この記事は、Kaggle Advent Calender 2021 の16日目の記事です
0.はじめに
Advent Calender へは初めて参加いたします。
kaggle を題材に何らか執筆するのも初めてですので、大変神妙な気分です。
今日はみなさまに向けて、私がとあることを始めて2か月弱でkaggle Expert になった経緯を記します。
これからkaggleを始める方、始めて間も無い方や、なかなかメダルが獲得できずにモチベーション維持に悩みを持つ方々に参考になれば。
1.背景
kaggleには2021年7月にアカウントを作成していましたが、チュートリアルの流れで、タイタニック号の生存者予測をしたくらいでした。
そこから約ひと月は何もせずに放置状態でしたし、8月も中旬に入ってからも当時開催中であったコンペにて公開notebookをそのままcopy&submitするというくらいでした。
本格的に?kaggleに向き合ったのは 「30days of ML」 が開催された9月。
ここでも、予測結果はLeaders Board(以下、LB)の遥か下のほうに載る程度です。
続いて参加したコンペも、同様にpublic scoreを上げられずに、LBでは下位を彷徨うのが精いっぱいでした。
2.転機
kaggleを始めてすぐに購入していた、『Kaggleで勝つデータ分析の技術』(技術評論社) を再度読み込んだことです。
章ごとにコンパクトにポイントがまとめられており、かつ、サンプルコードも記載されていることで、kaggleにおけるテーブルデータ・コンペの対策について理解を深めるに至りました。
それまでは、公開notebookをcopyしてきては充分にコードの内容を理解もせずに、僅かにコードを修正しただけでsubmitしていましたので、public scoreも上がる訳がありません。
scoreが上がらなければ、モチベーションの維持も難しくなります。
しかし、上述の書籍を読み込み、サンプルコードを参考にしつつも自身でイチからコードを組むことにより、コードへの理解もすすみ、scoreはなかなか上がらなかったものの、コンペに参加するモチベーションを維持できるようになりました。
3.きっかけ
公開notebookに対して、コンペ参加者からupvoteすることができます。
コンペの後半にLB上位に入るnotebookを公開すると、瞬く間にupvoteされていき、そのnotebookにbronze→silver→goldとメダルの色が変わっていきます。
この仕組みをしっかり理解した際に、ダメ元で自身が作成したnotebookを公開してみようと思ったのが、標題に至ったきっかけです。
さすがに、kaggleをはじめて3か月ほど、かつ、大学も文系学部出身で統計学や情報工学を学んだ訳でもなく、データ分析の初心者の初心者に、LBで上位に食い込むようなnotebookは作れません!🥺
ならば、コンペの序盤に、何の工夫も特徴も無いベースまたはプロトタイプといったnotebookを公開しても、少しではあれどupvoteしてもらえるのではと考えました。
(事実、コンペの序盤にはそういったnotebookでもupvoteされていることには気付いていました。)
4.結果
9月の後半に、恐る恐るでしたが、とあるコンペにて実際に自身でイチから作成したベースと言うべきnotebookを公開してみました。
本当に簡単なつくりの特段の工夫も無いnotebookです。
しかしながら、公開して数日間でupvote=6を記録してbrozeメダル 🥉を獲得するに至りました。
コンペではメダルを獲得していませんでしたので、(discussion以外では)初のメダル獲得 🥉です! ヤッタネ!!🙌
続けて、同じコンペでCross Validationを加えたり、学習器を変えたり(GBDT、線形回帰、ニューラルネットワーク)したnotebookを公開すると、それらも日をかけて徐々にupvoteが増えていきました。
また、予測結果ファイル(例:submission.csv)のみ提出するタイプのコンペでは、Google Collaboratoryで学習・予測を実行するための特別な処理・設定を入れたnotebookも公開しました。
※kaggle APIを利用して、予測ファイルの提出を自動化しました。
嬉しいことに、こちらも少しずつupvoteを頂きました。
別のコンペに入っても、序盤に幾つかのベースとなるnotebookを公開することで、upvoteを得ることができました。
11月の中旬、bronzeメダル 5つ🥉🥉🥉🥉🥉を獲得して、Notebooks Expert への昇格を果たしました!!
⇒ 2021年12月1日現在、公開したnotebook:11本、総獲得upvote:101
notebookを公開しはじめてからここまで、2か月弱。
Conpetition Expert ではありませんが、立派な Expert です! (自惚れ💧)
まだコンペでメダルを獲得していない方は、notebookを公開することでメダルを獲得してみませんか?
5.今後の目標
もちろん、コンペでのメダル獲得×2 ⇒ Conpetition Expert昇格 です!
より一層、機械学習の理解を深め、コンペの対策を詰めて、LB上位に登れるよう精進いたします。
- 2021年12月1日 現在のkaggle profile:
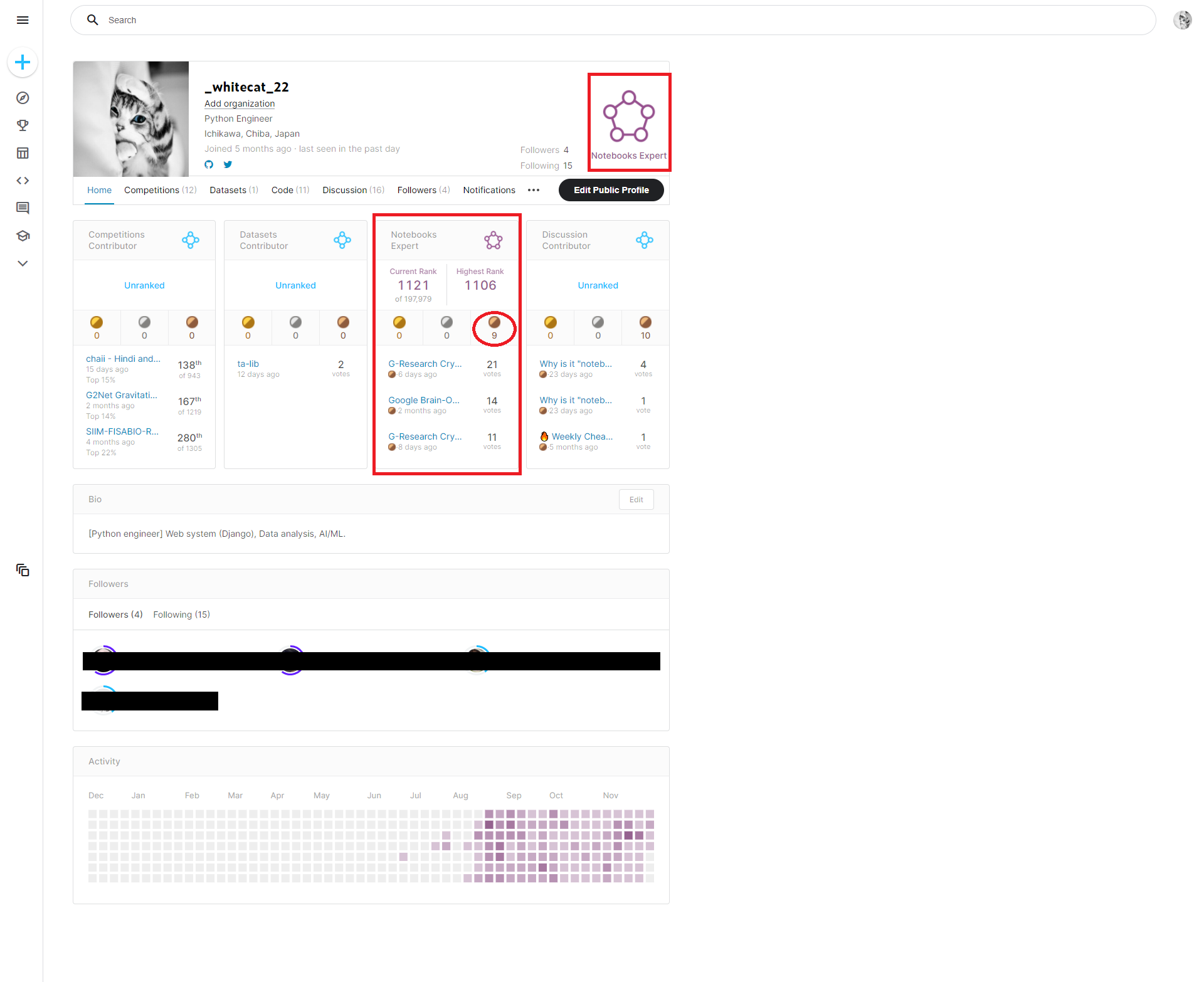
-参考-
公開したnotebookの一部 ★private sharingに抵触しないよう、一部、コンペ固有の情報は伏せてあります。
- kaggle kernel用
# Libraries
!pip install -U lightautoml
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import torch
from lightautoml.automl.presets.tabular_presets import TabularAutoML
from lightautoml.tasks import Task
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
# Warningの無効化
import warnings
warnings.filterwarnings("ignore")
# データフレームcolumの全表示
pd.set_option("display.max_columns", None)
# for reproducibility
np.random.seed(RANDOM_STATE)
torch.set_num_threads(N_THREADS)
# Load Data
DEBUG = False
train = pd.read_csv("../input/xxxxxxxxxx/train.csv")
test = pd.read_csv("../input/xxxxxxxxxx/test.csv")
submission = pd.read_csv("../input/xxxxxxxxxx/sample_submission.csv")
if DEBUG:
train = train[:80*1000]
train.shape, test.shape, submission.shape
display(train)
test["pressure"] = 0
display(test)
# Add Feature
def add_features(df):
# (省略)
return df
train = add_features(train)
test = add_features(test)
# LightAutoML model building
task = Task("reg", loss="mae", metric="mae")
roles = {
'drop': "id",
'group': "breath_id", # for group k-fold
'target': TARGET_NAME
}
%%time
# Fitting
automl = TabularAutoML(task=task,
timeout=TIMEOUT,
cpu_limit=N_THREADS,
reader_params={"n_jobs": N_THREADS, "cv": N_FOLDS, "random_state": RANDOM_STATE},
general_params={"use_algos": [["lgb", "lgb_tuned", "linear_l2"]]},
tuning_params={"max_tuning_time": 1800}
)
automl.fit_predict(train, roles=roles)
# Prediction
test_pred = automl.predict(test)
display(test_pred)
submission[TARGET_NAME] = test_pred.data[:, 0]
fi_score = automl.get_feature_scores("fast").sort_values("Importance", ascending=True)
plt.figure(figsize=(10, 30))
fi_score.set_index("Feature")["Importance"].plot.barh(fontsize=16)
plt.title("Feature importance", fontsize=18)
plt.show()
display(submission)
submission.to_csv("submission.csv", index=False)
- Google Colaboratory用
# Libraries
!pip install kaggle
import numpy as np
import pandas as pd
import tensorflow as tf
import gc
import matplotlib.pyplot as plt
%matplotlib inline
from tensorflow import keras
from tensorflow.keras.layers import *
from tensorflow.keras import *
from tensorflow.keras.callbacks import LearningRateScheduler
from tensorflow.keras.optimizers.schedules import ExponentialDecay
from sklearn.preprocessing import RobustScaler, normalize
from sklearn.model_selection import train_test_split, KFold
from sklearn.metrics import mean_absolute_error
from pickle import load
import os
# Warningの無効化
import warnings
warnings.filterwarnings("ignore")
# データフレームcolumの全表示
pd.set_option("display.max_columns", None)
# Load Data
from google.colab import files
uploaded = files.upload()
for fn in uploaded.keys():
print("User uploaded file '{name}' with length {length} bytes".format(
name=fn, length=len(uploaded[fn])))
# Then move kaggle.json into the folder where the API expects to find it. ##
!mkdir -p ~/.kaggle/ && mv kaggle.json ~/.kaggle/ && chmod 600 ~/.kaggle/kaggle.json
!kaggle competitions list
!kaggle competitions download -c xxxxxxxxxx
DEBUG = False
train = pd.read_csv(r"../content/train.csv.zip")
test = pd.read_csv(r"../content/test.csv.zip")
submission = pd.read_csv(r"../content/sample_submission.csv.zip")
if DEBUG:
train = train[:80*1000]
train.shape, test.shape, submission.shape
display(train)
display(test)
# Add Feature
def add_features(df):
# (省略)
return df
train = add_features(train)
test = add_features(test)
targets = train["pressure"].to_numpy().reshape(-1, 80)
train.drop(labels="pressure", axis=1, inplace=True)
train = add_features(train)
# normalize the dataset
RS = RobustScaler()
train = RS.fit_transform(train)
# Reshape to group 80 timesteps for each breath ID
train = train.reshape(-1, 80, train.shape[-1])
test = add_features(test)
test = RS.transform(test)
test = test.reshape(-1, 80, test.shape[-1])
train.shape, test.shape
# Model Creation
def create_lstm_model():
x0 = tf.keras.layers.Input(shape=(train.shape[-2], train.shape[-1]))
lstm_layers = 4 # number of LSTM layers
lstm_units = [320, 305, 304, 229]
lstm = Bidirectional(keras.layers.LSTM(lstm_units[0], return_sequences=True))(x0)
for i in range(lstm_layers-1):
lstm = Bidirectional(keras.layers.LSTM(lstm_units[i+1], return_sequences=True))(lstm)
lstm = Dropout(0.001)(lstm)
lstm = Dense(100, activation='relu')(lstm)
lstm = Dense(1)(lstm)
model = keras.Model(inputs=x0, outputs=lstm)
model.compile(optimizer="adam", loss="mae")
return model
# Training
# Function to get hardware strategy
def get_hardware_strategy():
try:
# TPU detection. No parameters necessary if TPU_NAME environment variable is
# set: this is always the case on Kaggle.
tpu = tf.distribute.cluster_resolver.TPUClusterResolver()
print("Running on TPU ", tpu.master())
except ValueError:
tpu = None
if tpu:
tf.config.experimental_connect_to_cluster(tpu)
tf.tpu.experimental.initialize_tpu_system(tpu)
strategy = tf.distribute.experimental.TPUStrategy(tpu)
tf.config.optimizer.set_jit(True)
else:
# Default distribution strategy in Tensorflow. Works on CPU and single GPU.
strategy = tf.distribute.get_strategy()
return tpu, strategy
tpu, strategy = get_hardware_strategy()
EPOCH = 350
BATCH_SIZE = 512
NFOLDS = 5
with strategy.scope():
kf = KFold(n_splits=NFOLDS, shuffle=True, random_state=2021)
history = []
test_preds = []
for fold, (train_idx, test_idx) in enumerate(kf.split(train, targets)):
print("-"*15, ">", f"Fold {fold+1}", "<", "-"*15)
X_train, X_valid = train[train_idx], train[test_idx]
y_train, y_valid = targets[train_idx], targets[test_idx]
model = create_lstm_model()
model.compile(optimizer="adam", loss="mae", metrics=[tf.keras.metrics.MeanAbsolutePercentageError()])
scheduler = ExponentialDecay(1e-3, 400*((len(train)*0.8)/BATCH_SIZE), 1e-5)
lr = LearningRateScheduler(scheduler, verbose=0)
history.append(model.fit(X_train, y_train,
validation_data=(X_valid, y_valid),
epochs=EPOCH, batch_size=BATCH_SIZE, callbacks=[lr]))
test_pred = model.predict(test).squeeze().reshape(-1, 1).squeeze()
test_preds.append(test_pred)
# save model
#model.save("lstm_model_fold_{}".format(fold))
del X_train, X_valid, y_train, y_valid, model
gc.collect()
# Export && Submission
submission["pressure"] = sum(test_preds)/5
submission.to_csv('submission.csv', index=False)
print('./submission.csv')
display(submission)
!kaggle competitions submit -c ventilator-pressure-prediction -f submission.csv -m "xxxxx Message xxxxx"
参考書籍
以上