TL;DR
pythonでwebスクレイピングを行いたく、いつも通りrequests+BeautifulSoupで試してみました。
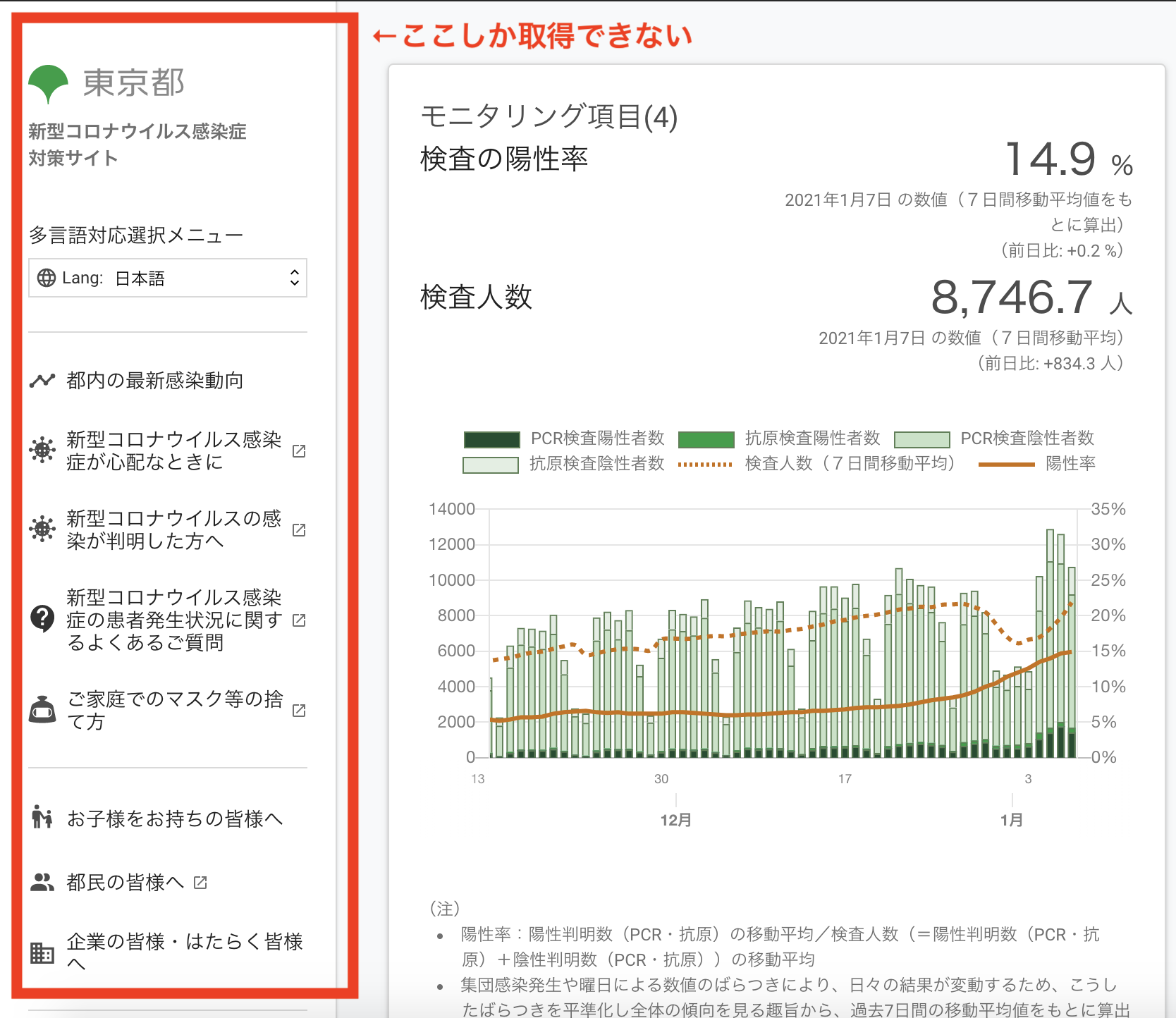
しかし、何故かページの一部しか取得できず、色々調べたところ「requests-html」というものが出てきたので、これを紹介します。
環境
- Raspberry Pi 4 Model B(Raspbian GNU/Linux 10)
- Python 3.6.1
module
pipでrequests_htmlをinstallします。
ラズパイ特有のエラー
macで試した際は何も問題なかったのですが、ラズパイでpip install requests_htmlを行った際、以下のようなエラーが発生
Command errored out with exit status 1
(省略)
Error: Please make sure the libxml2 and libxslt development packages are installed.
ERROR: Command errored out with exit status 1: python setup.py egg_info Check the logs for full command output ```
どうやらlxmlというものをrequests_htmlで入れているらしく、ラズパイではこれがエラーになっていると。
以下で解決
```sudo apt-get install libxml2-dev libxslt-dev python3-dev
pip install lxml
コード
from requests_html import HTMLSession
url = "https://stopcovid19.metro.tokyo.lg.jp/cards/positive-rate"
# セッション開始
session = HTMLSession()
r = session.get(url)
r.html.render()
# 要素取得
rows = r.html.find("span")
for row in rows:
print(row.text) # 全てのspan要素のテキストが表示される
r.html.find("要素名")で、ページ内の指定した全ての要素を取得します。
この例では東京都新型コロナサイトを取得しているのですが、requests+BeautifulSoupだと画面の一部しか取得できませんでした。