はじめに
DNSの基本の仕組みをおさえることができるよう、頑張って説明します。
もくじ
DNSの概要
下記の画像のように、WebブラウザでURL(例:mypage.com)を入力してアクセスすると、最初にDNSサーバがURLのドメイン名をIPアドレス(例:80.162.118.54)に変換します。
その後、取得したIPアドレスを使用して実際にそのウェブサーバにアクセスするための処理が始まります。
このように、人間が覚えやすいドメイン名をIPアドレスに変換するシステムがDNS(Domain Name System) です。
DNSによってIPアドレスが取得された後
DNSによってIPアドレスが取得された後、実際にサーバと通信を始めるためには、TCP/IPプロトコルを使用したコネクションの確立が必要になります。TCPを使用して、DNSで取得したIPアドレスと特定のポート番号に対して通信を行い、クライアントとサーバの間でTCPのスリーウェイハンドシェイク(SYN、SYN-ACK、ACK)してやっと両者間での通信経路が確立される、といった流れです。
名前解決とドメイン名
人間が覚えやすいドメイン名をIPアドレスに変換するシステムがDNS(Domain Name System)です。
上記をもう少し深堀りして説明します。
名前解決の概要
ウェブサイトを見たいときはブラウザのアドレスバーにURLを入力しますよね。
TCP/IPでは通信する相手を特定するのがIPアドレスであり、アプリケーションを特定するのがポート番号です。なのですが、URLを打ち込むことでウェブサイトが表示されるのはなぜでしょうか。
答えは当然 DNS です。URLからドメイン名を抜き出してIPアドレスに変えてくれてるからですね。
人間は数字の羅列であるIPアドレスなんか覚えてられません。DNSは、分かりやすいドメイン名を対応するIPアドレスに関連付ける(解決する)作業を通じて、ドメイン名を指定するだけでIPアドレスを返してくれるシステムです。この一連の流れがいわゆる「名前解決」と呼ばれるプロセスです。
名前解決の歴史
DNSが開発される以前、インターネットの前身であるARPANETにおいては通信先の機器名(ホスト名)とIPアドレスの対応関係を管理する方法が必要でした。その役割を果たしていたのが HOSTS.TXT ファイルで、これにはネットワーク上の「全ての」コンピュータのホスト名とIPアドレスが記載されていました。ネットワーク内の各ホストは、この HOSTS.TXT ファイルを定期的にダウンロードすることで 最新のホスト名とIPアドレスの対応情報を入手し、名前解決を行っていました。
なのですが、以下のような問題が起き始めました。(詳しくは上記の参考記事を読んでみてください)
-
HOSTS.TXTファイルのサイズが大きくなりすぎたことによるトラフィックの問題 -
HOSTS.TXTファイルの更新と配布のタイミングの違いによる名前解決の矛盾や食い違い
そんなこんなでしんどくなってしまったので、自動的に名前解決を行うDNSが生まれました。
DNSの登場によってドメイン名とIPアドレスの対応関係は分散したサーバで管理するようになり、個々のホストに HOSTS.TXT のような情報のスナップショットを持つことがなくなりました。
結果として、必要になったときだけ名前解決が走るのでトラフィックの問題は大幅に軽減され、また、ドメイン名とIPアドレスの対応関係はデータベース間で同期されるので名前解決の矛盾や食い違いが起きることはなくなりました。(正確にはキャッシュによって一時的な名前解決の矛盾や食い違いが生じる可能性はあります)
FQDN(Fully Qualified Domain Name:完全修飾ドメイン名)
さて、IPアドレスと紐づくドメイン名がどのようなものか説明します。
IPアドレスに対応し、インターネット上で一意な名前を提供するのが「ドメイン名」です。(厳密にはドメイン名は通信機器(ホスト)を個別に指定しているわけではなく、ネットワーク上の範囲を指していることに注意が必要です)
例えば、www.mypage.com は実際には www.mypage.com. がインターネット上の特定のサーバを指し示すための正確なドメイン名になります。あるコンピューターやネットワークリソースをインターネット上でユニークに識別するためのドメイン名の完全な表記を「完全修飾ドメイン名(FQDN)」と言います。
このFQDNは、以下のように構成されています。
-
www(ホスト名) -
mypage(セカンドレベルドメイン:SLD) -
com(トップレベルドメイン:TLD) -
.(ルートドメイン)
重要なのは、FQDNがあることによってグローバルなインターネット上で同じドメイン名は存在せず、これによりネットワーク上でホストを一意に特定することができる点 です。(ローカルやプライベートなネットワークでは同じドメイン名が存在する可能性がありますが、これらは外部のインターネットからは見えません)
ドメイン名前空間
「FQDNが守られることで同じドメイン名は存在しない」とはどういうことでしょうか。
インターネット上のすべてのドメイン名はルートを起点とするツリー構造になっており、これをドメイン名前空間と呼びます。同様に、ドメイン名とIPアドレスの対応関係は階層的なツリー構造をとる分散型データベースで管理されています。
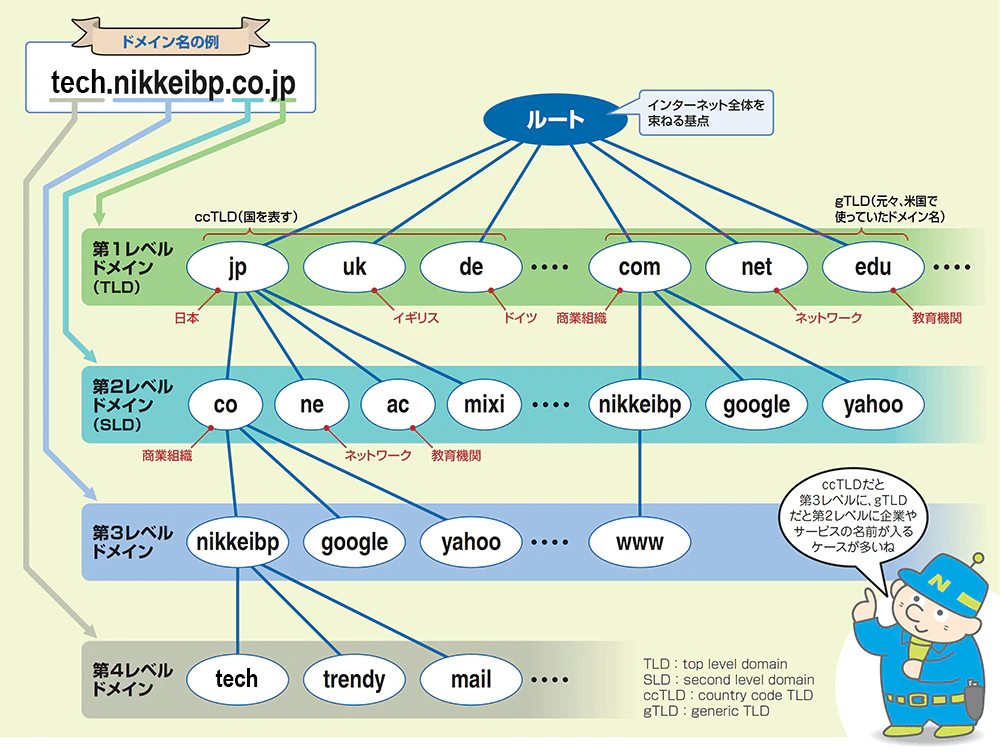
引用元:世界最大のツリー構造、ネットを網羅する「ドメイン名空間」を図解
ルート
最上位には起点となるルートDNSサーバがあります。これは世界中に分散配置された13の異なるオペレータによって管理されているサーバ群で、加えて複数のミラーサーバが存在します。
トップレベルドメイン(TLD)
ルートサーバ直下の階層をトップレベルドメイン(Top Level Domain, TLD)と 呼びます。TLDはインターネットの国やカテゴリを分類した最上位のドメインで、大きく以下の2種類があります。
-
ccTLD:- 国別のTLD(country code TLD)
-
ISO3166で規定されている2文字の国コードを基にしており、各国固有のコードが割り当てられている
- 例:
jp(日本)、gr(ギリシャ)など
- 例:
-
gTLD:- 国に関係なく使えるTLD(generic TLD)
- 通常3文字以上のドメインで構成されている
- 例:
com、net、orgなど
- 例:
セカンドレベルドメイン(SLD)
TLDの下の階層にはセカンドレベルドメイン(SLD)があり、ここには企業や組織の固有のドメイン名が登録されます。
一部のTLDでは直接TLD直下にドメインを登録することが可能で、SLDが省略されることもあります。(例えば日本の企業は .co.jp のように企業を示すSLDを使いますが、SLDが省略されて example.jp のように直接TLDの .jp ドメイン直下にドメインを登録することがあったりします)
サブドメイン・ホスト名
SLDの下(あるいはTLDの下)の階層には、その企業や組織の内部でさらに細分化されたサブドメインや特定のマシンを指すホスト名が位置します。
こんな感じでドメイン名前空間は階層的な構造になっていて、世界中のすべてのドメイン名がこのツリー構造の名前空間で管理されています。
ルートDNSサーバが直下のTLDの情報を持っているように、その下の各レベルのDNSサーバも下位のドメインの情報を持っています。ホスト名やドメイン名が登録される際には、それぞれのレベルで一意性が確認されるので、名前が重複することはありません。
なので、例えば .com のTLDにおいて、すでに mypage.com というドメインが登録されている場合、他に同じ名前で登録することはできません。また、このドメインの下にある shop.mypage.com や blog.mypage.com などのサブドメインもまた、同じドメイン名の中でユニークでなければなりません。
そういう理由で、FQDNのルールが守られている限り同じドメイン名が重複することはなく、www.mypage.com (com ドメイン内の mypage ドメイン内の www というホスト)はネットワーク上で一意になる、というわけです。
名前解決の仕組み
DNSについて、ここまでで以下を説明しました。
- 名前解決によってドメイン名を渡せばIPアドレスを教えてくれる
- ネットワーク上のすべての名前を持つ通信機器は、ドメイン名前空間というツリー構造の中にある
- FQDNという重複しない名前を持ち、ルートから辿れば見つかる
DNSの全体像が見えたところで、ここからはDNSがどうやって名前解決するための名前の管理をしているか、どうやって名前を検索しているかの説明をします。
DNSのクライアント・サーバシステム
まず前提ですが、DNSは以下のクライアント・サーバシステムで成り立っています。
- ドメイン名とIPアドレスの対応関係(データベース)を保持するサーバ群:
- ネームサーバ(DNSサーバ)
- それに問い合わせるクライアント:
- PC
- スマートフォン
- DNSサーバに問い合わせるDNSサーバ
- など
前述の通り、ドメイン名とIPアドレスの対応関係は階層的なツリー構造を持つ分散型データベースで管理されており、これはドメイン名前空間が複数のネームサーバ(DNSサーバ)によって成り立っていることを意味します。
ここでは複数のネームサーバを、ドメインごとに分散させて管理しています。 例えば、.com のTLDには .com ドメイン用のネームサーバを配置しています。同様に、.com 直下のそれぞれのSLD(例:mypage.com や example.com)にもまた、そのドメイン名専用のネームサーバを配置しています。こんな感じで、各ドメインごとに担当のサーバを 1 台あるいは複数台置いて管理しているのですが、これが「分散型」の正体になります。
ここで重要なのは、各ネームサーバの管理対象となるのは、そのネームサーバ直下の名前である ということです。つまり、com ドメインのネームサーバは mypage.com ドメインや example.com ドメインなどは管理しますが、www.mypage.com や blog.mypage.com は直接管理しません。
この、ネームサーバが管理するドメイン直下の情報の範囲を「ゾーン」と呼びます。
ゾーン
ゾーンはツリー構造の中でネームサーバが管理する範囲であり、そのドメインに関するすべてのDNS(名前解決)のための情報を保持しています。これをゾーン情報と言いますが、その中身は名前解決に必要な複数のリソースレコード(ドメイン名とIPアドレスの対応表)になります。(厳密にはメールサーバの情報や別名の情報などがある)
- ゾーン情報:
- そのゾーンのホストの名前とそのネームサーバのIPアドレス
- サブドメインの名前とサブドメインのネームサーバのIPアドレス

引用元:世界最大のツリー構造、ネットを網羅する「ドメイン名空間」を図解
上記の画像を参考にした場合、ゾーン情報は以下のようになるイメージです。
-
co.jp.のネームサーバが持つゾーン情報:- ホスト名
nikkeibp- IPアドレス(XXX.XXX.XXX.XXX) - ホスト名
google- IPアドレス(XXX.XXX.XXX.XXX) - ホスト名
yahoo- IPアドレス(XXX.XXX.XXX.XXX)
- ホスト名
-
nikkeibp.co.jp.ネームサーバが持つゾーン情報:- ホスト名
tech- IPアドレス(XXX.XXX.XXX.XXX) - ホスト名
trendy- IPアドレス(XXX.XXX.XXX.XXX) - ホスト名
mail- IPアドレス(XXX.XXX.XXX.XXX)
- ホスト名
該当のドメインの管理者、つまりドメインのネームサーバの管理者はゾーン情報を変更できます。例えばドメイン直下のホストを新たに登録したり、サブドメインを削除したりと、そのドメインの名前空間への追加・削除ができます。こんな感じで ネームサーバはゾーン情報に対して、つまりドメイン名前空間の一部を管理する権限を持っています。 これを「ネームサーバがオーソリティを持つ」と言います。(オーソリティを持つサーバが複数台ある場合はゾーン情報を同期することで整合性を保っています)
ドメイン名前空間の検索
ネームサーバがドメイン名前空間の一部を管理していて、その管理権限の有効範囲がゾーンです。DNSの名前解決は、この各ドメインのネームサーバが持つゾーン情報を活用することで可能になります。
どういうことかと言うと、親のネームサーバは子のサブドメインのネームサーバのアドレスを知っているので、問い合わせするアドレスが分かります。子のネームサーバは孫のサブドメインのネームサーバのアドレスを知っているので、問い合わせするアドレスが分かります。というように、これの繰り返しでドメイン名前空間のルートサーバから辿っていけば(FQDNの後ろから順番に辿っていけば)目的のIPアドレスを探すことができるわけです。
キャッシュがない前提で、クライアントは次のようなステップを踏んでドメインの名前解決を行います。
- クライアントはブラウザに打ち込まれたドメイン名を抽出(
www.mypage.com.) - クライアントはドメイン名をDNSリゾルバ(問い合わせる側のソフトウェア)に渡す
- DNSリゾルバはDNSサーバに問い合わせを行う
- ルートネームサーバ(
.)への問い合わせでcom.のネームサーバへの参照情報を取得する - TLDネームサーバ(
com.)への問い合わせでmypage.com.のネームサーバへの参照情報を取得する - オーソリティブネームサーバ(
mypage.com.)への問い合わせでwww.mypage.com.のIPアドレスを取得する(※) - DNSサーバは取得した
www.mypage.com.のIPアドレスを含む必要な情報を返す - DNSリゾルバは取得したIPアドレスをクライアントに返す
- クライアントは取得したIPアドレスをブラウザに返す
- ブラウザはIPアドレスをもとにTCP/IPで接続を試みる
※ オーソリティブネームサーバは、そのドメインに関する公式な情報を持っているサーバです
補足ですが、ここでは2種類の問い合わせ(再帰問い合わせ・非再帰問い合わせ)が行われています。
DNSキャッシュ
上記である程度は名前解決の概要を説明できたかと思います。最後にDNSキャッシュについて触れておきます。
DNSの仕組みにおいてキャッシュはとても大事です。というのも、世界中で検索のたびにルートサーバに問い合わせが発生・集中していたら、サーバ過負荷により処理速度の遅延やサーバダウンなんてことが起きかねないからです。それを解決するのがDNSキャッシュの仕組みで、キャッシュによってサーバ負荷を減らし、膨大な名前解決の問い合わせをうまいことさばいています。
DNSのキャッシュは平たく言うと、ドメイン名とIPアドレスの対応関係を一時的に保存しておいて、問い合わせされたときにキャッシュがあれば返す仕組みですが、けっこういろんなところで使われています。
- ブラウザのキャッシュ
- OSのキャッシュ
- ルータのキャッシュ
- フルサービスリゾルバ(≒ キャッシュサーバ)のキャッシュ
- オーソリティを持つ各DNSサーバのキャッシュ
こんな感じで、DNSの名前解決を行う際には至るところからキャッシュを探していて、それでもなければルートサーバに問い合わせをするような流れになります。
ちなみに、キャッシュを保存する際には有効期限(Time To Live: TTL)も一緒に保存しています。有効期限を設定して一時的に保存しているのは、IPアドレスに変更があったときにずっと古いアドレスを参照し続けられると困っちゃうからです。(実際、キャッシュ更新のタイミングによっては一時的に古いIPアドレスが使用されることがあります)あとは適宜キャッシュを消さないとキャッシュがたまり続けてサイズがえらいことになってしまうからですね。
おわりに
分かりにくい箇所、間違っている箇所などあれば教えてください。
参考