今回は、pythonで、話した言葉を文字起こしするアプリを作成しました。
これは、タイピングが苦手な人や、紙のメモをパソコンにそのまま入力したいときなどに役立ちます。
使用方法
zipファイルをダウンロードして解凍したら、voice_memoディレクトリで下記を実行して必要なライブラリをインポート、
pip install -r requirements.txt
できたら下記を実行します。
python voice_memo.py
実行結果
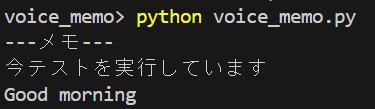
このように、話した言葉を文字起こししてくれます。頑張って発音すれば英語もいけます。終了するときは、'q'キーを押します。
実装方法
今回は、マイク入力と文字起こし共に、speech_recognitionを利用しました。
具体的には、まずSpeechRecognitionライブラリのRecognizerクラスのインスタンスを作成、
import speech_recognition as sr
r = sr.Recognizer()
マイクから話した言葉を受け取るには下記の関数で、
def get_audio_from_mic():
with sr.Microphone(sample_rate=16000) as source:
audio = r.listen(source, timeout=None)
return audio
それを文字起こしするには下記の関数で、
def convert_audio_to_text(audio_data):
try:
text = r.recognize_google(audio_data, language="ja-JP")
print(text)
save_to_file(text) # テキストをファイルに保存
except sr.UnknownValueError:
pass
実装しました。main関数は以下のようになっています。
def main():
print("---メモ---")
# 録音ループ
while not exit_loop:
audio_data = get_audio_from_mic()
# マルチスレッドで音声をテキストに変換
threading.Thread(target=convert_audio_to_text, args=(audio_data,)).start()
音声をテキストに変換中も音声を受け取れるように、マルチスレッドを導入しました。
全体のコード
A.py
import os
import speech_recognition as sr
import threading
import keyboard
import datetime
r = sr.Recognizer()
# outputディレクトリが存在しない場合は作成する
OUTPUT_DIR = "output"
if not os.path.exists(OUTPUT_DIR):
os.makedirs(OUTPUT_DIR)
# 現在の日時からファイル名を生成
now = datetime.datetime.now()
MEMO_FILE = os.path.join(OUTPUT_DIR, now.strftime("%Y-%m-%d_%H-%M-%S_memo.txt"))
def get_audio_from_mic():
with sr.Microphone(sample_rate=16000) as source:
audio = r.listen(source, timeout=None)
return audio
def convert_audio_to_text(audio_data):
try:
text = r.recognize_google(audio_data, language="ja-JP")
print(text)
save_to_file(text) # テキストをファイルに保存
except sr.UnknownValueError:
pass
def save_to_file(text):
with open(MEMO_FILE, "a") as file: # ファイルを追記モードで開く
file.write(text + "\n") # テキストをファイルに書き込む
# キーボードからの入力を監視して、'q'キーが押されたらループを抜ける
exit_loop = False
def on_key_event(event):
global exit_loop
if event.name == "q":
exit_loop = True
keyboard.on_press(on_key_event)
def main():
print("---メモ---")
# 録音ループ
while not exit_loop:
audio_data = get_audio_from_mic()
# マルチスレッドで音声をテキストに変換
threading.Thread(target=convert_audio_to_text, args=(audio_data,)).start()
if __name__ == "__main__":
main()