この記事は NTTコミュニケーションズ Advent Calendar 2019 の11日目の記事です。
昨日は @koki-sato さんの 作業手順書を docsify で作成する でした。
はじめに
セキュリティ脅威を分析する際にOSINT(Open Source INTelligence)と呼ばれる手法が用いられることがあります。OSINTとは公開されている情報源を用いた情報収集・分析活動のことで、その主たる情報源はインターネット上で公開されている記事やSNS、脅威フィードなどです。
OSINTの活用例としては、OSINTで集めた痕跡情報を参考にしてインシデントレスポンス時に発見したURLやファイルが悪性であるかを判断することなどがあります。
日々情報収集をしていると以下のような課題に直面します。
- 元情報がどこにあったか分からなくなる
- 溜め込んだ情報が多すぎて見つけられなくなる
マイ魚拓作ってみた
そこで今回はそんな課題を解決すべく、**プライベートアーカイブ(名付けて「マイ魚拓」)**を作ってみました。
目指した要件は以下の3点です
- 有料ツール/サービスを使わないこと
- 特定の端末に依存せずにいつでもどこでもアーカイブできること(端末非依存)
- アーカイブしたコンテンツの中身まで検索できること(全文検索)
これらの要件を満たすためにArchiveBoxとPocketとFessを組み合わせました。


レシピ
魚拓サーバを立ち上げる
魚拓サーバにはオープンソースのWebアーカイブツールであるArchiveBoxを選びました。
HTMLだけでなくPDFやスクリーンショット(PNG)、WARCなど様々な形式でアーカイブできるのが特徴です。
ConoHaではArchiveBoxがインストールされたテンプレートイメージが提供されていたりもします。
前提条件
Docker + Docker Composeが動くこと1
準備
必要なのはdocker-compose.ymlとnginx.confだけです。
Dockerイメージは全てDockerHubにある公式イメージを使います。
./
├ docker-compose.yml
└ nginx.conf
- docker-compose.yml
version: '3'
volumes:
archivebox-data:
elasticsearch-data01:
elasticsearch-dictionary01:
elasticsearch-data02:
elasticsearch-dictionary02:
services:
archivebox:
image: nikisweeting/archivebox:latest
stdin_open: true
tty: true
environment:
- TZ=Asia/Tokyo
- SUBMIT_ARCHIVE_DOT_ORG=False
- FETCH_MEDIA=False
volumes:
- archivebox-data:/data
shm_size: 256m
restart: always
command: bash -c '[[ -f /data/index.html ]] || ( echo "https://github.com/pirate/ArchiveBox" | /bin/archive ); tail -f /dev/null'
nginx:
image: nginx
ports:
- '8098:80'
environment:
- TZ=Asia/Tokyo
volumes:
- ./nginx.conf:/etc/nginx/nginx.conf:ro
- archivebox-data:/var/www
restart: always
fess:
image: codelibs/fess:13.4.0
ports:
- "8080:8080"
depends_on:
- elasticsearch01
- elasticsearch02
environment:
- TZ=Asia/Tokyo
- RUN_ELASTICSEARCH=false
- "ES_HTTP_URL=http://elasticsearch01:9200"
- "FESS_DICTIONARY_PATH=/usr/share/elasticsearch/config/dictionary/"
restart: always
elasticsearch01:
image: codelibs/fess-elasticsearch:7.4.0
environment:
- TZ=Asia/Tokyo
- node.name=elasticsearch01
- discovery.seed_hosts=elasticsearch02
- cluster.initial_master_nodes=elasticsearch01,elasticsearch02
- cluster.name=fess-elasticsearch
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms1g -Xmx1g"
- "FESS_DICTIONARY_PATH=/usr/share/elasticsearch/config/dictionary"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- elasticsearch-data01:/var/lib/elasticsearch
- elasticsearch-dictionary01:/usr/share/elasticsearch/config/dictionary
restart: always
elasticsearch02:
image: codelibs/fess-elasticsearch:7.4.0
environment:
- TZ=Asia/Tokyo
- node.name=elasticsearch02
- discovery.seed_hosts=elasticsearch01
- cluster.initial_master_nodes=elasticsearch01,elasticsearch02
- cluster.name=fess-elasticsearch
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms1g -Xmx1g"
- "FESS_DICTIONARY_PATH=/usr/share/elasticsearch/config/dictionary"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- elasticsearch-data02:/var/lib/elasticsearch
- elasticsearch-dictionary02:/usr/share/elasticsearch/config/dictionary
restart: always
ArchiveBoxの公式Dockerイメージはlatestタグしかないので分かりにくいですが、今回は12/1時点のバージョンのArchiveBoxを使用しています。
また、ArchiveBoxの環境変数は公式ドキュメントを参考にしつつお好みで。
上記の例では、Archive.orgへのアップロード(SUBMIT_ARCHIVE_DOT_ORG)とメディアファイルの取得(FETCH_MEDIA)をそれぞれ無効にしています。
- nginx.conf
nginx.confはArchiveBox公式の設定を持ってくるだけです。
サーバ起動
docker-compose up -d
動作確認(マイ魚拓の閲覧)
マイ魚拓のトップページはhttp://localhost:8098/からアクセスできます。2
取り込みが問題なく完了していれば、以下のような画面が見えます。

魚拓へのデータ投入
ArchiveBox公式ドキュメントにはdockerコマンドを用いた方法は書かれていますが、docker-composeコマンドを用いた方法は書かれていません。
公式ドキュメントと同じことをdocker-composeで実現するコマンドは以下の通りです。
echo 'https://example.com' | docker-compose exec -T archivebox /bin/archive
# or
cat bookmarks.html | docker-compose exec -T archivebox /bin/archive
# or
docker-compose exec archivebox /bin/archive 'https://example.com/some/rss/feed.xml'
「いつでもどこでも」の実現(Pocket連携)
このままではArchiveBoxが稼働している端末でコマンドを実行しないと魚拓が取れないので不便です。
人間は忘れる生き物なので移動中の隙間時間で調べ物をしている最中でもすぐに魚拓が取りたくなります。
そこで外部サービスであるPocketと連携させます。
Pocketはインターネット上の記事などのコンテンツの一覧を保存し、あとでまとめて読むためのサービスです。
Pocketには保存した一覧をRSSで公開する機能があるため、今回はこれを活用します。
-
Pocket RSS公開設定
無料アカウントを作成後、アカウントオプションのプライバシー設定でRSS フィードのパスワード保護を解除します。3
これでPocket側の準備は完了です。 -
RSSの定期取得
あとはArchiveBox側でcronで定期的にRSSを取得・アーカイブするように仕込めば連携は完了です。
具体的には、以下のようなコマンドをcron実行します。4
docker-compose exec archivebox /bin/archive 'http://getpocket.com/users/PATH-TO-MY-FEED/feed/all'
Pocketは主要ブラウザの拡張機能として利用できますし、AndroidやiPhoneアプリも存在します。
複数の端末で同じPocketアカウントを使って気になったページを随時Pocket保存しておけば、いつでもどこでも勝手に魚拓を取ってくれるわけです。
全文検索の実現(Fess設定)
ここまででいつでもどこでも魚拓が取れるようになりましたが、実はArchiveBox標準の検索機能はタイトルしか検索できません。
これでは必要な時に情報を振り返って活用することができません。
そこで最後に登場するのがFessです。
Fessは「5分で簡単に構築可能な全文検索サーバー」を謳ったオープンソースの全文検索サーバーです。
機能が豊富で、Web・ファイルシステム・Windows共有フォルダ・データベースなど様々な方式でクロールができ、MS Office(Word/Excel/PowerPoint)やPDFなど多くのファイル形式に対応しています。
すでに魚拓サーバの起動と共にFessも起動しているため、http://localhost:8080/からアクセスすることができます。5
Fessを設定するには、管理画面(http://localhost:8080/admin)に管理者としてログインします。
デフォルトのユーザ名・パスワードは公式ドキュメントに記載の通り、どちらもadminです。
魚拓の検索に必要な設定は最低限以下の2点です。
- クローラ設定
- パスマッピング設定
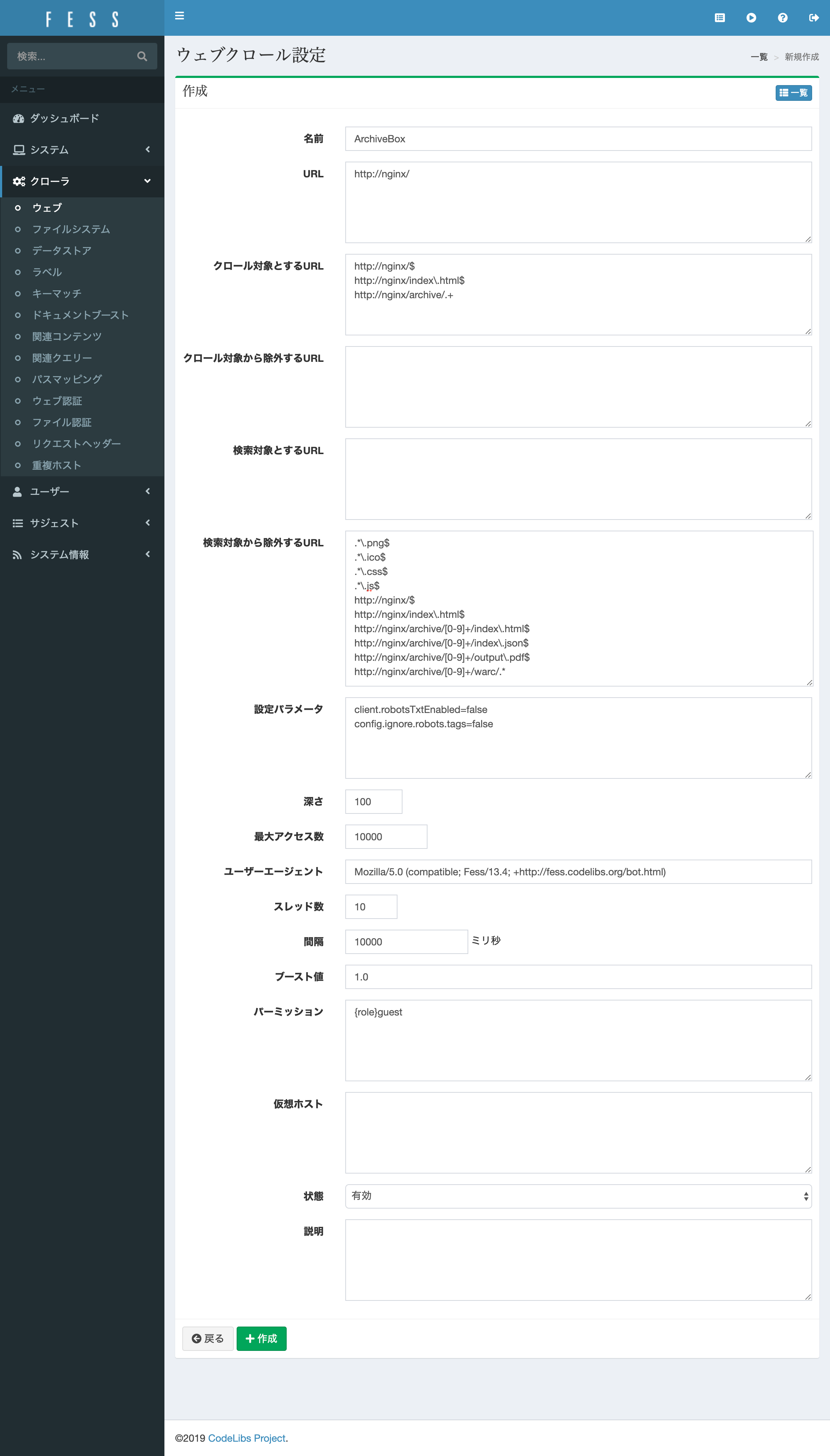
クローラ設定
ArchiveBoxを巡回し、検索インデックスを作成するためのクローラ設定を新規作成します。
スレッド数や間隔の値は端末のスペック応じて調整してください。
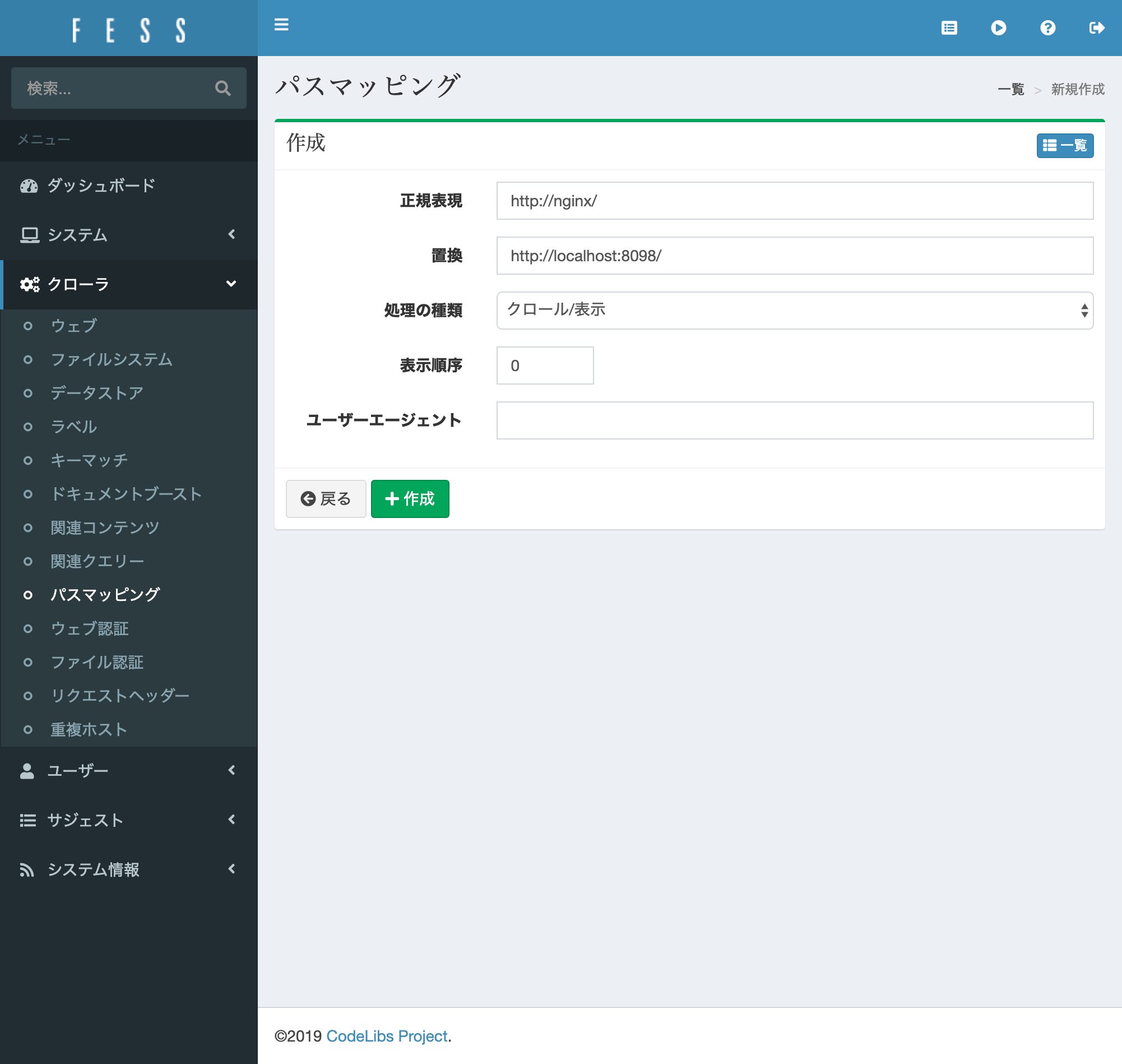
パスマッピング設定
前述のクローラ設定はDockerの内部ネットワーク経由でArchiveBoxにアクセスさせているため、そのままでは検索結果のリンクが外部からアクセス可能なURLになりません。
そのためパス文字列の置換を行うパスマッピングを設定します。
動作確認(手動クローリング)
デフォルトでは日次でクローリングが走りますが、スケジュール設定画面から手動でクローリングを回すこともできます。
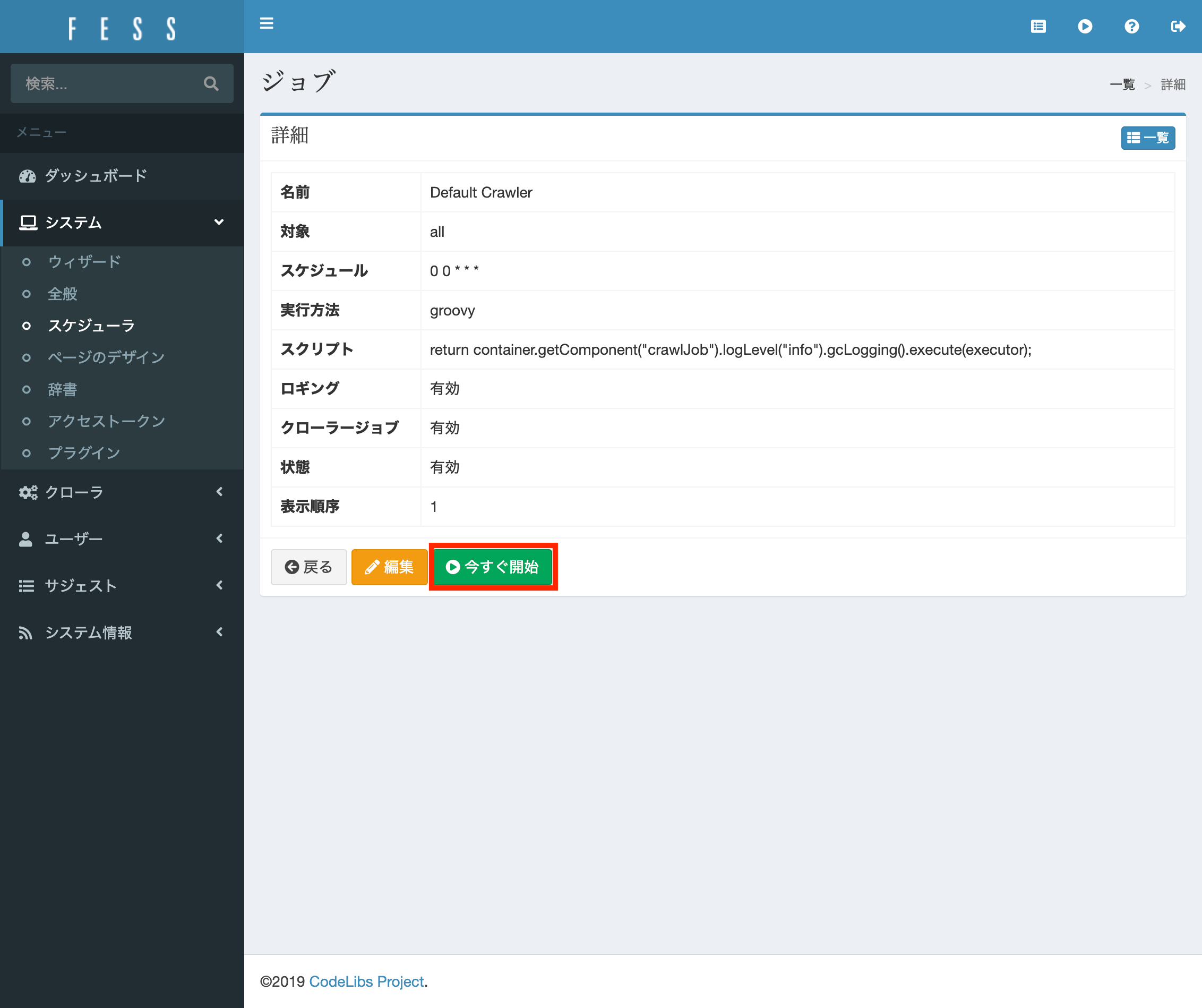
クローリングの実行完了はジョブログから確認ができます。

無事インデックスが作成されれば晴れてコンテンツも含めた全文検索ができるようになります。
おわりに
より効率的なOSINTを実現するためにマイ魚拓を作ってみました。
サイトによってはアーカイブの表示が崩れたり、拡張子の付いていない画像ファイルが検索インデックスに含まれてしまったりするなど、細かいところで気になる部分はまだありますが、個人的には十分なクオリティが実現できて満足です。
次はOCRを使った画像内文字列の検索インデックス化をやりたいと企んでいます。
それでは皆さんも良いOSINTライフを!
明日は @nitky さんです。お楽しみに!