はじめに
つくったもの
コンソール上で動く対話型のダイスボットです。四則演算と変数、加算ダイス1が使えます。PLYライブラリを使用してオリジナルの演算子を実装しています。
開発の経緯
- Rubyで書かれているBCdiceをPythonに移植できないか試行錯誤する。
↓
- BCdiceのファイルの中に拡張子が
.yのファイルをみつける。
↓
- ググって、
lex/yaccの存在を知る。Pythonに移植されてないのか調べる。
↓
- PLYのことを知る。なら作るとなる。
PLYって?
コードを解説する前に、PLYがどういうものなのか簡単に解説します。
PLY(Python Lex-Yacc)は、lex/yaccというC言語のツールをPythonに移植したものです。lex/yaccは、字句解析・構文解析を行うツールです。
英語でたとえると、
字句解析は、入力された文にYouやHeなどが現れたら主語、isやreadなどが現れたら動詞に分類することです。
そのうえで、構文解析でS(主語) + V(動詞) + C(補語) + .(ピリオド)のように英語の語順として正しく並んでいるかどうかを分析します。
構文解析と字句解析を組み合わせることにより、オリジナルの構文やオリジナルの言語がつくれます。
C言語のlex/yaccについては、こちらのページが詳しいです。
PLYのインストール
$ pip install ply
pipコマンドでインストールします。Macの場合はpip3を使ってください。Python 2・3の両方に対応しています。
コード
lex(字句解析)をつくる
まずは字句解析を行うlex.pyをつくります。
トークンを定義する
トークンは文を分解したあとのパーツのようなものです。使用するトークンをタプルで括り、それぞれのトークンを定義します。
今回は変数名、数字、四則演算の演算子、等号、かっこ、ダイス演算子を指定しています。
import ply.lex as lex #lexをインポート
tokens = ( #トークンを指定
'NAME',
'NUMBER',
'PLUS',
'MINUS',
'TIMES',
'DIVIDE',
'EQUALS',
'LPAREN',
'RPAREN',
'DICE'
)
変数で定義する
トークンの内容を定義する方法は2つあります。変数と関数です。
t_トークン名の変数で、それぞれのトークンの内容を正規表現で定義します。
t_PLUS = r'\+' #トークンの内容を定義
t_MINUS = r'-'
t_TIMES = r'\*'
t_DIVIDE = r'/'
t_EQUALS = r'='
t_LPAREN = r'\('
t_RPAREN = r'\)'
t_DICE = r'D|d' #⬅ダイス演算子
- 無視する要素を定義する
t_ignoreという特殊な変数で、文を分解するときに無視する要素を定義します。ここではスペースとタブを指定しています。
また、t_ignore_COMMENTでコメントを定義します。
t_ignore = ' \t'
t_ignore_COMMENT = r'\#.*'
関数で定義する
トークンを定義するときには関数を使うこともできます。これは、解析のときに処理を行う場合に有用です。
t_トークン名の関数を定義します。引数には必ずLexTokenオブジェクトが渡されます。
def t_NUMBER(t): #数の定義
r'\d+'
t.value = int(t.value) #整数型にする
return t
def t_NAME(t): #変数名の定義
r'^[a-zA-Z][a-zA-Z0-9]*'
return t
returnをしない場合、そのトークンは無視されます。ですから、さきほどのt_ignore_COMMENTは
def t_COMMENT(t):
r"""\#.*"""
pass
のようにも定義できます。
改行を定義する
デフォルトではlexerは行数を数えないので、t_newlineを定義して数えさせます。
def t_newline(t):
r"""\n+"""
t.lexer.lineno += t.value.count("\n")
エラーを定義する
エラーが起きた場合の処理を定義します。print文を表示したあと、トークンの処理をスキップしています。
def t_error(t):
print("Illegal character '%s'" % t.value[0])
t.lexer.skip(t)
デバックしてみる
lexerをビルドしたあと、プログラムの最後にデバック用のコードを書きます。
lexer = lex.lex() #lexerをビルド
data = '''
3 + 4 * 10
(2 + 5)/ 3
2 D 4 + 1
'''
lexer.input(data) #dataを読み込む
if __name__ == '__main__':
while True:
tok = lexer.token() #トークンに分解する
if not tok:
break
print(tok)
実行結果
LexTokenオブジェクトの引数はそれぞれ(トークンの種類,実際の文字列,行数,何番目の文字か)です。ちゃんと数字が整数型に変換されているのがわかります。
LexToken(NUMBER,3,2,2)
LexToken(PLUS,'+',2,4)
LexToken(NUMBER,4,2,6)
LexToken(TIMES,'*',2,8)
LexToken(NUMBER,10,2,10)
LexToken(LPAREN,'(',3,13)
LexToken(NUMBER,2,3,14)
LexToken(PLUS,'+',3,16)
LexToken(NUMBER,5,3,18)
LexToken(RPAREN,')',3,19)
LexToken(DIVIDE,'/',3,20)
LexToken(NUMBER,3,3,22)
LexToken(NUMBER,2,4,24)
LexToken(DICE,'D',4,26)
LexToken(NUMBER,4,4,28)
LexToken(PLUS,'+',4,30)
LexToken(NUMBER,1,4,32)
yacc(構文解析)をつくる
続いて構文解析を行うyacc.pyをつくります。
演算子をつくる
優先順位を決める
さきほど定義したトークンをインポートし、precedenceで計算の優先順位を決めます。タプルの下のトークンほど優先順位が高いです。
import ply.yacc as yacc #yaccをインポート
from lex import tokens #自作のトークンをインポート
precedence = ( #計算の優先順位を決める
('left', 'PLUS', 'MINUS'),
('left', 'TIMES', 'DIVIDE'),
('right', 'UMINUS'),
('right', 'DICE')
)
処理のルールを決める
構文解析の処理は関数で記述します。
関数名はかならずp_から始めてください。トークン名である必要はありません。引数にはルールで定義した記号の配列が渡されます。左から順番にインデックスが対応しています。
構文解析のルールは関数の一行目にドキュメントで定義します。ルールは非終端記号 : 非終端記号または終端記号の組み合わせで記述します。
def p_expression_plus(p):
"""expression : expression PLUS expression"""
#非終端記号 : 非終端記号 終端記号 非終端記号
# p[0] p[1] p[2] p[3]
p[0] = p[1] + p[3]
また、一番最初に定義してある関数の非終端記号が開始記号です。以下の場合だとstatementが開始記号になります。
def p_statement_expr(p):
"""statement : expression"""
# これ⬆
p[0] = p[1]
def p_expression_plus(p):
"""expression : expression PLUS expression"""
p[0] = p[1] + p[3]
ルールを分岐させれば、複数のトークンを一つの関数で処理することができます。|(パイプ)でルールを区切り、下のように書けます。
def p_expression_binop(p):
# p[2]
"""expression : expression PLUS expression
| expression MINUS expression
| expression TIMES expression
| expression DIVIDE expression"""
if p[2] == '+':
p[0] = p[1] + p[3]
elif p[2] == '-':
p[0] = p[1] - p[3]
elif p[2] == '*':
p[0] = p[1] * p[3]
elif p[2] == '/':
p[0] = p[1] / p[3]
さらに、四則演算以外の演算子も作っていきます。
def p_expression_uminus(p): #負の数
"""expression : MINUS expression %prec UMINUS"""
p[0] = -p[2]
def p_expression_group(p): #かっこ
"""expression : LPAREN expression RPAREN"""
p[0] = p[2]
数字についての処理もしなければなりませんので、関数を追加します。
def p_expression_number(p):
"""expression : NUMBER"""
p[0] = p[1]
変数をつくる
変数は辞書型を使い、変数名と値の組み合わせで管理します。関数の定義の前にnamesを追加します。
names = {}
変数を定義するときの処理の関数を定義します。これは開始記号で始めてください。
names = {}
def p_statement_assign(p):
"""statement : NAME EQUALS expression"""
names[p[1]] = p[3]
また、変数を使うときの処理の関数も定義します。
def p_expression_name(p):
"""expression : NAME"""
try:
p[0] = names[p[1]]
except LookupError:
print("Undefined name \"%s\"" % p)
p[0] = 0
エラーを処理する
エラーが起きた場合はprint文を表示するようにします。
def p_error(p):
print("Syntax error in input")
ダイスを実装する
randomモジュールをインポートしてから、ダイス演算子の処理をp_expression_binopに追加します。
import random
#...
def p_expression_binop(p):
"""expression : expression PLUS expression
| expression MINUS expression
| expression TIMES expression
| expression DIVIDE expression
| expression DICE expression"""
if p[2] == '+':
p[0] = p[1] + p[3]
elif p[2] == '-':
p[0] = p[1] - p[3]
elif p[2] == '*':
p[0] = p[1] * p[3]
elif p[2] == '/':
p[0] = p[1] / p[3]
elif p[2] == 'D' or p[2] == 'd':
r = 0
for x in range(p[1]):
r += random.randint(1, p[3])
p[0] = r
続いて、yacc()を使ってparaserオブジェクトを作成し、parse()で構文解析を行います。
最後に実際に稼働するようにします。今回はwhile文でずっと動き続けるようにしました。
yacc.yacc()
def main():
while True:
try:
data = input("[DiceBot]> ")
except EOFError:
break
result = yacc.parse(data)
print(" [%s] -> " % data + str(result))
if __name__ == '__main__':
main()
動作
ちゃんと動いてくれました。終了の処理は定義していないので、プログラムを終了するかエラーを起こすまで延々と問いかけてきます。
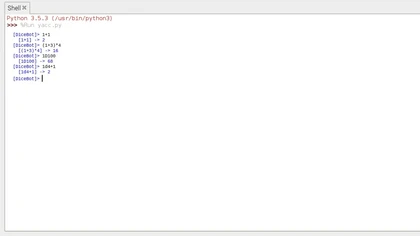
コード全文
GitHubにもyacc.pyからmainを切り離したものをあげています。
lex.py
import ply.lex as lex
tokens = (
'NAME',
'NUMBER',
'PLUS',
'MINUS',
'TIMES',
'DIVIDE',
'EQUALS',
'LPAREN',
'RPAREN',
'DICE',
)
t_PLUS = r'\+'
t_MINUS = r'-'
t_TIMES = r'\*'
t_DIVIDE = r'/'
t_EQUALS = r'='
t_LPAREN = r'\('
t_RPAREN = r'\)'
t_DICE = r'D|d'
t_ignore = ' \t'
t_ignore_COMMENT = r'\#.*'
def t_NUMBER(t):
r'\d+'
t.value = int(t.value)
return t
def t_NAME(t):
r'^[a-zA-Z][a-zA-Z0-9]*'
return t
def t_newline(t):
r"""\n+"""
t.lexer.lineno += t.value.count("\n")
def t_error(t):
print("Illegal character '%s'" % t.value[0])
t.lexer.skip(t)
lexer = lex.lex()
data = '''
3 + 4 * 10
(2 + 5)/ 3
2 D 4 + 1
'''
lexer.input(data)
if __name__ == '__main__':
while True:
tok = lexer.token()
if not tok:
break
print(tok)
yacc.py
import ply.yacc as yacc
from dicelex import tokens
import random
precedence = (
('left', 'PLUS', 'MINUS'),
('left', 'TIMES', 'DIVIDE'),
('right', 'UMINUS'),
('right', 'DICE')
)
names = {}
def p_statement_assign(p):
"""statement : NAME EQUALS expression"""
names[p[1]] = p[3]
def p_statement_expr(p):
"""statement : expression"""
p[0] = p[1]
def p_expression_binop(p):
"""expression : expression PLUS expression
| expression MINUS expression
| expression TIMES expression
| expression DIVIDE expression
| expression DICE expression"""
if p[2] == '+':
p[0] = p[1] + p[3]
elif p[2] == '-':
p[0] = p[1] - p[3]
elif p[2] == '*':
p[0] = p[1] * p[3]
elif p[2] == '/':
p[0] = p[1] / p[3]
elif p[2] == 'D' or p[2] == 'd':
r = 0
for x in range(p[1]):
r += random.randint(1, p[3])
p[0] = r
def p_expression_uminus(p):
"""expression : MINUS expression %prec UMINUS"""
p[0] = -p[2]
def p_expression_group(p):
"""expression : LPAREN expression RPAREN"""
p[0] = p[2]
def p_expression_number(p):
"""expression : NUMBER"""
p[0] = p[1]
def p_expression_name(p):
"""expression : NAME"""
try:
p[0] = names[p[1]]
except LookupError:
print("Undefined name \"%s\"" % p)
p[0] = 0
def p_error(p):
print("Syntax error in input")
yacc.yacc()
def main():
while True:
try:
data = input("[DiceBot]> ")
except EOFError:
break
result = yacc.parse(data)
print(" [%s] -> " % data + str(result))
if __name__ == '__main__':
main()
おわりに
Pythonで動くTRPG用のツールがほしいと思って作り始めましたが、判定機能をつけていないので実質役に立ちません。そのうち作ったら記事にしようかと思っています。
プログラムが完成して、Qiitaに投稿しようと決めてから記事ができるまで6日ほどかかり、毎日投稿されている方は大変だなと感じました。とりあえずこれからも頑張っていきます。
参考にしたもの
PythonでPPAP(ペンパイナッポーアッポーペン)をイメージしたオリジナル言語 「PPAPScript」を作ってみた - Qiita
PLY (Python Lex-Yacc)でLexical Analysis (字句解析) - プログラミングと慶應通信
bison マニュアルの中間記法電卓 - noritsugu's diary
dabeaz/ply: Python Lex-Yacc - GitHub
-
TRPGでよく使う
2D6や1D100のような、振ったダイスの出目をすべて足し合わせるダイスのこと。 ↩