こちらはLife is Tech ! Advent Calendar 2016 22日目の記事です。
自己紹介
こんにちは!先日GitHubのIDがha1fha1fからha1fになりました、はるふ(@_ha1f)と申します。
Life is Tech ! では、主にiPhoneコースのメンター・講師をしています。
本記事について
Gitについての記事は、世の中に多くあります。
- gitコマンドの使い方
- gitの仕組み
- gitを用いたプロジェクト管理・運用
- subversionなどとの比較・歴史
など、テーマが色々有ると思いますが、本記事では、gitについて、少し仕組みについて踏み込みながら、コマンドとの関連を説明します。
用語の確認の章は初心者向けの基礎編です。使い方わかる方は飛ばしてください!
それ以降は、仕組みについて書きます。もちろん軽く使うだけなら仕組みを知る必要はないですが、自分は仕組みを知ることで、初めてrebaseとかのコマンドを覚えられたので、それを伝えたくて。
研修などで少しGitを使ったことあるけど、流れを覚えられないとか、rebaseとかやった事あるけど覚えられない、という人向けに書きます。触ったことがないと想像しにくいかもしれません。
仕組みを知ることで、なぜそういうコマンドの流れなのかとか、なぜファイルを file(11/23ver), filer(12/3ver) のようにいくつも作るのよりも優れているのか、みたいなことが伝わるかな、と思います。
用語の確認:初級
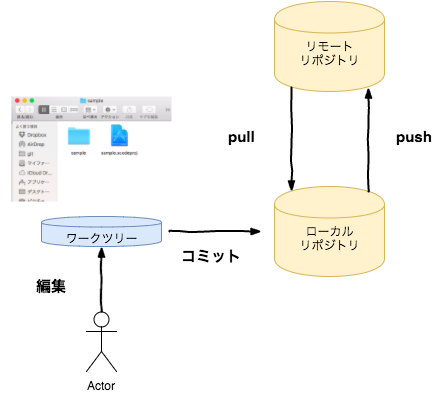
リポジトリ
難しいイメージは必要ありません。Gitは、過去ソースコードのデータベースです。これを「リポジトリ」と呼びます。
ワークツリー
Gitがない時でも、普通にファイルは存在します。Gitの世界では、これをワークツリーと呼びます。
普段編集・閲覧している、Finderやエクスプローラから見れるファイルのことです。
上の図で、右側の領域は見えない部分で、gitコマンドを使うことで、操作することのできる部分です。基本的に直接触れることはなく、コミットに限らず、「コマンドを介して」操作を行います
コミット
その時のワークツリーの状態を、git = 過去ソースコードデータベースに登録する操作を、「コミット」と呼びます。
ワークツリーの内容を、ある程度作業をするたびに、「コミット」しておくと、失敗した時は、データベースを読み込むことで、昔の状態に戻すことができます。
以下のスクショでは、各行が「コミット」に対応しています。

各コミットの一つ前のコミットのことを親コミットと呼びます。そのコミットの時にどんな操作をしたのかは、親コミットとの差分を比較することで実現されています。
コミットメッセージ
コミットする際に、どんな作業をしたか、どんな変更をしたか、ということをメモしておくことができます。これを「コミットメッセージ」と呼びます。
上のスクリーンショットでの、"add walking animation in splash view"のようなもののことです。複数行など、もっと長いメッセージも保存できます。
「タイトル+空白行+本文」というのが標準だそうですが、実際の業務ではタイトルだけとかが多い気がします(個人的には、編集や議論しやすいように、コミットメッセージはタイトルだけぐらいで、プルリクエストに丁寧に書くのがいい気がします)
コミットログ
過去のコミット群のことを、コミットログと呼びます。それぞれにコミットメッセージがついているので、遡りやすいです。
スクショでない実物も、こんな感じで見ることができます→commits
大規模なプロジェクトだと、数万コミットとか溜まっていたりします。右側にある英数列を押すと、親コミットとの差を見ることもできます。

ローカルリポジトリ・リモートリポジトリ
Gitは「分散型バージョン管理システム」と言われます。これは、各PCにGitというデータベースがある(サーバーに一つだけある状態ではない)ということを意味します。
とはいえ、各人のPCだけにあると、他の人に見てもらいたいとか、PCが壊れたとか、そういう時に困るので、サーバー上にバックアップをとれると便利です。これがリモートリポジトリです。
逆に、各PCにあるデータベースをローカルリポジトリ、と呼びます。
リモートリポジトリは、GitHubやBitbucketが有名ですね。こんな感じで、見ることができます→jphacks/KB_1501
ほぼ、ローカルのもののコピーと思ってもらって大丈夫です。
push, pull
ローカルリポジトリの内容を、リモートリポジトリに反映する操作をpush(プッシュ)、
リモートリポジトリの内容を、ローカルリポジトリに反映する操作をpull(プル)、
と呼びます
clone
リポジトリの内容を、丸々(コミットログも含めて)コピーすることをclone(クローン)と呼びます。通常、リモートリポジトリから自分のPCにコピーする事を言います。
ブランチ
この文字列(16進数)の意味は後で説明します。四角がコミットに対応すると思ってください。

複数人で開発する場合を考えてみて下さい。
あるときの状態(ここでは、c1eb914)から、複数の人が別々のPCで、それぞれコミットを行うと、どうなるでしょうか?AさんのPCとBさんのPCで、状態に不整合が発生してしまいます。そうなると、ふたりとも同じサーバー上に反映しようとすると、不整合が発生してしまいます。
そうならないように、分岐を作ります。それぞれの分岐に名前をつけて、同時にサーバー上に保存すると、不整合は発生しません。
このそれぞれを「ブランチ」と呼びます。ブランチにつけた名前を、「ブランチ名」と呼びます。
これは一人でも、新規の機能を作成中に、深刻なバグが見つかった場合、一旦コミットしておいて、一つ前のコミットからバグ修正を行う、そういう場合にも、ブランチを作ります。
マージ
同じブランチ名であっても、push, pullしなければ、ローカルとリモート、もしくは他の人のローカルと自分のローカルの内容は異なることがあります。
また、ブランチだけいっぱい作っても、まとめられなければあまり意味がありません。各ブランチをまとめることをマージと呼びます。
以下のスクリーンショットは、ブランチが作られたりマージされたりしている様子を表したものです。
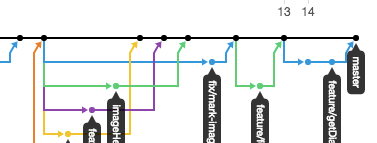
この図では、各点が「コミット」に、各線が「ブランチ」に対応しています。青・緑・紫・黄色で、同じ親コミットを持ったコミットが作られているのが見えます。
黒い線がmasterブランチといって、メインのブランチになります(※開発体制により異なります)
矢印がマージを表しています。作業ごとに新しいブランチを作って、作業が完了したらマージして、変更分を取り込んで、masterを成長させています。
仕組み:初級
ここまでは、基礎の確認です。
add, commit, push, など、毎回色々しなきゃいけなくて面倒?と感じたことあると思います。実際どうやって「コミット」などが行われているのでしょうか?
Gitの実体
git initコマンドを実行すると、.gitというディレクトリが作られます。この中に、Gitに関するすべてのデータが保存されます。逆に、このディレクトリを消すだけで、Git関連ファイルはなくなります。
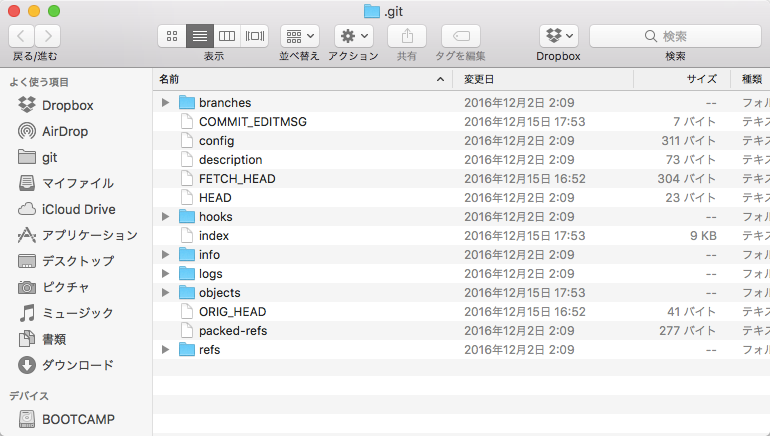
実行したディレクトリ以下のファイルを監視できます
オブジェクト
このGitのデータベースを構成する実体は、大量のオブジェクトです。
- blobオブジェクト
- treeオブジェクト
- commitオブジェクト
この3種類のオブジェクトが、
.git/objects/
というディレクトリの中に”たくさん”保存されています。
commitオブジェクトはコミット(とルートディレクトリ)に、
treeオブジェクトはディレクトリに、
blobオブジェクトはファイルに、
対応しています。これらがうまく働いて、システムができています。それぞれについて、詳しくは後で説明します。

各オブジェクトには、「ハッシュ」という名前がついていて、それによって特定のオブジェクトにアクセスすることができます
ハッシュ
オブジェクトを保存するときに、内容に応じて「ハッシュ」というものが作られます。3ae0e411fa621bc549023dc588bcbda7ff5c55cbのような値です。これを名前にして保存します。
40桁の16進数(SHA1)で、ランダムに見えますが、ファイルの内容が全く同じであれば同じ物が作られて、少しでも違うと、全く別のものが作られます。
もちろん、ある確率で衝突しますが、この確率は十分に低く、無視して良いとされています。
僕の計算では、オブジェクトがnこの時の衝突確率は、ハッシュが均一分布だと仮定すれば、
余事象は「n個のハッシュがすべて異なる」ことであるので、
1 - 1 \cdot \frac{16^{40}-1}{16^{40}} \cdot \frac{16^{40}-2}{16^{40}} ・・・ \frac{16^{40}-n+1}{16^{40}}\\
= 1 - \frac{(16^{40}-1)!}{16^{40(n-1)} \cdot (16^{40}-n)!}
です(※保証しません)
よくコマンド実行したときとかに
git pull
Updating f7f89f3..5ea791f
みたいなのが出ると思いますが、これはコミットオブジェクトのハッシュの前7桁です。40桁もなくても前7桁でもあれば、ほぼ判別できるので、前だけ表示されることも多いです。
.git/objectsをみてみる
ある程度コミットログが溜まった.git/objectsを見てみると、ディレクトリがいくつもあります。これは、ハッシュの前二桁がフォルダ名にになっていて、その中に各オブジェクトが存在します。

ディレクトリの中身は、残り38桁がファイル名になったファイル(オブジェクト)があります。

どれも名前がハッシュなので、見た目ではどれがblobでどれがtreeでどれがcommit、とかは判断つきません。が、ちゃんと種類も含めて保存されています。
ハッシュは名前なので、ハッシュが分かれば、そのオブジェクトにアクセスすることができます。
これらのオブジェクトがどうやって動作するのか見ていきます。
blobオブジェクト
blobオブジェクトは、ファイルが圧縮されたものです。ファイルと1:1に対応しています。
git addという操作は、今のワークツリーにあるファイルをここにコピーして、圧縮する作業です。
git addするたびにファイルが圧縮されてblobオブジェクトになり、.git/objectsに蓄積されます。復元できるので、「ある時点でのファイルそのもの」というイメージを持つとわかりやすいと思います。
※よって、500MBとか、大容量のファイルをgit addすると少し時間がかかります。また、不用意にgit addし続けると、かなり容量が肥大化します。(gcコマンドを使えば解消もできますがここでは割愛します)
treeオブジェクト
treeオブジェクトは、ディレクトリに対応していて、ディレクトリの中にあるファイルとディレクトリの一覧を示します。(つまり、中身のblobオブジェクトとtreeオブジェクトを示すハッシュ)

treeオブジェクトは、上のスクショ(全てで一つのtreeオブジェクト)のように、
- ファイル名 & 対応するblobオブジェクトのハッシュ
- ディレクトリ名 & 対応するtreeオブジェクトのハッシュ
の一覧を持っています。
treeオブジェクトを復元するときには、一覧を順番に見ながら、
- blobオブジェクトなら復元する
- treeオブジェクトならその中身に対し、同じ操作を適用する
という再帰処理によって、完全に復元できるのがわかるかと思います。
こちらも復元できるので、「ある時点でのディレクトリとその中身そのもの」というイメージを持つとわかりやすいと思います。
コミットオブジェクト
コミットオブジェクトは、
- ルートのtreeオブジェクトのハッシュ
- 親コミット(一つ前のコミット)
- authorの名前・メールアドレス
- committerの名前・メールアドレス
- コミットメッセージ
のデータを保持しています。スクリーンショットは一例です。

ルートのtreeオブジェクトは、.gitディレクトリが含まれるディレクトリ(git initしたディレクトリ)に対応するtreeオブジェクトになります。ルートのツリーオブジェクトが分かれば、上で述べたように、その時の状態をすべて復元することができます。よって、コミットがわかればその時の状態に完全に復元することができます!
また、親コミットを持っているので、「そのコミットの時にどんな変更をしたのか」(親コミットとの差分)を見ることができます(※これにより、まるで「コミット」が「差分」に対応しているかのように見えます)
さらに、親コミット→親コミットの親コミット→親コミットの親コミットの親コミット→……
というように、どんどん遡ることもできます
committerとauthorについては、あとで述べる git rebase コマンドなどを使うとコミットログを書き換えられるのですが、その場合でもオリジナルのコードを書いた人をauthorとして保持しておく、というものですが、ここで特に意識する必要はありません。(参考:Git での Committer と Author の違いは?)
差分(参照)
以上のように、ハッシュの参照だけでオブジェクトを扱うことで、100ファイルあるうちの1ファイルのみ変更したコミットでは、99の変更してないファイルに対応するblobオブジェクトは再度は生成されません。
異なるtreeオブジェクトが、同じblobオブジェクトを参照するような形になります。
これにより、過度に容量が肥大化することなく、完全に復元可能なログを保持することができます。(こう考えると、file(最終), file(ホントの最終), file_ver2みたいにすべてのファイルを保持したまま、別の名前をつけているのがいかに愚かか・・・)
HEAD
今の作業からみて、直前のコミットのことをHEADと呼びます(以下の説明でもこの表現を多用します)
直前のコミットオブジェクトを示すハッシュと同等のものが、.git/HEADに保存されています。
各コミットは親コミットを持つので、HEADから、親コミットを順番に辿っていくと、コミットログを遡ることができます。
また、新しいコミットを作るときは、親コミットとしてHEADの示すハッシュが設定されます。
ステージング(インデックス)
gitにはステージングエリア(インデックス)というものがあって、「いまコミットすると保存される状態」を表します。

コミットした直後は、ステージングエリアの状態と、HEADの状態は全て同じです。ワークツリーの状態も、すべてaddしていれば同じです。
そこから何か作業をすると、ワークツリーだけが違う状態になります。
ここで、git addコマンドを実行すると、追加された部分に対応するblob/treeオブジェクトが作成されるのと同時に、自動的にステージングの状態が変更されます。(addした直後は、ワークツリーの状態とステージングエリアの状態は同じになります)
コミットする際には、ステージングの状態からコミットオブジェクトが作成されます。(よって、コミットした直後は、ステージングエリアの状態と、HEADの状態は同じになります)
git statusコマンドをを実行したときに、Changes to be committedとして表示されるのは、HEADの状態と、ステージングの状態の差になります。
.git/indexというファイルに、インデックスの状態が保持されています。バイナリファイルなので直接は見れませんが、 git ls-files --stage を実行すると確認できます。
インデックスの状態は、git addコマンドや、git rmコマンドを実行したときに自動的に変更されますが、git resetコマンドなどでも書き換えることができます。
コマンドの使い方:初級
ここまで理解すると、少し見え方が変わってくると思います。実際に使うコマンドを見てみましょう
git init
git initコマンドを実行すると、データベース用のフォルダとして.gitという隠しフォルダが作られます。(ls -aを実行すると確認できます)
必要な空ディレクトリも用意されます。
git rm
そのファイルを削除した上で、インデックスにも反映します
git add
ファイル/ディレクトリを、圧縮・ハッシュで命名して.git/objectsにコピーします。同時に、ステージングにも反映します
git add 対象
のように、対象ファイルを指定します。対象ファイルの指定の仕方はいろいろあって、以下に示します。
ファイル名: 指定されたファイル、スペース区切りで複数指定可能。ワイルドカード(*)も使えます
-u: 削除されたファイルと、修正されたファイル
.: 新しく作られたファイルと、修正されたファイル
-A: 新しく作られたファイルと、削除されたファイルと、修正されたファイル
より詳しい説明は、以下のリンク先をご参照ください
git status
git status
主にステージングの状態を確認することができます。
Changes to be committedがHEADとの差分、Changes not staged for commit及びUntracked filesはワークツリーとの差分になります。

git reset
HEADやステージングの状態、ワークツリーの状態を、指定した状態に戻します。どれを戻すかの設定が--soft, --hardといったオプションです。
先程の、add, commitなどが書いてあるスクリーンショットで、逆向きの動きをするのがresetです。

git reset 対象ファイル コミットへの参照
「対象ファイル」の指定の仕方はaddと同じです。
「コミットへの参照」は、何も指定しないとHEADになります。コミットへの参照は、ハッシュを入力するか、HEADを入力するかがメインになります。
ハッシュを入力する際、オブジェクトを区別できるのであれば、32桁全てでなくとも、上7桁程度でも大丈夫です。(大抵の場合十分です。上の衝突確率の式の、40の部分を7に、n=1000で計算してみると、0.18%ぐらいでした。)
HEAD^ や HEAD~3 のような書き方もあります。それぞれ、HEADの一つ前、HEADの3つ前、という意味になります。HEAD^^^でも3つ前を表せます。
--mixed
何もオプションを付けないと、--mixedをつけた設定になり、ステージングとHEADを変更します。(--mixed を明示しても同じ動作をしますが、deprecatedと言われます)
よって、git resetのみ実行した場合は、git add や git rm といった処理を取り消せます。
※--mixedでなく、--hardや--softなどをつける場合、対象ファイルの指定はできなくなり、必ずgit監視下のすべてのファイル/ディレクトリになります。(指定しようとするとfatal: Cannot do (soft|hard) reset with pathsというエラーが出ます)
--hard
git reset --hard コミットへの参照の場合、ワークツリーとインデックスをすべてそのコミットのときの状態に戻します。本当に失敗した時に使います。
よく使うのは、git reset --hard HEADとして、直前のコミットの状態からやり直すことでしょうか
--soft
ワークツリーはそのままに、インデックスもそのまま、HEADのみを変更します。
コミットをまとめるときなどに使います。
git commit
ステージングの状態を、コミットオブジェクトに変換して、コミットログとして登録します。
git commit -m "コミットメッセージ"
軽くコミットメッセージを書くときは、-mオプションで一行だけつけます。これをつけないと、git configのcore.editorで指定されているエディタが立ち上がります。
これに書いて保存すると、複数行のコミットメッセージなども書くことができます。
可能であれば、一行目にタイトル、2行目は空行、三行目以降に詳細、というスタイルが良いらしいです。
--amend
直前のコミットを取り消して、その変更と、今の変更を含めて、新たなコミットを作ることができます。
動作としては、
git reset --soft HEAD~1
git commit
と同じです。
git config
commitオブジェクトに保存されるユーザー情報などを設定できます。
core.editor
user.email
user.name
などは設定しておくと良いでしょう
設定するときは、
git config --global user.name "ha1f"
のように、git config --global 設定項目 "内容" というコマンドを実行します
git config --list
ですべての設定を確認できます。
git log
gitのコミットログを確認することができます。
実体としては、HEADから、親コミットを順番に辿っていって、表示しています。
何も指定しないとすべて走査しようとするので、基本的には、下記のように表示数を指定して表示させます。
git log -4
のように、表示件数を指定して表示します。(ハイフンの後ろに件数)
--oneline
--oneline オプションを付けると、各コミットを一行で表示できるので便利です。このときコミットのハッシュは7桁しか表示されませんが、先に述べたとおり、reset時なども特定できる桁数あれば十分なので、これで困ることはほぼないと思います。
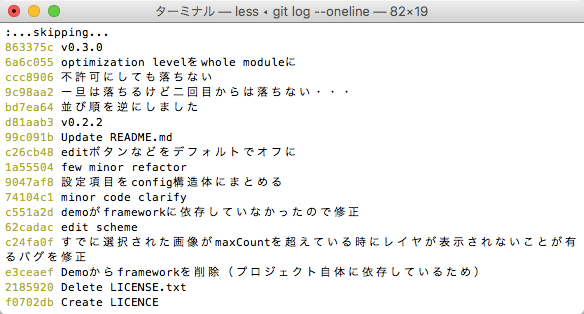
--graph
--graph オプションを付けると、ブランチの流れを見ることができます。
ブランチについては後で説明します。
--graphと--onelineどっちもつけるのも便利です
git diff
2つの状態(コミット間など)の差を見ることができます。
git diff

何も指定しないと、ワークツリーとステージングとの差を見れます
git diff --cached
とすると、ステージングとHEADとの差を見れます
git diff ハッシュ1 ハッシュ2
とすると、コミット間の差を見れます
仕組み:中級
上の部分がわかれば、あとの機能は延長線です。
ブランチ
ブランチの実体は、ただの最新コミットへのハッシュです。 .git/refs/heads/ に保存されています。

※上のスクショではディレクトリができていますが、ブランチ名に / を入れたためにディレクトリになっているだけです。
それぞれはテキストファイルになっていて、

こんな感じでハッシュが保存されているのを確認できます。
もちろん書き換えればブランチのHEADを動かすことができるし、新しくテキストファイルを作ってハッシュを書けば、ブランチを作ることができます。
スクショでは、一番下にあるのが、各ブランチのHEADになります。上が古いコミットです。masterのHEADはc1eb914、feature/AブランチのHEADはd14ed85ですね。
矢印が指しているのが親コミットです。最新コミットだけ持っていれば、それぞれ親をたどれば、分岐を作ることができるのは想像できると思います。
再掲ですが、左から二つ目の黒いコミットオブジェクトを親に持ったコミットオブジェクトが4つあって、それぞれが青、緑、紫、黄色に対応しています。想像できますでしょうか?
ブランチ一覧表示のときは、 .git/refs/heads/ 以下のファイルを表示するだけです。
ブランチ作成は、分岐元ファイルをコピーするだけです。ブランチ削除もファイルを消すだけです。
マージ
fast-forwardマージ
feature/Aブランチをmasterブランチにそのままマージすることを考えると、masterのHEADをd14ed85にすればいいだけのように見えます。こういうマージを、fast-forwardマージと呼びます。
ただし、マージの取り消し操作のやりやすさから、マージコミットと言うものを作ることが好まれます。
git merge --no-ff
このffはfast-forwardです。fast-forwardでないマージがマージコミットを作るコミットです。
マージコミットを作るマージ
マージコミットは特殊なコミットで、親コミットが2つあります。

9e434a8、がマージコミットです。
コマンドの使い方:中級
長くなってきたので、ここは基本的に紹介するだけにします。
そんなことできるんだぐらいで、具体的な使い方は、使う時に調べていただければと思います。
git remote
git remote add リモートリポジトリ名 url
リモートリポジトリとして登録
git remote set-url 名前 url
リモートリポジトリのurlの書き換え
※リモートリポジトリ名は、originという名前が標準です。
git push
git push リモートリポジトリ名 ブランチ名
リモートリポジトリへ送信
git push -u origin master
とすると、デフォルトの追跡ブランチ(upstream, 同期?しているリモートリポジトリのブランチ)が登録されるので、次回以降 git push だけ打てば良くなります。
git push origin master:branch2
のようにすることで、リモートリポジトリのbranch2へローカルリモートリポジトリのmasterの内容を送信できます。
git pull
リモートリポジトリの変更をローカルリポジトリにマージします
git branch
git branch # ブランチ一覧を表示
git branch ブランチ名 # ブランチを作成
git branch -D ブランチ名 # ブランチを削除
git checkout
ブランチを切り替えます。HEADの内容を、そのブランチのHEADで置き換え、ワークツリーの内容にも反映します。
git checkout -b ブランチ名
とすると、
git branch ブランチ名
git checkout ブランチ名
という操作をまとめてできるので便利です。
git rebase
歴史を改変することができます。コミットをまとめるとか、コミットメッセージを編集するとか、コミットの順番を変えるとか、そのコミットでの差分をなかったことにするとか、親コミットを付け替えるとか、なんでもできます
上の記事がめっちゃわかりやすいです。
git rebaseによるマージもよく使います。merge 〜〜みたいなコミットを作らずにマージできるのできれいです。
git fetch
リモートリポジトリの特定のブランチを、ローカルリポジトリにもコピーします
git merge
特定のブランチでの変更をすべて取り入れます
git cherry-pick
特定のコミットでの差分を取り入れます。
上級の一部
機能自体はそんなに多くないと思うのですが、便利なように便利なようにといろんなコマンドがあり、自分も全然覚えられておりませんが、その他コマンドについても少しだけ書きます
git cat-file
git cat-file -p <SHA1ハッシュ>
で中身を見ることができます
(上のスクリーンショットを撮るのに重宝しましたがいつ使うんだ・・・?)
git gc
addしたけどcommitしなかった、のような場合だと、不要なオブジェクトが生成されてしまいます。このようにどこからも参照されなくなったオブジェクトを消すのが git gc コマンドです。
git stash
コミットせずに、一時的に変更内容を保存することです。コミットしたくないけどブランチを切り替えなきゃいけない時に使います。
仮の名前でコミットしておいて、あとで--amendするのと結果としては同じです
git ls-files --stage
インデックスの状態を確認できる
最後に
これだけ長く書きましたが、Git関係の機能はまだまだあります。実際、GitHub周りの仕様(fork, PR等)には全く触れていません。コマンドの説明もそれぞれ端折ってますし、rebaseとか、mvとか、説明してないコマンドもあります。でも、仕組みをしれば、別のコマンドを学ぶときもかなり理解しやすくなると思います。