こんにちは、 株式会社ミクシィ で 家族アルバム みてね というアプリの開発に携わっている @_sobataro です。この記事では絵文字の標準とその扱いについてまとめます。
なお、この記事は mixiグループ Advent Calendar 2016 18日目の記事です。昨日は @radioboo さんの IGListKitでフィードUIをリファクタする でした。明日は @yusuke_tashiro さんの担当です。
TL; DR
Part I.
- Unicode 絵文字の標準について。
- 暇人向け。読まなくてよい。
Part II.
- 実際にプログラムで絵文字を扱う上で問題となりうる点について。
- Unicode 絵文字の文字数 (書記素クラスタの個数) を 厳密に正しく カウントするには、最新の Unicode (現時点では Unicode 9.0) 以降に対応したパーサが必要。
- ActiveSupport 5.0 や Swift 3.1 では Unicode 8.0 までにしか対応していない。
- Ruby 2.4.0 以降は Unicode 9.0 に対応している。
- 雑な実装でよければ、そこそこお手軽にできる。
- 環境によって unicode 絵文字のスタイル (テキストスタイル or 絵文字スタイル) は変わる。
- 検証用のページ を用意したのでお使いください。
- 各環境で絵文字のスタイルを統一したい / 絵文字ファイルをアプリやサービスに含めて提供したい / サーバサイドで絵文字を利用したい
- Twitter の twemoji や、 google の noto-emoji を使うとよい。
Part I. Unicode 絵文字の標準 (暇人向け)
はじめに Unicode 絵文字の標準に関する資料をまとめます。
注意: この part は長いので暇人向けです。
-
Unicode® Emoji
- Unicode Emoji の標準と関連資料へのリンク集。
-
UTR #51: Unicode Emoji (Version 4.0, 現在の最新版), Proposed Update UTR #51: Unicode Emoji (Version 5.0, 最新のドラフト版)
- Unicode emoji の相互運用性を高めるためのデザインガイドライン。またこの文書は、 unicode emoji の一覧や、後述する emoji のプレゼンテーションスタイル、 skin tone modifier に関する一覧も含む。
- Unicode emoji version 4.0 と 5.0 (ドラフト版) で、主に絵文字のパースに関する内容が大きく異なるため、この差異についても後ほど扱う。
- (参考) これからの絵文字の実装指針、UTR #51“Unicode Emoji”とはなにか: 絵文字の歴史と未来をふまえて UTR#51 を解説した記事。これからプログラム上で unicode 絵文字を扱おうと思っているのであれば必読!
- [USA #29: Unicode Text Segmentation] (http://www.unicode.org/reports/tr29/tr29-29.html) (Version 9.0.0, 現在の最新版), Proposed Update USA #29: Unicode Text Segmentation (Version 10.0.0, 最新のドラフト版)
- Unicode において“文字”や“単語”の切れ目をどのように定めるかを示した文書。
- Unicode Version 9.0.0 と 10.0.0 (ドラフト版) で、主に絵文字に関する内容に変更が加えられる。
以下では、主に UTR #51 Version 5.0 (ドラフト版) について紹介します。
Unicode Emoji の一覧
Unicode emoji に関するデータベースは emoji-data に用意されています。この中では、unicode emoji version 4.0 と 5.0 のいずれでも1126文字を「絵文字」であると定義しています。
また Full Emoji Data, v4.0 や http://unicode.org/emoji/charts-beta/full-emoji-list.html にも unicode emoji の一覧があります。こちらは絵文字1文字ずつについて、その文字の説明や unicode emoji に収録された時期、さまざまな環境でどのように表示されるのか、といった事柄が確認できます。
文字の表示 (Presentation): テキストスタイルと絵文字スタイル
一部の unicode emoji は テキストスタイル と 絵文字スタイル の2種類のスタイル (presentation style) を持ちます。この区別は2012-01-31にリリースされた Unicode 6.1 で導入されたものです。
UTR #51 によれば、ある絵文字がテキストスタイルと絵文字スタイルのどちらで表示されるかは、以下の要素によって決まります。
各文字がもつ Emoji_Presentation property
emoji-data では、各 unicode 文字に対し Emoji_Presentation プロパティを Yes (絵文字スタイル) または No (テキストスタイル) に定めています。
| Emoji_Presentation | デフォルトスタイル | 例 |
|---|---|---|
No |
テキスト | U+0023 1 U+00A9 ©️ U+2702 ✂️ |
Yes |
絵文字 | U+2705 ✅ U+1F440 👀 |
ただしこれはデフォルト値であり、後述の要因によってスタイルが上書きされることがあります。
文字の後ろにつける variation selector
Unicode には、異体字を処理する variation selector という仕組みがあり、これを絵文字のスタイル指定にも利用します。
絵文字の後ろに U+FE0E VARIATION SELECTOR-15 (TPVS) または U+FE0F VARIATION SELECTOR-16 (EPVS) をつけてスタイルを指定します。
手元の環境 (OS X El Capitan + Chrome 54) だと Qiita 上で variation selector をつけてもスタイルが変更できなかったので、別途 Gist として用意しました。
- sobataro/emoji_list.txt (素の絵文字、TPVS 付きの絵文字、 EPVS 付きの絵文字、のリスト)
- sobataro/emoji_list.rb (↑を生成したスクリプト)
環境によりますが (詳しくは後述)、たとえば手元の TextEdit.app では以下のように表示されます。
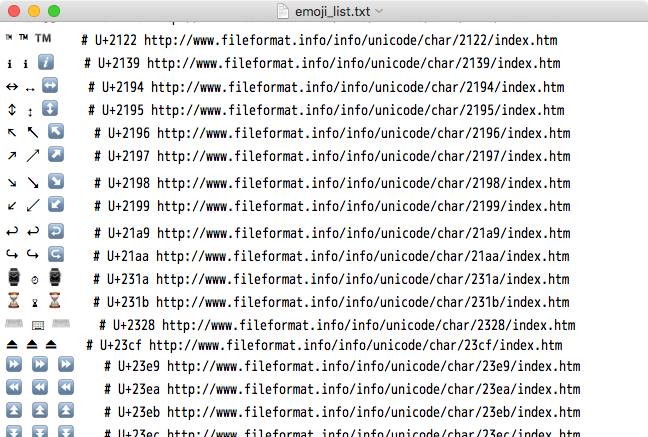
この例でいえば、たとえば以下のような感じです。
| 文字 | Emoji_ Presentation |
VS なし | TPVS つき | EPVS つき |
|---|---|---|---|---|
U+2122 TRADE MARK SIGN ™ |
No |
text | text | emoji |
U+231B HOURGLASS ⌛ |
Yes |
emoji | text | emoji |
U+23EB BLACK UP-POINTING DOUBLE TRIANGLE ⏫ |
Yes |
emoji | emoji (※) | emoji |
(※ 該当するグリフが OS X の有するフォントファイルに存在しないため、絵文字スタイルにフォールバックして表示されています。)
その他
Emoji Locale Extension や Emoji Script を使う方法もあるようですが、ここでは省略します。
また環境によっては、前述の Emoji_Presentation property を無視することも UTR #51 では許容しています。以下の表では、いちばん右の “with neither” 列のように、環境 (“word processing” なのか “texting, chats” なのか) によって variation selector が無かったときのデフォルトスタイルが変更されうる、とされています。
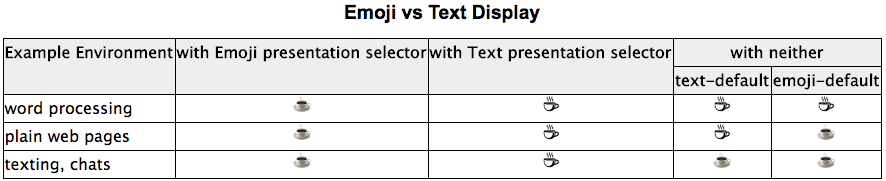
(表: UTR #51 から引用)
絵文字シーケンス
Unicode emoji には、単体のコードポイントからなる singleton と、複数のコードポイントからなる emoji sequence があります。とくに emoji sequence は、以下のように emoji core sequence と emoji zwj sequence に大別され、前者はさらに3つの分類があります。
emoji
├ singleton (単体のコードポイントからなる絵文字)
└ emoji sequence (複数のコードポイントからなる絵文字)
├ emoji core sequence (通常の絵文字)
│ ├ emoji combining sequence (囲み文字)
│ ├ emoji modifier sequence (skin tone 絵文字)
│ └ emoji flag sequence (国旗絵文字)
├ emoji zwj sequence (家族絵文字、職業絵文字など)
└ emoji tag sequence (タグ絵文字)
以下では emoji sequence の要素について解説します。
Emoji Combining Sequence (囲み文字)
Non spacing mark (結合文字; それ自体は幅を持たず、前の文字に結合してひとつの形になる文字) を含む絵文字です。
いまのところ non spacing mark として U+20E3 COMBINING ENCLOSING KEYCAP を持つ、 1️⃣ などの囲み文字だけが含まれています。
例: U+0031 U+FE0F U+20E3 Keycap Digit One 1️⃣
(注: OS X El Capitan だと↑の絵文字は正しく表示されません)
http://emojipedia.org/keycap-digit-one/
| コードポイント | 文字 | 説明 |
|---|---|---|
| U+0031 | 1 | DIGIT ONE |
| U+FE0F | N/A | VARIATION SELECTOR-16 (EPVS) |
| U+20E3 | ⃣ | COMBINING ENCLOSING KEYCAP |
Emoji Modifier Sequence (skin tone 絵文字)
絵文字のうち人体の肌が露出している文字 (Emoji_Modifier_Base property が Yes の文字) の後ろに Emoji_Modifier (U+1F3FB..U+1F3FF EMOJI MODIFIER FITZPATRICK TYPE 1-2..6) を付けて、肌の色を変更した絵文字です。
この種類の絵文字は、人類の多様性を絵文字にも反映させ、世界中の人々が絵文字を使えるようにするため、2015-06-17にリリースされた Unicode 8.0 で導入されたものです。
例: U+1F44F U+1F3FD Clapping Hands Sign, Type-4 👏🏽
| コードポイント | 文字 | 説明 |
|---|---|---|
| U+1F44F | 👏 | CLAPPING HANDS SIGN |
| U+1F3FD | 🏽 | EMOJI MODIFIER FITZPATRICK TYPE-4 |
Emoji Flag Sequence (国旗絵文字)
U+1F1E6..U+1F1FF REGIONAL INDICATOR を ふたつ並べた絵文字です。
Unicode emoji における国旗は、 A から Z までのアルファベット1文字を表す文字 REGIONAL INDICATOR をふたつ並べたものとして表されます。
例: U+1F1EF U+1F1F5 Flag for Japan 🇯🇵
| コードポイント | 文字 | 説明 |
|---|---|---|
| U+1F1EF | 🇯 | REGIONAL INDICATOR SYMBOL LETTER J |
| U+1F1F5 | 🇵 | REGIONAL INDICATOR SYMBOL LETTER P |
Emoji ZWJ Sequence (家族絵文字、職業絵文字など)
U+200D ZERO WIDTH JOINER (ZWJ) によって複数の絵文字を連結し、1文字として見せる絵文字です。主に家族絵文字、職業絵文字に使われます。
この種類の絵文字も skin tone 絵文字と同様に、人類の多様性、とくに gender equality を絵文字に反映させるために導入されました。
例: U+1F468 U+200D U+1F468 U+200D U+1F466 Family: Man, Man, Boy 👨👨👦
| コードポイント | 文字 | 説明 |
|---|---|---|
| U+1F468 | 👨 | MAN |
| U+200D | N/A | ZERO WIDTH JOINER |
| U+1F468 | 👨 | MAN |
| U+200D | N/A | ZERO WIDTH JOINER |
| U+1F466 | 👦 | BOY |
例: U+1F6B5 U+1F3FC U+200D U+2640 U+FE0F Woman Mountain Biking, Type-3 🚵🏼♀️
(注: OS X El Capitan だと↑の絵文字は正しく表示されません)
http://emojipedia.org/woman-mountain-biking-type-3/
| コードポイント | 文字 | 説明 |
|---|---|---|
| U+1F6B5 | 🚵 | MOUNTAIN BICYCLIST |
| U+1F3FC | 🏼 | EMOJI MODIFIER FITZPATRICK TYPE-3 |
| U+200D | N/A | ZERO WIDTH JOINER |
| U+2640 | ♀ | FEMALE SIGN |
| U+FE0F | N/A | VARIATION SELECTOR-16 (EPVS) |
Emoji TAG Sequence (タグ絵文字)
既存の絵文字に対し、髪の色や絵文字の向きなどを変更し、さまざまなバリエーションを実現するタグを付けたもの……のようですが、私の知るかぎり、現在の Andorid/iOS の標準キーボードで emoji TAG sequence を入力することはできないようです。
これについては詳しく調べていないのですが、 Proposed Draft UTS #52: UNICODE EMOJI MECHANISMS にはより詳細な説明 (ドラフト版) があるようです。
Part II. 絵文字の扱い
ここからは、実際にプログラムで絵文字を扱う上で問題となりうる点について扱います。
絵文字の文字数カウント
プログラムでユーザ入力値を扱う場合、しばしば文字数のカウントが必要になります。
ところが、絵文字の文字数を数えようとすると、しばしばおかしな値になってしまいます。
irb(main):001:0> RUBY_VERSION
=> "2.3.1"
irb(main):002:0> "1️⃣".scan(/\X/).count
=> 3
irb(main):003:0> "👏🏽".scan(/\X/).count
=> 2
irb(main):004:0> "👨👨👦".scan(/\X/).count
=> 5
irb(main):005:0> "🇯🇵".scan(/\X/).count
=> 2
irb(main):006:0> "🇯🇵🇯🇵🇯🇵".scan(/\X/).count
=> 6
これは ruby の String#length が コードポイント単位で文字数を数えているため で、複数のコードポイントからなるこれらの絵文字の“見た目上の”文字数を数えるには、 unicode における書記素クラスタ (grapheme cluster) の概念が必要です。
書記素クラスタ (grapheme cluster)
書記素クラスタ とは、 unicode において自然な“1文字”を表す単位です。 Unicode による文字の一部は複数のコードポイントから構成 (例: U+0061 U+0301 á) されますが、書記素クラスタを用いると、これを1文字ごとに分割することができます。
書記素クラスタについては、さまざまな記事で解説されていますので、いくつか紹介します:
- Unicodeのgrapheme cluster (書記素クラスタ) - hydroculのメモ
- 文字数をカウントする7つの方法 - LINE Engineers' Blog
- なぜSwiftの文字列APIは難しいのか - POSTD
絵文字の文字数カウントにも書記素クラスタを使えばよいので、 ActiveSupport 5.0 の ActiveSupport::Multibyte::Unicode.unpack_graphemes を使ってみましょう。
irb(main):001:0> load 'unicode.rb'
=> true
irb(main):002:0> ActiveSupport::Multibyte::Unicode.unpack_graphemes("1️⃣").count
=> 1
irb(main):003:0> ActiveSupport::Multibyte::Unicode.unpack_graphemes("👏🏽").count
=> 2
irb(main):004:0> ActiveSupport::Multibyte::Unicode.unpack_graphemes("👨👨👦").count
=> 3
irb(main):005:0> ActiveSupport::Multibyte::Unicode.unpack_graphemes("🇯🇵").count
=> 1
irb(main):006:0> ActiveSupport::Multibyte::Unicode.unpack_graphemes("🇯🇵🇯🇵🇯🇵").count
=> 1
こうすると、ただ単にコードポイントを数えるよりも実態に近い値が得られましたが……まだおかしいですね。家族絵文字は人数のカウントになってしまったようですし、最後の国旗は3文字あるはずなのに1文字としてカウントされてしまいました。
これは、 rails 5.0.0 の ActiveSupport::Multibyte::Unicode.unpack_graphemes が Unicode 8.0.0 以下のバージョンに基づき書記素クラスタを分割するために発生する問題です。なお Swift 3.1 の String.characters.count などを使っても同じ結果が得られます。
書記素クラスタに関する Unicode 9.0 以降と 8.0 以前の違い
書記素クラスタの分割ルールは USA #29: Unicode Text Segmentation で定められています。このうち、最新の Unicode 9.0 に対応する Revision 29 と Unicode 8.0 に対応する Revision 27 では、絵文字まわりの取り扱いが以下のように変わっています。
| 項目 | Unicode 8.0 | Unicode 9.0 |
|---|---|---|
| Emoji modifier sequence (skin tone 絵文字) | 分割する (※) | 分割しない |
| Emoji zwj sequence (家族絵文字、職業絵文字など) | 分割する (※) | 分割しない |
| Emoji flag sequence (国旗絵文字) | 分割しない | 奇数番目では分割しない |
(※ Emoji modifier sequence などの概念自体が Unicode 9.0 で加えられたものなので、 Unicode 8.0 以前では「その他の (特別な扱いを要さない普通の) 文字として扱われた結果、分割されてしまう」ということであり、「わざわざ分割する」ということではない。)
このため、上記の ActiveSupport::Multibyte::Unicode.unpack_graphemes を用いた例でも、 skin tone 絵文字は ZWJ や skin tone modifier で分割されてしまいましたし、国旗絵文字は何文字続こうとも1文字としてカウントされてしまいました。
絵文字の文字数を正しくカウントするには
絵文字の文字数を 厳密に正しく 数えるには、 Unicode 9.0 以降に対応した、最新の USA #29 に従うパーサが必要です。
Ruby 2.4.0 は Unicode 9.0 に対応している ため、2016-12-12にリリースされたばかりの ruby 2.4.0-rc1 を使うと、以下のように正しい文字数が得られます。
irb(main):001:0> RUBY_VERSION
=> "2.4.0"
irb(main):002:0> "1️⃣".scan(/\X/).count
=> 1
irb(main):003:0> "👏🏽".scan(/\X/).count
=> 1
irb(main):004:0> "👨👨👦".scan(/\X/).count
=> 1
irb(main):005:0> "🇯🇵".scan(/\X/).count
=> 1
irb(main):006:0> "🇯🇵🇯🇵🇯🇵".scan(/\X/).count
=> 3
ただし、まだ正式リリース前である ruby 2.4.0 を本番サービスに投入することは難しいでしょう。
筆者がこの問題に直面した2016-08の時点では、 Unicode 9.0.0 に対応したパーサは (筆者が探した限り) 見当たらず、自前で実装することにしました。
ただし、 Unicode 9.0.0 に厳密に従うには unicode_tables.dat のような Unicode 文字のデータベースが必要になるほか、 USA #29 を読み解かなければならずハードルが高いです。これを避けたい場合、たとえば Ruby で絵文字を含む文字列の長さをカウントしたい で紹介されているように、以下のような方針で雑な実装が可能です。
- Variation selector, skin tone modifier や、囲み絵文字の
U+20E3 ENCLOSING KEYCAPは数えない。 - 国旗絵文字を表す regional indicator は、2つで1文字と数える。
- Zero width joiner の数だけ、全体の文字数をマイナスする。
ここでは上記を実装した 雑な文字数カウンタ を用意しました。その出力がこちらです:
$ ruby length.rb
RUBY_VERSION = 2.3.1
"1️⃣".length = 3
"1️⃣".codepoints.count = 3
"1️⃣".scan(/\X/).count = 1
lesser_graphemes_counter("1️⃣") = 1
"👏🏽".length = 2
"👏🏽".codepoints.count = 2
"👏🏽".scan(/\X/).count = 2
lesser_graphemes_counter("👏🏽") = 1
"👨👨👦".length = 5
"👨👨👦".codepoints.count = 5
"👨👨👦".scan(/\X/).count = 5
lesser_graphemes_counter("👨👨👦") = 1
"🇯🇵".length = 2
"🇯🇵".codepoints.count = 2
"🇯🇵".scan(/\X/).count = 2
lesser_graphemes_counter("🇯🇵") = 1
"🇯🇵🇯🇵🇯🇵".length = 6
"🇯🇵🇯🇵🇯🇵".codepoints.count = 6
"🇯🇵🇯🇵🇯🇵".scan(/\X/).count = 6
lesser_graphemes_counter("🇯🇵🇯🇵🇯🇵") = 3
自前実装の lesser_graphemes_counter() のみ、正しそうな文字数を出力しています。
……もちろんこのような雑実装では、たとえば regional indicator が1個だけ存在した場合や、 zero width joiner の前後に絵文字でない文字が存在した場合には、正しい文字数とずれてしまいます。そのあたりは適宜やっていきましょう。筆者の環境では、もう少し真っ当なパーサが実装され本番で動いています (が、時間が足りず、本記事でご紹介することは叶いませんでした。。。 もう少し待てば各言語やフレームワークが Unicode 9.0 以降に対応すると思いますので、とりあえず雑実装で乗り切るというのもひとつの選択肢だと思います。)
絵文字の表示スタイルが環境によって異なる問題
「絵文字をテキストスタイルと絵文字スタイルのどちらで表示すべきか」について、 UTR #51 では以下のように示されています。
- Variation selector がついていたら、それに従う。
- さもなくば、各文字の
Emoji_Presentationproperty に定められたデフォルト値に従う。ただし環境によって、このデフォルト値は無視されうる。
(表: UTR #51 から引用・再掲)
では「環境によって」というのは、具体的にどの程度の差があるのでしょうか。これを検証するページを用意しました (Part I. でも掲載したものを再掲):
- sobataro/emoji_list.txt (素の絵文字、TPVS 付きの絵文字、 EPVS 付きの絵文字、のリスト)
- sobataro/emoji_list.rb (↑を生成したスクリプト)
このページを iOS 10.2 (iPhone 5S), Android 7.1.1 (Nexus 5X), Android 5.1.1 (Xperia Z Ultra) で表示した際のスクリーンショットを以下に掲載します:
| iOS 10.2 (iPhone 5S) | Android 7.1.1 (Nexus 5X) | Android 5.1.1 (Xperia Z Ultra) |
|---|---|---|
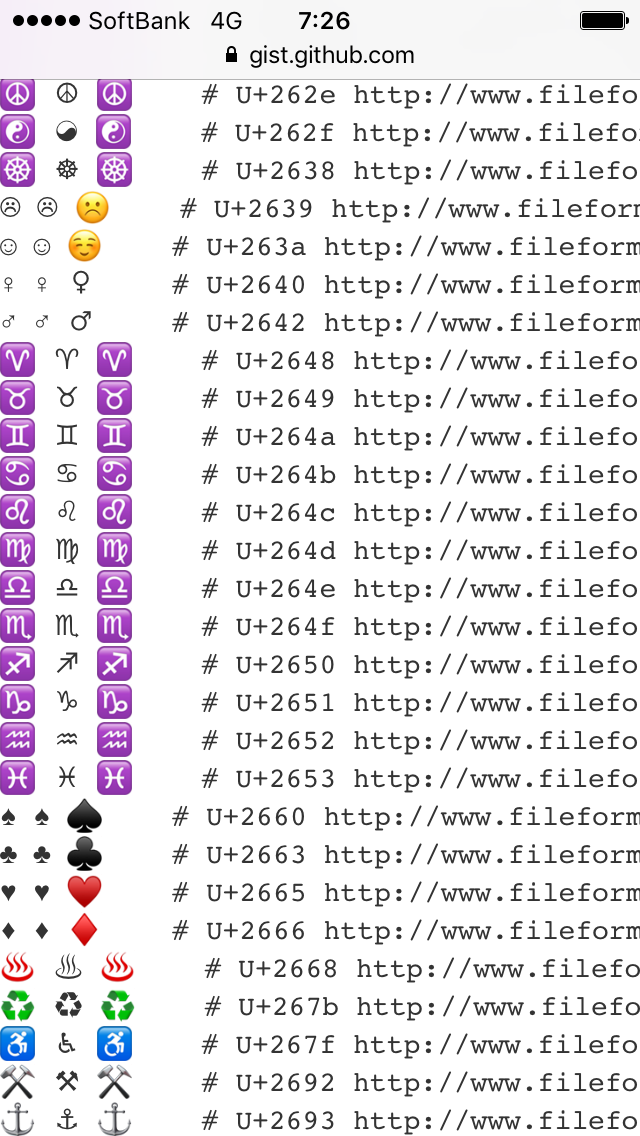 |
 |
 |
この画面内だけでも、環境によってずいぶんと違いがあることがわかります。たとえば variation selector のないデフォルト表示 (いちばん左の列) については、以下のような差があります:
| 文字 | iOS 10.2 | Android 7.1.1 | Android 5.1.1 |
|---|---|---|---|
| U+262E PEACE SYMBOL ☮ | emoji | text | 文字化け |
| U+263A WHITE SMILING FACE ☺ | text | emoji | emoji |
| U+2665 BLACK HEART SUIT ♥ | text | emoji | text |
この表示スタイルを各環境で検証したところ、以下のような感想 (あくまでも感想です) が得られました:
- iOS
-
Emoji_Presentationproperty をほぼ無視しており、ほとんどの文字がデフォルトで絵文字表示となる。 - デフォルトでテキスト表示となる文字は20文字程度と少ない。
- iOS 10.1 と 10.2 で、デフォルトスタイルに少しだけ差がある気がした。
-
- Android 7 以降
- Unicode の定める
Emoji_Presentationproperty におおむね従ったスタイルを表示している (が、一部例外もある)。 - その結果、デフォルトでテキスト表示となる文字がそこそこ多い (100文字程度)。
- Unicode の定める
- Android 6 以前
- そもそも variation selector に対応しないため、 variation selector の有無に関わらず単一のスタイルで表示される。
- 各絵文字のスタイル選択は、端末のもつフォントファイルに依存しているようで、メーカーや端末ごとの差も激しい。
- 古い端末 (とくに Android 4 系) では、白黒の文字や、ガラケーのキャリア絵文字に類似した絵文字も見られる。
- (おまけ) OS X El Capitan
- 雑にしか検証していないが、 Unicode の定める
Emoji_Presentationproperty におおむね (完全に?) 従っているようだ。
- 雑にしか検証していないが、 Unicode の定める
各環境で表示スタイルを統一する方法としては、以下で紹介する twemoji や noto-emoji を利用するとよいでしょう。
各環境で絵文字のスタイルを統一したい / 絵文字ファイルをアプリやサービスに含めて提供したい / サーバサイドで絵文字を利用したい
Twitter の twemoji や、 google の noto-emoji を使いましょう。
- twemoji
- 画像ファイルの形式で配布される。
-
CDN経由でも利用 できるほか、文章中に画像ファイルの
<img>タグを埋め込む javascript も付属する。 - スクリプトなどの付属ソースコードは MIT License, 絵文字の画像ファイルは CC-BY 4.0 でライセンスされる。
- noto-emoji
- 画像ファイルおよびフォントファイルの形式で配布される。
- フォントファイルを使って、通常のテキストや他のフォントとあわせて利用することが容易。
- フォントファイルは SIL Open Font License v1.1, その他の (絵文字の) 画像ファイルや付属ソースコードは Apache License v2.0 でライセンスされる。
まとめ
絵文字を扱う上では、いろいろと落とし穴があることが分かってきました。とくに iOS や Android の最新版では、最新の絵文字が「使える」ようになっているものの、「使える」といってもキーボードから入力して表示ができるだけで、文字数カウントや削除でトラブルが起きたりして、頭を悩ませることがあると思います。そんな時にこの記事が助けになれば幸いです。
この記事は mixiグループ Advent Calendar 2016 18日目の記事でした。昨日は @radioboo さんの IGListKitでフィードUIをリファクタする でした。明日は @yusuke_tashiro さんの担当です。