はじめに
あまりAWS触ったことがない人向けに、サーバーレスアーキテクチャの勉強会をすることになりました。
座学だけやっても身につかないことはここ1年で感じていましたし、AWS日本語ハンズオンやQiita/Zennは全体的に説明が丁寧すぎて苦労しないので、独自のハンズオンを作ってみようと思いました。
この記事の趣旨
そこで本記事では、初学者が苦労して学ぶハンズオンを目指しています。
自分で調べて、トライ&エラーして知識を学んでいくという感じです。
初学者向けの研修としても、チューターが何人かいればサポートしながら動くものが作れることで、知識だけでなく達成感も得られると思います。
この記事は勉強会の結果をフィードバックして、更新していきたいと思います。
ハンズオン要件編
要件
今回のハンズオンでは図書貸出アプリを作ります。
イメージしやすいと思いますが、図書館で管理する本を利用者に貸し出す、返却するなどを行います。
基本的な要件は以下とします。
- 利用者は、図書館で扱う本の一覧を取得できる
- 利用者は、貸出可能な本を借りられる
- 利用者は、借りている本を返すことができる
追加要件について
別途追加要件を増やして機能を増やすなど、学習者のペースに合わせて変更してください。 例えば、こんな要件を追加できます。- 管理者は、購入した本を新規に追加できる
- 利用者は、貸出可能な本の一覧を取得できる(基本要件から制限)
- 利用者が貸出可能な本は、同時に5冊までである
- 管理者は、図書館で扱うすべての本の一覧を取得できる
- システムは、貸出期限を過ぎている図書の利用者に催促メールを送信できる
- 利用者は、サインアップしてユーザー登録し、アプリにログインできる
基本編で考慮しないこと
今回のハンズオンは1-2時間くらいで動作確認ができるところまでを考えています。
簡単なハンズオンのため、単体試験や準正常/異常処理などは省きます。
これらは追加課題としてやってみてください。
開発環境
AWS環境さえあれば手軽に始められるCloud9を想定しています。
もちろんVSCodeなどでローカルで開発してもよいです。
またAWS環境は、以下アーキテクチャのサービス権限だけでなく、Cloud9系(背後でEC2が動いたりするのでそれも)やRole系も許可されたユーザーをご準備ください。
アーキテクチャ
アーキテクチャは、サーバーレスアーキテクチャを採用します。
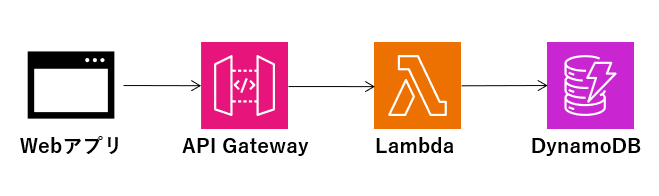
| サービス | 内容 | 実装内容 | 備考 |
|---|---|---|---|
| Webアプリ | 図書館アプリのフロントエンド | APIコールして画面表示 | StreamlitでもAmplifyでも |
| API Gateway | フロントエンドとLambdaを結合 | REST APIでパス設定とLambdaプロキシ統合 | 認証などは追加課題 |
| Lambda | データベースの出し入れ | aws sdkを使ったDBアクセス | CS的な内容はまずは問わない |
| DynamoDB | 図書データベース | NoSQLテーブル作成 | PK/SKのテーブル設計は追加課題 |
使用言語
Lambdaではコーディング作業が発生しますが、ここではPythonとします。
そのため、フロントエンドもstreamlitを前提とします。
フロントエンドをTypeScriptなどで記述される方は、node.jsなど周りの状況に合わせて採用してください。
使用言語は対応言語であれば、何を使っても構いません。
ハンズオン本編
①DynamoDBを構築する
DynamoDBでテーブルを作ります。
AWSコンソール(通称マネコン)の検索窓からDynamoDBと検索して開いてください。
テーブル作成にあたり以下の要件とします。
| 項目 | 内容 | 備考 |
|---|---|---|
| テーブル名 | Tbl_Book | 適当な名称でOKです |
| PK(プライマリーキー) | bookId | 各本が持つユニークなID |
| SK(ソートキー) | なし | 基本編では利用しない |
作成するテーブルは以下のように定義されている前提です。
ここに加えて、返却期限やデータ更新日時などを追加しても構いません。
| 論理名 | 物理名 | データ型 | 説明 |
|---|---|---|---|
| 図書ID | bookId | string | 各本が持つユニークなID |
| 図書名 | bookName | string | 本のタイトル |
| 著者名 | author | string | 著者名 |
| 貸出状態 | enable | boolean | 貸出可(true),貸出中(false) |
| 貸出中ユーザー | userId | string | 貸出中のユーザーID(貸出可の場合は空) |
テーブル名やPK/SK以外の項目はデフォルトで構いません。
テーブルが作成できたら、自分でテーブルを追加してみてデータセットを作成してみましょう。
設定した図書ID以外は上記テーブル定義に従い、適当な値を入れてみてください。
②ロールを作成する
Lambdaを作成する前にロールを作成します。
このロールは、これから作成するLambdaにDynamoDBにアクセスできる権限を与えるためのものです。
マネコンからIAMを検索し、左ペインにあるロールを開き、「ロールを作成」から新しいロールを作成します。
以下設定を選択していってください。他はデフォルトで構いません。
| 項目 | 内容 |
|---|---|
| 信頼されたエンティティタイプ | AWSのサービス |
| ユースケース | Lambda |
| 許可ポリシー | ・DynamoDBにフルアクセスできる権限 ・CloudWatchLogsに書き込める権限 |
最後に信頼ポリシーがJSON形式で表示されます。
設定した信頼されたエンティティタイプやユースケースがどのように設定されているのか確認してみてください。
(CloudWatchLogsへのWrite権限を追記し忘れていました)
ロール名は適当でよいですが、つけたロール名はメモしておきましょう。
③Lambda関数を作成する
それではアプリの機能を担うLambda関数を作成します。
マネコンからLambdaを検索し、「関数の作成」を選択します。
以下を設定したら、「関数の作成」をクリックします。
| 項目 | 内容 |
|---|---|
| 関数の作成 | 一から作成 |
| 関数名 | 適当な名前 |
| ランタイム | 言語に適したもの(最新がオススメ) |
| アーキテクチャ | どちらでもよい |
| デフォルトの実行ロールの変更 | 「既存のロールを使用する」で作成したロールを選択 |
④Lambda関数でコーディングする
Lambda関数ができたらコーディングしてみます。
初期はHello Worldが書いてありますので、テストを実行して結果を確認します。
Lambda関数をテストする
Lambdaのコード記述部分の上にあるTestをクリックすると、テストイベントを設定できます。
まずはイベント名だけを適当につけて保存し、テストを実行してみましょう。
これだけで、Hello Worldが実行できます。
boto3を使ってDynamoDBにアクセスする
boto3というAWS SDK for Pythonがあり、boto3でDynamoDBへアクセスしてデータを取得したり、データを挿入したりできます。
Lambdaでは最初からboto3がインストールされた状態ですので、import boto3だけでboto3を使うことができます。
作ったテーブルにアクセスするためのインスタンスを作成するコードは以下の通りです。
import boto3
dynamodb = boto3.resource('dynamodb') # dynamoDBインスタンス
table = dynamodb.Table('Tbl_Book') # テーブルインスタンス
インスタンス化したテーブルに対してメソッドを使うことで、テーブル操作ができます。
基本的なメソッドは以下の通りです。
| メソッド | 説明 |
|---|---|
| get_item | テーブルからを取得する |
| put_item | テーブルにレコードを追加する |
| delete_item | レコードを削除する |
| scan | テーブルから全レコードを取得する |
基本編はPKのみのテーブルのため、queryは省略しています。
PK-SKのテーブルやGSIを設定したテーブルではqueryを使うケースは非常に多いです。
また、update_itemもよく使いますが、やや複雑なので省略します。
以下に各メソッドの使い方などはまとめています。
https://qiita.com/_YukiOgawa/items/c0c9ebbe4813ab9f52ad
まずはscanあたりを使って、DynamoDBに入れたデータが取得できることを確認してください。
関数は1つ作ったら次のAPI Gatewayに一旦進んでも構いません。
⑤API Gatewayを設定する
作ったLambdaをWebアプリから呼び出すために、API Gatewayを設定します。
マネコンから"API Gateway"を検索し、以下設定に沿ってAPIを作成していきます。
| 項目 | 内容 |
|---|---|
| APIタイプを選択 | REST API |
| APIの詳細 | 新しいAPI |
| API名 | 適当な名前 |
| APIエンドポイントタイプ | リージョン |
APIができたら、左ペインの「リソース」を選択し、「リソース」を作っていきます。
リソースでは、APIのパスとメソッドの2つを定義していきます。
パス
パスでは、APIをコールするURIを定義します。
要素ごとにスラッシュで区切っていき、パスの中に変数(パスパラメータ)を入れることができます。
まずは本の一覧取得を考えるので、booksのリソースを作成してください。
この時CORS(クロスオリジンリソース共有)のチェックはつけるようにしてください。
メソッド
メソッドは、RESTful APIにおける操作内容を定義します。
GET,POST,PUT,DELETEの4つが基本メソッドとしてあります。
まずは本の一覧取得を考えるので、先ほど作ったbooksの中にGETメソッドを作ります。
「メソッドの作成」を選択し、以下を設定します。
| 項目 | 内容 |
|---|---|
| メソッドタイプ | GET |
| 統合タイプ | Lambda関数 |
| Lambdaプロキシ統合 | 有効 |
| Lambda関数 | 先ほど作ったLambda関数 |
作成したら「APIをデプロイ」をクリックし、適当な新しいステージを作ってデプロイします。
API Gatewayでは、デプロイして初めてAPIが更新されることに注意してください。
Lambdaプロキシ統合にすると、Lambdaからの応答は既定のJSON形式である必要があります。
Lambdaのreturn内容が以下になっているかをご確認ください。
特にbodyはJSON形式のため、json.dumps()でPython辞書型からJSON型への変換するようにしてください。
{
"isBase64Encoded" : "boolean",
"statusCode": "number",
"headers": { ... },
"body": "JSON string"
}
デプロイ後
左ペインから「ステージ」を選択するとデプロイしたステージがあり、URLを呼び出すにパスが記載されています。
このパスがAPIのエンドポイントとなります。
ここまで来たら早速APIをコールしてみましょう。
APIのコールはcurlと呼ばれるコマンドが便利です。
Cloud9などのターミナルから以下コマンドを呼んでみましょう。
curl https://xxxxxx.execute-api.ap-northeast-1.amazonaws.com/api/books
LambdaでTestした結果と同じような結果が返ってくれば成功です。
また、今後API数を増やしたり確認頻度が多い場合は、PostmanなどのAPI試験ツールを使うと便利です。
curlがうまくいかない場合は、CloudWatch Logsでログがどのように出ているか確認しましょう。
CloudWatch Logsがない場合は、LambdaにCloudWatch Logsの書込み許可ポリシーのあるロールがアタッチされているか確認してください。
CloudWatch Logsのログが正常な場合は、API Gatewayでのエラーではないかを確認してみてください。
API Gatewayのログを有効にしておくと、CloudWatch Logsにログが出ます。
この時、API Gatewayにもロールが必要なので、ロールを作成しておきましょう。
⑥Webアプリを作る
最後にAPIをフロントエンドから呼び出して、結果を表示するようにします。
今回はCloud9上でstreamlitというPythonモジュールを使います。
Cloud9環境を作る
マネコンからCloud9を検索し、開いてください。
最初は環境がないので、「環境を作成」から始めましょう。
設定は基本デフォルトで問題ありません。
| 項目 | 内容 |
|---|---|
| 環境タイプ | 新しいEC2インスタンス |
| インスタンスタイプ | t2.micro |
| プラットフォーム | Amazon Linux 2023 |
作成したCloud9環境が開けない場合、VPC設定がうまくいっていない場合が多いです。
選択したVPCやサブネットが制限のあるものになっていないかを確認してください。
モジュールをインストールする
Cloud9には入れたら、ターミナルからstreamlitをインストールします。
pip install streamlit
他にも必要なモジュールがあれば、必要に応じてpipでインストールしてください。
今回の場合はrequestsというAPIを呼び出すためのモジュールも使うので、インストールしておいてください。
streamlitでWebサーバを立てる
streamlitを使ってWebアプリ部分を作成していきます。
streamlitの詳細な使い方は省略しますが、import streamlitでモジュールを使えるようにして、ボタンやテキストボックスなどの素材を配置していきます。
簡単なサンプルの例は以下の通りです。
テキスト入力と変数への格納、ボタンなどの基本的な機能がありますので、試してみてください。
import streamlit as st
st.title('サンプルアプリ')
text_input = st.text_input('テキスト入力', '好きなテキストを入力してください')
if st.button('ボタン'):
st.write(text_input)
上記ファイルをapp.pyなどの適当な名前を付けて保存します。
以下コマンドをターミナルで実行し、Cloud9の上部メニュバーからPreview→Preview Running Applicationを選択します。
python3 -m streamlit run app.py --server.port 8080
すると、先ほど作った簡単なWebアプリのブラウザ画面が開くはずです。
この画面はブラウザの別タブで開くこともできますので、色々と試してみてください。
作成したAPIを呼び出す
それでは、作成したAPIを呼び出してWebアプリ上に表示させてみましょう。
PythonではAPIを呼び出すにはrequestsやurllibがよく使われます。
今回はrequestsを利用してみます。
requestsでAPIを呼び出すコードの例を以下に示します。
urlで先ほど作成したAPI Gatewayエンドポイントを入れることで応答が返ってくるはずです。
import requests
url = "https://xxxxxx.execute-api.ap-northeast-1.amazonaws.com/api/books"
response = requests.get(url)
print(response.status_code) # 応答のHTTPステータスコード
print(response.text) # 応答のテキスト表示
print(response.json()) # 応答のJSON表示
正常な応答が返ってきたら、先ほどのstreamlitに組み込んでみましょう。
これで基本的なサーバーレスアーキテクチャの構築が体験できたと思います。
WebアプリでうまくAPIが応答しない場合、Cross-Origin Resource Shareing(CORS)の設定を有効にする必要があります。
API Gatewayの設定だけでなく、Lambdaでの設定もする必要があります。
Lambdaの場合はレスポンスのヘッダーに'Access-Control-Allow-Origin':'*'を付与してみてください。
response = {
'statusCode': code,
'headers': {
'Access-Control-Allow-Origin': '*'
},
'body': json.dumps(body)
}
return response
④~⑥を繰り返す
ここまで1つのAPIをWebアプリに実装する手段について、解説いたしました。
後は要件に従って、Lambda関数を作成→API Gatewayにデプロイ→Webアプリ、の開発と確認を繰り返してみてください。
最後に
実際の開発ではLambda関数のコーディング(バックエンド)、Webアプリのフロントエンド、デプロイはCloudFormationなどのIaCと別れてしまいますが、まずは動くところまで自分で作ってみると理解が深まると思います。