はじめに
こんにちは、普段業務でGoを書いているkenと申します。
突然ですが問題です。
要素数が10,000個あるint型のスライスの中から100という要素が存在するかどうかを判定してくださいといわれたら、どんなコードを書けば良いでしょうか。
様々な実装方法があると思いますが、ネットで検索すると4つの選択肢が見つかりました。この記事ではその4つの方法をご紹介します。そして最後にはどの書き方を採用すべきなのかについても触れていこうかなと思います。
方法1: 愚直にひとつずつ探索していく
一番素直な実装だと思います。
与えられたスライスの要素をひとつずつ確認し、該当する要素があればtrueを返すというものです。
いわゆる線形探索というやつですね。
func simpleInFunction(slice []int, key int) bool {
for _, s := range slice {
if s == key {
return true
}
}
return false
}
方法2: mapを活用する
この方法はまずintをkeyに持ち空の構造体をvalueにもつmap準備し、ここに与えられたスライスをkeyの部分にセットしていきます。
そして最後にkeyの存在確認をして答えを出力するという方法です。
func inFunctionWithMap(slice []int, key int) bool {
m := map[int]struct{}{}
for _, s := range slice {
m[s] = struct{}{}
}
_, ok := m[key]
return ok
}
面倒に感じるかもしれないこの方法ですが、実はその背後には利点が潜んでいます。その詳細は後ほどお伝えいたします。
方法3: slicesパッケージのContains関数を用いる
こちらはGoの1.18で追加された slicesパッケージのContains関数をそのまま用いる方法です。
import (
"golang.org/x/exp/slices"
)
func containsFunctionWithSlicesPkg(slice []int, key int) bool {
return slices.Contains(slice, key)
}
方法4: golang-setパッケージのContainsメソッドを用いる
最後はgolang-setパッケージのContainsメソッドを用いる方法です。
与えられたスライスをgolang-setパッケージ内で定義されているSetインターフェースへ変換し、それをレシーバとしてContainsメソッドを呼び出します。
import (
set "github.com/deckarep/golang-set/v2"
)
func containsFunctionWithSetPkg(slice []int, key int) bool {
s := set.NewSet(slice...)
return s.Contains(key)
}
どの方法を用いるべきか
実は存在確認をしたい要素の数によって、どの方法を使うべきかが変わってきます。
存在確認をしたい要素が少ないとき
たとえばこの記事の冒頭で紹介したような状況の場合、つまり要素数が10,000個あるint型のスライスから100というただ一つの要素が含まれているかを確認したいときは方法1または方法3を使うと良いです。
実際にベンチマークテストを行ってみましょう。
次のようなベンチマークテスト用のコードを書いてみました。
package In
import (
"math/rand"
"testing"
)
// 別ファイルで
// const (
// sliceSize = 10000
// )
// と定義している
// 方法1
func Benchmark_simpleInFunction(b *testing.B) {
LargeSlice := generateLargeSlice(sliceSize)
b.ResetTimer()
for n := 0; n < b.N; n++ {
key := rand.Intn(2*sliceSize)
simpleInFunction(LargeSlice, key)
}
}
// 方法2
func Benchmark_inFunctionWithMap(b *testing.B) {
LargeSlice := generateLargeSlice(sliceSize)
b.ResetTimer()
for n := 0; n < b.N; n++ {
key := rand.Intn(2*sliceSize)
inFunctionWithMap(LargeSlice, key)
}
}
// 方法3
func Benchmark_containsFunctionWithSlicesPkg(b *testing.B) {
LargeSlice := generateLargeSlice(sliceSize)
b.ResetTimer()
for n := 0; n < b.N; n++ {
key := rand.Intn(2*sliceSize)
containsFunctionWithSlicesPkg(LargeSlice, key)
}
}
// 方法4
func Benchmark_containsFunctionWithSetPkg(b *testing.B) {
LargeSlice := generateLargeSlice(sliceSize)
b.ResetTimer()
for n := 0; n < b.N; n++ {
key := rand.Intn(2*sliceSize)
containsFunctionWithSetPkg(LargeSlice, key)
}
}
少しコードの解説をしておきます。
generateLargeSlice(n)は[0,1,2,...,n-1]というようなスライスを返します。
そしてrand.Intn(n)は0以上n未満の範囲でランダムな整数を出力してくれる関数です。
このふたつを存在確認を行う各関数に渡してrand.Int(2*sliceSize)が[0,1,2,...,sliceSize-1]に存在するかどうかを判定させています。
では早速結果を見てみましょう。
$ go test -bench . -benchtime 10s
goos: windows
goarch: amd64
pkg: practice
cpu: Intel(R) Core(TM) i7-8565U CPU @ 1.80GHz
Benchmark_simpleInFunction-8 2136710 5259 ns/op
Benchmark_inFunctionWithMap-8 7566 1425794 ns/op
Benchmark_containsFunctionWithSlicesPkg-8 2247199 4909 ns/op
Benchmark_containsFunctionWithSetPkg-8 9146 1257649 ns/op
結果はこのようになりました。
やはり方法1と方法3が早いですね。なぜこのような結果になるかは後ほど説明するのでしばしお待ちを。
存在確認をしたい要素が多いとき
次に、要素数が10,000個あるint型のスライスから、100,123,334,551……というように、存在確認したい要素数が複数ある場合を考えてみましょう。
次のように、第一引数で受け取ったスライスの中で、存在確認を第二引数で受け取った数だけ実行するrepeatXXX関数というのを、各方法ごとに準備してみました。
//方法1
func repeatSimpleInFunction(slice []int, repeat int) {
for r := 0; r < repeat; r++ {
e := rand.Intn(2*len(slice))
if simpleInFunction(slice, e) {
// sliceに要素eが存在
} else {
// sliceに要素eが存在しない
}
}
}
// 方法2
func repeatInFunctionWithMap(slice []int, repeat int) {
m := map[int]struct{}{}
for _, s := range slice {
m[s] = struct{}{}
}
for r := 0; r < repeat; r++ {
e := rand.Intn(2*len(slice))
if _, ok := m[e]; ok {
// sliceに要素eが存在
} else {
// sliceに要素eが存在しない
}
}
}
// 方法3
func repeatContainsFunctionWithSlicesPkg(slice []int, repeat int) {
for r := 0; r < repeat; r++ {
e := rand.Intn(2*len(slice))
if containsFunctionWithSlicesPkg(slice, e) {
// sliceに要素eが存在
} else {
// sliceに要素eが存在しない
}
}
}
// 方法4
func repeatContainsFunctionWithSetPkg(slice []int, repeat int) {
for r := 0; r < repeat; r++ {
e := rand.Intn(2*len(slice))
if containsFunctionWithSetPkg(slice, e) {
// sliceに要素eが存在
} else {
// sliceに要素eが存在しない
}
}
}
この各repeatXXX関数に対してベンチマークテストを行うとどうなるでしょうか。
package In
import (
"testing"
)
// 別ファイルで
// const (
// sliceSize = 10000
// repeat = 1000
// )
// と定義している
// 方法1
func Benchmark_repeatSimpleInFunction(b *testing.B) {
LargeSlice := generateLargeSlice(sliceSize)
b.ResetTimer()
for n := 0; n < b.N; n++ {
repeatSimpleInFunction(LargeSlice, repeat)
}
}
// 方法2
func Benchmark_repeatInFunctionWithMap(b *testing.B) {
LargeSlice := generateLargeSlice(sliceSize)
b.ResetTimer()
for n := 0; n < b.N; n++ {
repeatInFunctionWithMap(LargeSlice, repeat)
}
}
// 方法3
func Benchmark_repeatContainsFunctionWithSlicesPkg(b *testing.B) {
LargeSlice := generateLargeSlice(sliceSize)
b.ResetTimer()
for n := 0; n < b.N; n++ {
repeatContainsFunctionWithSlicesPkg(LargeSlice, repeat)
}
}
// 方法4
func Benchmark_repeatContainsFunctionWithSetPkg(b *testing.B) {
LargeSlice := generateLargeSlice(sliceSize)
b.ResetTimer()
for n := 0; n < b.N; n++ {
repeatContainsFunctionWithSetPkg(LargeSlice, repeat)
}
}
結果は次のようになりました。
$ go test -bench . -benchtime 10s
goos: windows
goarch: amd64
pkg: practice
cpu: Intel(R) Core(TM) i7-8565U CPU @ 1.80GHz
Benchmark_repeatSimpleInFunction-8 1552 7149816 ns/op
Benchmark_repeatInFunctionWithMap-8 6667 1882591 ns/op
Benchmark_repeatContainsFunctionWithSlicesPkg-8 1612 6706634 ns/op
Benchmark_repeatContainsFunctionWithSetPkg-8 8 1467467088 ns/op
方法2が最も早く、方法1と3が同じくらいで、方法4がダントツで遅いですね……
このような結果になる理由
各方法の(平均)計算量をみてみましょう。
以下、探索対象となるスライスの要素数を$N$、存在確認を行いたいkeyの数を$K$とします。
方法1
これは計算量$O(N)$です。というのも探している要素が全く見つからない場合、はじめから一つずつ見ていくとすると$N$回for文を回す必要があるからです。
よって、$K$個のkeyの存在確認を行いたい場合は$O(NK)$となります。
方法2
こちらは存在確認用のmapを構築するのに$O(N)$,存在確認では$O(1)$1です。つまり、一度mapを作ってしまえば存在確認は$N$の値によらず高速に行えるということです。
よって$K$個のkeyの存在確認を行いたい場合は$O(N+K)$となります。
方法3
方法1と同じく計算量$O(N)$です。
ここでネタばらしをすると、方法3がつかっているslicesパッケージのContains関数は、内部で方法1と同じ線形探索をしています。
https://cs.opensource.google/go/x/exp/+/master:slices/slices.go
こちらを見ていただくとこのContains関数はIndex関数の値が正であるかどうかで判定しています。
// Contains reports whether v is present in s.
func Contains[E comparable](s []E, v E) bool {
return Index(s, v) >= 0
}
そしてIndex関数というのはスライス内でのkeyのindexを出力するもので、存在しなかった場合は-1を返す実装になっています。まさにこれは方法1で見ていた線形探索ですね。
// Index returns the index of the first occurrence of v in s,
// or -1 if not present.
func Index[E comparable](s []E, v E) int {
for i := range s {
if v == s[i] {
return i
}
}
return -1
}
よって計算量は方法1と全く同じです。今までの計測結果で方法1と3が同じような結果を示していたのはこれが理由だったんですね。
方法4
こちらもContainsメソッドの実装を読んでみると方法2とやっていることは同じです。(内部ではmapを構築してそのkeyを使って存在確認をしています。)よって計算量は方法2と変わりません。
それならどうしてこんなに実行時間が遅いのでしょうか。
Go言語にはプロファイリングを行うコマンドがあるので、それを使ってどこがボトルネックになってるのかを調べてみましょう。
まずは比較対象となる方法2のプロファイリングをしてみます。
$ go test -bench Benchmark_repeatInFunctionWithMap -benchmem -o pprof/test.bin -cpuprofile pprof/cpu.out -benchtime 10s
goos: windows
goarch: amd64
pkg: practice
cpu: Intel(R) Core(TM) i7-8565U CPU @ 1.80GHz
Benchmark_repeatInFunctionWithMap-8 7515 1578064 ns/op 389409 B/op 255 allocs/op
PASS
ok practice 12.282s
$ go tool pprof --svg pprof/test.bin pprof/cpu.out > pprof/test.svg
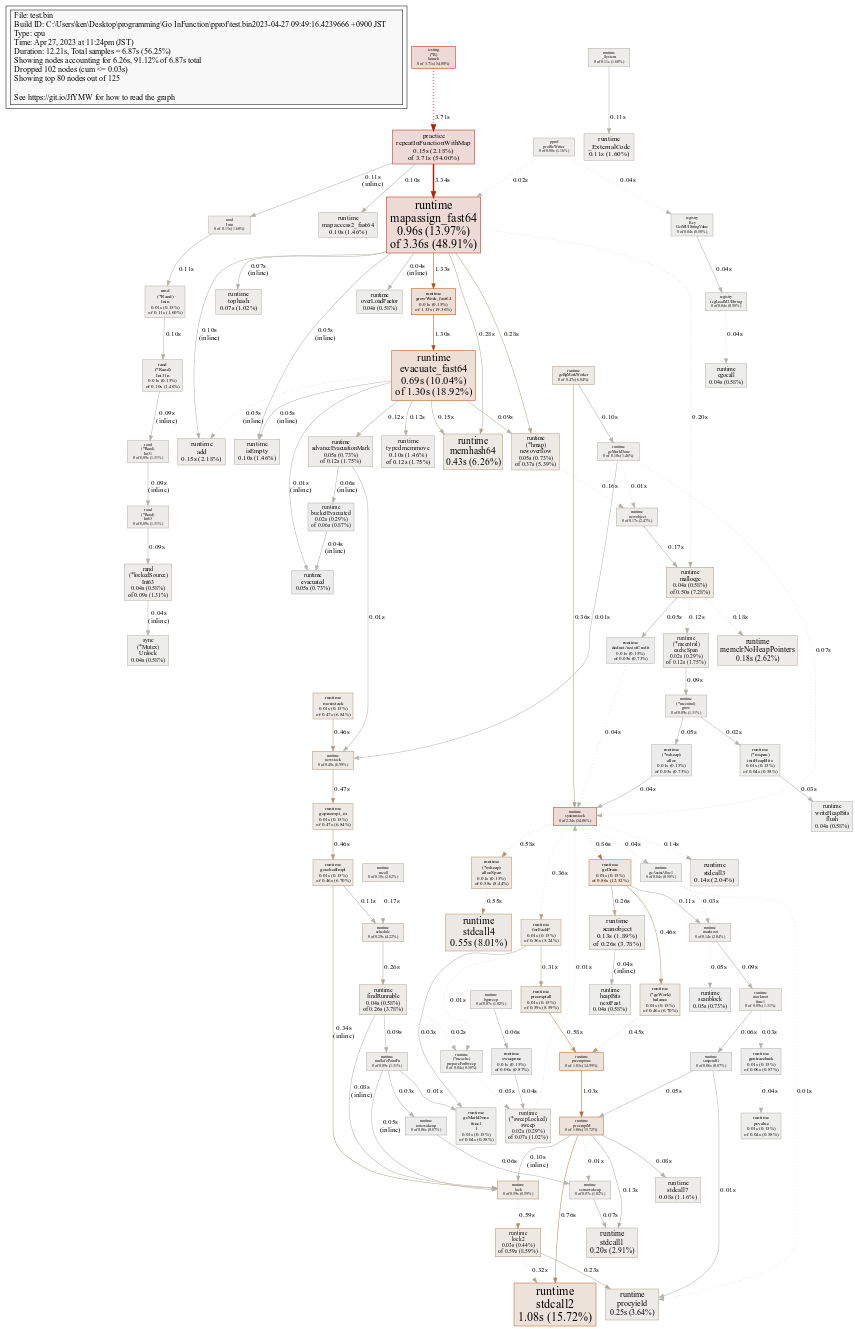
結果はこのようになりました。有向グラフの形で出力してくれるのはとても見やすくて良いですね。処理に時間がかかっていそうなところを拡大してみます。
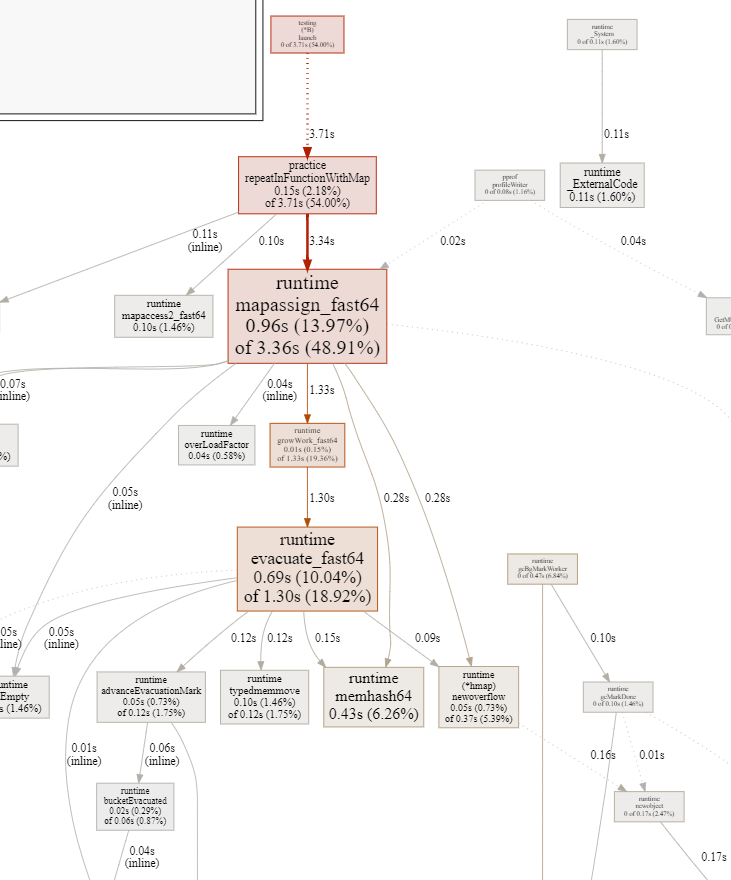
mapassign_fast64というところに時間がかかってそうですね。これはGo言語のランタイム内部で使われる関数で、64ビット整数のキーを持つマップへの要素の代入(挿入)を高速化するために用いられるものです。(多分)
続いて方法4のプロファイリング結果を見てみましょう。
$ go test -bench Benchmark_repeatContainsFunctionWithSetPkg -benchmem -o pprof/test.bin -cpuprofile pprof/cpu.out -benchtime 10s
goos: windows
goarch: amd64
pkg: practice
cpu: Intel(R) Core(TM) i7-8565U CPU @ 1.80GHz
Benchmark_repeatContainsFunctionWithSetPkg-8 18 737602700 ns/op 183050152 B/op 14320 allocs/op
PASS
ok practice 21.249s

少し見た目が違いますね。ここでも時間がかかっていそうなところを拡大してみます。

少し文字化けしてしまってますが、方法2のときにはなかったLockやUnlockがありますね。
ここから察するに、方法4が遅い理由はおそらくスレッドセーフに作っているからだと思います。2
確かに内部実装をみてみるとsetの代用として使うmapを構築する段階で頻繁にLockとUnlockによる排他制御を行っていました。
func (t *threadSafeSet[T]) Add(v T) bool {
t.Lock()
ret := t.uss.Add(v)
t.Unlock()
return ret
}
プロファイリングをしてみると思わぬ発見があって面白いですね……!3
グラフ化
スライスの要素数を10,000で固定し、存在確認したい要素数をいろいろ変えてベンチマークをとってみました。その結果をグラフにしたのが次です。(ただし方法4を含めるとグラフが見にくくなるので除いてます。)
縦軸の単位は今まで通りns/opです。4
こうやってみると方法2がいかに速いかがわかりますね……!!

最後に
mapを使うことで格段に存在確認が早くなることは知っていたのですが、実際ベンチマークをとってみると違いが顕著に見えて面白いですね!
結局まとめとしては
- 少ない回数の存在確認なら線形探索(方法1、方法3)でOK
- 何度も存在確認を繰り返すならmapを使う方法2
- スレッドセーフに行いたい場合は方法4
になるのかなあと思います。具体的にどのくらいの要素数に対してどのくらいの存在確認を行う場合に線形探索の方が優れているのかなどは別途調査する必要がありそうですね。(私はここで疲れたのでいったん筆を置きます……)
もし間違いなどありましたら、コメントにてご指摘ください。ここまで読んでいただきありがとうございました!!