内容
前回Tableauで東京23区の人口をマップ表示しました。
これをSnowflakeでやってみようというのが今回の記事です。
下準備
前回の下準備としてダウンロードしていた
・東京都のポリゴンデータ(拡張子が.geojsonのファイル)
・東京都の人口データ(拡張子が.csvのファイル)
をそのまま使います。
学ぶ
ググってたらTrueStarさんの記事にあたりました。
まずはこのソースをマルコピしてSnowflakeのNotebookに貼り付けてみます。
初めてSnowflakeでNotebookを使うのでドキドキです。
貼り付けて実行したところ以下のエラーが出ました。
ModuleNotFoundError: Line 9: Module Not Found: geopandas. To import packages from Anaconda, install them first using the package selector at the top of the page.
geopandasというモジュールがNot Foundと言われてます。

画面ヘッダーのパッケージからgeopandasと入れて検索し、クリックすればインストールされます。

すぐに実行ボタンを押そうとしましたが、実行ボタンがグレーになっていて「パッケージを更新中…」とtooltipが出てきますのでしばらく待ちます。
実行ボタンが押せるようになったら押します。
また同じようにpydeckがNot Foundとのことで同様の手順でクリアします。
ModuleNotFoundError: Line 14: Module Not Found: pydeck. To import packages from Anaconda, install them first using the package selector at the top of the page.

geopandas
pydeck
の2つが追加されればOKです。
再度実行します。

地図キターー!
人口の多い東京が赤、大阪とか神奈川が茶色っぽい、埼玉や愛知が薄い茶色、であとは緑の濃淡で表現されました。
ここまで、SnowflakeのNotebookで初めて試してみた感じです。
今までPythonは自分のPCのリソースでやるものだったのですが、Snowflakeのリソースで動かすのはなんか新鮮です。
いよいよ本題(のデータアップロード部分)

前回Tableauで試したこの地図をSnowflake上で作ってみようというチャレンジです。
ソースはさっき試したTrueStarさんのコードをちょっとだけ変えて、東京都のデータだけでやります。
※TrueStarさんはSnowflakeのMarketPlaceでPODBという無料データを公開していて、そのうちの都道府県データを使って地図を作るというのが先ほどやったことなのですが、今回は前回のTableauでやったのと同じデータを使いたいので、Snowflake上にgeojsonファイルとcsvファイルをアップロードするところからです。
SnowSightのGUIでデータファイルをアップロードしてテーブル作成する機能があります。

左メニューの「データ」→「データを追加」→「テーブルにデータをロード」を選びます。
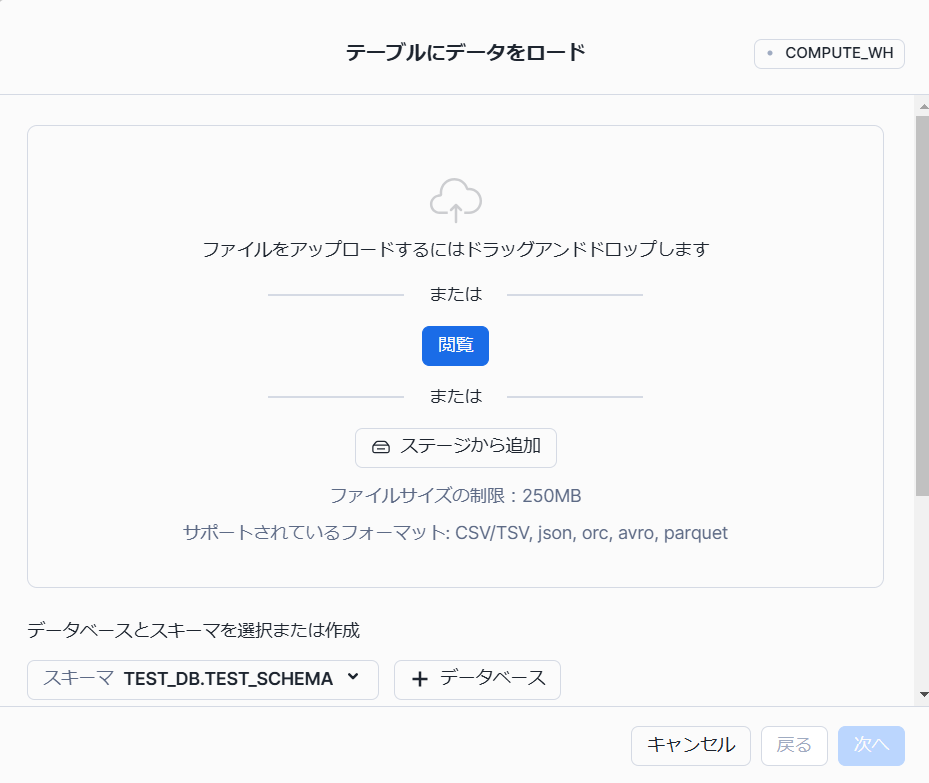
ファイルをアップロードできる画面が上がります。
下にスクロールすると
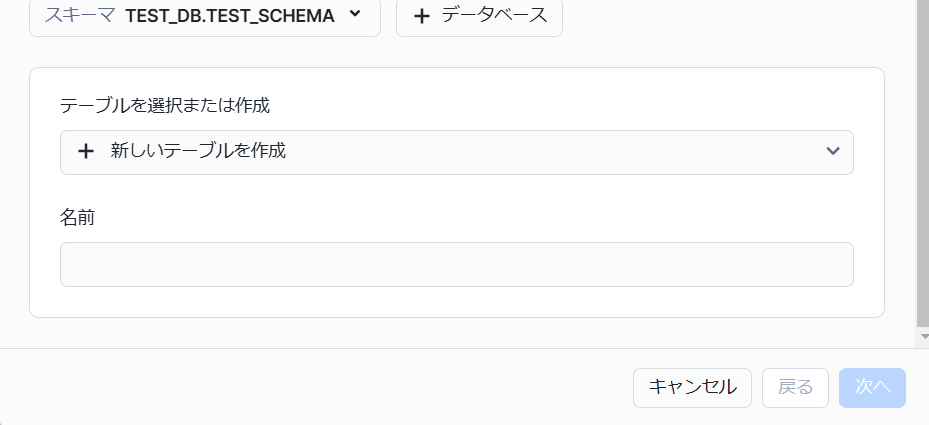
新たなテーブルを作る場合はテーブル名をセットできます。
※既存のテーブルにデータを追加することもできます。
まずは人口データを保持しているcsvファイルをアップロードします。
読み込むファイル:js24av0000_1.csv
名前:TOKYO_POPULATION
「次へ」で進みます。
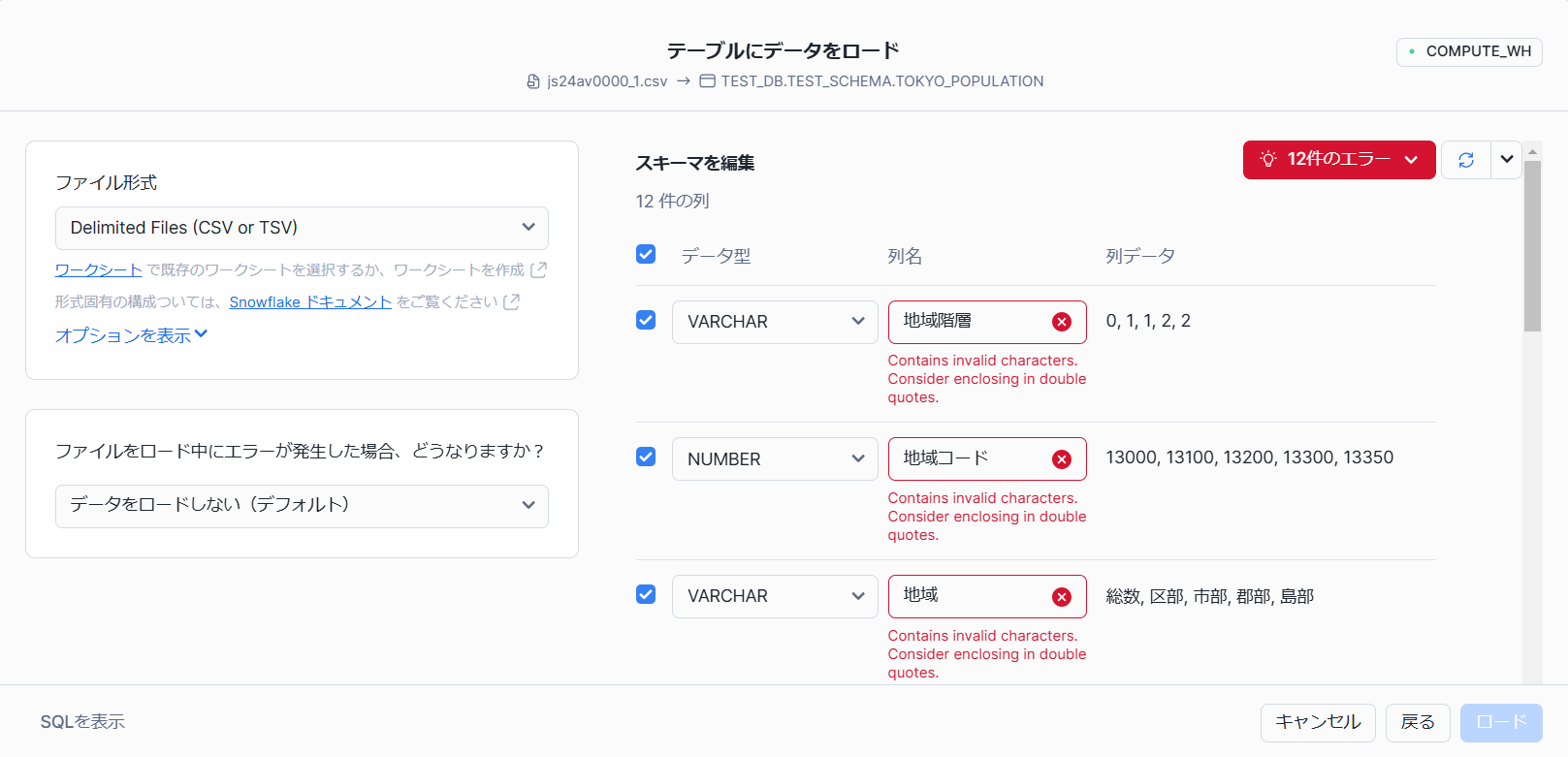
エラーがいっぱい出てますが、焦らないでOKです。
列名が2バイト文字なのがinvalidだと言ってます。すべて同じエラーです。
1バイトでの列名を考えるのが面倒なので、""で囲みます。
例:"地域階層"
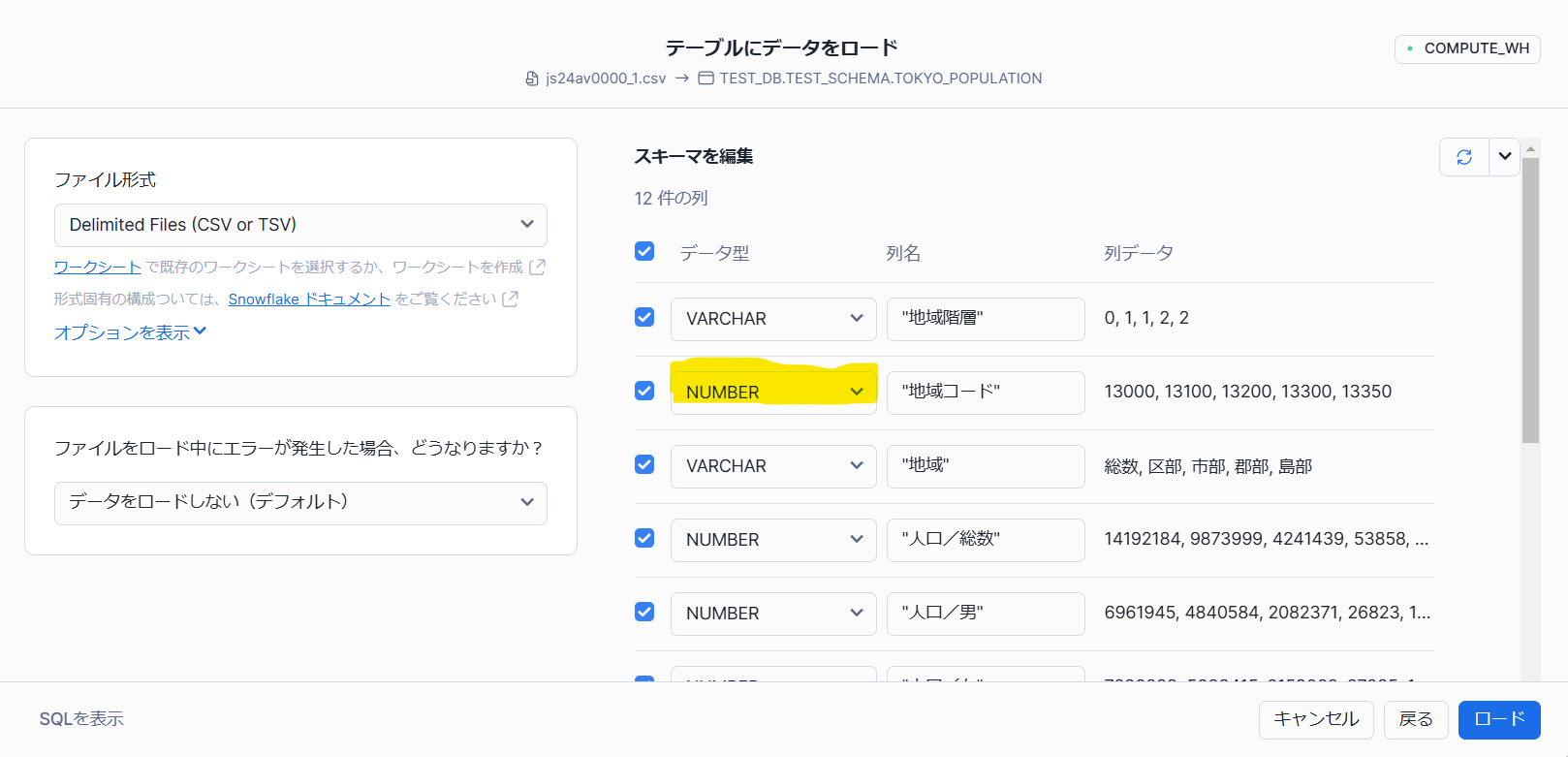
全列を""で囲ったらエラーがすべて消えます。
前回Tableauでやった時に地域コードが数値なのを文字列に変更するということをしました。
画像で黄色に塗った部分、NUMBER型になっているのでVARCHAR型に変更しておいた方がよさそうです。
変えましょう。

できたようです。
次にポリゴンデータのgeojsonファイルをアップロードします。
読み込むファイル:N03-19_13_190101.geojson
名前:TOKYO_POLYGON
「次へ」で進みます。
ここは先ほどと同様の手順のため画像省略です。
次の画面に行くと先ほどとはちょっと違ってこんな画面でした。

ファイルの拡張子が.geojsonで、どのファイル形式なのかSnowflakeが判断つかなかったためと思われます。
ファイル形式のところでJSONを選びましょう。
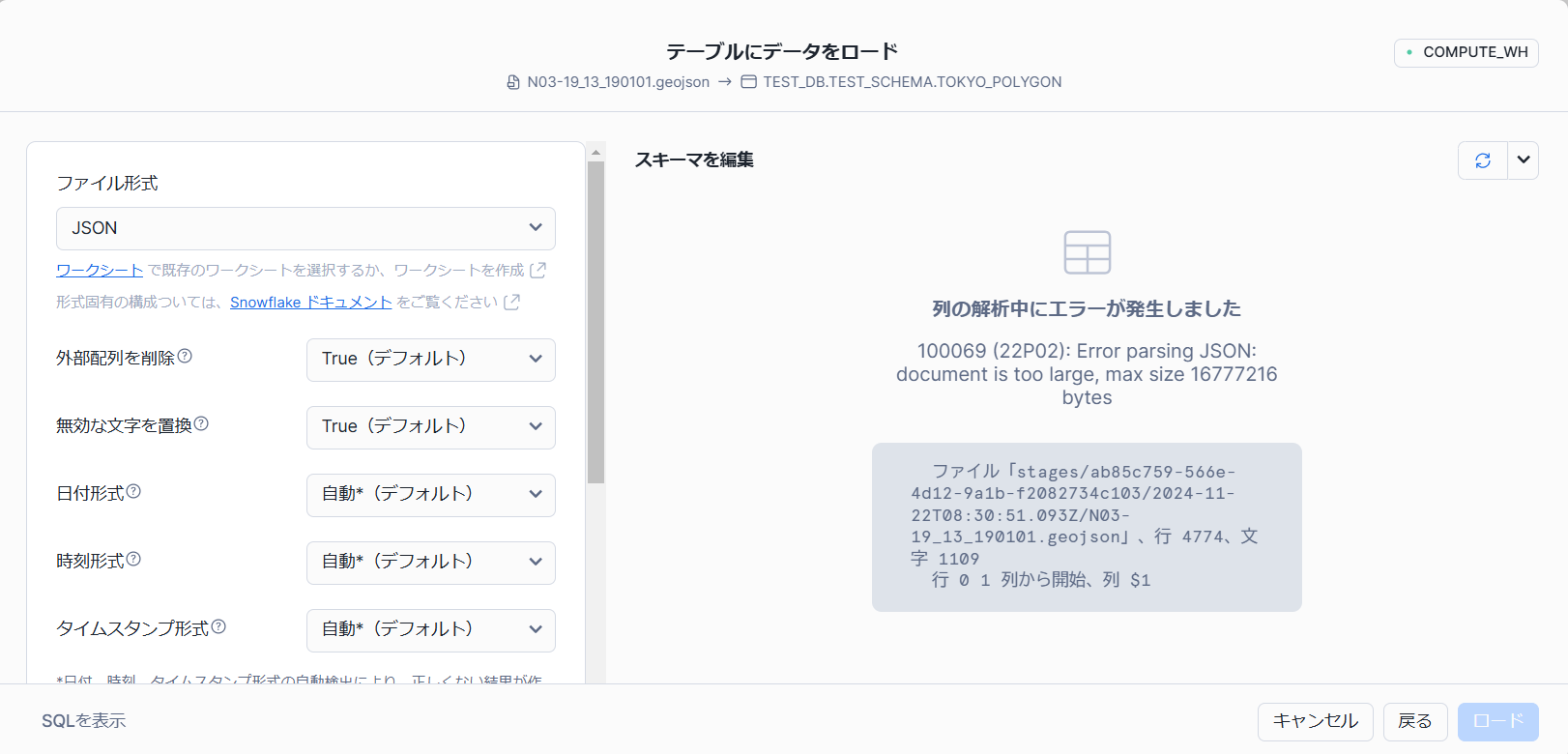
列の解析中にエラーが発生しました
100069 (22P02): Error parsing JSON: document is too large, max size 16777216 bytes
JSONのサイズは16MBまでというエラーです。
公式ドキュメントを見てみます。
半構造化データサイズの制限
VARIANT の最大サイズは16 MB です。しかし実際には、内部的なオーバーヘッドのために最大サイズは小さくなるのが普通です。最大サイズは保存されるオブジェクトにも依存します。
データが 16 MB を超える場合は、 COPY INTO <テーブル> コマンドの STRIP_OUTER_ARRAY ファイル形式オプションを有効にして、外部配列構造を削除し、記録を別のテーブル行にロードします。
「外部配列を削除」は「True」になってるので、どうしましょう。
読み込む実際のファイルをテキストエディタで見てみます。
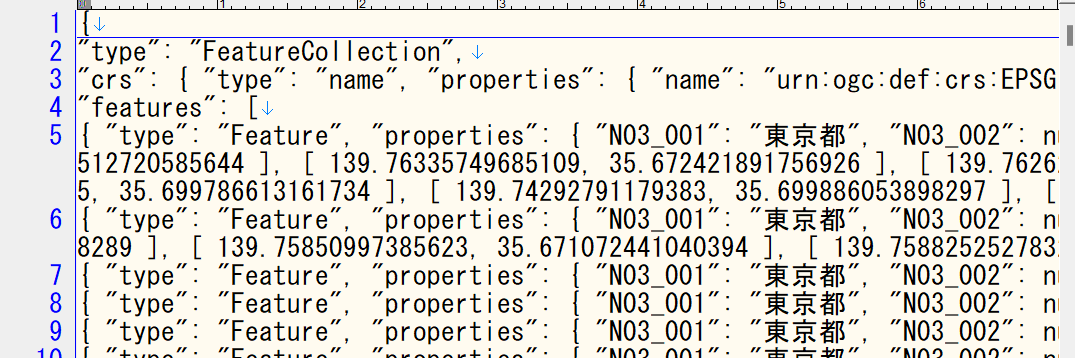
なんか眺めてたら1行目~4行目、削除しても良さそうに見えてきました。

1行目~4行目に対応するカッコの締め部分の末尾2行も併せて削除してみます。
これでファイルを別名で保存(N03-19_13_190101_rename.geojson)して再度チャレンジです。
読み込むファイル:N03-19_13_190101_rename.geojson
名前:TOKYO_POLYGON
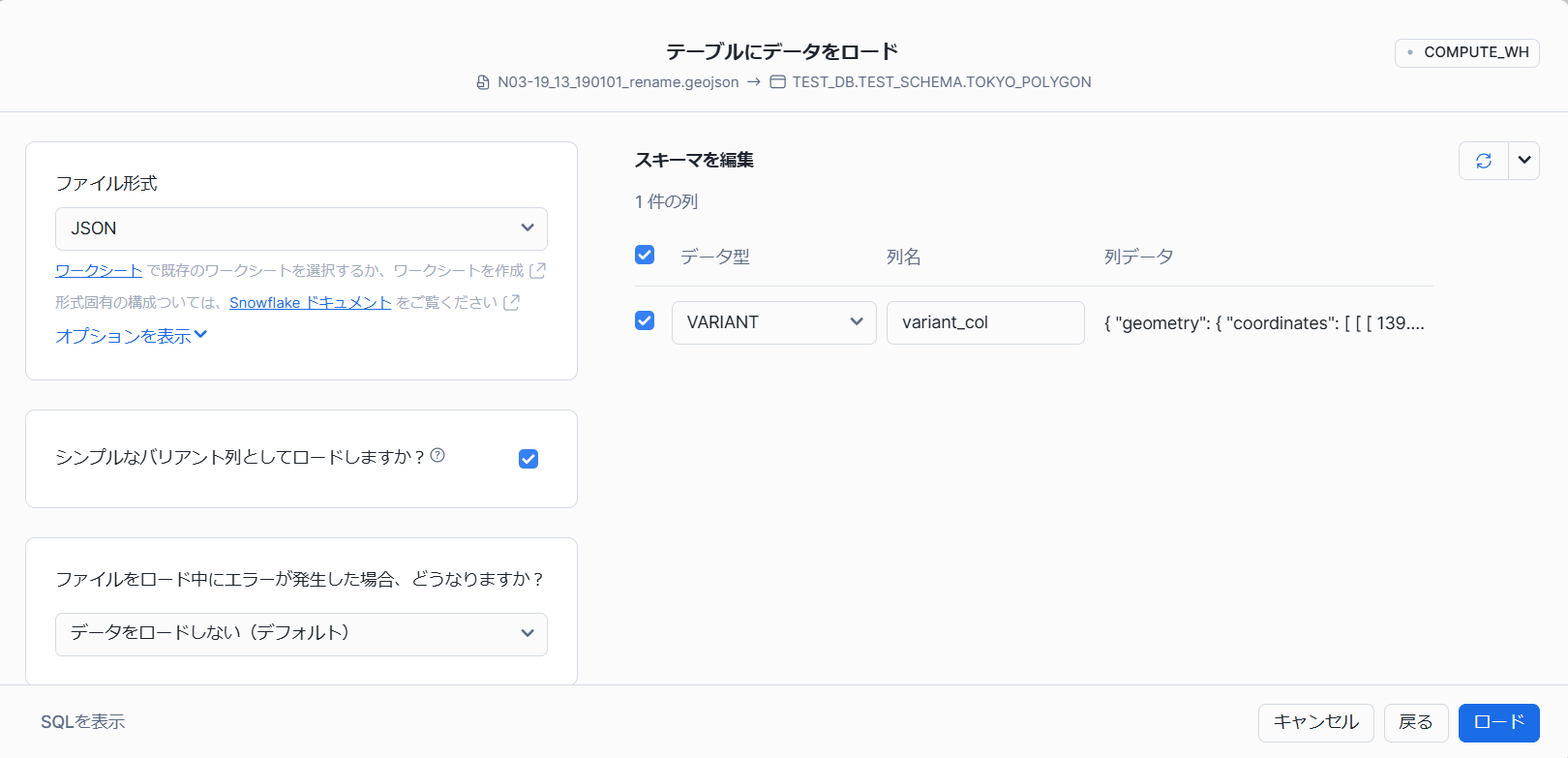
ビンゴ!
エラー回避!
「ロード」を押します。

ロードできました。
「クエリデータ」を押すとワークシートが開きます。
デフォルトで10件を*で取ってくるSELECT文がセットされてます。
それは試しても試さなくてもいいので省略。
2テーブルをJOINして、さらに23区で絞るため(Tableauの時に後方一致の"区"でフィルターをつけたので同条件にするため)WHERE句を付けます。
SELECTの項目はTrueStarさんのサンプルで試したのと同じ並びになるようにしました。
SELECT
AS_VARCHAR(VARIANT_COL:properties.N03_004) AS "地域名"
,AS_VARCHAR(VARIANT_COL:properties.N03_007) AS "地域コード"
,tokyo_population."人口/総数"
,VARIANT_COL:geometry AS GEO_JSON
FROM
TOKYO_POLYGON
INNER JOIN TOKYO_POPULATION ON
TOKYO_POLYGON.VARIANT_COL:properties.N03_007 = TOKYO_POPULATION."地域コード"
WHERE
tokyo_population."地域" LIKE '%区'
;
これを実行すると

113行取れました。
列名を2バイト文字じゃなくて1バイト文字にしておきましょう。
AS "地域名"⇒AS CITY_NAME
AS "地域コード"⇒AS CITY_CODE
"人口/総数"⇒AS POPULATION
と変えました。(画像省略)
いよいよ本題(の可視化部分)
ここからNotebookを新規起動します。
まず、geopandasとpydeckはインストールしておきます。
TrueStarさんのブログ記事を試した際は1つのセルでまとめてやっちゃいましたが、
今回はセルを分けます。
Cell1
# 必要なライブラリをインポート
import streamlit as st
from snowflake.snowpark.context import get_active_session
import json
#geo版のPandas
import geopandas as gpd
#geoデータの補正関数
from shapely.geometry import shape
from shapely.validation import make_valid
#geoデータの表示
import pydeck as pdk
# Snowflakeからデータを取得する関数をキャッシュ化
@st.cache_resource
def create_source():
session = get_active_session()
# Snowflakeからデータをクエリして取得
df = session.sql('''
SELECT
AS_VARCHAR(VARIANT_COL:properties.N03_004) AS CITY_NAME
,AS_VARCHAR(VARIANT_COL:properties.N03_007) AS CITY_CODE
,TOKYO_POPULATION."人口/総数" AS POPULATION
,VARIANT_COL:geometry AS GEO_JSON
FROM
TOKYO_POLYGON INNER JOIN TOKYO_POPULATION ON
TOKYO_POLYGON.VARIANT_COL:properties.N03_007 = TOKYO_POPULATION."地域コード"
WHERE
TOKYO_POPULATION."地域" LIKE '%区'
''').to_pandas()
return df
# データの取得
df = create_source()
# 確認用
df
df.index
SQL部分を変えて、最後にdataframeの確認用出力を入れました。
ここまでで実行してみます。

よさそうです。
次にPythonのCell2を作って続きを書きます。
#GeojsonからGeometryに変換
def trans_shape(x):
geometry = shape(json.loads(x))
if geometry.is_valid:
return geometry
else:
return make_valid(geometry)
# GeoDataFrameに区名・人口・ポリゴン(GeojsonからGeometryに変換したもの)を格納
# COLORカラム:人口をもとにしたポリゴンの色
geometry = [trans_shape(row) for row in df['GEO_JSON'] ]
gdf = gpd.GeoDataFrame(df[['CITY_NAME', 'CITY_CODE', 'POPULATION']].reset_index(), geometry=geometry)
gdf["color"] = [[i*255, (1-i)*255, 0, 140] for i in gdf['POPULATION']/gdf['POPULATION'].max()]
# ポリゴン地図の可視化
layer = pdk.Layer(
"GeoJsonLayer",
data=gdf, # GeoDataFrameを指定
get_polygon="geometry.coordinates", # Geometry辞書のgeometry.coodinatesの中に地理データが入っているので指定
get_fill_color='color', # ポリゴン色はCOLORカラムを指定
)
fig = pdk.Deck(
layers=[layer],
map_style="mapbox://styles/mapbox/light-v9", # ベースマップを指定
initial_view_state=pdk.ViewState( # マップの初期表示の拡大度、中心を指定
latitude=35.6940, #千代田区の緯度
longitude=139.7538, #千代田区の経度
zoom=10,
)
)
# 地図を表示
st.pydeck_chart(fig)
元のTrueStarさんのソースから変えたのは
PREF_NAME⇒CITY_NAME
PREF_CODE⇒CITY_CODE
latitude=35.6940, #千代田区の緯度
longitude=139.7538, #千代田区の経度
zoom=10
くらいです。
実行します。

地図キターー!(2回目)
Tableauだと区の名称と人口をラベルで表示するのができたのですが、pydeckでテキストを表示する方法はわかりませんでした。
ご存じの方、コメントなどで教えてください。
今回の地図は透過で表示されたので、ある程度区の名前は見えますね。
Tableauの時もそうでしたが大田区は見切れガチになってしまい大田区民の皆様、申し訳ないです。
まとめ
自分のTableauでやってみた記事
+
TrueStarさんの記事
の合わせ技で初Notebookでの地図表示をやってみました。
TrueStarさんの記事にはコードの説明がしっかりしてあるので、ぱっと見で理解できていないところがまだあるのでちゃんと読んで理解しないとなと思っております。
Snowflake上のデータとコンピュートリソースでSnowflake内でこれだけできるんだなーと実感できました。
補足
※TrueStarさんのPODBを使えば自分でデータをアップロードしなくてもすでにSnowflake内で公開されているデータを使えるのでもっと楽です。