はじめに
ゼロから学ぶRustという書籍で正規表現エンジンの実装を学んだものの、理解が足らないので、自分でまとめたいと思います。
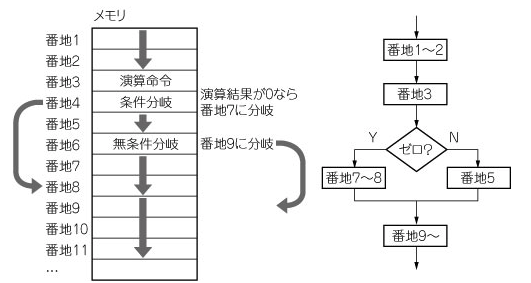
処理の流れ
正規表現は、例えば /ab*(a|c)+/ のような表現で文字列を表します。しかし、プログラムで処理するにはこの表現を扱いにくいです。そこで、まずはプログラムで扱いやすい形式に変換します。
その形式として使用されるのが、AST(Abstract Syntax Tree)です。ASTは正規表現の構造を木構造で表現するデータ構造です。ASTを作成することで、正規表現の解析やパターンマッチングのための処理を簡単に行うことができます。
次に、ASTを元にコード生成を行います。コード生成は、コンピュータが実際に実行する命令を生成するためのプログラムを記述する作業です。ASTを解析し、必要な命令や処理の手順を生成することで、正規表現を実際に処理するコードを生成することができます。
最後に、与えられた文字列に対して生成したコードを使用して正規表現に一致するかどうかを評価します。生成されたコードを実行し、与えられた文字列が正規表現のパターンに一致するかどうかを判定することが目的です。
これによって、正規表現を効果的に扱い、文字列のパターンマッチングや検索などの処理を行うことができます。
ASTへのParse
まずは正規表現をASTにparseします。
サンプルとしてab*(c|d)という正規表現を考えます。
ab*(c|d)のAST
Concat
|
---------------------------------
| | |
Literal('a') Repeat0(Literal('b')) or
|
-----------
| |
Literal('c') Literal('d')
この木構造を構造体で表すとプログラムで扱いやすくなります。
enum RegexAst {
Literal(char),
Concat(Vec<RegexAst>),
Or(Box<RegexAst>, Box<RegexAst>),
Repeat0(Box<RegexAst>), // 0回以上繰り返す
...他+とか?等
}
このような構造体を定義すると、ab*(c|d)のASTは、以下のように記述できます
Concat([
Literal('a'),
Repeat0(Literal('b')),
Or(
Concat([Literal('c')]),
Concat([Literal('d')])
)
])
コード生成
コード生成では、AST(Abstract Syntax Tree)を解析して、実際に正規表現を処理するためのコードを生成します。具体的には、正規表現を処理するための命令セットを定義し、それに基づいてコードを生成します。
まず、正規表現を処理するためのデータ構造として、正規表現レジスタマシンを定義します。レジスタマシンは、有限個のレジスタとプログラムカウンタ(命令の実行位置を示す)から構成されます。このレジスタマシンを使って正規表現の処理を実行します。
CPUの動作について以下のような図を見たことあると思いますが、つまりこの命令にあたる部分を定義するということです。
TechVillageより引用
使用する命令を定義します。レジスタマシンには以下の4つの命令があります:
- char: 文字のマッチングを行います。現在の文字と指定された文字が一致する場合、次の命令に進みます。
- match: 正規表現の一致を確認します。指定されたパターンと現在の文字列が一致する場合、次の命令に進みます。
- jump: 指定された位置にジャンプします。命令の実行位置を変更します。
-
split: 分岐を行います。2つの命令へのジャンプ先を指定し、それぞれの命令に進む可能性があります。
これらの命令を組み合わせて、正規表現の処理を表現します。ASTを解析し、各ノードに対応する命令を生成します。また、必要に応じてループや条件分岐などの制御構造も生成します。
この4つの命令だけで正規表現が評価できます。
サンプルの正規表現(ab*(c|d))をこの4つの命令だけで表すと以下のようになります。
0001: Char(a)
0002: Split 0003, 0005
0003: Char(b)
0004: Jump(0002)
0005: Split 0006, 0008
0006: Char(c)
0007: Jump(0009)
0008: Char(d)
0009: Match
左側の数字はPC(プログラムカウンタ)です。
評価
ちょっとわかりづらいかもしれませんが、先ほど生成したコードを1つずつ説明します。
-
まず、Char(a) 命令が実行され、現在の文字が 'a' と一致するかどうかを判定します。もし一致しない場合は、この正規表現とはマッチしません。一致している場合はPCを1つ増やして0002に飛びます。
-
一致する場合、Split 0003, 0005 命令が実行され、プログラムカウンタが 0003 と 0005 の2つの位置に分岐します。これにより、b* の部分が0回以上の繰り返しを表現します。どういうことかというとPCが0005を指定した場合は、特に0003がスキップされるので、'b'という文字の一致は評価されません。一方で、0003にとんだ場合には'b'の一致を評価します。一致している場合はPCを1つ増やすので0004に飛びます。0004の命令は0002に飛ぶという命令なので、再び0003と0005に分岐します。ここで再度0003が選ばれた場合には再び'b'の一致が評価されるため'b'が連続で評価されることになります。0005に飛ぶとこの分岐を抜けるので、結果的に
b*つまり'b'が0回以上繰り返しというのが評価されます。 -
0006と0008に分岐します。これにより、c または d のいずれか一方がマッチするようになります。0006 の位置では、Char(c) 命令が実行され、現在の文字が 'c' と一致するかどうかを判定します。一致した場合にはpcを次に進めて0007となるので0009にjumpし、終了です。一方、0008 の位置では、Char(d) 命令が実行され、現在の文字が 'd' と一致するかどうかを判定します。こちらもPCを1つ増やして最終的に、Match 命令が実行され、正規表現の一致が確認された場合にプログラムが終了します。
このように、上記の命令列によって正規表現 /ab*(c|d)/ のパターンが効率的に処理されます。各命令は正規表現の構造を反映しており、プログラムカウンタの制御によって適切な分岐や繰り返し処理が行われます。
具体的に評価はどのように行われるかというと、ループ文を使います。
例えばchar = xabdという文字列を評価する際には、
- char[0] == xなので、0001の処理で終了、次を確認
- char[1] == aなので、0001はOK。PCを1増やす。
- 0002において0003と0005に分岐するのでそれぞれ評価
- 0003において'b'が一致するので評価する文字をdにした上で0004にPCを増やす
上記のような流れで1文字ずつ評価します。
まとめ
正規表現たまに使いますが、自分で実装してみるのは面白かったです。
普段正規表現そんなに書かないので、いつもどうやって表すかわからなくなってたのですが、自分で実装すると結構理解しますね。