「ScraperWiki」サービスを利用すれば、自分でサーバーなどを借りなくてもウェブスクレイピングを定期的に行うことができます。
ScraperWikiの特徴
- スクレイパーのスクリプトをブラウザ上で編集・実行できる
- スクリプトを定期的に実行できる
- 取得したデータをcsvでエクスポートしたりJSON APIを通じて取得したりできる
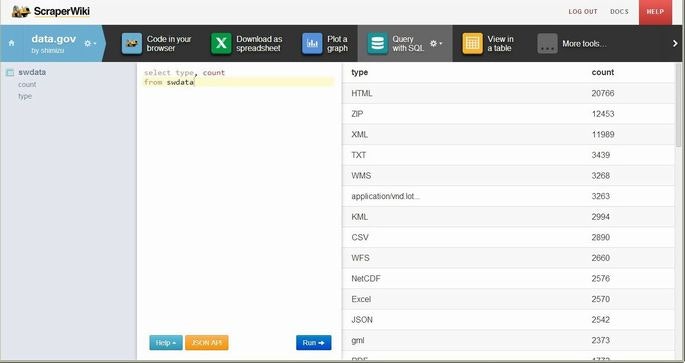
- 取得したデータをテーブルやグラフとして表示できる
- 3データセットまで無料
スクリーンショット
スクリプト編集画面
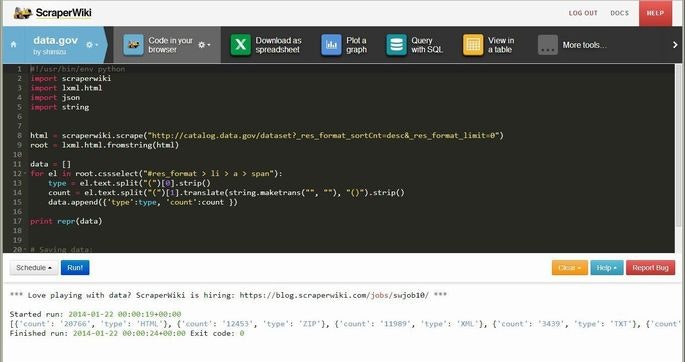
DB
スクレイパースクリプト サンプル
#!/usr/bin/env python
import scraperwiki
import lxml.html
import json
url = "http://target.website.hoge/index.html" #スクレイピングするターゲットサイト
html = scraperwiki.scrape(url) #htmlドキュメント取得
root = lxml.html.fromstring(html) #rootエレメントオブジェクト取得
data = []
id = 0
for el in root.cssselect("#hoge_contents > li > span"): #cssセレクタで要素を抽出
data.append({'id':id, 'text':el.text }) #抽出した要素のテキストを保存
id = id + 1
print repr(data) #保存したデータをコンソールに出力
# Saving data:
unique_keys = [ 'id' ] #ユニークキーを指定
scraperwiki.sql.save(unique_keys, data) #DBに保存
実際に使用した例
http://shimz.me/blog/d3-js/3353