この記事はTokyo City University Advent Calendar 2019,22日目の記事となります.
https://adventar.org/calendars/4282
はじめに
カニ@_BBPIと申します.
都市大四年目にして初めてこのようなアドベントカレンダーに参加出来て嬉しい限りです.
卒論がまだ全く書けてないので助けてください.
4年間の昼飯の話をします
ピーナッツブロックチョコ
#カニランチ3rdSeason _BBPI - Twitter検索
異常です.
カップ焼きそば最高~~~~~~~~~~~~~~~~~~~~~~~!!!!!!!!!!
#KaniLunchとかいうオーストラリア留学中(TAP)に5袋1AUDのインスタントラーメンを食べ続けたこの世の終わりみたいなハッシュタグがありますが恥ずかしいので見なくてよいです.
また4年間大学の食堂の給茶機でカップ焼きそばのお湯を入れ続けた知見として,一番奥の機械が一番お湯の出が良かったというのがあります.
大学水没の一件で変わってしまった可能性があるのですが・・・
本題
アドベントカレンダーのネタについて,昼食(カニランチ)を技術的な話と絡めて書けないかなと考えていたときに,今研究で機械学習についてやってるしそれでいいのでは?ってことでこうなりました.
今からディープラーニングそのもの(アルゴリズムやら高速化やら)の研究をするのは割と修羅の道です,相手がGoogleや謎の半導体メーカーになります.
やるならこんな問題をディープラーニングで解決しました!みたいなテーマのほうがやりやすいと思います.(後輩へのアドバイス)
学習データの用意
はじめに学習データとして必要な画像を集めます
#カニランチ3rdseasonのハッシュタグでそこそこ集まるかなと思っていたら全然足りなかったのでTwitterで"ごつ盛り 塩 pic"みたいに検索して一種類あたり50枚ほどかき集めました
今回はごつ盛り塩,ごつ盛りソース,ぶぶか油そば,一平ちゃん,UFOの5種類を判別します
UFOの画像収集中に輝夜月の画像やたら見たけどなんだったんだろ・・・
下準備
実行環境にはGoogle Colaboratoryを使います
Googleアカウントさえあれば無料でGPUがブン回せるすごいやつです
ブラウザから機械学習などを行うプログラムを実行することができます
Colaboratory へようこそ - Colaboratory
https://colab.research.google.com/notebooks/welcome.ipynb
コードの全容はここにあるので,このHantei.ipynbをダウンロードするなりコピペしていくと本記事と同じことができます
https://github.com/bluekani/yakusoba-classification/blob/master/Hantei.ipynb
Colabを開いたらまずはじめにGoogleDriveのファイルにアクセスできるようにします
↓このへんの[ ]もしくは▶ボタンを押すとその枠内のコードが実行されます
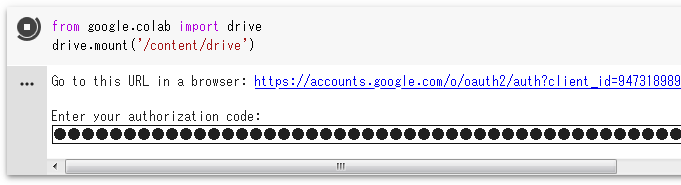
出てきたURLをクリックして認証コードをコピペします
Mounted at /content/drive と出れば接続完了です
GoogleDriveにアクセスし,フォルダを作って画像を入れます
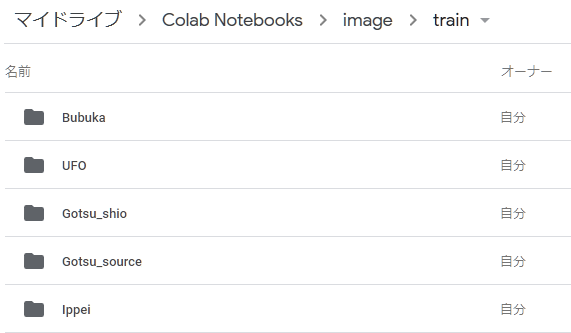

trainフォルダには学習用として各種50枚,testフォルダには5~10枚ほど画像を入れます
学習
それでは学習をやっていきます
# モデルを生成してニューラルネットを構築
model = Sequential()
model.add(Conv2D(32,(3,3), padding = "same", input_shape =(input_size, input_size, 3)))
model.add(BatchNormalization())
model.add(Activation("relu"))
model.add(Conv2D(32,(3,3), padding = "same"))
model.add(BatchNormalization())
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(.25))
model.add(Conv2D(64,(3,3), padding = "same"))
model.add(BatchNormalization())
model.add(Activation("relu"))
model.add(Conv2D(64,(3,3), padding = "same"))
model.add(BatchNormalization())
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(.25))
model.add(Conv2D(128,(3,3), padding = "same"))
model.add(BatchNormalization())
model.add(Activation("relu"))
model.add(Conv2D(128,(3,3), padding = "same"))
model.add(BatchNormalization())
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(.4))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation("relu"))
model.add(Dropout(.50))
model.add(Dense(5))
model.add(Activation("softmax"))
opt = SGD(lr=1e-3, decay=1e-6, momentum=0.9, nesterov=True)
# モデルのコンパイル
model.compile(loss="categorical_crossentropy", optimizer=opt, metrics=["accuracy"])
model.summary()
# 学習を実行,10%はテストに使用
model.fit(image_list, Y, epochs=20, batch_size=100, validation_split=0.1, shuffle = True)
今回構築したモデルは6層の畳み込みを行う浅めのネットワークです
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 64, 64, 32) 896
_________________________________________________________________
batch_normalization_1 (Batch (None, 64, 64, 32) 128
_________________________________________________________________
activation_1 (Activation) (None, 64, 64, 32) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 64, 64, 32) 9248
_________________________________________________________________
batch_normalization_2 (Batch (None, 64, 64, 32) 128
_________________________________________________________________
activation_2 (Activation) (None, 64, 64, 32) 0
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 32, 32, 32) 0
_________________________________________________________________
dropout_1 (Dropout) (None, 32, 32, 32) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 32, 32, 64) 18496
_________________________________________________________________
batch_normalization_3 (Batch (None, 32, 32, 64) 256
_________________________________________________________________
activation_3 (Activation) (None, 32, 32, 64) 0
_________________________________________________________________
conv2d_4 (Conv2D) (None, 32, 32, 64) 36928
_________________________________________________________________
batch_normalization_4 (Batch (None, 32, 32, 64) 256
_________________________________________________________________
activation_4 (Activation) (None, 32, 32, 64) 0
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 16, 16, 64) 0
_________________________________________________________________
dropout_2 (Dropout) (None, 16, 16, 64) 0
_________________________________________________________________
conv2d_5 (Conv2D) (None, 16, 16, 128) 73856
_________________________________________________________________
batch_normalization_5 (Batch (None, 16, 16, 128) 512
_________________________________________________________________
activation_5 (Activation) (None, 16, 16, 128) 0
_________________________________________________________________
conv2d_6 (Conv2D) (None, 16, 16, 128) 147584
_________________________________________________________________
batch_normalization_6 (Batch (None, 16, 16, 128) 512
_________________________________________________________________
activation_6 (Activation) (None, 16, 16, 128) 0
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 8, 8, 128) 0
_________________________________________________________________
dropout_3 (Dropout) (None, 8, 8, 128) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 8192) 0
_________________________________________________________________
dense_1 (Dense) (None, 512) 4194816
_________________________________________________________________
activation_7 (Activation) (None, 512) 0
_________________________________________________________________
dropout_4 (Dropout) (None, 512) 0
_________________________________________________________________
dense_2 (Dense) (None, 5) 2565
_________________________________________________________________
activation_8 (Activation) (None, 5) 0
=================================================================
Total params: 4,486,181
Trainable params: 4,485,285
Non-trainable params: 896
学習結果
Epoch 1/20
225/225 [==============================] - 10s 44ms/step - loss: 3.8390 - acc: 0.1867 - val_loss: 1.9019 - val_acc: 0.0000e+00
Epoch 2/20
225/225 [==============================] - 8s 37ms/step - loss: 2.6603 - acc: 0.2756 - val_loss: 2.2221 - val_acc: 0.0800
Epoch 3/20
225/225 [==============================] - 8s 37ms/step - loss: 2.3123 - acc: 0.3156 - val_loss: 2.4967 - val_acc: 0.0000e+00
Epoch 4/20
225/225 [==============================] - 8s 37ms/step - loss: 1.8484 - acc: 0.4267 - val_loss: 1.4778 - val_acc: 0.3200
Epoch 5/20
225/225 [==============================] - 8s 38ms/step - loss: 1.3170 - acc: 0.5289 - val_loss: 1.2526 - val_acc: 0.6400
Epoch 6/20
225/225 [==============================] - 8s 37ms/step - loss: 1.0123 - acc: 0.6311 - val_loss: 0.8774 - val_acc: 0.7200
Epoch 7/20
225/225 [==============================] - 8s 37ms/step - loss: 0.7975 - acc: 0.6889 - val_loss: 0.7064 - val_acc: 0.7600
Epoch 8/20
225/225 [==============================] - 8s 38ms/step - loss: 0.6445 - acc: 0.7556 - val_loss: 0.4325 - val_acc: 0.8400
Epoch 9/20
225/225 [==============================] - 8s 38ms/step - loss: 0.5464 - acc: 0.8044 - val_loss: 0.3630 - val_acc: 0.8400
Epoch 10/20
225/225 [==============================] - 9s 38ms/step - loss: 0.4339 - acc: 0.8444 - val_loss: 0.3565 - val_acc: 0.8400
Epoch 11/20
225/225 [==============================] - 9s 38ms/step - loss: 0.4272 - acc: 0.8444 - val_loss: 0.3397 - val_acc: 0.8800
Epoch 12/20
225/225 [==============================] - 8s 38ms/step - loss: 0.2925 - acc: 0.8756 - val_loss: 0.2931 - val_acc: 0.8800
Epoch 13/20
225/225 [==============================] - 9s 38ms/step - loss: 0.2147 - acc: 0.9289 - val_loss: 0.2903 - val_acc: 0.8400
Epoch 14/20
225/225 [==============================] - 9s 38ms/step - loss: 0.2260 - acc: 0.9244 - val_loss: 0.3240 - val_acc: 0.8400
Epoch 15/20
225/225 [==============================] - 8s 38ms/step - loss: 0.2332 - acc: 0.9244 - val_loss: 0.3161 - val_acc: 0.8400
Epoch 16/20
225/225 [==============================] - 9s 38ms/step - loss: 0.1769 - acc: 0.9333 - val_loss: 0.2997 - val_acc: 0.8400
Epoch 17/20
225/225 [==============================] - 9s 38ms/step - loss: 0.1499 - acc: 0.9600 - val_loss: 0.2706 - val_acc: 0.8800
Epoch 18/20
225/225 [==============================] - 9s 38ms/step - loss: 0.1500 - acc: 0.9556 - val_loss: 0.2780 - val_acc: 0.8800
Epoch 19/20
225/225 [==============================] - 8s 38ms/step - loss: 0.1558 - acc: 0.9467 - val_loss: 0.3100 - val_acc: 0.8800
Epoch 20/20
225/225 [==============================] - 8s 38ms/step - loss: 0.1349 - acc: 0.9511 - val_loss: 0.3689 - val_acc: 0.8400
20サイクル学習しましたがval_acc(正解率)が9割に届かずに頭打ちになっています
またval_loss(正解にどれくらい近いか,0に近いほうがよい)が終盤でまた増えていることから過学習を起こしている可能性も考えられます
推論
testフォルダに入れた未知の画像を使って推論を行います
total = 0.
correct = 0.
for dir in os.listdir("drive/My Drive/Colab Notebooks/image/test"):
dir1 = "drive/My Drive/Colab Notebooks/image/test/" + dir
label = 0
if dir == "Gotsu_shio":
label = 0
elif dir == "Gotsu_source":
label = 1
elif dir == "Bubuka":
label = 2
elif dir == "Ippei":
label = 3
elif dir == "UFO":
label = 4
for file in os.listdir(dir1):
label_list.append(label)
filepath = dir1 + "/" + file
print(filepath)
img = []
img.append(img_to_array(load_img(filepath, target_size=(input_size,input_size))))
result = model.predict_classes(np.array(img))
print("label:", label, "result:", result[0])
total += 1.
if label == result[0]:
correct += 1.
print("正解率: ", correct / total * 100, "%")
model.save("drive/My Drive/Colab Notebooks/model.h5f", overwrite=True)
正解率: 62.06896551724138 %
微妙な結果となりました,このままでは実用性に乏しいのでさらに精度をあげたいと思います
入力画像の水増し
50枚x5種類の250枚では学習が不十分なことがわかりました.
そこでData Augmentation(画像の水増し)という手法を用います.
import numpy as np
from keras.preprocessing.image import ImageDataGenerator,img_to_array, array_to_img
# 出力先ディレクトリの設定
input_dir = 'drive/My Drive/Colab Notebooks/image/train/UFO' #適宜変える
output_dir = input_dir + '_ex'
if not(os.path.exists(output_dir)):
os.mkdir(output_dir)
# 1つの画像から何枚増やすか
output_num = 10
# 生成をする関数
def draw_images(generator, x, dir_name, index):
save_name = 'extened-' + str(index)
g = generator.flow(x, batch_size=1, save_to_dir=output_dir, save_prefix=save_name, save_format='jpg')
for i in range(1):
bach = g.next()
num = 0
for file in os.listdir(input_dir) :
datagen = ImageDataGenerator(rotation_range=20,width_shift_range=20,height_shift_range=20,zoom_range=0.1)
file_path = input_dir + "/" + file
img = load_img(file_path)
img = img.resize((150, 150))
x = img_to_array(img)
x = np.expand_dims(x, axis=0)
draw_images(datagen, x, output_dir, num)
num = num + 1
datagen = ImageDataGenerator(rotation_range=20,width_shift_range=20,height_shift_range=20,zoom_range=0.1)
とあるように,今回は回転率20%,上下,左右の移動を20%,拡大範囲を10%に設定しました.

1枚の画像からこのような画像が生成されます.
別のフォルダに画像が保存されるので,画像を元のフォルダに移したりフォルダ名を書き換えたりコードを一部書き換えて対応します.
また画像の読み込みをし,イチから学習を行います.
色々実験していたら混ざってしまったのか入力画像の枚数が3500枚弱になりましたが気にしないことにします.画像は多いほうが嬉しいので.
入力データを増やした実行結果
Train on 3122 samples, validate on 347 samples
Epoch 1/20
3122/3122 [==============================] - 118s 38ms/step - loss: 1.5882 - acc: 0.4942 - val_loss: 0.4034 - val_acc: 0.8415
Epoch 2/20
3122/3122 [==============================] - 117s 37ms/step - loss: 0.4380 - acc: 0.8504 - val_loss: 0.4307 - val_acc: 0.8617
Epoch 3/20
3122/3122 [==============================] - 116s 37ms/step - loss: 0.2218 - acc: 0.9234 - val_loss: 0.1131 - val_acc: 0.9568
Epoch 4/20
3122/3122 [==============================] - 116s 37ms/step - loss: 0.1563 - acc: 0.9484 - val_loss: 0.1913 - val_acc: 0.9251
Epoch 5/20
3122/3122 [==============================] - 116s 37ms/step - loss: 0.1156 - acc: 0.9628 - val_loss: 0.0431 - val_acc: 0.9827
Epoch 6/20
3122/3122 [==============================] - 117s 37ms/step - loss: 0.0893 - acc: 0.9702 - val_loss: 0.0561 - val_acc: 0.9827
Epoch 7/20
3122/3122 [==============================] - 117s 37ms/step - loss: 0.0646 - acc: 0.9795 - val_loss: 0.0258 - val_acc: 0.9942
Epoch 8/20
3122/3122 [==============================] - 117s 37ms/step - loss: 0.0592 - acc: 0.9805 - val_loss: 0.0277 - val_acc: 0.9914
Epoch 9/20
3122/3122 [==============================] - 116s 37ms/step - loss: 0.0514 - acc: 0.9833 - val_loss: 0.0199 - val_acc: 0.9942
Epoch 10/20
3122/3122 [==============================] - 117s 37ms/step - loss: 0.0472 - acc: 0.9862 - val_loss: 0.0178 - val_acc: 0.9942
Epoch 11/20
3122/3122 [==============================] - 116s 37ms/step - loss: 0.0497 - acc: 0.9840 - val_loss: 0.0225 - val_acc: 0.9942
Epoch 12/20
3122/3122 [==============================] - 116s 37ms/step - loss: 0.0452 - acc: 0.9849 - val_loss: 0.0267 - val_acc: 0.9914
Epoch 13/20
3122/3122 [==============================] - 117s 37ms/step - loss: 0.0317 - acc: 0.9917 - val_loss: 0.0185 - val_acc: 0.9942
Epoch 14/20
3122/3122 [==============================] - 116s 37ms/step - loss: 0.0312 - acc: 0.9914 - val_loss: 0.0183 - val_acc: 0.9914
Epoch 15/20
3122/3122 [==============================] - 115s 37ms/step - loss: 0.0246 - acc: 0.9917 - val_loss: 0.0104 - val_acc: 0.9942
Epoch 16/20
3122/3122 [==============================] - 116s 37ms/step - loss: 0.0267 - acc: 0.9936 - val_loss: 0.0160 - val_acc: 0.9942
Epoch 17/20
3122/3122 [==============================] - 116s 37ms/step - loss: 0.0212 - acc: 0.9952 - val_loss: 0.0153 - val_acc: 0.9942
Epoch 18/20
3122/3122 [==============================] - 116s 37ms/step - loss: 0.0271 - acc: 0.9907 - val_loss: 0.0129 - val_acc: 0.9942
Epoch 19/20
3122/3122 [==============================] - 116s 37ms/step - loss: 0.0225 - acc: 0.9946 - val_loss: 0.0192 - val_acc: 0.9942
Epoch 20/20
3122/3122 [==============================] - 115s 37ms/step - loss: 0.0239 - acc: 0.9923 - val_loss: 0.0212 - val_acc: 0.9942
再びtestフォルダ内の画像で推論を実行します
正解率: 96.55172413793103 %
といい感じの結果となりました
そこそこの結果を出せたので満足です,今回は比較的単純な物体かつ各種の変化が大きい(色,文字etc...)ものの判別だったので上手く行きましたが,人間から見ても違いが分かりづらいものなどを分類しようとすると難易度が上がると思います.
おみやげ
ここまでに使ったコードはフォルダ名を変えれば他の画像分類がすぐできるので,興味があればぜひやってみてください.
更に精度を上げるためにはネットワークの構造を変えたりオプティマイザの値を色々変えたりするのですが,この先は深淵なので頑張ってください.
下記に訓練済みモデルとGoogleColabで動くコードを置いておきます
カップ焼きそばの判定をしたい方はどうぞ
https://github.com/bluekani/yakusoba-classification/blob/master/Omiyage.ipynb
こんな感じです

Androidアプリに組み込む(失敗編)
https://github.com/tensorflow/examples/tree/master/lite/examples/image_classification/android
ここのチュートリアルが詳しいです
TensorflowLite用にモデルを変換します
import tensorflow as tf
converter = tf.lite.TFLiteConverter.from_keras_model_file("model.h5f")
tflite_model = converter.convert()
open("model.tflite", "wb").write(tflite_model)
もしくはTensorflowが入ったPCでコマンドラインから
tflite_convert --output_file=model.tflite --keras_model_file=model.h5f
この記事のやり方でAndroidのプロジェクトを編集します
https://tane-no-blog.com/417/
変換済みモデルを突っ込んでAndroidStudioでビルド&実行!
あれ?
全然出力結果がダメダメです
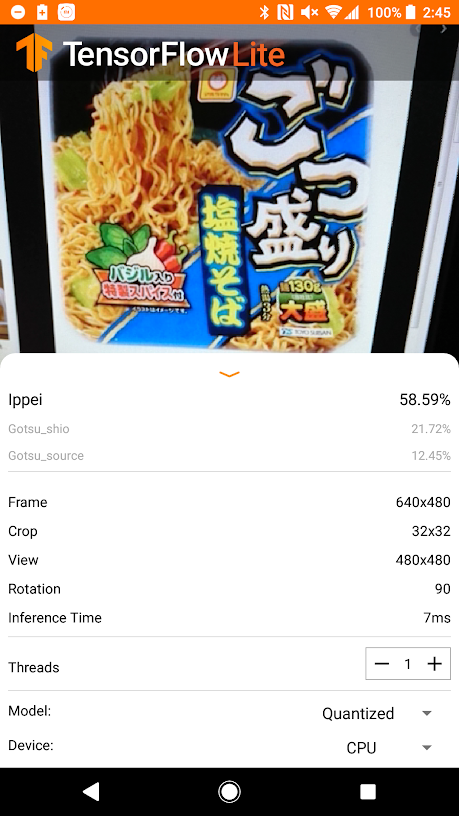
おかしいと思いまずは変換済みモデルが正しく動くか確認
PythonでTensorflowLiteを実行
https://www.tensorflow.org/lite/guide/inference
import numpy as np
import tensorflow as tf
from PIL import Image
# input_data = np.zeros((1,64,64,3), dtype=np.float32)
input_data = []
image = Image.open("Test_IMG.jpg")
image = image.resize((64, 64))
img = np.array(image, dtype=np.float32)
input_data.append(img)
print(input_data.shape)
# Load TFLite model and allocate tensors.
interpreter = tf.lite.Interpreter("model.tflite")
interpreter.allocate_tensors()
# Get input and output tensors.
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
# Test model on random input data.
input_shape = input_details[0]['shape']
interpreter.set_tensor(input_details[0]['index'], input_data)
interpreter.invoke()
output_data = interpreter.get_tensor(output_details[0]['index'])
print("Gotsu_shio, Gotsu_source, Bubuka, Ippei, UFO")
print(output_data)

Gotsu_shio, Gotsu_source, Bubuka, Ippei, UFO
[[6.0000294e-01 3.9834428e-01 8.8274525e-04 7.6191511e-04 8.0608534e-06]]
そこそこの結果が出ている
試しに入力にすべてゼロの配列を渡してみる
Gotsu_shio, Gotsu_source, Bubuka, Ippei, UFO
[[0.20664915 0.13758983 0.06034803 0.58013 0.01528302]]
アプリとだいたい同じ結果が出力された
ということはカメラの画像が正しく渡されていない・・・?
Android開発をまともにやったことない自分はここでお手上げです
誰か詳しい方が居たら教えてください...
おわり
以上です.もっと詳しく書きたかったけど力尽きました.
明日は廣木亮哉さんの記事となります.よろしくお願いいたします.