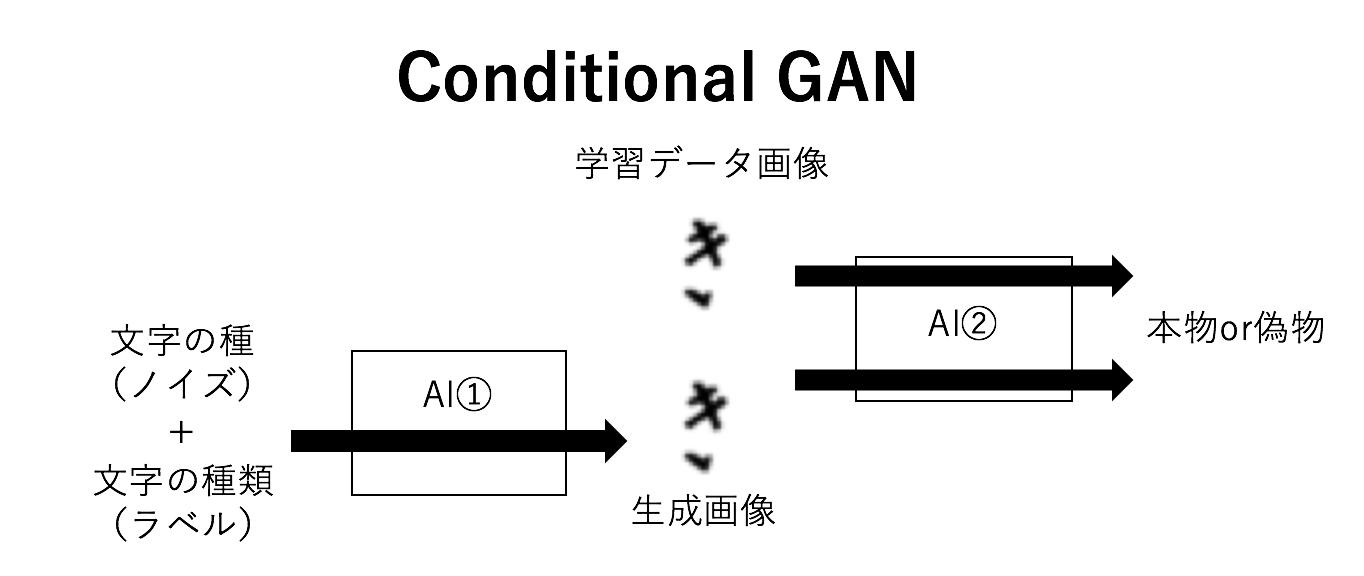
GANでAI①は乱数から画像を生成するので,そのままでは毎回何の文字が生成されるかランダムになってしまいます。
Conditional GANを用いると生成する字を指定できます。
※図では端折っていますがDiscriminatorにもラベルを入力します。
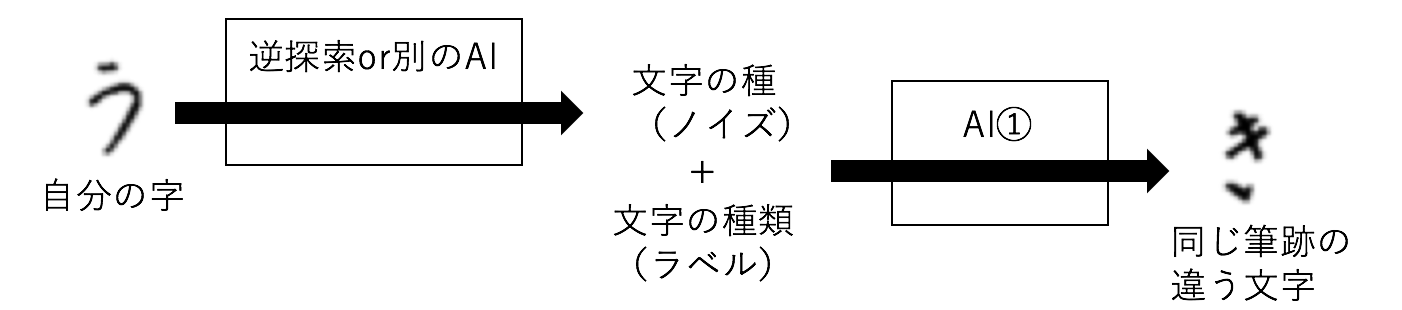
Conditional GANでAI①は文字の種(ノイズ)とラベル(生成する字の指定)を入力にとるのですが、このノイズを固定しラベルだけを変えてやると、同じ筆跡の違う字を生成することができます。つまり、自分で一文字だけ書いてその文字に対応する文字の種(ノイズ)を探し保存しておき、ラベルを変えて般若心経の各文字を生成してやると、あたかもすべて自分で手書きで写経したかのようなことが出来てしまいます!
書いた文字に対応するノイズは,勾配法で探索したり追加のニューラルネットワークを使うことで得ることができます。
できたもの

各行の一番左が適当に選んだ手書き文字です。この文字から文字の種を取得し,ラベルを各ひらがなの変えて生成させたものが同じ行に並んでいます。
どうでしょう?小さく書かれた文字に対しては,同じように小さい文字が生成されており,大きい文字からは大きい文字が生成されています。それぞれ書体もなんとなく似たような雰囲気になっており,かなりいい感じに筆跡を真似できていると言えるんではないでしょうか。
さっそくこれを使って,写経をしてみましょう。
まずは普通の字
大きめの字

小さめの字

おわり
これでより多くの徳を積むことができますね。
写経した際は書いた紙を箱に入れて保管していくそうです。
なのでできた般若心経画像は箱(HDD or SSD)に別名保存して貯めていきましょう。
今回AI②を神と見立て,神が手書きだと判定すれば高徳点としましたが(この時点でむりやりすぎますが),
GANでうまく学習されている場合AI②の正答率は五分五分程度になるはずです。
つまり,完全に神は騙されているわけではなく半分程度なのでその分得られる徳も減少していると考えられます。今後の研究では完全に神を欺けるように改善したい。(論文conclusion感)
実装の詳細
ETL文字データベースからひらがな、濁音半濁音で全部で75種類の字を抽出しました。それぞれ1000データくらいあり(濁音,半濁音は400くらい),学習時に拡大縮小と移動のData audumentationをしています。文字サイズは32×32で、ネットワークはそれぞれ4層のcnnを使っています。
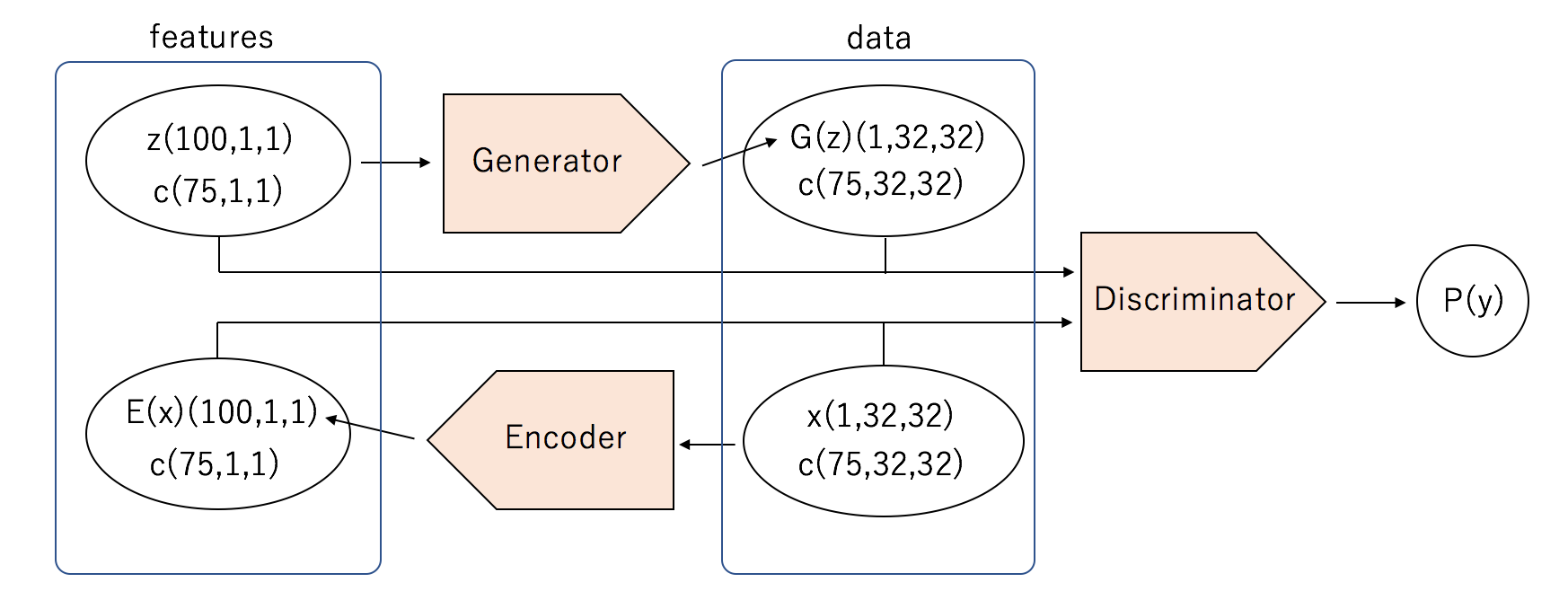
モデルの全体像は図のようにBiGANをベースにしており,Conditionalになるようにラベル情報cを各入力となるx,G(x),z,E(z)にサイズを合わせてconcatしています。Generator側のDiscriminatorへの入力は[(G(z),c),(z,c)]となりますが,(G(z),c)用のレイヤーと(z,c)用のレイヤーを別々に持っており,途中でconcatしています(Encoder側も同様)。Discreminatorへの入力でラベル情報が2重に入力されてしまっており,xもしくはE(x)にはcがいらないんじゃないかと最初思いましたが,入れないとうまく学習されませんでした。((G(z),c)用のレイヤーの学習がうまくいかないのかもしれません)また,レイヤーを分けず[G(z),z,c]を入力することもしてみましたが全くうまくいきませんでした。
BiGANをConditionalにするという発想はもちろんすでにありBidirectional Conditional Generative Adversarial Networksとして発表されています。この論文ではEncoderにラベル情報は入力せず,ラベル情報と特徴ベクトルを分離する役割も持たせているようです。しかし,今回の目的でEncoderは最初に書いた一文字目から特徴ベクトルを得ることですので,Encoderにラベル情報を与えてもいいと思います。試してないのでわかりませんが,おそらくラベルを与えたほうが学習は簡単になりそうです。
またチューニング不足なだけかもしれませんが,バッチサイズが大きくするとうまく学習が進まず,バッチサイズを下げないとうまく進みませんでした。ある程度安定したあとにバッチサイズを上げるのは大丈夫でした。
学習後のGeneratorの文字生成結果です。
横にラベルを変えた結果が並んでおり,縦にzランダムを変えた結果が並んでいます。同じ行は同じzを使っており,筆跡がおなじになっていることがわかります。

また,画像 -> Encoder -> Generator -> 再構成画像としたときの結果です。
元の画像

再構成画像

完全に復元されているわけではないですが,ほぼうまく再構成できていることがわかります。
また,推論時には同じ文字を指定すると全く同じ画像が生成されるため,zにガウシアンノイズを足すことで微妙に文字が揺らぐようにしてリアル感を出してみました。
【追記】漢字版もやってみた

やはり漢字のほうが雰囲気出そうなので,漢字版にも挑戦しました。
ETLデータセットには常用漢字3000字弱も含まれます。すべての文字を学習に使って好きな文章(手書きのお手紙とか)を生成できるようにしたかったのですが,残念ながら私の作成したモデルでは3000種ものクラスをうまく生成させることはできませんでした。
なので般若心経に登場する100種強の漢字のみを使いました。また常用漢字ではない漢字が登場するため,意味や見た目が近そうな感じに置き換えてます。
ひらがなほど筆跡を真似しきれていませんが,雰囲気はひらがなよりも出てる気がするのでより多くの徳を稼げそうです!