今回はKaggleで公開されている「Face Mask Dataset」を使って物体検出モデルを作成してみます!
YOLOv8についてはこちら
ultralytics/ultralytics - GitHub
今回使用するデータセットはこちらからダウンロードできます。
Face Mask Dataset (YOLO Format)

データセットの準備
ディレクトリ構成の修正
YOLOv8はpipから導入することができ、非常に簡潔なコードで学習を行うことができます。しかし、デフォルトの設定を流用して簡単に学習を行うには、開発元のUltralytics社の指定する形式(ディレクトリ構成)になっていないとエラーが起きるので注意が必要です。
参考:Ultralytics YOLO format
今回使用するデータセットはimagesディレクトリ内にラベルファイルも一緒に入っている構造になっているため、次のコードで画像とラベルをそれぞれ別のディレクトリに分けます。
# 元のデータセットの構成
dataset
|--images
| |--classes.txt
| |--test
| | |--NUZZ...VOMBHU.jpg
| | |--NUZZ...VOMBHU.txt
| | |--youn...UEZG6HJ.jpg
| | |--youn...UEZG6HJ.txt
...
| |--train
| | |---1x_1.jpg
| | |---1x_1.txt
| | |---I1_MS...eckoM.jpeg
| | |---I1_MS...eckoM.txt
...
| |--valid
| | |--KZJI...F02yshdNs.jpeg
| | |--KZJI...F02yshdNs.txt
| | |--news_...1580213989065.jpg
| | |--news_...1580213989065.txt
...
|--test.txt
|--train.txt
|--valid.txt
# create_datasets.py
import os
import shutil
src_dirs = [f"dataset/images/{dirname}" for dirname in ["test", "train", "valid"]]
dst_dirs_texts = ["datasets/labels/test", "datasets/labels/train", "datasets/labels/valid"]
dst_dirs_images = ["datasets/images/test", "datasets/images/train", "datasets/images/valid"]
image_type = (".jpg", ".jpeg", ".png", ".JPG", ".JPEG", ".PNG")
for dst in dst_dirs_texts + dst_dirs_images:
if not os.path.exists(dst):
os.makedirs(dst)
for src, dst_text, dst_image in zip(src_dirs, dst_dirs_texts, dst_dirs_images):
for filename in os.listdir(src):
src_path = os.path.join(src, filename)
if filename.endswith(".txt"):
shutil.copy(src_path, dst_text)
print(f"Copied {src_path} -> {dst_text}")
elif filename.endswith(image_type):
shutil.copy(src_path, dst_image)
print(f"Copied {src_path} -> {dst_image}")
# 実行結果
# datasets
# |--images
# | |--test
# | | |--NUZZ...VOMBHU.jpg
# | | |--youn...UEZG6HJ.jpg
# ...
# | |--train
# | | |---1x_1.jpg
# | | |---I1_MS...eckoM.jpeg
# ...
# | |--valid
# | | |--KZJI...F02yshdNs.jpeg
# | | |--news_...1580213989065.jpg
# ...
# |--labels
# | |--test
# | | |--NUZZ...VOMBHU.txt
# | | |--youn...UEZG6HJ.txt
# ...
# | |--train
# | | |---1x_1.txt
# | | |---I1_MS...eckoM.txt
# ...
# | |--valid
# | | |--KZJI...F02yshdNs.txt
# | | |--news_...1580213989065.txt
# ...
参考までに...
私が引っかかったエラー↓
(ディレクトリの構成が違ったことでエラーが起きていましたorz)
train: No labels found in /content/yolo-sample/datasets/labels/train.cache, can not start training. See https://docs.ultralytics.com/datasets/detect for dataset formatting guidance.
'No labels found' after 'Caching labels' #1024 - GitHub
学習
学習するためのコードは非常にシンプルです。
from ultralytics import YOLO
# Load a model
model = YOLO('yolov8n.yaml') # build a new model from YAML
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
model = YOLO('yolov8n.yaml').load('yolov8n.pt') # build from YAML and transfer weights
# Train the model
results = model.train(data='coco128.yaml', epochs=100, imgsz=640)
様々な設定で学習を試せるように、次のようなコードを作成しました。
# train.py
import configparser
import logging
from ultralytics import YOLO
class ConfigLoader:
def __init__(self, config_path: str) -> None:
"""
指定されたパスから設定を読み込みます。
config_path: .iniファイルまでのパス
"""
self.path = config_path
self.config = configparser.ConfigParser()
# もし設定ファイルが指定されたパスになければエラーを発出します
if not self.config.read(self.path, encoding="utf-8"):
raise FileNotFoundError(f"'{self.path}' file not found or failed to load!")
def get_config_sections(self) -> list:
"""
設定ファイルに記載されたセクション名を取得します。
:return: セクション名が入ったリスト
"""
return self.config.sections()
class TrainYOLO:
def __init__(self, config_path) -> None:
self.config = ConfigLoader(config_path)
self.set_logger()
def set_logger(self):
# ロガーを設定
formatter = logging.Formatter(
'%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
self.logger = logging.getLogger(__name__)
self.logger.setLevel(logging.DEBUG)
console_handler = logging.StreamHandler()
console_handler.setFormatter(formatter)
self.logger.addHandler(console_handler)
file_handler = logging.FileHandler("train.log")
file_handler.setFormatter(formatter)
self.logger.addHandler(file_handler)
def train(self):
# 設定ファイルにあるセクション名を読み込み
sections = self.config.get_config_sections()
settings = self.config.config
for section in sections:
yaml = settings[section]["model_yaml"]
initial_weight = settings[section]["initial_weight"]
data_yaml = settings[section]["data_yaml"]
epoch_num = int(settings[section]["epochs"])
image_size = int(settings[section]["image_size"])
try:
self.logger.info("Loading weight to start training")
model = YOLO(yaml).load(initial_weight)
self.logger.info("start training the model")
model.train(data=data_yaml, epochs=epoch_num, imgsz=image_size)
except BaseException as e:
self.logger.error(e)
def main():
yolo = TrainYOLO(config_path="config.ini") # 設定ファイルのパスを指定
yolo.train()
if __name__ == "__main__":
main()
設定ファイルはこのような感じで作成しました。
各セクションで設定を様々な値にして一気に試すことができます。
[DEFAULT]
model_yaml = yolov8n.yaml
initial_weight = yolov8n.pt
data_yaml = data.yaml
epochs = 200
image_size = 640
[YOLOv8x] # セクション名
model_yaml = yolov8x.yaml
initial_weight = yolov8x.pt
epochs = 200
image_size = 640
学習が終わると学習状況がわかるデータが一緒に自動的に生成されています(めっちゃ便利!!!!)
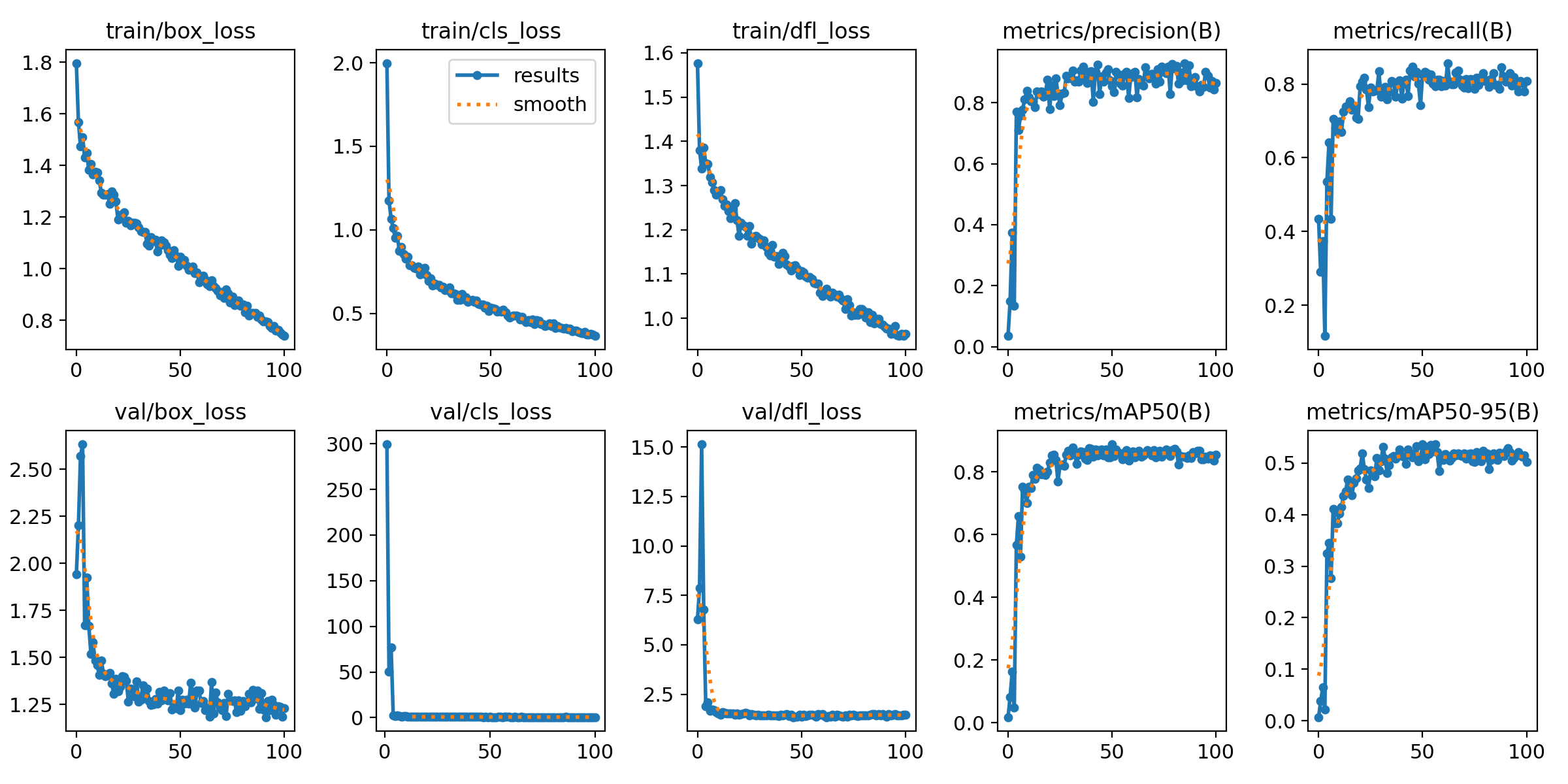
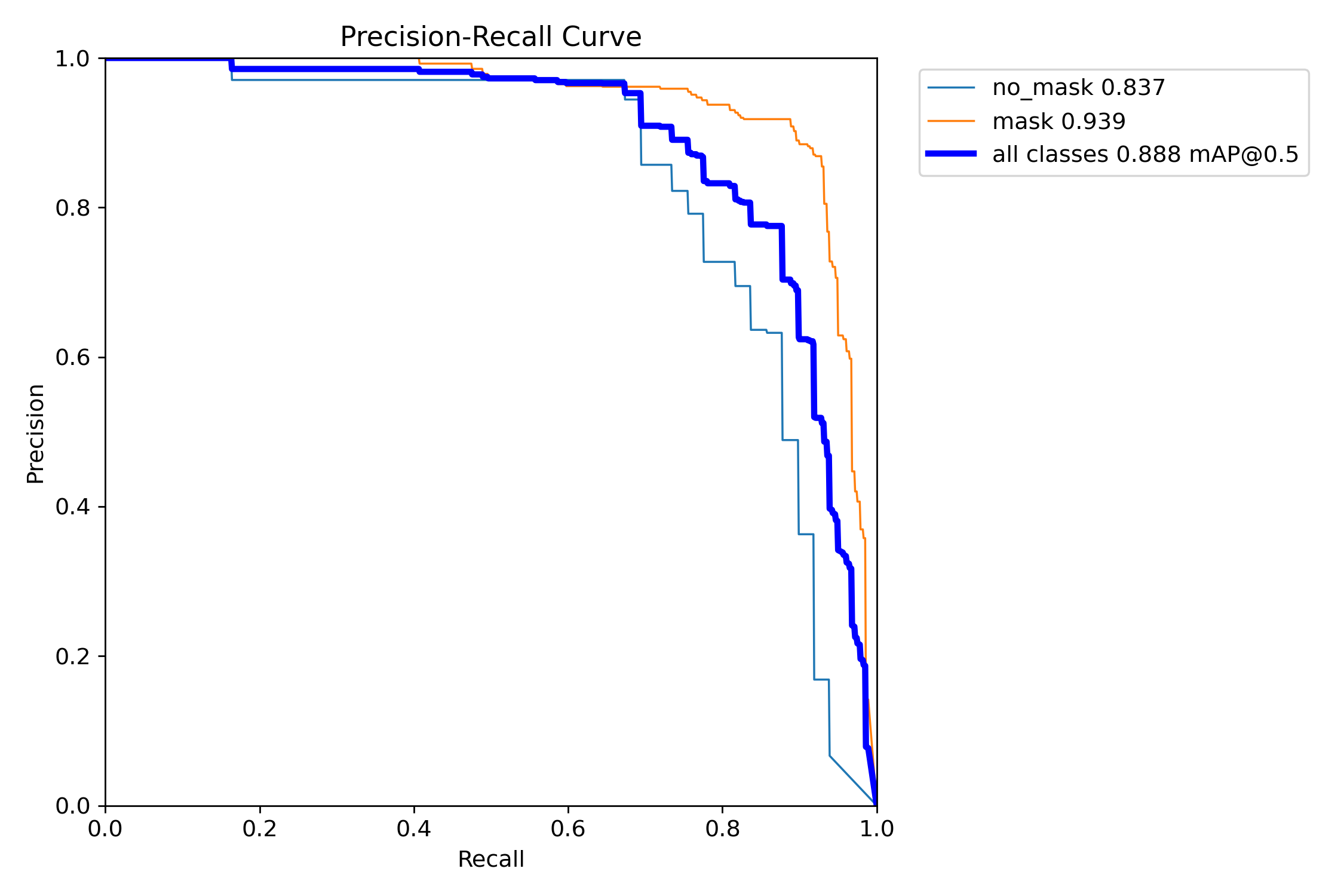
検出
検出に必要なコードも非常にシンプルです。
from PIL import Image
model = YOLO("./runs/detect/train/weights/best.pt")
results = model("./pexels-brett-sayles-5382987.jpg")
for r in results:
im_array = r.plot() # plot a BGR numpy array of predictions
im = Image.fromarray(im_array[..., ::-1]) # RGB PIL image
im.show() # show image
im.save('results.jpg') # save image
検出例
左が元画像、右が検出結果です。
画像はPexelsから持ってきました。


ここまで読んでいただきありがとうございました。
(環境構築等については需要があれば後日追記するかもしれません..)