はじめに
初めて GraphQL API(query) を使う人が、GitHub GraphQL API の公式ドキュメント読んだだけでは確実につまづくだろうなぁというポイントをまとめています。
あくまで大枠を理解してもらうことに主眼を置いているので、細かい仕様などは説明しきれていませんがご了承ください。
記事のゴール
「GraphQLってなに?」という人が、データ取得のクエリを作成できるようになること
※ 本記事では Mutation については扱いません
参考資料
もくじ
- GraphQL APIの概要
-
クエリ操作について
- クエリの例
- GraphQL APIに初めて触れた人が直面する疑問
- 公式ドキュメントのサンプルコードを1行ずつ補足します
- ① Query タイプのオペレーション宣言
- ② Query タイプが持つ repository フィールドへのクエリ
- ③ repository フィールドが持つ issues フィールドへのクエリ
- ④ Issues フィールドが持つ edges フィールドへのクエリ
- ⑤ edges フィールドが持つ node フィールドへのクエリ
- ⑥ node フィールドが持つ各フィールドへのクエリ
- ⑦ labels フィールドが持つ各フィールドへのクエリ
- Example query を振り返る
- GitHub GraphQL API(query) の全体を把握する
- おわりに
GraphQL APIの概要
GraphQLについて
GraphQL は Facebook によって開発された API のためのクエリ言語です。従来の REST API では各エンドポイントでサーバーが返すデータを決定していたのに対し、GraphQL は単一のエンドポイントを通じてデータの取得や操作を可能にします。
つまり、クライアント側で必要なデータ構造のクエリを定義し、それをサーバーに送信することで、必要な情報だけを取得できるというわけです。
イメージとして、「SQL とそっくり」と捉えてもらえばけっこうしっくりくるんじゃないかなと思っています。(SQL は RDB に対するクエリ言語ですが、GraphQL は API のためのクエリ言語です!)
そんなこんなで、GitHub でも REST API だけでなく GraphQL API が使えるようになっています。
GitHubは、インテグレーターにとって大きな柔軟性を提供してくれることから、GraphQLを選択しました。 必要—なデータを正確に定義する機能と、必要_なデータ_のみを—定義できることは、従来の REST API エンドポイントよりも強力な利点です。 GraphQL を使用すると、複数の REST 要求を 1 回の呼び出しに 置き換えて、指定したデータをフェッチできます。
参考:GitHub が GraphQL に投資した理由について書かれたブログ
GitHub Rest API(v3)との違い
Rest API と比較したときの GraphQL の特徴・利点は、より柔軟にデータ取得ができること、とだけ覚えてればOKかと思います。
-
REST API(v3):- 固定のエンドポイントからデータを取得するので、事前に決定されている構造でデータが返される
- 1 度に必要以上のデータを取得する「オーバーフェッチング」が起きやすい
- 必要なデータを 1 度に取得できない「アンダーフェッチング」が起きやすい
- 上記より、各エンドポイントに対して投げるリクエストの数が増えやすい
- 固定のエンドポイントからデータを取得するので、事前に決定されている構造でデータが返される
-
GraphQL API(v4):- クライアントが必要なデータの構造をクエリとして送信するため、必要なデータを過不足なく取得できる
- 上記が最大の特徴であり利点だが、REST API とは全く違うアプローチをとっているので学習コストが高め
GitHub GraphQLのオペレーション種類
一般的に GraphQL では以下の 3 種類の操作が定義されていますが、GitHub GraphQL API はそのうちの 2 種類をサポートしています。
The two types of allowed operations in GitHub's GraphQL API are queries and mutations.
-
Query:- データを取得する(読みとる)ための操作
- REST API の
GETリクエストのようなもの
-
Mutation:- データの作成、編集、削除など、データを更新するための操作
- REST API の
POST/PUT/DELETEリクエストのようなもの
-
Subscription:- リアルタイムでデータの変更を受け取るための操作
- データを継続的に取得する際などに使われる
- 現時点で GitHub GraphQL API ではサポートされていない
クエリ操作について
ここから本題の GitHub GraphQL API の Query 操作について解説します。
クエリの例
公式ドキュメントの Example query で利用されているクエリをそのまま使いつつ解説していきます。
query {
repository(owner:"octocat", name:"Hello-World") {
issues(last:20, states:CLOSED) {
edges {
node {
title
url
labels(first:5) {
edges {
node {
name
}
}
}
}
}
}
}
}
上記をコマンドで実行する場合は以下のようになります。
curl -X POST -H "Authorization: bearer YOUR_ACCESS_TOKEN" -H "Content-Type: application/json" --data '{ "query": "query GetLast20ClosedIssues { repository(owner: \"octocat\", name: \"Hello-World\") { issues(last: 20, states: CLOSED) { edges { node { title url labels(first: 5) { edges { node { name } } } } } } } }" }' https://api.github.com/graphql
また、上記の実行結果は以下のようになります。
【click to expand】 ※ Example query の実行結果
{
"data": {
"repository": {
"issues": {
"edges": [
{
"node": {
"title": "Internationalization",
"url": "https://github.com/octocat/Hello-World/issues/2831",
"labels": {
"edges": []
}
}
},
{
"node": {
"title": "SydScreenShot_FullPage.png (972×6654)",
"url": "https://github.com/octocat/Hello-World/issues/2856",
"labels": {
"edges": []
}
}
},
{
"node": {
"title": "Hello, world!2",
"url": "https://github.com/octocat/Hello-World/issues/2857",
"labels": {
"edges": []
}
}
},
{
"node": {
"title": "Hello, world!",
"url": "https://github.com/octocat/Hello-World/issues/2858",
"labels": {
"edges": []
}
}
},
{
"node": {
"title": "Hello, world!",
"url": "https://github.com/octocat/Hello-World/issues/2859",
"labels": {
"edges": []
}
}
},
{
"node": {
"title": "test",
"url": "https://github.com/octocat/Hello-World/issues/2861",
"labels": {
"edges": []
}
}
},
{
"node": {
"title": "https://github.com/octocat/Hello-World/issues/2874#issue-2054638316",
"url": "https://github.com/octocat/Hello-World/issues/2883",
"labels": {
"edges": []
}
}
},
{
"node": {
"title": "El disciplina",
"url": "https://github.com/octocat/Hello-World/issues/2885",
"labels": {
"edges": []
}
}
},
{
"node": {
"title": "take a test",
"url": "https://github.com/octocat/Hello-World/issues/3004",
"labels": {
"edges": []
}
}
},
{
"node": {
"title": " octocat/Hello-World",
"url": "https://github.com/octocat/Hello-World/issues/3013",
"labels": {
"edges": []
}
}
},
{
"node": {
"title": "Hello",
"url": "https://github.com/octocat/Hello-World/issues/3021",
"labels": {
"edges": []
}
}
},
{
"node": {
"title": "Found a bug",
"url": "https://github.com/octocat/Hello-World/issues/3056",
"labels": {
"edges": []
}
}
},
{
"node": {
"title": "test linked issue",
"url": "https://github.com/octocat/Hello-World/issues/3057",
"labels": {
"edges": []
}
}
},
{
"node": {
"title": "Hello world",
"url": "https://github.com/octocat/Hello-World/issues/3067",
"labels": {
"edges": []
}
}
},
{
"node": {
"title": "Hello, world!",
"url": "https://github.com/octocat/Hello-World/issues/3103",
"labels": {
"edges": []
}
}
},
{
"node": {
"title": "Dfr",
"url": "https://github.com/octocat/Hello-World/issues/3127",
"labels": {
"edges": []
}
}
},
{
"node": {
"title": "01-10-Tree",
"url": "https://github.com/octocat/Hello-World/issues/3161",
"labels": {
"edges": []
}
}
},
{
"node": {
"title": "https://developer.grammarly.com/API KEY QfXE9AHW2PdtmBDO6ppHXsM1",
"url": "https://github.com/octocat/Hello-World/issues/3168",
"labels": {
"edges": []
}
}
},
{
"node": {
"title": "N",
"url": "https://github.com/octocat/Hello-World/issues/3183",
"labels": {
"edges": []
}
}
},
{
"node": {
"title": "Bug: Issue with loading the homepage",
"url": "https://github.com/octocat/Hello-World/issues/3202",
"labels": {
"edges": []
}
}
}
]
}
}
}
}
GraphQL APIに初めて触れた人が直面する疑問
『こんな感じで取得できるんか便利そうだね!』
『────んで、このクエリどうやって作った...????????????』
『公式ドキュメントでクエリの例って説明されてるけど、いまいちよく分からんな...。』
公式ドキュメントのサンプルコードを1行ずつ補足します
おそらくこんな動機があったのでしょう。
『 octocat/Hello-World リポジトリ内で、解決された issue のうち最新の 20 個を取得し、各 issue のタイトル、URL、最初の 5 つのラベルを見たいなぁ!!』
というわけで、以下でクエリを 1 行ずつ解説していきます。
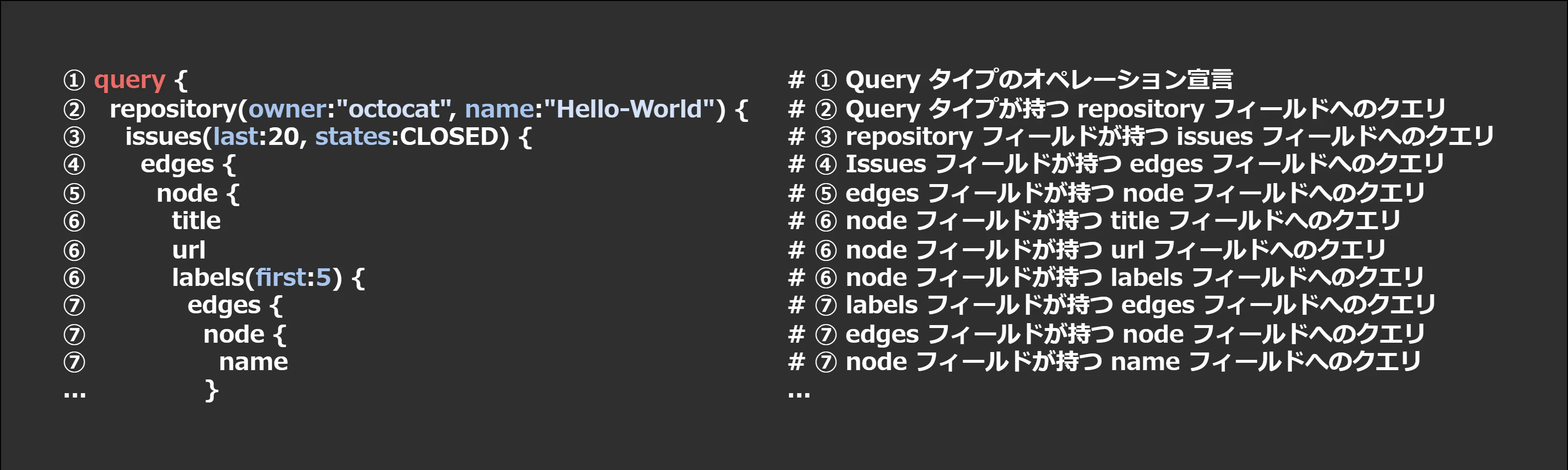
- ① Query タイプのオペレーション宣言
- ② Query タイプが持つ repository フィールドへのクエリ
- ③ repository フィールドが持つ issues フィールドへのクエリ
- ④ Issues フィールドが持つ edges フィールドへのクエリ
- ⑤ edges フィールドが持つ node フィールドへのクエリ
- ⑥ node フィールドが持つ各フィールドへのクエリ
- ⑦ labels フィールドが持つ各フィールドへのクエリ
① Query タイプのオペレーション宣言
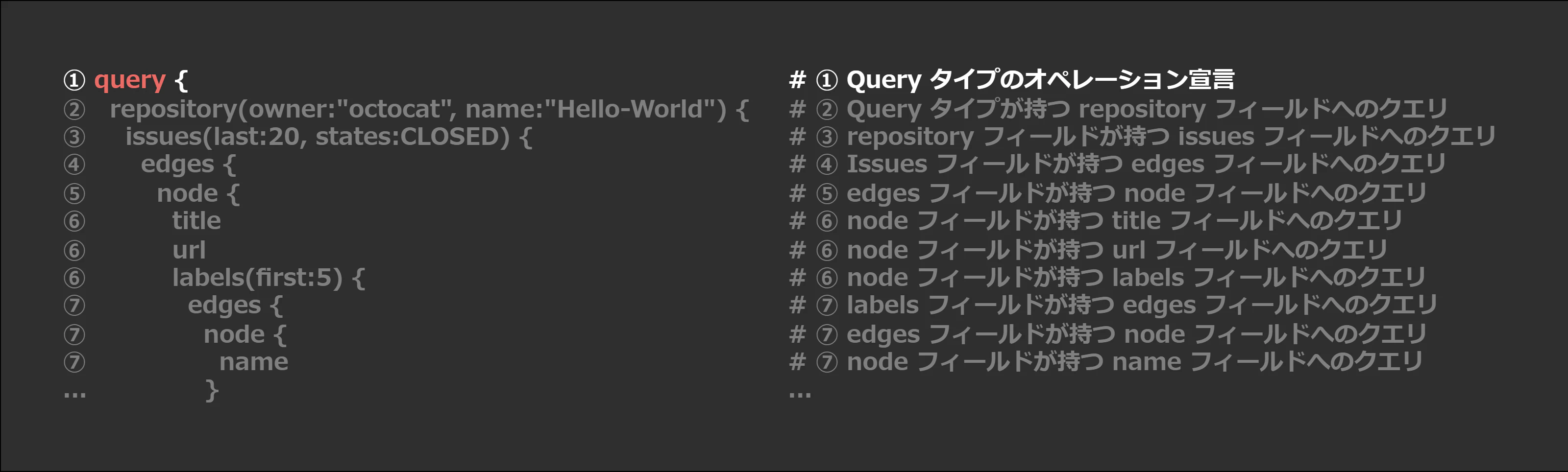
query {
Because we want to read data from the server, not modify it,queryis the root operation. (If you don't specify an operation,queryis also the default.)
GitHub GraphQLのオペレーション種類 で説明しましたが、GitHub GraphQL API では以下の2つのオペレーションをサポートしています。
-
Query:データを取得する(読む)ための操作 -
Mutation:データを作成、編集、削除など、データを更新するための操作
今回の GraphQL を利用する動機が「最新の issue を見たい」なので、利用するのは Query オペレーションです。
クエリの頭で query と宣言していますが、GraphQL のサーバーが処理を行うための起点になるため、オペレーションの宣言はクエリ内に必ず含める必要があります。
また、クエリに名前を付けることも可能です。
curl -X POST -H "Authorization: bearer YOUR_ACCESS_TOKEN" -H "Content-Type: application/json" --data '{ "query": "query FetchRecentClosedIssues { repository(owner: \"octocat\", name: \"Hello-World\") { issues(last: 20, states: CLOSED) { edges { node { title url labels(first: 5) { edges { node { name } } } } } } } }" }' https://api.github.com/graphql
② Query タイプが持つ repository フィールドへのクエリ
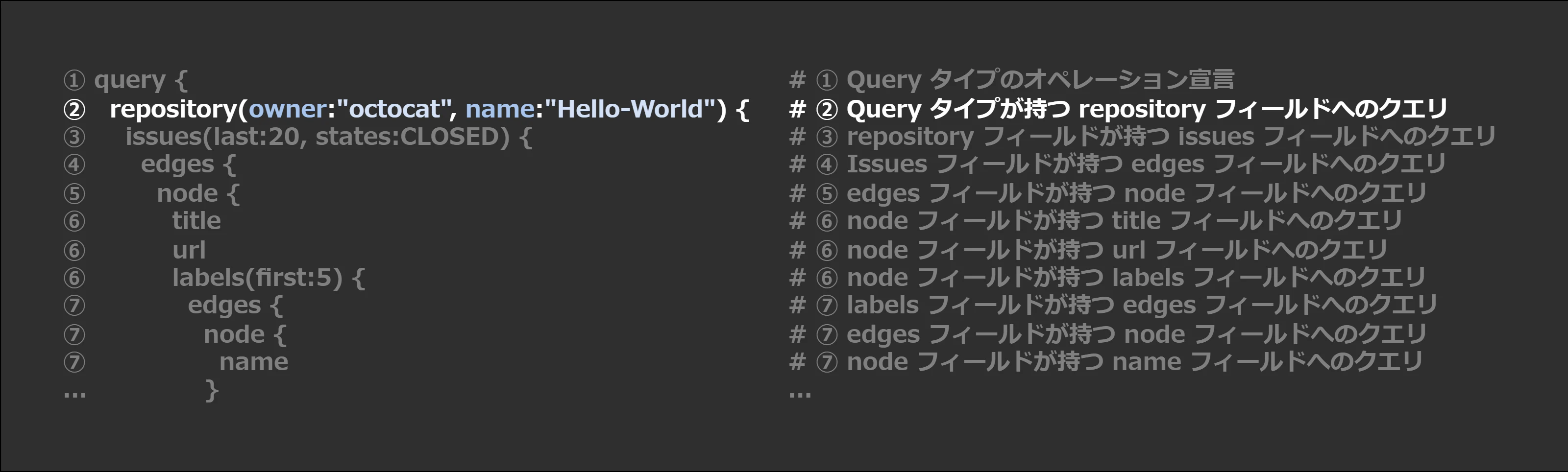
repository(owner:"octocat", name:"Hello-World") {
To begin the query, we want to find arepositoryobject. The schema validation indicates this object requires anownerand anameargument.
日本語版では、「クエリを開始するには、repository オブジェクトを検索します。 スキーマの検証により、このオブジェクトに owner と name の引数が必要であることがわかります。」とありますが、初見ではまぁ意味がわかりません。
そこで、まず見るべきドキュメントはコチラになります。
The query type defines GraphQL operations that retrieve data from the server.
GitHub GraphQL Query の中には、クエリの中の大分類ともいえるいくつかの種類が用意されているのですが、ここでは「Queryの中でもどういったQuery?」を宣言することで絞りを入れるようなイメージです。
公式ドキュメントの Example query の例では「octocat/Hello-World リポジトリ内で、解決された issue」を取得したいので、repository を選択しています。
さて、repository のドキュメントを確認すると「Arguments for repository」で必要な引数が記載されています。
-
followRenames (Boolean):デフォルトでtrue -
name (String!):リポジトリ名 -
owner (String!):リポジトリのオーナー名(ユーザー名または組織名)
必須なのは owner と name なので、octocat/Hello-World リポジトリに対するクエリの場合はサンプルの通り、 repository(owner:"octocat", name:"Hello-World") { になるというわけですね。
③ repository フィールドが持つ issues フィールドへのクエリ
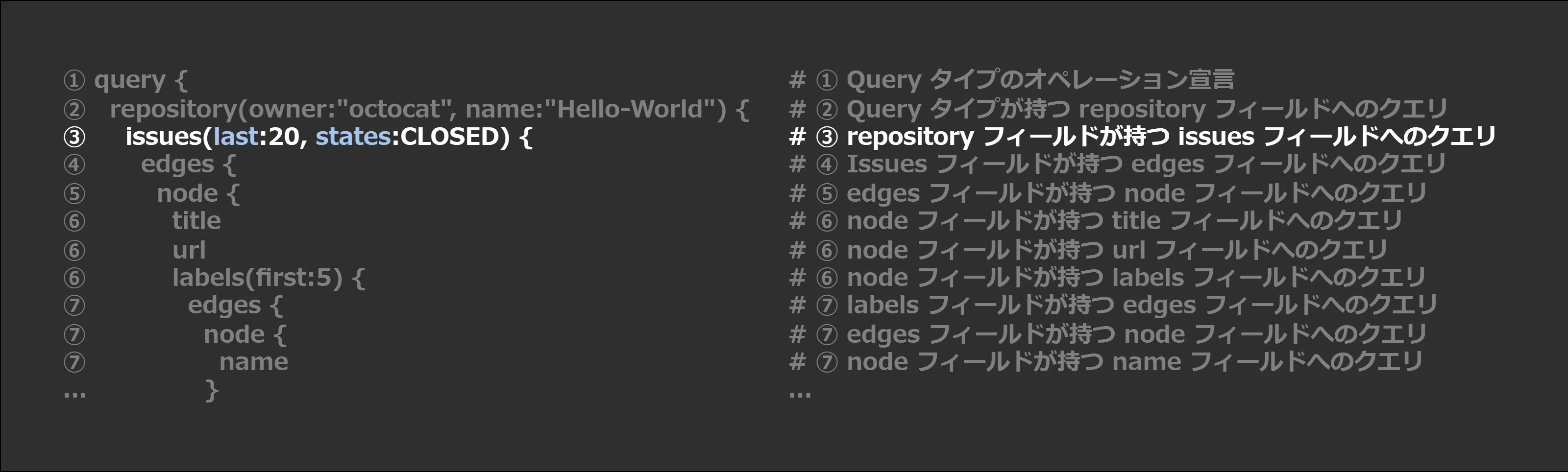
issues(last:20, states:CLOSED) {
To account for all issues in the repository, we call theissuesobject. (We could query a singleissueon arepository, but that would require us to know the number of the issue we want to return and provide it as an argument.)
先ほどの ② Query タイプが持つ repository フィールドへのクエリ で repository クエリを選択したことは分かりました。次の関心事は、「リポジトリ情報からどの情報を引っ張ってくるか?」です。
そのためにまず、この Repository クエリがどんなオブジェクトを返すのかを知る必要があります。
方法は2つあり、
- さっきの
repositoryクエリのドキュメントを見る - クエリを投げる(Discovering the GraphQL API参照)
です。
【click to expand】※クエリを投げる場合はこんな感じで確認できます
curl -X POST -H "Authorization: bearer YOUR_ACCESS_TOKEN" -H "Content-Type: application/json" --data '{ "query": "query { __type(name: \"Repository\") { name kind description fields { name } } }" }' https://api.github.com/graphql
Repository という名前のオブジェクトが返ることが分かります。
{
"data": {
"__type": {
"name": "Repository",
"kind": "OBJECT",
"description": "A repository contains the content for a project.",
"fields": [
{
"name": "allowUpdateBranch"
},
{
"name": "archivedAt"
},
{
"name": "assignableUsers"
},
{
"name": "autoMergeAllowed"
},
{
"name": "branchProtectionRules"
},
※以下略
というわけで、 repository クエリは repository オブジェクトを返すことが分かりました。そこが分かったら、repository オブジェクトに関するドキュメントを見てみましょう。
ドキュメントを確認すると、repository オブジェクトはたくさんのフィールドを持っていることが分かります。
今回は「解決された issue のうち最新の 20 件」が欲しいので、個別の Issue である issue フィールドではなく issues フィールドを選択します。
以下で、公式ドキュメントの クエリの例 で説明されている Some details about the issues object: の部分をいい感じに翻訳します。
- The docs tell us this object has the type
IssueConnection.
訳:issues というフィールドが IssueConnection 型を返すことを意味しており、IssueConnection 型はnon-nullable(このフィールドがnullを返すことはない!)であることを示しているよ。
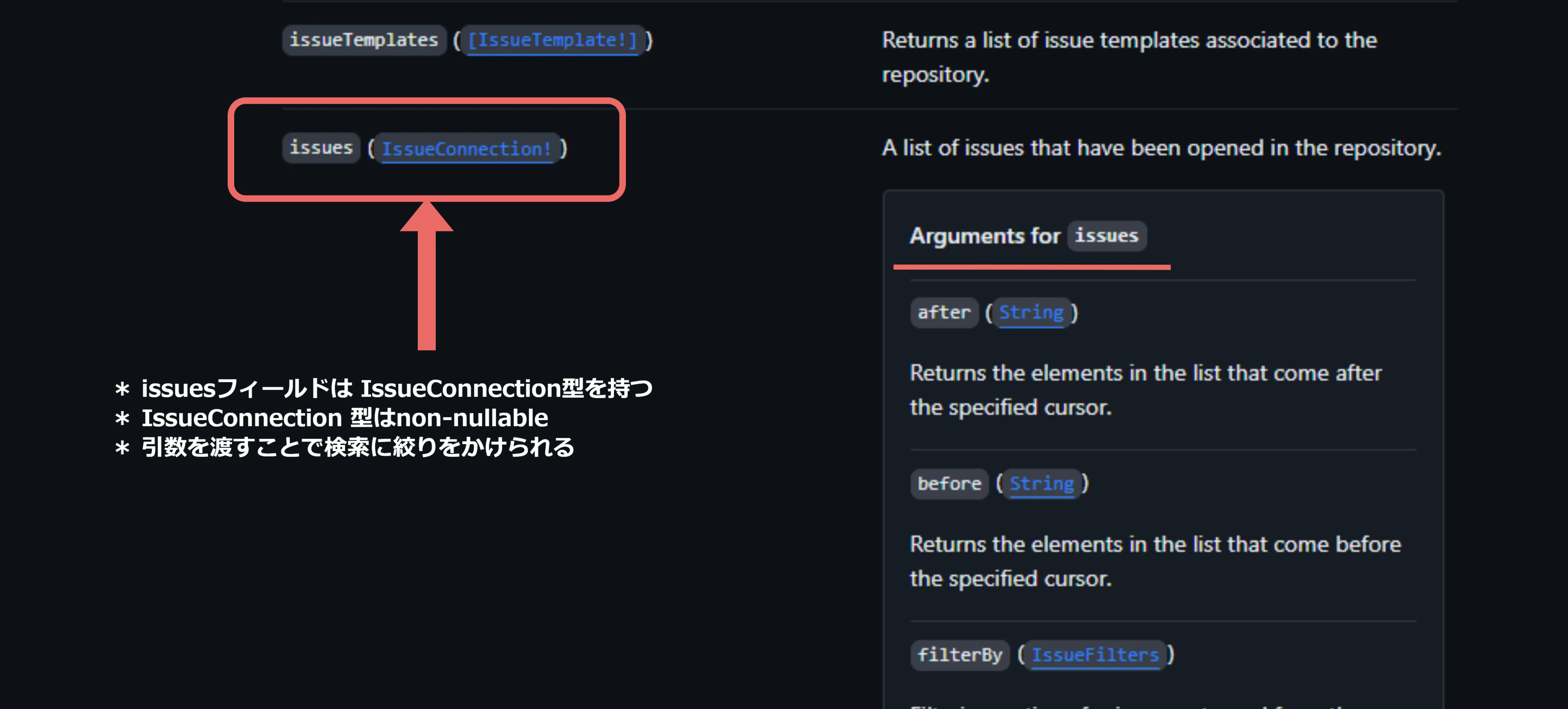
※ GraphQLの型システムでは、型名の後に ! が付くことで、その型がnon-nullableであると指定されます
- Schema validation indicates this object requires a
lastorfirstnumber of results as an argument, so we provide20.
訳:Arguments for issues に記載されている引数を指定することで、絞りをかけられるよ。今回だったら「Issue のうち最新の20件」が欲しいから、last:20 で指定するよ。
- The docs also tell us this object accepts a
statesargument, which is anIssueStateenum that acceptsOPENorCLOSEDvalues. To find only closed issues, we give thestateskey a value ofCLOSED.
訳:Arguments for issues では states も引数で指定できるって書いてあるよ。「解決済み Issues」の情報が欲しいので、states:CLOSED を指定するよ。
④ Issues フィールドが持つ edges フィールドへのクエリ
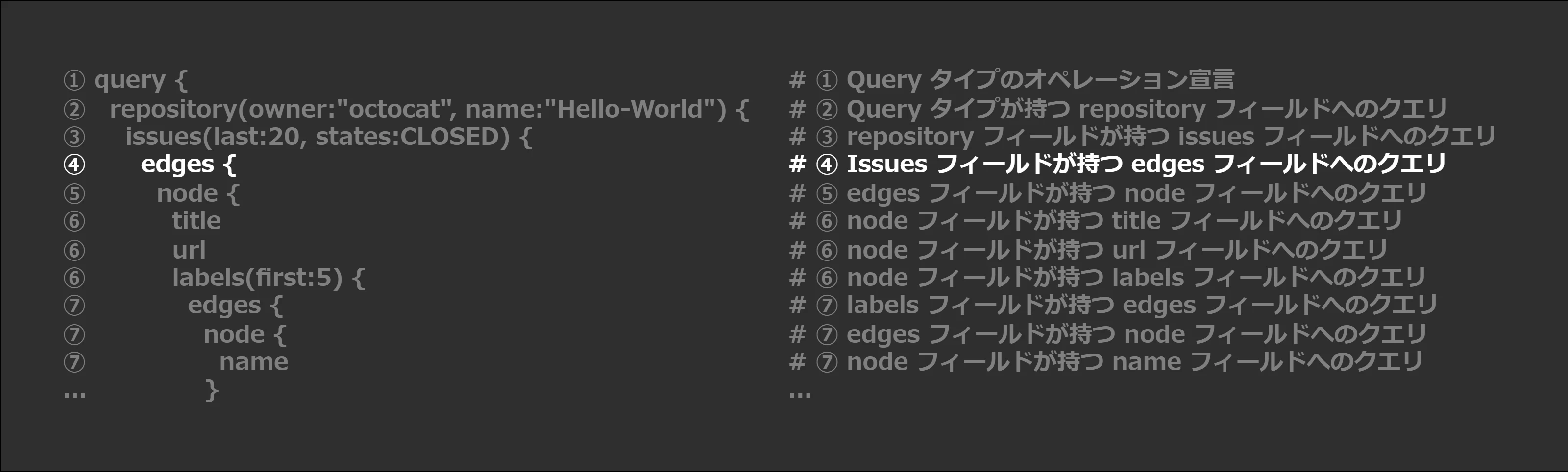
edges {
We knowissuesis a connection because it has theIssueConnectiontype. To retrieve data about individual issues, we have to access the node viaedges.
上記の説明文を1つずつ解読します。
We know issues is a connection because it has the IssueConnection type.
GraphQL には connection という概念があります。
GitHub GraphQL API での 1 度のクエリリクエストにより、特定の connection オブジェクト(例えば IssueConnection )が 1 つ得られます。connection オブジェクトはそれに関連する複数のアイテム(この場合は Issue の)情報をリストで持っています。(例えば edges フィールドや nodes フィールドなど)
詳しくはこちらの記事を読むとイメージが付くかと思います。(図解がとても分かりやすくてありがたい)
なので、とりあえず「issues フィールドの戻り値は IssueConnection 型ってことは、Issue に関する connection オブジェクトを介してデータを取得することができるんだな」くらいの理解でいったんよいと思います。
To retrieve data about individual issues, we have to access the node via edges.
「個々の issue に関するデータを取得するには、edges を介して node にアクセスする必要があるよ」とのことですが、実は Example query の場合は edges を介さなくても同じデータを取得することができます。
例えば、IssueConnection オブジェクトは以下のように edges、nodes、pageInfo、totalCount と4つのフィールドを持っています。
{
"data": {
"__type": {
"name": "IssueConnection",
"kind": "OBJECT",
"description": "The connection type for Issue.",
"fields": [
{
"name": "edges",
"args": []
},
{
"name": "nodes",
"args": []
},
{
"name": "pageInfo",
"args": []
},
{
"name": "totalCount",
"args": []
}
]
}
}
}
GitHub公式ドキュメント内の Example query では上記の edges フィールドを使っていますが、以下のような nodes フィールドを使う形でも同じデータが取れます。
query {
repository(owner:"octocat", name:"Hello-World") {
issues(last:20, states:CLOSED) {
nodes {
title
url
labels(first:5) {
nodes {
name
}
}
}
}
}
}
なのですが、なぜここで 「個々の issue に関するデータを取得するには edges を介してね」と言われているかというと、簡単に言えば今回のような IssueConnection オブジェクト(つまりはIssueの一覧)を操作する際に、edges を介したほうが融通が利きやすいからです。
今回の例からは話が逸れますが、例えば直近に起票された Issue とその関連情報を 500 件取得したいとして、1 度のリクエストで 100 件分を取得しようとすると、リクエストを 5 回投げる必要があります。このとき、100 件目と 101 件目をどう判別したらよいでしょうか。
IssueConnection オブジェクトのような複数の Issue を内包したオブジェクトにおいて、edges は各 node (つまり個々のIssue)への参照だけでなく、各 node がオブジェクト全体の中でどの位置にいるかという追加情報(ページネーション用の cursor など)を提供します。
Issue が多数ある場合、全てを一度にロードしてクライアントに返すのは効率が悪い(もしかしたら不可能かも)場合があるので、GraphQL では edges を通じてそれぞれの node にアクセスし、各 edge が持つ cursor を利用して、どのデータが既に取得されたかを追跡しながらページネーションを効果的に実施できるようになっています。
まとめるとこんな感じです。
-
edgesフィールドはページネーションやnodeのメタデータが必要な場合に便利 -
nodesフィールドは直接nodeにアクセスするようなシンプルなデータ取得の場合に効率的
話を戻すと、個別の Issue に関わる周辺情報などを取得する場合は、 edges を介してデータ取得すると融通利くよ!ということが分かっていればよい気がします。
⑤ edges フィールドが持つ node フィールドへのクエリ
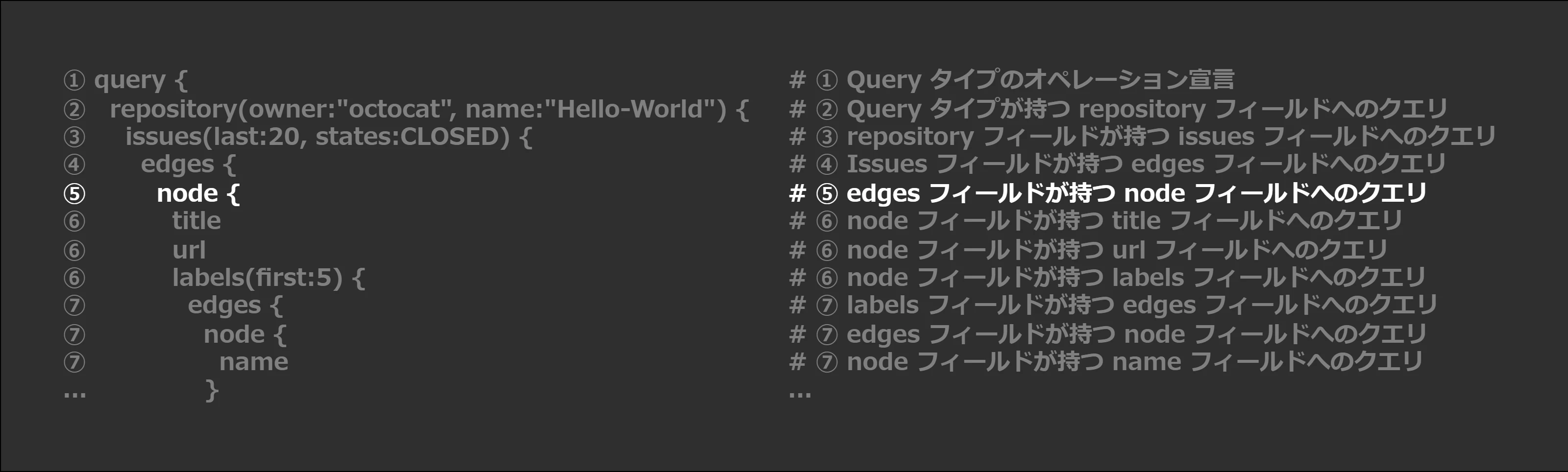
- node {
Here we retrieve the node at the end of the edge. TheIssueConnectiondocs indicate the node at the end of theIssueConnectiontype is anIssueobject.
IssueConnection フィールドが持つ edges フィールドは、リスト型の IssueEdge オブジェクトを返します。で、IssueEdge オブジェクトはノードとして、欲しかった Issue 情報である Issue オブジェクトを持っていることが分かります。
⑥ node フィールドが持つ各フィールドへのクエリ

- Now that we know we're retrieving an
Issueobject, we can look at the docs and specify the fields we want to return:
Here we specify thetitle,url, andlabelsfields of the Issue object.
はい、本命の Issue の情報までたどり着きました。
もともとの動機が『 octocat/Hello-World リポジトリ内で、解決された issue のうち最新の 20 個を取得し、各 issue のタイトル、URL、最初の 5 つのラベルを見たいなぁ!!』だったので、title、url、label を探します。結果、以下のような戻り値であると分かりました。
- title (String!)
- url (URI!)
- labels (LabelConnection)
今まで「このフィールドはこのオブジェクトを返す」で辿ってきましたが、どこまでいけば終わりが来るのでしょうか。その答えは以下のドキュメントにまとまっています。
GraphQL queries return only the data you specify. To form a query, you must specify fields within fields (also known as nested subfields) until you return only scalars.
Scalars are primitive values: Int, Float, String, Boolean, or ID.
When calling the GraphQL API, you must specify nested subfields until you return only scalars.
GraphQLにおいて、スカラー(Scalar)はプリミティブな値を表しており、ドキュメントでは Int、Float、String、Boolean、ID がそれにあたると示されています。なので、それ以上分解できない単一の値(スカラー)になるまで、つまり戻り値が Int、Float、String、Boolean、ID になるところまで指定しないといけないということですね。
これを踏まえて、上記の title、url、labels フィールドを見てみます。
-
title(String!):Stringなのでここが末端 -
url(URI!):ドキュメント より形式が指定されたStringなのでここが末端 -
labels(LabelConnection):Connectionオブジェクトなのでさらに深堀りが必要になる
もうちょっとがんばりましょう。
⑦ labels フィールドが持つ各フィールドへのクエリ

The
labelsfield has the typeLabelConnection. As with theissuesobject, becauselabelsis a connection, we must travel its edges to a connected node: thelabelobject. At the node, we can specify thelabelobject fields we want to return, in this case,name.
もはや IssueConnection と同じです。
labels (LabelConnection) > edges ([LabelEdge]) > node (Label) > name (String!) の順番に進んでいくと、最終的にプリミティブな値であるスカラー(String)にたどり着きました。
Example query を振り返る
クエリを 1 行ずつ上から見てきましたが、いかがでしたでしょうか。
ドキュメントの例ではクエリ型の選択という大きいところから出発して開設されていますが、実際にクエリを作成する際にはほしいデータからの逆算で考えるとよいかもしれません。
「戻り値がスカラーである取得したいフィールド」から逆算して、そのフィールドがどのオブジェクトに属しているのかを 1 つずつ見ていきながらクエリを作成するという感じになるかもです。
GitHub GraphQL API(query) の全体を把握する
GraphQL はデータを要求し取得するための強力なクエリ言語ですが、その効率と柔軟性の秘密は「スキーマ」にあります。
スキーマは GraphQL API を利用する上での地図のようなもので、スキーマへの理解があれば、自分でクエリを作成していくことができるようになります。
以下は、公式が提供している schema.docs.graphql という GraphQL を利用するうえで必要になるスキーマ情報から、今回解説した Example query に関わる部分を抜き出したものです。
type Query {
repository(
followRenames: Boolean = true
name: String!
owner: String!
): Repository
}
type Repository implements Node & PackageOwner & ProjectOwner & ProjectV2Recent & RepositoryInfo & Starrable & Subscribable & UniformResourceLocatable {
issues(
after: String
before: String
filterBy: IssueFilters
first: Int
labels: [String!]
last: Int
orderBy: IssueOrder
states: [IssueState!]
): IssueConnection!
}
type IssueConnection {
edges: [IssueEdge]
nodes: [Issue]
pageInfo: PageInfo!
totalCount: Int!
}
type IssueEdge {
cursor: String!
node: Issue
}
type Issue implements Assignable & Closable & Comment & Deletable & Labelable & Lockable & Node & ProjectV2Owner & Reactable & RepositoryNode & Subscribable & SubscribableThread & UniformResourceLocatable & Updatable & UpdatableComment {
labels(
after: String
before: String
first: Int
last: Int
orderBy: LabelOrder = {field: CREATED_AT, direction: ASC}
): LabelConnection
title: String!
url: URI!
}
type LabelConnection {
edges: [LabelEdge]
nodes: [Label]
pageInfo: PageInfo!
totalCount: Int!
}
type LabelEdge {
cursor: String!
node: Label
}
type Label implements Node {
name: String!
}
例えば、
-
type Queryはrepositoryフィールドを持っており、repositoryフィールドに対するクエリはrepository型のオブジェクトを返す -
type repositoryはissuesフィールドを持っており、issuesフィールドに対するクエリはIssueConnection!型のオブジェクトを返す -
type IssueConnectionはedgesフィールドを持っており、edgesフィールドに対するクエリは リスト型のIssueEdgeオブジェクトを返す
といったように、スキーマは入れ子構造のような関係になっていることが分かります。つまり、スキーマを 1 つずつ辿っていくことで、取得したいデータのクエリを組み立てることができるというわけです。
おわりに
ここで紹介したものはあくまで基礎の部分ですが、この辺を分かっていれば関連情報を調べるときに理解しやすくなるかなと思います。
今回の記事では紹介していませんが、インターフェースやエイリアス、Fragment など周辺の概念なども知っておくとより扱える幅が広がります。
世の中にはいっぱい記事があるので、もし興味を持ったら手を動かしてみてください~!