polars最高ですよね1。職場でも大いに布教しているのですが、polarsを使い始めた際に引っ掛かるポイントとして、pandasの代入の操作に相当する処理が分からないというものがあるようです。polarsで特定の要素を変更するやり方についてまとめてみました。
以下の記事で説明されているような、pandasの loc を用いた代入や mask / where に相当するpolarsの処理を紹介していきます。
- Pandas DataFrameへの置換操作のまとめ - Qiita
- [Python] pandas 条件抽出した行の特定の列に、一括で値を設定する|こはた
- 【Pandas】条件に一致する行にのみ処理を実行する -loc, mask(), where()
- Python初心者向け:条件に応じて代入する値を変える方法を解説 | happy analysis
- pandasで条件分岐(case when的な)によるデータ加工を網羅したい - Qiita
準備
palmerpenguinsのデータセットを使います。
import polars as pl
# 出力を短めに設定
pl.Config.set_tbl_rows(4)
# データの読み込み
df = pl.read_csv('https://raw.githubusercontent.com/mcnakhaee/palmerpenguins/master/palmerpenguins/data/penguins.csv', null_values='NA')
なお、polarsのバージョンは0.17.3で確認しています。
1. いつでも使える方法
pl.when を使うと実現できます。これは複雑な条件でも全て対応できる書き方です。
df.with_columns(
pl.when(pl.col('body_mass_g') < 3800).then('small').otherwise(pl.col('body_mass_g'))
)
書いている内容としては、body_mass_g 列が3800未満だった場合は "small"、それ以外は body_mass_g 列のままにする、という処理です。今回は True の時の値として単なる文字列を渡していますが、ここに pl.Series や pl.Expr を記述することも可能です。
▼ 結果
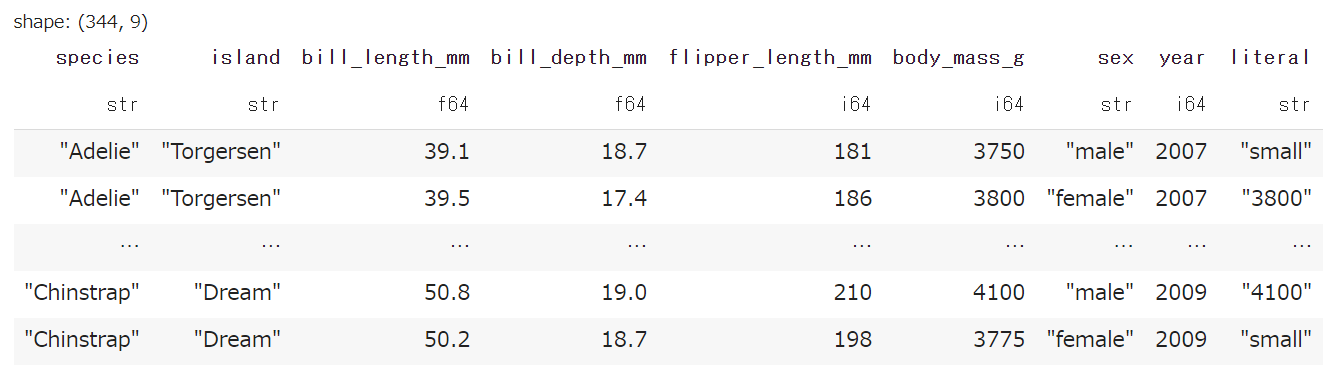
一番右に新しい列として追加されています。なお、列名は alias で指定することが出来ます。
また、この例だと元々f64型だったのがstr型に変わるのに注意が必要です2。
dplyrのifelseに相当する処理を書く
when..then..otherwiseを毎回書くのが面倒な場合、以下のような関数を用意することで、dplyrの ifelse と似た使い方が出来ます。
def ifelse(cond: pl.Expr, true_value, false_value) -> pl.Expr:
return pl.when(cond).then(true_value).otherwise(false_value)
df.with_columns(
ifelse(pl.col('body_mass_g') < 3800, 'small', pl.col('body_mass_g'))
)
引数に①条件、②条件が真だった場合に入れる値、③条件が偽だった場合に入れる値を記述できるような関数です。例にあげている処理の内容は先ほどと同じです。pandasの .loc を用いた代入とも似た感覚で使えると思います。
pandasのmask (where) に相当する処理を書く
あるいは以下のような関数を用意することで、pandasの mask と似た使い方が出来ます。
def mask(cond: pl.Expr, true_value) -> pl.Expr:
used_col = cond.meta.root_names()[0]
return pl.when(cond).then(true_value).otherwise(pl.col(used_col)).alias(used_col)
df.with_columns(
mask(pl.col('body_mass_g') < 3800, 'small')
)
pandasの mask と同じく、引数に①条件、②条件が真だった場合に入れる値を記述し、条件が偽の場合は元の列の値がそのまま残るような関数です。
ポイントとしては、条件のなかで参照されている列を特定し、偽の時の値として自動で取得しています。あと alias を指定して元の列を上書きする処理として書いていますが、これは良しなに変えていいでしょう。
なお、逆のものを書けばpandasの where に相当する処理も簡単に書くことが可能です。polarsには一応 where は存在しているので(単なる filter のエイリアスですが)、紛らわしくない mask に留めておくのが良いかと思っています。
2. 特定の要素を入れ替える方法
pandasの replace と同じ処理は、polarsでは map_dicts を用いると実現できます。
df.with_columns(
pl.col('island').map_dict({'Dream': 'd'}, default=pl.col('island'))
)
▼ 結果
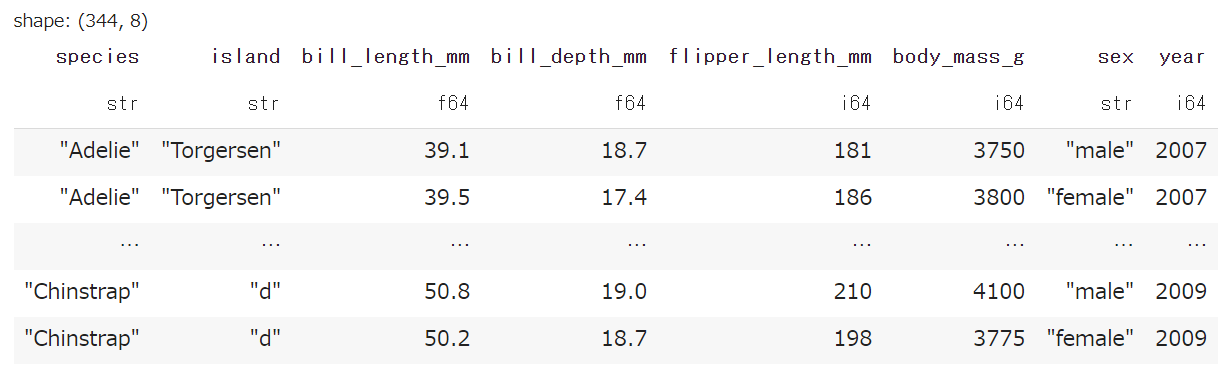
default を指定しないと、辞書のkeyにヒットしない行が全て欠損になってしまいます。
なお、polarsの replace はpandasの replace と全然違うことをやっていることに注意が必要です3。
3. 文字列の置換
文字列の置換が目的の場合、str.replace あるいは str.replace_all を使うと簡単に正規表現も用いた置換ができます。
df.with_columns(
pl.col('island').str.replace(r'e[a|r]', 'EA')
)
▼ 結果
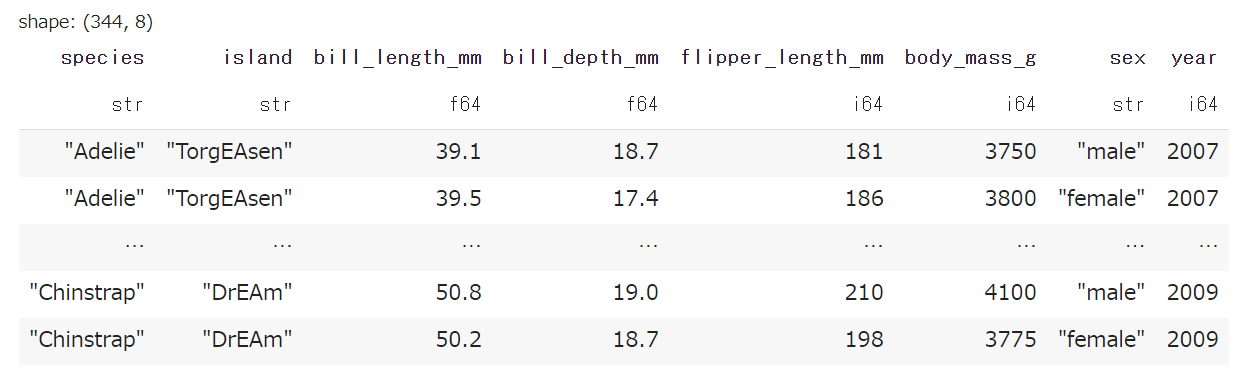
ちょっとこれは例がキモイですね(笑)
文字列の(部分)置換が出来るメソッドです。全出現箇所置換するには、str.replace_all を用います。
まとめ
色々書きましたが、pl.when を使うとやりたいことは全てできます。こちらを使う強みとして、複数の条件分岐を一連の処理として対応できる点があげられます。つまり、elif が沢山出てくるような処理も when..then.. を繰り返すことで一続きに書けるのがメリットです。
なお今回 ifelse などの関数を作る例をあげましたが、with_columns の性質から、同じ列に対して繰り返しこの関数を使って書くのは避けたほうがいいです。
-
pandasの場合、ひとつの列に異なる型が入ってしまうことがあるので、それと比べると列全体での一貫性は保たれるという利点があります。 ↩
-
ある列を別のSeriesで置き換える処理になります。参考: https://pola-rs.github.io/polars/py-polars/html/reference/dataframe/api/polars.DataFrame.replace.html ↩