データサイエンス100本ノック(構造化データ加工編)をPythonのPolarsで解いていきます1。
本記事では、各問題のポイントや細かい使い方の注意などに絞って解説していきます。
Polarsの基礎は以下などを参考にどうぞ。1, 2は公式の出してるドキュメントで、3は概要的な説明です(他にもググったら色々出てきます)。
- Introduction - Polars - User Guide
- API reference — Polars documentation
- 超高速、、だけじゃない!Pandasに代えてPolarsを使いたい理由 - Qiita
ちなみに本記事で使用したコードはこちらです。
0. 準備
ライブラリのインストール
pip install polars
なお、今回使用したpolarsのバージョンは0.15.11です。
データのダウンロード
git clone https://github.com/The-Japan-DataScientist-Society/100knocks-preprocess
データの読み込み
import os
import polars as pl
dtypes = {
'customer_id': str,
'gender_cd': str,
'postal_cd': str,
'application_store_cd': str,
'status_cd': str,
'category_major_cd': str,
'category_medium_cd': str,
'category_small_cd': str,
'product_cd': str,
'store_cd': str,
'prefecture_cd': str,
'tel_no': str,
'postal_cd': str,
'street': str,
'application_date': str,
'birth_day': pl.Date
}
df_customer = pl.read_csv("../data/customer.csv", dtypes=dtypes)
df_category = pl.read_csv("../data/category.csv", dtypes=dtypes)
df_product = pl.read_csv("../data/product.csv", dtypes=dtypes)
df_receipt = pl.read_csv("../data/receipt.csv", dtypes=dtypes)
df_store = pl.read_csv("../data/store.csv", dtypes=dtypes)
df_geocode = pl.read_csv("../data/geocode.csv", dtypes=dtypes)
P001 ~ P010
P-001:
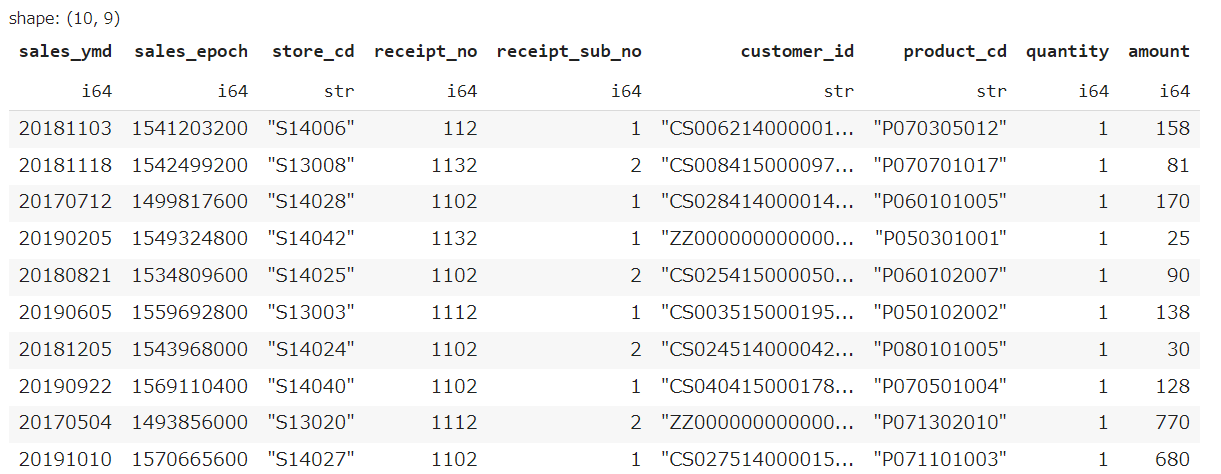
レシート明細データ(df_receipt)から全項目の先頭10件を表示し、どのようなデータを保有しているか目視で確認せよ。
df_receipt.head(10)
ちなみにpolarsはこんな感じで、shapeと型も出してくれます
P-002:
レシート明細データ(df_receipt)から売上年月日(sales_ymd)、顧客ID(customer_id)、商品コード(product_cd)、売上金額(amount)の順に列を指定し、10件表示せよ。
df_receipt.select(['sales_ymd', 'customer_id', 'product_cd', 'amount']).head(10)
なお、pandasでよく見られる以下の書き方は推奨されていません2。select を使いましょう。
df_receipt[['sales_ymd', 'customer_id', 'product_cd', 'amount']].head(10)
P-003:
レシート明細データ(df_receipt)から売上年月日(sales_ymd)、顧客ID(customer_id)、商品コード(product_cd)、売上金額(amount)の順に列を指定し、10件表示せよ。ただし、sales_ymdsales_dateに項目名を変更しながら抽出すること。
df_receipt.select([
pl.col('sales_ymd').alias('sales_date'), 'customer_id', 'product_cd', 'amount'
]).head(10)
P-004:
レシート明細データ(df_receipt)から売上日(sales_ymd)、顧客ID(customer_id)、商品コード(product_cd)、売上金額(amount)の順に列を指定し、以下の条件を満たすデータを抽出せよ。
- 顧客ID(customer_id)が"CS018205000001"
df_receipt.select([
'sales_ymd', 'customer_id', 'product_cd', 'amount'
]).filter(
pl.col('customer_id') == "CS018205000001"
)
列の指定と同じく行の指定でもIndexingによる選択は非推奨です。filter を使いましょう。
P-005:
レシート明細データ(df_receipt)から売上日(sales_ymd)、顧客ID(customer_id)、商品コード(product_cd)、売上金額(amount)の順に列を指定し、以下の全ての条件を満たすデータを抽出せよ。
- 顧客ID(customer_id)が"CS018205000001"
- 売上金額(amount)が1,000以上
df_receipt.select([
'sales_ymd', 'customer_id', 'product_cd', 'amount'
]).filter(
(pl.col('customer_id') == "CS018205000001") &
(pl.col('amount') >= 1000)
)
条件が複数ある場合、各条件は括弧で囲む必要があります。
これはpythonの演算子の優先順位が理由で、括弧がないと以下のように解釈されてしまいます3。
pl.col('customer_id') == ("CS018205000001" & pl.col('amount')) >= 1000
P-006:
レシート明細データ(df_receipt)から売上日(sales_ymd)、顧客ID(customer_id)、商品コード(product_cd)、売上数量(quantity)、売上金額(amount)の順に列を指定し、以下の全ての条件を満たすデータを抽出せよ。
- 顧客ID(customer_id)が"CS018205000001"
- 売上金額(amount)が1,000以上または売上数量(quantity)が5以上
df_receipt.select([
'sales_ymd', 'customer_id', 'product_cd', 'quantity', 'amount'
]).filter(
(pl.col('customer_id') == "CS018205000001") &
((pl.col('amount') >= 1000) | (pl.col('quantity') >=5))
)
P-007:
レシート明細データ(df_receipt)から売上日(sales_ymd)、顧客ID(customer_id)、商品コード(product_cd)、売上金額(amount)の順に列を指定し、以下の全ての条件を満たすデータを抽出せよ。
- 顧客ID(customer_id)が"CS018205000001"
- 売上金額(amount)が1,000以上2,000以下
df_receipt.select([
'sales_ymd', 'customer_id', 'product_cd', 'amount'
]).filter(
(pl.col('customer_id') == "CS018205000001") &
(pl.col('amount').is_between(1000, 2000))
)
P-008:
レシート明細データ(df_receipt)から売上日(sales_ymd)、顧客ID(customer_id)、商品コード(product_cd)、売上金額(amount)の順に列を指定し、以下の全ての条件を満たすデータを抽出せよ。
- 顧客ID(customer_id)が"CS018205000001"
- 商品コード(product_cd)が"P071401019"以外
df_receipt.select([
'sales_ymd', 'customer_id', 'product_cd', 'amount'
]).filter(
(pl.col('customer_id') == "CS018205000001") &
(pl.col('product_cd') != "P071401019")
)
P-009:
以下の処理において、出力結果を変えずにORをANDに書き換えよ。
df_store.query('not(prefecture_cd == "13" | floor_area > 900)')
df_store.filter(
(pl.col('prefecture_cd') != "13") & (pl.col('floor_area') <= 900)
)
P-010:
店舗データ(df_store)から、店舗コード(store_cd)が"S14"で始まるものだけ全項目抽出し、10件表示せよ。
df_store.filter(pl.col('store_cd').str.starts_with('S14')).head(10)
pandasだと startswith なのに対して、starts_with と微妙に違います。文字列に対する処理に str を噛ませるのは共通しています。
P011 ~ P020
P-011:
顧客データ(df_customer)から顧客ID(customer_id)の末尾が1のものだけ全項目抽出し、10件表示せよ。
df_customer.filter(pl.col('customer_id').str.ends_with('1')).head(10)
P-012:
店舗データ(df_store)から、住所 (address) に"横浜市"が含まれるものだけ全項目表示せよ。
df_store.filter(pl.col('address').str.contains('横浜市'))
P-013:
顧客データ(df_customer)から、ステータスコード(status_cd)の先頭がアルファベットのA〜Fで始まるデータを全項目抽出し、10件表示せよ。
df_customer.filter(pl.col('status_cd').str.contains(r'^[A-F]')).head(10)
pandasと違い、正規表現を渡したらそのまま正規表現として解釈してくれます。
P-014:
顧客データ(df_customer)から、ステータスコード(status_cd)の末尾が数字の1〜9で終わるデータを全項目抽出し、10件表示せよ。
df_customer.filter(pl.col('status_cd').str.contains(r'[1-9]$')).head(10)
P-015:
顧客データ(df_customer)から、ステータスコード(status_cd)の先頭がアルファベットのA〜Fで始まり、末尾が数字の1〜9で終わるデータを全項目抽出し、10件表示せよ。
df_customer.filter(pl.col('status_cd').str.contains(r'^[A-F].*[1-9]$')).head(10)
P-016:
店舗データ(df_store)から、電話番号(tel_no)が3桁-3桁-4桁のデータを全項目表示せよ。
df_store.filter(pl.col('tel_no').str.contains(r'^[0-9]{3}-[0-9]{3}-[0-9]{4}$'))
P-017:
顧客データ(df_customer)を生年月日(birth_day)で高齢順にソートし、先頭から全項目を10件表示せよ。
df_customer.sort('birth_day').head(10)
同順位(同日生まれ)の順番はpandasとずれてました。
P-018:
顧客データ(df_customer)を生年月日(birth_day)で若い順にソートし、先頭から全項目を10件表示せよ。
df_customer.sort('birth_day', reverse=True).head(10)
P-019:
レシート明細データ(df_receipt)に対し、1件あたりの売上金額(amount)が高い順にランクを付与し、先頭から10件表示せよ。項目は顧客ID(customer_id)、売上金額(amount)、付与したランクを表示させること。なお、売上金額(amount)が等しい場合は同一順位を付与するものとする。
df_receipt.select([
pl.col('customer_id'),
pl.col('amount'),
pl.col('amount').rank(method='min', reverse=True).alias('ranking')
]).sort('ranking').head(10)
同順位の場合の順位の付け方は method で指定できます4。
P-020:
レシート明細データ(df_receipt)に対し、1件あたりの売上金額(amount)が高い順にランクを付与し、先頭から10件表示せよ。項目は顧客ID(customer_id)、売上金額(amount)、付与したランクを表示させること。なお、売上金額(amount)が等しい場合でも別順位を付与すること。
df_receipt.select([
pl.col('customer_id'),
pl.col('amount'),
pl.col('amount').rank(method='random', reverse=True).alias('ranking')
]).sort('ranking').head(10)
P-021 ~ P-030
P-021:
レシート明細データ(df_receipt)に対し、件数をカウントせよ。
len(df_receipt)
P-022:
レシート明細データ(df_receipt)の顧客ID(customer_id)に対し、ユニーク件数をカウントせよ。
df_receipt.select(pl.col('customer_id').n_unique())
groupby をせずに全行を対象に集計する場合、agg ではなくて select を用います。
P-023:
レシート明細データ(df_receipt)に対し、店舗コード(store_cd)ごとに売上金額(amount)と売上数量(quantity)を合計せよ。
df_receipt.groupby('store_cd').agg([
pl.col('amount').sum(),
pl.col('quantity').sum()
]).sort('store_cd')
groupby で sort されないので、pandasでの実行結果の整合性確認のためだけに最後 sort を入れてます。以下のように maintain_order=True としても同じことができます。
df_receipt.groupby('store_cd', maintain_order=True).agg([
pl.col('amount').sum(),
pl.col('quantity').sum()
]).head(5)
同様に以下の問題でも、整合性確認のため意味もなく sort を入れている箇所があります。
P-024:
レシート明細データ(df_receipt)に対し、顧客ID(customer_id)ごとに最も新しい売上年月日(sales_ymd)を求め、10件表示せよ。
df_receipt.groupby('customer_id').agg(
pl.col('sales_ymd').max()
).sort('customer_id').head(10)
P-025:
レシート明細データ(df_receipt)に対し、顧客ID(customer_id)ごとに最も古い売上年月日(sales_ymd)を求め、10件表示せよ。
df_receipt.groupby('customer_id').agg(
pl.col('sales_ymd').min()
).sort('customer_id').head(10)
P-026:
レシート明細データ(df_receipt)に対し、顧客ID(customer_id)ごとに最も新しい売上年月日(sales_ymd)と古い売上年月日を求め、両者が異なるデータを10件表示せよ。
df_receipt.groupby('customer_id').agg([
pl.col('sales_ymd').min().alias('sales_ymd_min'),
pl.col('sales_ymd').max().alias('sales_ymd_max'),
]).filter(
pl.col('sales_ymd_min') != pl.col('sales_ymd_max')
).sort('customer_id').head(10)
P-027:
レシート明細データ(df_receipt)に対し、店舗コード(store_cd)ごとに売上金額(amount)の平均を計算し、降順でTOP5を表示せよ。
df_receipt.groupby('store_cd').agg(
pl.col('amount').mean()
).sort('amount', reverse=True).head(5)
P-028:
レシート明細データ(df_receipt)に対し、店舗コード(store_cd)ごとに売上金額(amount)の中央値を計算し、降順でTOP5を表示せよ。
df_receipt.groupby('store_cd').agg(
pl.col('amount').median()
).sort('amount', reverse=True).head(5)
P-029:
レシート明細データ(df_receipt)に対し、店舗コード(store_cd)ごとに商品コード(product_cd)の最頻値を求め、10件表示させよ。
df_receipt.groupby('store_cd').agg(
pl.col('product_cd').mode()
).select([
'store_cd',
pl.col('product_cd').arr.first()
]).sort('store_cd')
この問題は少しややこしいことをやっているので、丁寧に解説していきます。
まず、最頻値は複数の値が該当しうるため、Polarsの mode は以下のようにList型を返します。
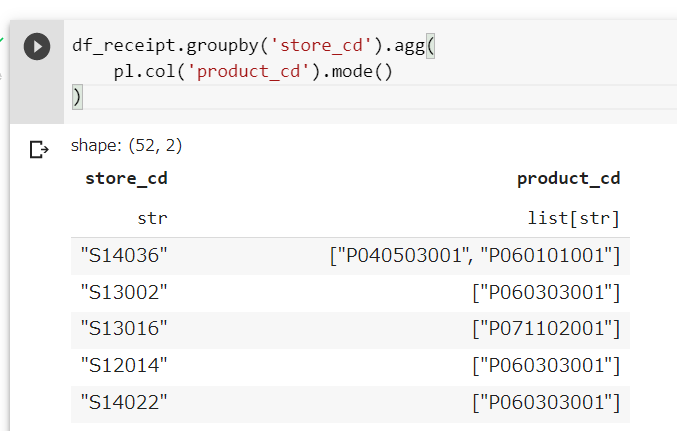
ここから適当にひとつの要素を抽出するために、arr.first を使用しています。arr はリスト型の列に対する処理をしたいときに挟む(str や dt と似たような)もので、first で一つ目の要素を取り出しています5。
結果、こうなります。

P-030:
レシート明細データ(df_receipt)に対し、店舗コード(store_cd)ごとに売上金額(amount)の分散を計算し、降順で5件表示せよ。
df_receipt.groupby('store_cd').agg(
pl.col('amount').var(ddof=0)
).sort('amount', reverse=True).head(5)
P-031 ~ P-040
P-031:
レシート明細データ(df_receipt)に対し、店舗コード(store_cd)ごとに売上金額(amount)の標準偏差を計算し、降順で5件表示せよ。
df_receipt.groupby('store_cd').agg(
pl.col('amount').std(ddof=0)
).sort('amount', reverse=True).head(5)
P-032:
レシート明細データ(df_receipt)の売上金額(amount)について、25%刻みでパーセンタイル値を求めよ。
df_receipt.select([
pl.col('amount').quantile(0).alias('q_0'),
pl.col('amount').quantile(0.25).alias('q_25'),
pl.col('amount').quantile(0.5).alias('q_5'),
pl.col('amount').quantile(0.75).alias('q_75'),
pl.col('amount').quantile(1).alias('q_100'),
])
Pandasのように quantile にArrayを渡すことは出来ません。が、やっていることは select にリストを渡すだけなので、以下のように書くこともできます。
df_receipt.select([
pl.col('amount').quantile(i).alias(f'q_{i}') for i in [0, 0.25, 0.5, 0.75, 1]
])
P-033:
レシート明細データ(df_receipt)に対し、店舗コード(store_cd)ごとに売上金額(amount)の平均を計算し、330以上のものを抽出せよ。
df_receipt.groupby('store_cd').agg(
pl.col('amount').mean()
).filter(
pl.col('amount') >= 330
).sort('store_cd')
P-034:
レシート明細データ(df_receipt)に対し、顧客ID(customer_id)ごとに売上金額(amount)を合計して全顧客の平均を求めよ。ただし、顧客IDが"Z"から始まるものは非会員を表すため、除外して計算すること。
df_receipt.filter(
pl.col('customer_id').str.starts_with('Z').is_not()
).groupby('customer_id').agg(
pl.col('amount').sum()
).select(
pl.col('amount').mean()
)
「顧客IDが"Z"から始まるものは非会員を表すため、除外して計算する」のように他の問題でもよく出てくるpl.Exprは、以下のように変数に代入してしまうのも有用でしょう。
exclude_nonmember = pl.col('customer_id').str.starts_with('Z').is_not()
df_receipt.filter(exclude_nonmember).groupby('customer_id').agg(
pl.col('amount').sum()
).select(
pl.col('amount').mean()
)
P-035:
レシート明細データ(df_receipt)に対し、顧客ID(customer_id)ごとに売上金額(amount)を合計して全顧客の平均を求め、平均以上に買い物をしている顧客を抽出し、10件表示せよ。ただし、顧客IDが"Z"から始まるものは非会員を表すため、除外して計算すること。
(df_receipt
.filter(pl.col('customer_id').str.starts_with('Z').is_not())
.groupby('customer_id')
.agg(pl.col('amount').sum())
.with_column(pl.col('amount').mean().alias('avg_amount'))
.filter(pl.col('amount') >= pl.col('avg_amount'))
.sort('customer_id')
.head(10)
)
ここまでは User Guide にあるっぽくコードを書いていたのですが、ここはdplyrっぽい書き方にしています。他意はありません。
P-036:
レシート明細データ(df_receipt)と店舗データ(df_store)を内部結合し、レシート明細データの全項目と店舗データの店舗名(store_name)を10件表示せよ。
df_receipt.join(
df_store.select(['store_cd', 'store_name']),
how='inner',
on='store_cd'
).head(10)
P-037:
商品データ(df_product)とカテゴリデータ(df_category)を内部結合し、商品データの全項目とカテゴリデータのカテゴリ小区分名(category_small_name)を10件表示せよ。
df_product.join(
df_category.select(['category_small_cd', 'category_small_name']),
how='inner', on='category_small_cd'
).head(10)
P-038:
顧客データ(df_customer)とレシート明細データ(df_receipt)から、顧客ごとの売上金額合計を求め、10件表示せよ。ただし、売上実績がない顧客については売上金額を0として表示させること。また、顧客は性別コード(gender_cd)が女性(1)であるものを対象とし、非会員(顧客IDが"Z"から始まるもの)は除外すること。
df_customer.filter(
(pl.col('gender_cd') == '1') &
(pl.col('customer_id').str.starts_with('Z').is_not())
).join(
df_receipt, how='left', on='customer_id'
).groupby('customer_id').agg(
pl.col('amount').sum().fill_null(0)
).head(10)
nullとnanが区別されるため、fill_nan ではなく fill_null を使います。
P-039:
レシート明細データ(df_receipt)から、売上日数の多い顧客の上位20件を抽出したデータと、売上金額合計の多い顧客の上位20件を抽出したデータをそれぞれ作成し、さらにその2つを完全外部結合せよ。ただし、非会員(顧客IDが"Z"から始まるもの)は除外すること。
df_data = df_receipt.filter(pl.col('customer_id').str.starts_with('Z').is_not())
df_cnt = df_data.groupby('customer_id').agg(pl.col('sales_ymd').n_unique()).sort('sales_ymd', reverse=True).head(20)
df_sum = df_data.groupby('customer_id').agg(pl.col('amount').sum()).sort('amount', reverse=True).head(20)
df_cnt.join(df_sum, how='outer', on='customer_id')
P-040:
全ての店舗と全ての商品を組み合わせたデータを作成したい。店舗データ(df_store)と商品データ(df_product)を直積し、件数を計算せよ。
(df_store.with_column(pl.lit(0).alias('key'))
.join(df_product.with_column(pl.lit(0).alias('key')), on='key', how='outer')
).shape
直積を計算するために、全レコードで0をとる、仮想的なKey列を作っています。
P041 ~ P050
P-041:
レシート明細データ(df_receipt)の売上金額(amount)を日付(sales_ymd)ごとに集計し、前回売上があった日からの売上金額増減を計算せよ。そして結果を10件表示せよ。
(df_receipt
.groupby('sales_ymd')
.agg(pl.col('amount').sum())
.sort('sales_ymd')
.with_column((pl.col('amount') - pl.col('amount').shift()).alias('diff_amount'))
.head(10)
)
shift は単に1行前のものを取得するだけです。したがって、前回売上日との差分を計算するには、shift の前に sort で並び替える必要があります。
P-042:
レシート明細データ(df_receipt)の売上金額(amount)を日付(sales_ymd)ごとに集計し、各日付のデータに対し、前回、前々回、3回前に売上があった日のデータを結合せよ。そして結果を10件表示せよ。
(df_receipt
.groupby('sales_ymd')
.agg(pl.col('amount').sum())
.sort('sales_ymd')
.with_columns([
pl.col('sales_ymd').shift(1).alias('sales_ymd_lag1'),
pl.col('amount').shift(1).alias('amount_lag1'),
pl.col('sales_ymd').shift(2).alias('sales_ymd_lag2'),
pl.col('amount').shift(2).alias('amount_lag2'),
pl.col('sales_ymd').shift(3).alias('sales_ymd_lag3'),
pl.col('amount').shift(3).alias('amount_lag3'),
])
.head(10)
)
指示とは違う気もするが、結合しない方法もありますよ、ということで…。
P-043:
レシート明細データ(df_receipt)と顧客データ(df_customer)を結合し、性別コード(gender_cd)と年代(ageから計算)ごとに売上金額(amount)を合計した売上サマリデータを作成せよ。性別コードは0が男性、1が女性、9が不明を表すものとする。
ただし、項目構成は年代、女性の売上金額、男性の売上金額、性別不明の売上金額の4項目とすること(縦に年代、横に性別のクロス集計)。また、年代は10歳ごとの階級とすること。
gender_mapping = {
'0': 'male',
'1': 'female',
'9': 'unknown'
}
(df_customer
.join(df_receipt, how='left', on='customer_id')
.with_columns([
((pl.col('age') / 10).floor() * 10).alias('era'),
pl.col('gender_cd').apply(lambda x: gender_mapping[x]).alias('gender')
])
.groupby(['gender', 'era']).agg(pl.col('amount').sum())
.pivot(values='amount', index='era', columns='gender')
.sort('era')
)
apply を使っている部分は、when ~ then ~ ohterwise で記述することも可能です。
P-044:
043で作成した売上サマリデータ(df_sales_summary)は性別の売上を横持ちさせたものであった。このデータから性別を縦持ちさせ、年代、性別コード、売上金額の3項目に変換せよ。ただし、性別コードは男性を"00"、女性を"01"、不明を"99"とする。
(df_customer
.join(df_receipt, how='left', on='customer_id')
.with_columns([
((pl.col('age') / 10).cast(pl.Int16) * 10).alias('era'),
pl.col('gender_cd').apply(lambda x: gender_mapping[x]).alias('gender')
])
.groupby(['gender', 'era']).agg(pl.col('amount').sum())
.sort(['era', 'gender'])
)
P-045:
顧客データ(df_customer)の生年月日(birth_day)は日付型でデータを保有している。これをYYYYMMDD形式の文字列に変換し、顧客ID(customer_id)とともに10件表示せよ。
df_customer.select([
'customer_id',
pl.col('birth_day').dt.strftime('%Y%m%d')
]).head(10)
最初の read_csv で dtypes を指定しなかった場合、birth_dayが文字列でデータを保有している可能性があります。その場合、以下を噛ませてあげればよいです。
df_customer = df_customer.select([
pl.col('birth_day').str.strptime(pl.Date, "%Y-%m-%d"),
pl.all().exclude('birth_day')
])
P-046:
顧客データ(df_customer)の申し込み日(application_date)はYYYYMMDD形式の文字列型でデータを保有している。これを日付型に変換し、顧客ID(customer_id)とともに10件表示せよ。
df_customer.select([
'customer_id',
pl.col('application_date').str.strptime(pl.Date, "%Y%m%d")
]).head(10)
strptime は型(Date/DateTime)を第一引数に指定します。
最初の read_csv で dtypes を指定しなかった場合、application_dateが数値型でデータを保有している可能性があります。その場合、次の問題のように cast(pl.Utf8) を噛ませてあげればよいです。
P-047:
レシート明細データ(df_receipt)の売上日(sales_ymd)はYYYYMMDD形式の数値型でデータを保有している。これを日付型に変換し、レシート番号(receipt_no)、レシートサブ番号(receipt_sub_no)とともに10件表示せよ。
df_receipt.select([
'receipt_no',
'receipt_sub_no',
pl.col('sales_ymd').cast(pl.Utf8).str.strptime(pl.Date, "%Y%m%d")
]).head(10)
数値型から直接日付型に変換することは(たぶん)できないため、一旦文字型に変換するプロセスを噛ませます。
P-048:
レシート明細データ(df_receipt)の売上エポック秒(sales_epoch)は数値型のUNIX秒でデータを保有している。これを日付型に変換し、レシート番号(receipt_no)、レシートサブ番号(receipt_sub_no)とともに10件表示せよ。
df_receipt.select([
'receipt_no',
'receipt_sub_no',
pl.col('sales_epoch').cast(pl.Utf8).str.strptime(pl.Datetime, fmt='%s')
]).head(10)
P-049:
レシート明細データ(df_receipt)の売上エポック秒(sales_epoch)を日付型に変換し、「年」だけ取り出してレシート番号(receipt_no)、レシートサブ番号(receipt_sub_no)とともに10件表示せよ。
df_receipt.select([
'receipt_no',
'receipt_sub_no',
pl.col('sales_epoch').cast(pl.Utf8).str.strptime(
pl.Datetime, fmt='%s').dt.year().alias('sales_year')
]).head(10)
P-050:
レシート明細データ(df_receipt)の売上エポック秒(sales_epoch)を日付型に変換し、「月」だけ取り出してレシート番号(receipt_no)、レシートサブ番号(receipt_sub_no)とともに10件表示せよ。なお、「月」は0埋め2桁で取り出すこと。
df_receipt.select([
'receipt_no',
'receipt_sub_no',
pl.col('sales_epoch').cast(pl.Utf8). \
str.strptime(pl.Datetime, fmt='%s'). \
dt.strftime('%m').alias('sales_month')
]).head(10)
文字列の形式を指定して取り出すときは、dt.month() よりも strftime を使用したほうが便利です。
おわりに
せっかくなので、今回解いた問題のひとつを使ってPolarsの良さを語っていきたいと思います。
P-035:
レシート明細データ(df_receipt)に対し、顧客ID(customer_id)ごとに売上金額(amount)を合計して全顧客の平均を求め、平均以上に買い物をしている顧客を抽出し、10件表示せよ。ただし、顧客IDが"Z"から始まるものは非会員を表すため、除外して計算すること。
この問題文を分解するとこうなります。
- レシート明細データ(df_receipt)に対し
- 顧客ID(customer_id)ごとに売上金額(amount)を合計して
- 全顧客の平均を求め
- 平均以上に買い物をしている顧客を抽出し
- 10件表示せよ
- ただし、顧客IDが"Z"から始まるものは非会員を表すため、除外して計算すること
コードと対応させると、ほぼこの流れの通りに書けることが分かります。
※ 6は割とどこで書いてもいいやつなので最初に持って来てます
(df_receipt # 1. レシート明細データに対し
.filter( # 6. 非会員の除外
pl.col('customer_id').str.starts_with('Z').is_not()
)
.groupby('customer_id').agg( # 2. 顧客IDごとに売上金額を合計
pl.col('amount').sum()
)
.with_column( # 3. 全顧客の平均を求め
pl.col('amount').mean().alias('avg_amount')
)
.filter( # 4. 平均以上に買ってる顧客を抽出
pl.col('amount') >= pl.col('avg_amount')
)
.head(10) # 5. 10件表示
)
実務とかで問題文を読みながらコードを書くようなことはないでしょう。ですが、日本語で考えたとき浮かぶ自然な処理の順序とコードを書く順序が揃っていることを意味する、かなり書きやすいポイントかと思います。
ちなみにpandasだと
df_amount_sum = df_receipt[~df_receipt['customer_id'].str.startswith("Z")].\
groupby('customer_id').amount.sum()
amount_mean = df_amount_sum.mean()
df_amount_sum = df_amount_sum.reset_index()
df_amount_sum[df_amount_sum['amount'] >= amount_mean].head(10)
みたいな感じになったりします6。途中でぱっと見関係なさそうな reset_index が混ざったり、別の変数に代入したりしています。
後編へ続く
-
上のGithubにあげられている「Colaboratory(Python解答)」を参考にしている部分があります。なお、表示される解答が一致することは確認しています ↩
-
https://pola-rs.github.io/polars-book/user-guide/howcani/selecting_data/selecting_data_indexing.html#indexing-is-an-anti-pattern-in-polars ↩
-
https://pola-rs.github.io/polars/py-polars/html/reference/expressions/api/polars.Expr.rank.html#polars.Expr.rank ↩
-
リスト型についての公式ガイドのページはこちら → https://pola-rs.github.io/polars-book/user-guide/dsl/list_context.html ↩
-
注1にあげられている「Colaboratory(Python解答)」に載っている書き方です。 ↩