概要
クラウドアプリケーションの特性
クラウドアプリケーションの特性は、従来のアプリケーションと大きく異なります。
ユーザー数は非常に簡単に数百万人に達し、データボリュームは短期間で PB レベルや EB レベルに到達することもあります。
パフォーマンスは、多くの場合、ミリ秒で動作することが期待されます。
アプリケーションによっては、 1 秒間に数百万件のリクエストを処理し、多い日には 1 秒間に数千万件のリクエストを処理することもあるでしょう。
適切なコストとパフォーマンスを維持するためにシステムが分散し、スケールアップ、アウト、インできるアプリケーションである必要があります。
Amazon DynamoDBでは、開発者は完全マネージド型の API を介して瞬時にアクセスし利用することができます。
- クラウドアプリケーションに求められる特性
| 要素 | 特性 |
|---|---|
| ユーザー | 100 万人以上 |
| データボリューム | TB、PB、EB |
| データの局所性 | グローバル |
| パフォーマンス | ミリ秒、マイクロ秒 |
| リクエスト頻度 | 数百万 |
| アクセス | モバイル、IoT、デバイス |
| スケール | Up and down |
| エコノミクス | 従量制料金 |
| 開発手法 | API アクセス |
Amazon DynamoDB 自体の解説についてはこちら
Amazon DynamoDB の特性
- フルマネージド型の NoSQL データベースサービス
- 3つの Availability Zone に保存されるので信頼性が高い
- 性能要件に応じて、テーブルごとにスループットキャパシティを定義するキャパシティの Auto Scaling、オンデマンドキャパシティといった設定も可能
- ストレージの容量制限がない
DynamoDB のテーブル
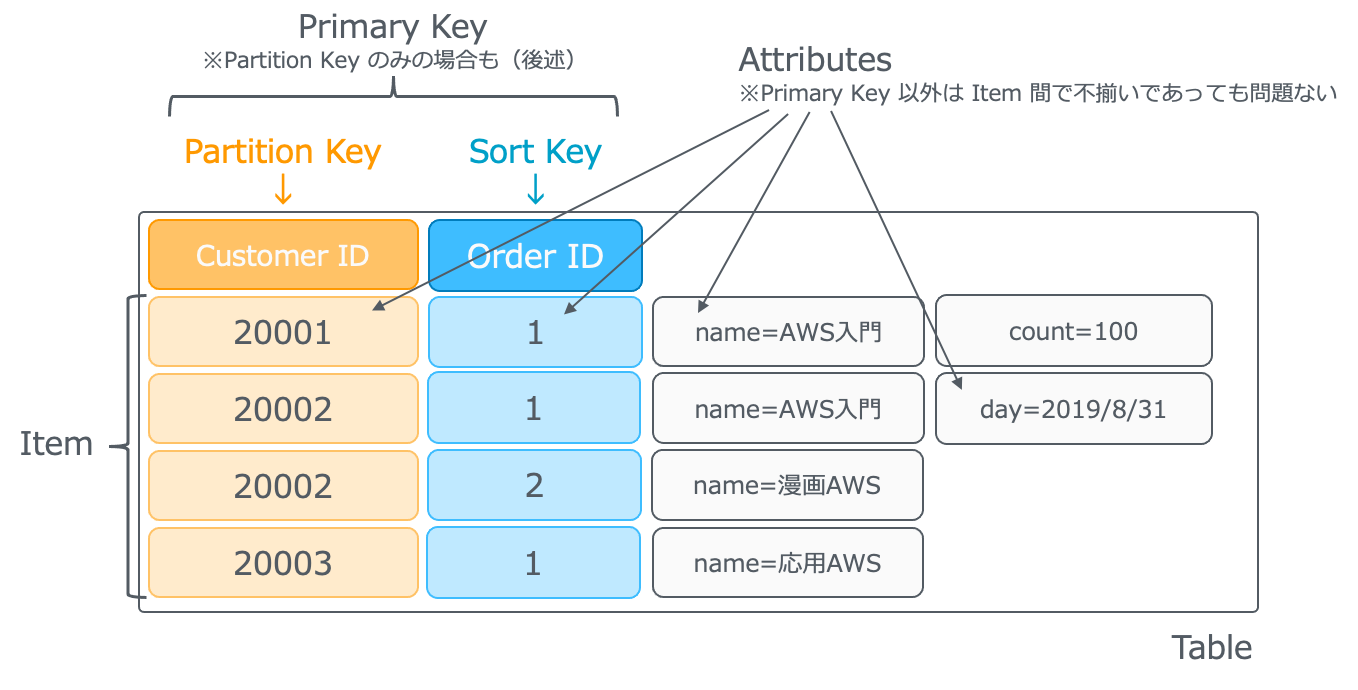
DynamoDB におけるテーブルはRDBMSにおけるテーブルと概念が異なります。
テーブルを作成する際に、Primary Key を指定する必要があります。
Primary Key はテーブルの各項目を一意に識別するために使います。Primary Key は、Partition Key および Sort Key で構成されます。(Sort KeyがなくPartition Keyのみの場合もあります)
Item は RDBMS でいうレコードになります。
各ItemはAttributesによって構成されますが、Primary Key 以外の Attribute については不揃いであっても問題ありません。
Partition Key と Sort Key
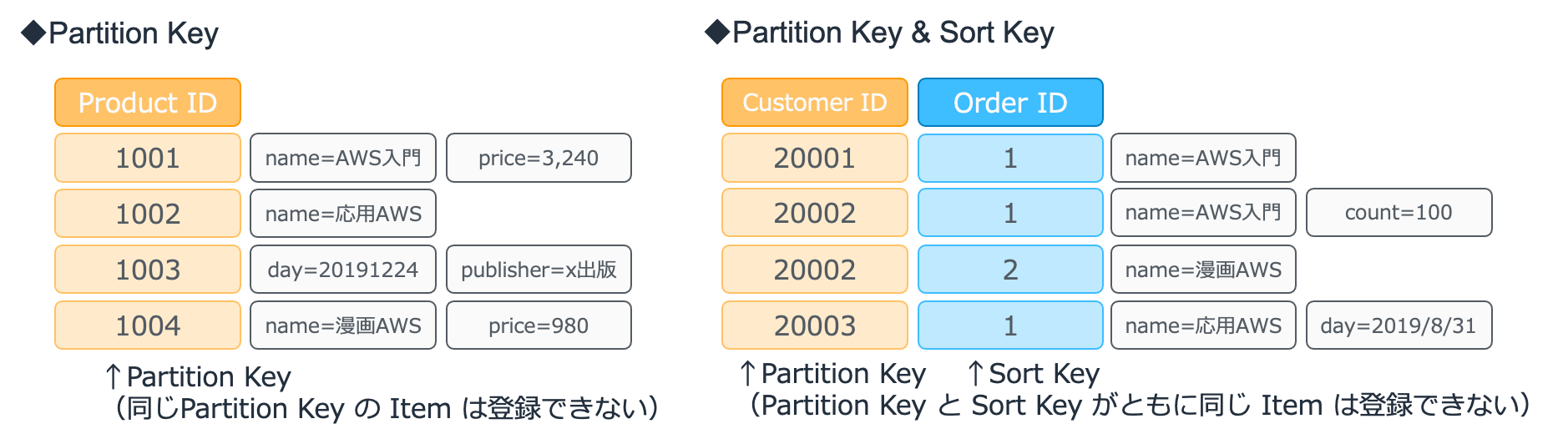
DynamoDB では2種類のプライマリーキーをサポートする
https://aws.amazon.com/blogs/database/choosing-the-right-dynamodb-partition-key/
- Partition Key
- Partition Key & Sort Key
Secondary Index
https://docs.aws.amazon.com/ja_jp/amazondynamodb/latest/developerguide/SecondaryIndexes.html
DynamoDB では2種類の Secondary Index を利用することができる
- Local Secondary Index (LSI)
- Sort Key 以外に絞り込み検索を行う Key を持つことができる
- Partition Key はベーステーブルと同じで、Sort Key が異なる
- Global Secondary Index (GSI)
- Partition Key 属性の代わりとなる、Partition Key をまたいで検索を行うためのインデックス
LSIの例

Capacity Unitの考え方
- Read: 1ユニットにつき、最大4KBのデータを1秒に2回読み込み可能(強い一貫性を持つ読み込み設定であれば、1秒あたり1回)
- Write: 1ユニットにつき、最大1KBのデータを1秒に1回書き込み可能
DynamoDB におけるデータの操作
API Call によるデータ操作を行う
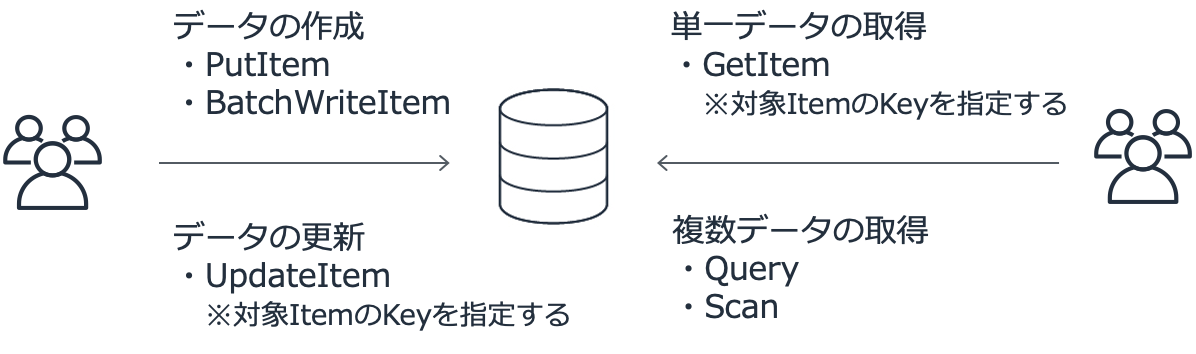
https://docs.aws.amazon.com/ja_jp/amazondynamodb/latest/developerguide/HowItWorks.API.html
https://docs.aws.amazon.com/ja_jp/amazondynamodb/latest/developerguide/bp-query-scan.html
DynamoDB の知識とベストプラクティス
-
テーブルの数は最小限に留める
- 一箇所にあるデータに、テーブルやインデックスを通じアクセスすることで望む形のデータが入手しやすいように構成
- キャパシティユニットの効率向上
- テーブルを分けるべき例外はある
-
DynamoDB は Primary Key(Partition Key(PK)、または PK + Sort Key(SK) の複合)でデータを識別し、アクセスする
-
Query 等のAPI利用
-
グローバルセカンダリインデックスは元テーブルから非同期レプリケーションされる別テーブルのような存在
-
1テーブルや1インデックスに複数種類のアイテムをもたせてもよいし、1属性に複数種類の値を入れてもよい
https://docs.aws.amazon.com/ja_jp/amazondynamodb/latest/developerguide/best-practices.html
DynamoDB の設計について
RDBMS と DynamoDB のモデリングの違い
RDBMS のモデリングプロセス
みなさまよくご存知の RDBMS におけるモデリングプロセスです。

DynamoDB のモデリングプロセス
DynamoDB でよくある誤解の一つに、「DynamoDB ってスキーマレスだから、事前の設計いらないでしょ?」があります。

しかし、このように、DynamoDB においても、アクセスパターン に基づいた設計が必要です
イベント検索アプリを実際に設計してみる
対象とするサンプルアプリケーションについて
今回は、イベントの検索画面と検索結果の一覧表示画面を持つアプリケーションを考えていきます。
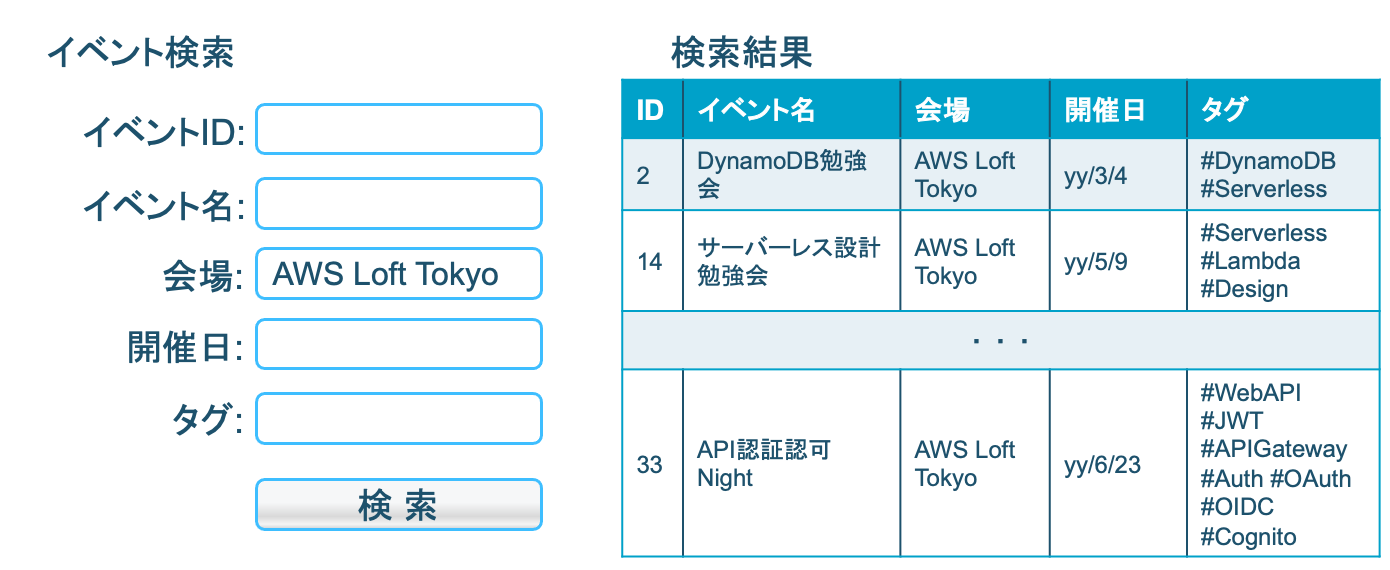
※ この例題では、シンプルに各項目を完全一致で検索できるようにするものとします
※ 現実的には OpenSearch 等の利用も検討してください(今回はDynamoDBの学習教材としてお考えください)
それぞれのモデリングプロセスを実例を交えてもう少し詳しく見てみよう
ドメインデータモデリング

- 対象ドメインのデータをモデリング
- RDB 設計と同じく ER 図による概念と論理レベルの整理は有効
今回のアプリケーションのER図はこんな感じにしてみました。他にも様々な設計方針があると思いますが、今回はこれで。

もし、この ER を SQL でアクセスするならこんな感じになるはずです。
-- 例: 会場名とタグでイベントを完全一致検索
SELECT e.id, v.name, ...
FROM Events e
JOIN Venues v
ON v.id = e.venue_id
JOIN EventTags et
ON et.event_id = e.id
JOIN Tags t
ON t.id = et.tag_id
WHERE v.name = :vname AND t.name = :tname
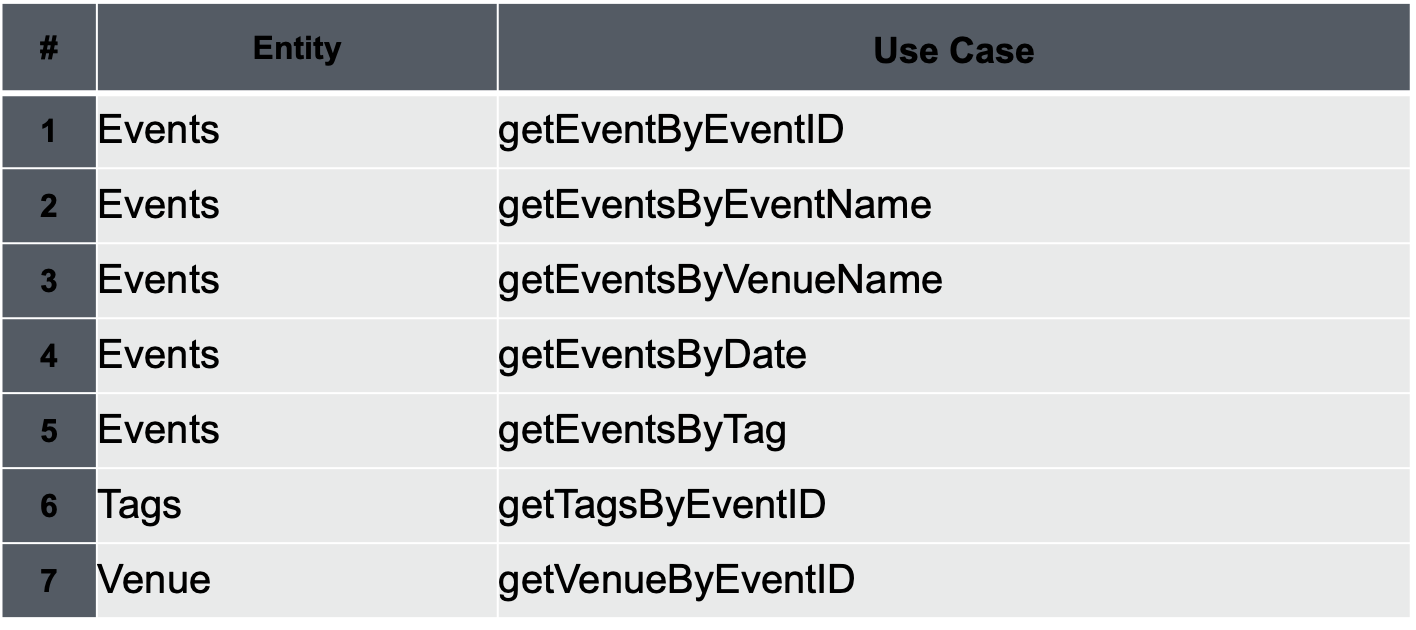
アクセスパターン設計

- ビジネス要件からアプリケーションで必要な機能とデータ(アクセスパターン)を整理する
- 「イベント情報を ID で検索する」など
- アクセスパータンが洗い出せたら、それぞれ Use Case に落とし込んで見る
- 「イベント情報を ID で検索する」=> 「getEventByEventID」
Index設計

- ユースケースを満たせるテーブルおよびインデックスのスキーマを設計する
何も考えずにシンプルに DynamoDB に落とし込んでみると? どうなる?
RDBMS の経験則に沿った設計方針
シンプルな Attributes 列挙パターン
RDBMSのスキーマ設計のように、まずはシンプルに Attributes (RDBMSでいうカラムのようなもの)を横並びに持ってみたいと思います。

※ {foo} は何らかの値が入っていることを示す
この構成の懸念点
- GetItem や Query が EventID にしか使えず、それ以外の属性で検索したいとき Scan + Filter で高コストになってしまう
- Scan はテーブル・インデックス内を文字通りフルスキャンするため、パフォーマンスおよびコスト面のリスクがある
- 項目数が少なく Scan で問題ないことが担保できている場合などを除き、一般に Scan でなく Query や GetItem / BatchGetItem の利用を検討すべき
Attributes 列挙 GSI パターン
前例の懸念点を踏まえて、GSIによるインデックス追加を実施してみます。

この構成で解決した点
- 各 Attribute に Global Secondary Index が貼られたため Query が可能に
- ※ GSI はデフォルトで 20 個/テーブル。それ以上は上限緩和を申請
この構成の懸念点
- GSI が増えることによる金銭(スループット+ストレージ)コスト増、管理コスト増
- 多くの GSI をアプリケーションが意識する必要がある
- このスキーマが絶対にダメというわけではないが他の設計パターンを踏まえて検討すべき
DynamoDB らしい Index 設計テクニック
GSI オーバーローディング パターン
- 1 項目内にフラットに属性を並べるのではなく、情報を縦に持つ
- 一つの GSI に複数の検索要件をもたせる(GSI オーバーローディング)
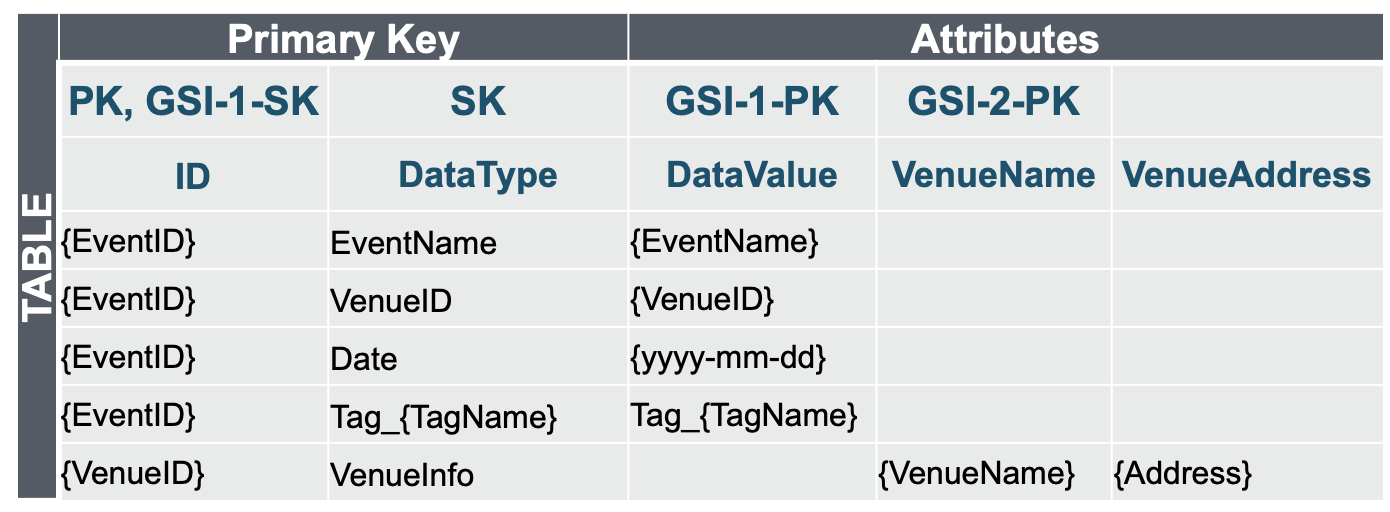
それぞれ GSI をどのように構成しているかみてみましょう。
基本的な方針としては、検索条件として指定したい属性をキーとする GSI を定義するようにしています。
-
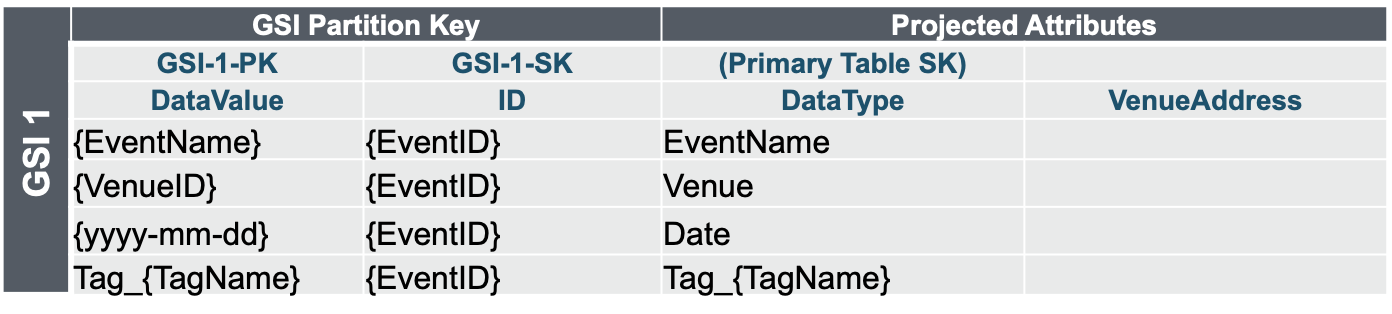
GSI-1
-
GSI-2

この構成で解決した点
- GSI の数が少なくて済み、コストやクエリを最適化できる
格納されるデータイメージ
実際にはこのような値が入ることを想定
この例の場合、E123 と E145 の2つのイベント情報。会場はどちらも V32 としている
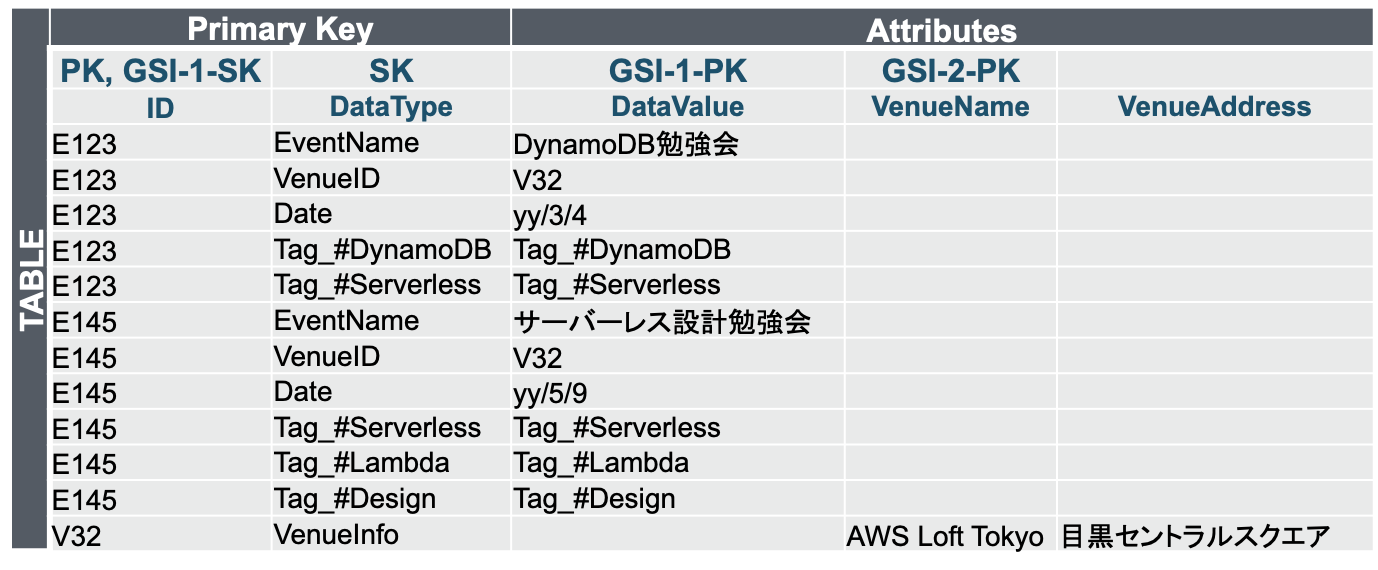
データに対するQueryを考えてみる
EventのIDに対する検索では、Primary Key の Partition Key がそのまま利用できる。
つまり、Query(ID = :eventId) で該当 EventのIDでアイテムが取得できる
例: Table.Query(ID = "E123")

タグに対する検索は、GSI-1 の Partition Key を利用する。
Query(DataValue = :tagName) で該当 タグ を持つ Event の ID を取得できる
例: GSI1.Query(DataValue = "Tag_#Serverless")

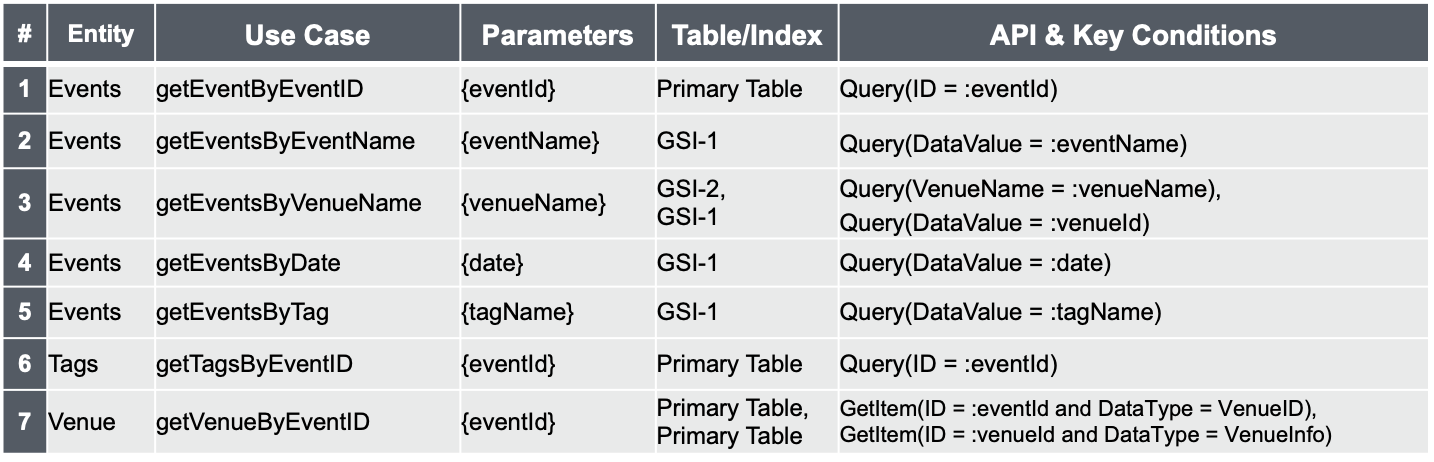
Query条件設計

- どのユースケースにはどの Table / Index を使い、どうデータを問い合わせるのか(GetItem? GetBatchItem? Query? Scan?)を列挙
- Filter Condition や Projection Expression などを記述してもよし
まとめ
-
サーバーレスアプリケーション にはスケーラブルな Amazon DynamoDB が使いやすい
- 懸念事項を考慮の上で許容できるならその限りではない
-
DynamoDB のモデリングプロセスは
- 業務分析してデータモデルを整理
- ユースケースリスト
- テーブル・インデックス設計
- クエリ条件設計
-
公式ドキュメントのベストプラクティスを踏まえた上で設計に臨むとよい。
Appendix
GSI オーバーローディングに関するより詳細な情報はこちら。

※ 画像をクリックするとBlackBelt資料に飛びます。