やりたいこと
広告の画像のテキストには媒体によって20%ルールというのがあります。
これらと他の規定やらを機械的にまとめてチェックできたら広告業界ぽいネタになりますよね。
画像内テキスト占有率とは

こんな画像があったときに、左の「こうこく」と下の「オプテクノロジー」がテキストです。
このテキストが画像全体をどの程度埋めてしまっているかが画像内のテキスト占有率になります。
まともに配信されるには20%以下である必要があります。
Cloud Vision API
API登録
適宜調べてやりましょう。
ドキュメントテキスト検出API
お試し https://cloud.google.com/vision/docs/drag-and-drop

オラ テクノロジー
セーフサーチAPI
アダルト要素もついでにチェック
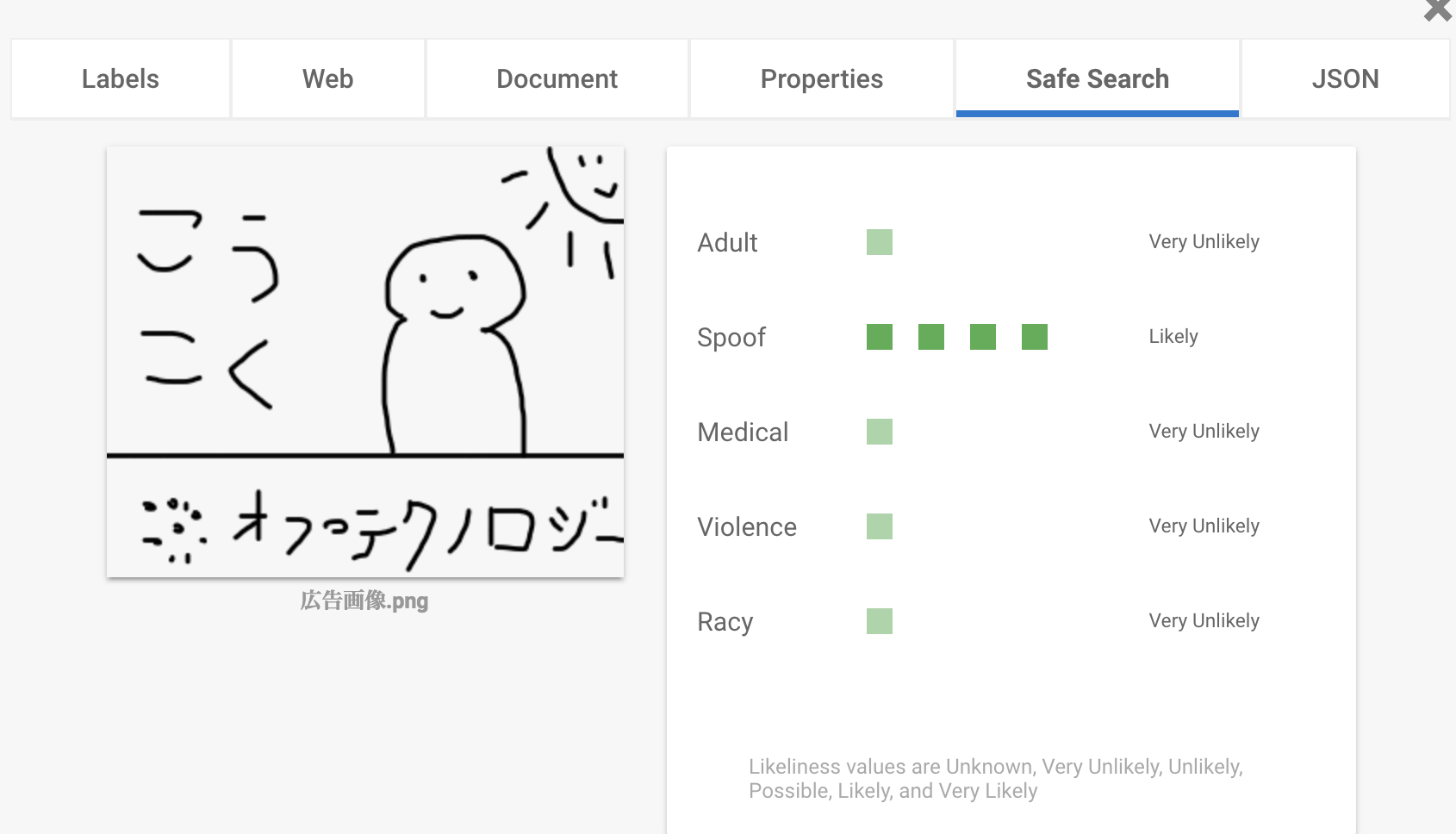
Spoof
テキスト占有率を計算
pip
$ pip install google-cloud-vision
$ pip install opencv-python
グリッドツール
20%ルールのチェックには グリッドツール を使用するのが一般的であり、蓋を開けてみれば画像をグリッドに分けてテキストがかかってるマスを塗りつぶすとかすごく温かみがある方法が取られています。
 押せば押すほど黒くなってびっくりした
押せば押すほど黒くなってびっくりした
コード化
APIのレスポンスにはこんな感じで見つけたテキストのバウンディングボックスの座標ぽいのが入ってます。
{
"locale": "ja",
"description": ":: オラテクノロジー\n「うく\n「)()\n",
"boundingPoly": {
"vertices": [
{
"x": 10,
"y": -10
},
{
"x": 302,
"y": -10
},
{
"x": 302,
"y": 244
},
{
"x": 10,
"y": 244
}
]
}
}
たぶんこれで計算できるはず
import io
import os
import sys
import click
import cv2
from google.cloud import vision
def client_account_json():
json_path = 'json' # 使う時はAPIの認証をこのあたりでやってね
return vision.ImageAnnotatorClient.from_service_account_json(json_path)
def text_rule_check(path, name):
client = client_account_json()
# [START vision_python_migration_document_text_detection]
with io.open(path, 'rb') as image_file:
content = image_file.read()
image = vision.types.Image(content=content)
response = client.document_text_detection(image=image)
orig_image = cv2.imread(path)
img = orig_image.copy()
boxes = []
for page in response.full_text_annotation.pages:
for block in page.blocks:
for paragraph in block.paragraphs:
for word in paragraph.words:
x1 = word.bounding_box.vertices[0].x
y1 = word.bounding_box.vertices[0].y
x2 = word.bounding_box.vertices[2].x
y2 = word.bounding_box.vertices[2].y
img = cv2.rectangle(img, (x1, y1), (x2, y2), (0, 255, 0), 1)
boxes.append((x1, y1, x2, y2))
cv2.imwrite(f'{name}_box.jpg', img)
height, width, channel = orig_image.shape
cnt = 0
step = 5
step_x = int(width / step)
step_y = int(height / step)
for y in range(0, height, step_y):
y2 = y + step_y - 1
for x in range(0, width, step_x):
x2 = x + step_x - 1
for b in boxes:
if (x <= b[2] and b[0] <= x2) and (y <= b[3] and b[1] <= y2):
cnt += 1
break
print(f"画像内の文字占有率: {int(cnt / (step * step) * 100)}%")
@click.command()
@click.option('--identify', '-i', help='file name')
def main(identify):
file_name = os.path.join(
os.path.dirname(__file__),
f'{identify}')
text_rule_check(file_name, identify.split('.')[0])
detect_safe_search(file_name)
if __name__ == '__main__':
sys.exit(main())
結果
画像内の文字占有率: 64%
思ったより多いな
おわりに
何を誤検出したかはおいておいて、とりあえず画像内のテキスト占有率のチェックが自動でできるようになりました。
めでたし...めでたし......