これはどんな話?
私は千株式会社で保育園・幼稚園向けDXサービス「はいチーズ! シリーズ」の写真販売サービスを開発・運用をしています。
2024年、この写真販売サービスのtoC向けの機能(以下、ECサイト)を分離し、単一のサービスとしてECSへ移行しました。
この記事では主に、
- なぜ構成変更を決断したのか
- 構成変更のための技術選定
- 構成変更に際してチームでやってよかったこと
について書きます。
やったことをベースに書き出しているので、長い記事になります。
なぜ構成変更を決断したのか
決断する直前の状態
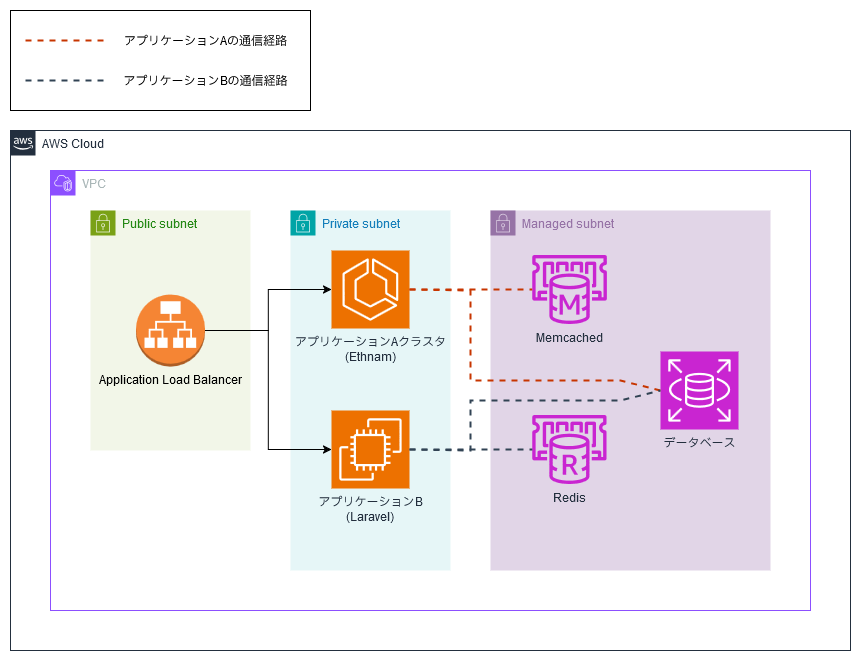
今回構成変更を決断したECサイトは、以下のような構成で動いていました(細かいリソースは省略しています)。
サービス稼動初期から同じコードベースで動き続けているアプリケーションAと、サービスの途中から増設されたアプリケーションBをALBで束ねて、ユーザからはひとつのアプリケーションとして見せかけるような構成です。
抱えていた課題
アプリケーション面
まず構成図から察することができますが、アプリケーションA,Bは非常に密な設計になっており、なにかの機能を追加したり修正したりするときは両方に手を加えることが多いのですがアプリケーションAはethnam、アプリケーションBはLaravelと別々のフレームワークで書かれており、開発者の認知的負荷が異様に高い状態です。
また、アプリケーションA, BにはECサイトだけでなく、社内向けの管理画面や利用団体に提供するtoB向け画面の機能も相乗りしており、かつそれぞれが密になってしまっています。そのため、ECサイトの改修をしたら社内管理画面が壊れてしまった……というような事故が時たま発生していました。
インフラ面
アプリケーション面だけでなく、インフラ面でもいくつか課題を抱えていました。
特に問題視されていたのが以下の3点です。
- アプリケーションBはEC2で稼動しているが、過去インスタンス内に状態を持っていた歴史的事情からオートスケールが設定できていなかった
- アプリケーションBを構築する方法が古くなっており、0からインスタンスを再構築することができなくなっていた
- アプリケーションAをFARGATE 1.4.0で起動することができなかった
どれも今後のサービス継続性が怪しくなる課題で、放置しているといずれサービスを停止せざるをえない状況に追い込まれることは明白でした。
また、オートスケールが設定されていないことで、負荷を予測し事前にスケールする、というオペレーションが発生してしまい、運用負荷が上がっていました。
まとめ
ここまでの課題をざっくりまとめると、以下のようになります。
- ECサイト向け機能とそれ以外の機能が密すぎて、ECサイトの改修でそれ以外の機能を破壊したり、その逆が起きたりしていた
- アプリケーションBではオートスケールが使えず、負荷傾向を読んで事前にメンテナンス・スケールする職人技が求められていた
- アプリケーションBのインスタンスを再構築できなくなっていた
EOLがやってくる
これらの課題は認知しつつも、なんとか運用できていることや、優先すべき機能改修が多々ある状態が続いており、上記の状態は長い間継続していました。
そんな中、CentOS 7のEOLの存在に気づきます。
EOLはサービス構成を見直すいいタイミングです。ここを逃がすとしばらくチャンスはないだろうと思い、EOL対応と、それに合わせた課題解消の検討を開始しました。
構成変更のための技術選定
変更をしてどうなりたいのかを考える
課題を改めて確認すると、ECサイトの開発チームだけではサービスがメンテナンスできる状態ではない、ということが根本の課題として存在することがわかります。
より具体的にすると、
- ECサイトの機能開発をするのに、toB向けチームとも調整・確認をしなければいけない
- ECサイトの構成変更をするのに、インフラチームに相談・依頼をしなければいけない
- 自分たちの動かしているサービスがどういう構成なのかを開発メンバー全員が把握できていない
といったような状態です。
もちろん、チーム間連携は大事なのですが、なにをするにも他のチームと連携しなければ難しい、という状況も健全ではありません。
実情としても、リリース確認のためのミーティングが増えたり、リリース順番の調整を行ったりと、各チームそれぞれが自分たちの都合だけではリリースを完結できないために速度を落とさざるをえない状況がありました。
裏返すと、ECサイト開発チーム自身でサービスをメンテナンスできるようにサービスそのものの構成を変更すると、これらは解決できそうです。
少し抽象的なので、当時社内向け資料では ECサイト開発チームでECサイトの設計-開発-監視-運用のサイクルを速く回せる構成にする としました。
この課題を解消できるのであれば、構成変更という破壊的な行為はコストとしてちょうどいいのではないでしょうか。
どうすれば自分たちでメンテナンスできるようになるのかを考える
現状ECサイト開発チームだけでECサイトのメンテナンスができていない原因に対して、どうすればいいでしょうか。
- ECサイトの機能開発をするのに、toB向けチームとも調整・確認をしなければいけない
- ECサイトの構成変更をするのに、インフラチームに相談・依頼をしなければいけない
- 自分たちの動かしているサービスがどういう構成なのかを開発メンバー全員が把握できていない
これらに対して、実現可能性を無視した上で考えると、それぞれ以下のような形の回答が出ました。
- コードベースを分割する
- ガードレールを設けたうえで、開発チームにインフラ操作の権限を移譲する
- 自分たちが把握できる形に再構成する(目的に対してトートロジー的ですが)
これらをそのまま実装しようとすると、かなりハードコアな印象です。
1は適切なドメイン分割を行なったうえでサービスに切り分けるの? と思われてしまうでしょうし、2もガードレールに求める期待値を揃えて実装するのは短期間では難しそうです。
あくまでも今回の目標は数ヶ月先に迫ったEOL対応なので、最終的なあるべきから現実的なラインまで引き下げます。
- 既存のコードのままで、実行環境とデプロイフロー、管理するリポジトリを他の業務ドメインと分離する
- リソースをIaCで管理する。IaCの差分検知と反映は自動化し、実行前に必ずコードレビューを通すことで最低限のガードレールとする。各メンバー自身にはadminを渡さない
- 可能な限りECSを使った構成に寄せることで、必要な前提知識をローカル環境+α程度まで下げる
やればなんとかできそうな内容ですね。
それぞれのゴールの実現手法を考える
コード・デプロイの分離
単純なコード・デプロイの分離はリポジトリを新しく作成し、そこに旧リポジトリの内容をコピペするだけでよさそうです。
問題は、移行作業中のコードの同期で、構成変更の開始からリリースまでは数ヶ月単位でかかることが見込まれます。
その間も機能改修や新機能のリリースは起きるわけなので、旧リポジトリの差分を新リポジトリに持ち込む必要があります。
日々手動で心をこめてコピペしてもよかったのですが、今回はGitHub Actionsを使い、旧リポジトリのリリースが発生したら、新リポジトリにコードを同期するような仕組みを作成することにします。
IaCと最低限のガードレール
結論から書くと、今回はリソースをTerraformで管理する方法を取ります。
採用理由は以下の5点です。
- ステート管理が強力で、意図しない差分の検知をしやすい
- モジュール機能が強力で、コードの見通しがいい
- 設計次第だが、単一のコードで複数の環境を構築できる
- IaC管理外の既存リソースの参照がしやすい
- HCP Terraformを導入すれば、リリースを承認制にできる
ガードレールを厳密に運用することは現段階では難しいと判断したため、自分や他のAWSに詳しいメンバーがチームの人間ガードレールになる必要があります。
コードレビューのしやすさと、実行するとどうなるかが確認しやすい点で、Terraformがベストだと考えました。
また、HCP Terraformと連携したり、GitHub Actions上で実行環境を構築することで、メンバーの手元にはadmin権限を渡さなくてもよい、という点も重要でした。
ガードレール以前の話で、権限を管理する側の責任として、やってほしくないふるまいはお互いのためにそもそもできないようにしておく必要があるからです。
ECSに寄せる構成変更
いま動いているインスタンスやそのスナップショットに対して変更を継ぎ足していく、という運用を続けていたため、現状のEC2を再現できない、という大きな課題が生まれてしまっていました。
もちろん、手順書やAnsibleは存在していて、そこを見れば必要なリソースは把握できるのですが、参照しているパッケージのバージョンが古すぎてAMIを変更したら動かなかったり、そもそも参照しているパッケージが消えていたり、という状況です。
そのため、大前提として、なにをするにもまずはアプリの実行環境を綺麗に再構築する必要があります。
ここで、綺麗に作ればオートスケールも組めるので改めてEC2で構築しなおす、というのも選択肢としてはもちろんありました。
しかし、コンテナベースの技術選定をしたほうが、
- ローカル開発環境(Docker)の延長線上に実環境を置ける
- Ansible, Chefなどの構成管理ツールを運用しなくてもいい
- いざというときにコンテナイメージごと塩漬けできる
などのメリットがあると考えたため、ECS on Fargateをいったん仮採用とし、アプリケーションで実は状態を持ってしまっていたことが発覚するなど、なんらかの事情でECSが難しくなったときにDockerfileからAnsibleを起こす方向としました。
また、ここまではインフラの都合でしたが、アプリケーション開発の視点としても、アプリケーションA, Bで実行環境が異なることでトラブル時に確認する項目が多かったり、ログの出力先に違いがあってスイッチングコストがかかったりという課題がありました。
アプリケーションA, BをどちらもECSにまとめることで、監視やトラブル調査の負担が少なくなりそうなこともあり、やはりECSの採用に傾いていきました。
実際にリリースしたもの
ここまでの技術選定を踏まえて、実際にリリースしたものは以下のような構成になりました。

| 採用するもの | 目的 | 置き換え元 |
|---|---|---|
| ECS on Fargate | コンテナベースでのアプリケーション実行 | EC2 |
| Terraform | リソース変更の差分確認とレビューを簡単に行う | なし |
| HCP Terraform | リソース変更のガードレール設置 | なし |
| GitHub Actions | アプリケーションのデプロイ・旧リポジトリからのコード同期を行う | 一部CodePipeline |
また、上記のECサイト環境に加えて、ECサイトの監視・計測のためのツールも新規で構築されました。
具体形には、Grafana + Loki + TempoがECサイトクラスタとは別に構築されたほか、アプリケーションA, BのサイドカーコンテナとしてFluentd, OpenTelemetry Collectorが追加されています。
そのあたりはアプリケーションにオブザーバビリティを導入した話として書かれています。合わせてどうぞ。
さて、この構成変更によって、当初の課題は解決したのでしょうか?
- ECサイト向け機能とそれ以外の機能が密すぎて、ECサイトの改修でそれ以外の機能を破壊したり、その逆が起きたりしていた
- コードベースの分離が完了したため、起こりにくい状況にはなった
- リリースタイミングもECサイト、toB側ともに自分のタイミングで選べるようになった
- ただし、マイグレーションだけは分離しきれておらず、旧リポジトリに取り残されているため、DB変更だけはいまだ調整が必要な状態
- アプリケーションBではオートスケールが使えず、負荷傾向を読んで事前にメンテナンス・スケールする職人技が求められていた
- アプリケーションA, Bの両方にオートスケールが導入されたことで、手作業は不要になった
- オブザーバビリティ計測の導入によって、平常時から負荷の高いところを洗い出せるようになり、トラブルが起きる前に重い処理を見つけて直す、ということもできるようになった
- アプリケーションBのインスタンスを再構築できなくなっていた
- コンテナ化することで、再構築できない問題から解放された
- アプリケーションAもコンテナイメージを一般的な構成に作り直して、メンテナンス性が上がった
EOL対応のついでで得られたものとしては、非常に大きいのではないでしょうか。
また、当初致命的な課題だと感じていなかったが、治ってわかった細々としていたがつらかった課題、というのもありました。
- ローカル開発環境の構築が短縮された(1~2日→1時間程度)
- デプロイ速度が短縮された(40分程度→10分程度)
- スポットインスタンスの導入でコスト削減
- ECS Execができるようになったことで、トラブル時の調査しやすさが改善
- arm/Apple Silicon機でもローカルのコンテナイメージがビルドできるようになった
- etc……
これらが解決し、チームメンバーの開発者体験が改善したこともよかったな、と思います。
構成変更に際してチームでやってよかったこと
本当はプロジェクトの頭からリリースまでのすべてを書きたかったのですが、書ききれないので構成変更に際してチームで取り組んでよかったことをいくつか紹介します。
チームでサービスをメンテナンスできるようになる、ということを目的に実施した活動が特に効果が大きかったように思います。
Terraformを触ってもらう場をつくる
いきなりメインサービスでチャレンジしてみてね、では触れるものも触れないので、
- サブサービスのTerraform化をチームでモブプロ
- Terraformのハンズオン
などを実施して、Terraform(IaC)のうれしいところつらいところ、手作業のうれしいところつらいところを体験してもらいました。
結果として、メンバーにTerraform導入の意義を理解してもらい、Terraformを書いてサービスの設定を見直したり、必要に応じて自分で検証環境を立ち上げたりといった活用も行えるようになりました。
デプロイの仕組みを棚卸しする
今回サービスをECSに移行するに際してどんなフローでサービスがリリースされるのかを棚卸ししました。
GitHub Actionsはどういう意図でmatrixを組まれているのか、どこでキャッシュされているのか、ecspressoはどんなことをしているのか、このステップではAWS側に何が起きているのか、などなど、ことあるごとにチームにActionsの中身を解説しました。
結果として、デプロイ失敗時の対応を誰でもできるようになったり、チームメンバーの誰もがデプロイフローを改善するようになったり、と、全員でGitHub Actionsのメンテナンスが行われるようになりました。
〆
今回はEOLのタイミングで、開発チーム自身で運用できる構成に変更しました。
変更してからの期間はまだまだ短く、今後これに起因するトラブルが発生するかもしれませんが、今のところはメリットを多く享受しています。
EOLのタイミングはただのバージョンアップのタイミングではなく、よりよいサービス構成を検討するいいタイミングだと思います。
なるべくギリギリのタイミングで迎えたくないものですが、ギリギリで迎えてしまったときも今回のようにせめて楽しんでチーム状況に合わせた対応ができるといいですね。
それではよいお年を。