0. 動機
業務中によく使うPDFファイル内部の文字を抽出し、正規表現でパターンを探したり特定の単語を探したり、またそれらの結果を一覧で表示できたりすると業務で色々捗るなと思ったこと。
ただそもそもPowerShellでデフォルトでPDFを読む手段が無いのでModuleのInstallから取り組んでます。
1. 準備1:PSWritePDFモジュールのインストール
ネットで「PowerShell PDF テキスト抽出」と検索してもいまいちピンとくる記事が無かったのでとりあえずPowerShell Galleryへ。
検索窓に"PDF"と入力し、検索結果を「人気(Popularity)」でソートすると最初に出るのがPSWritePDF。ダウンロード数もそれなり(109,900)で信頼性ありそう、概要もPDFのテキスト抽出はできそうなのでひとまずクリック。
※参考:Seleniumの総ダウンロード数は176,716
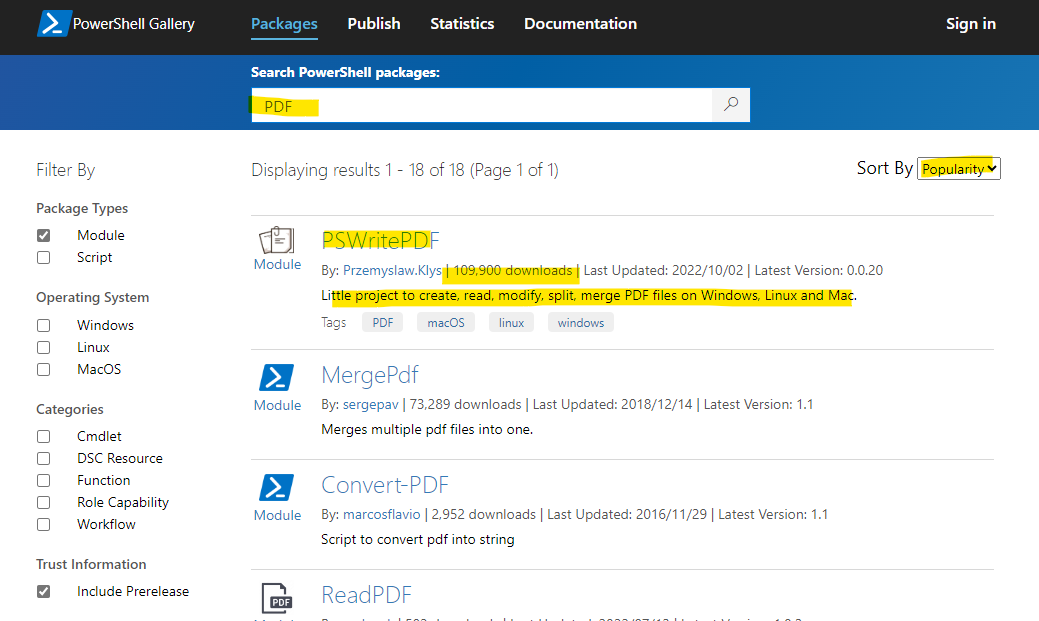
ザッと概要を見ると"Convert-PDFToText"というズバリなコマンドもあるので、指示に従いInstall-Moduleコマンドレットでインストール。
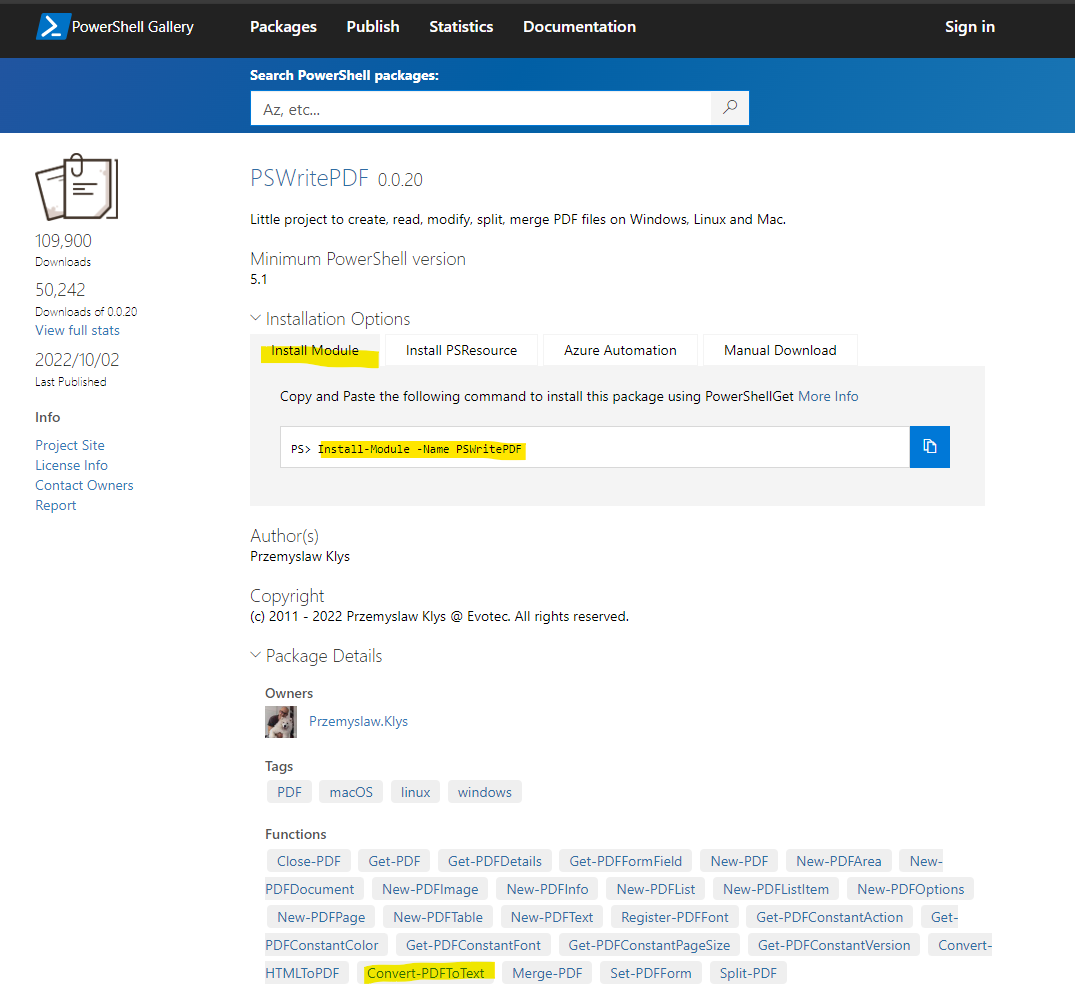
無事にインストール完了。
ただこれは以前Seleniumを落とした時に色々やってるからスムーズにできている可能性があるので、ここでエラーが出てきてしまった場合は過去記事を参照して見てください。
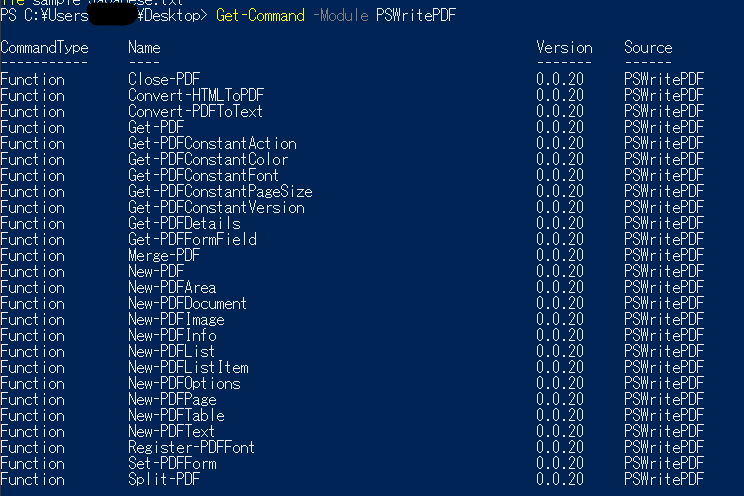
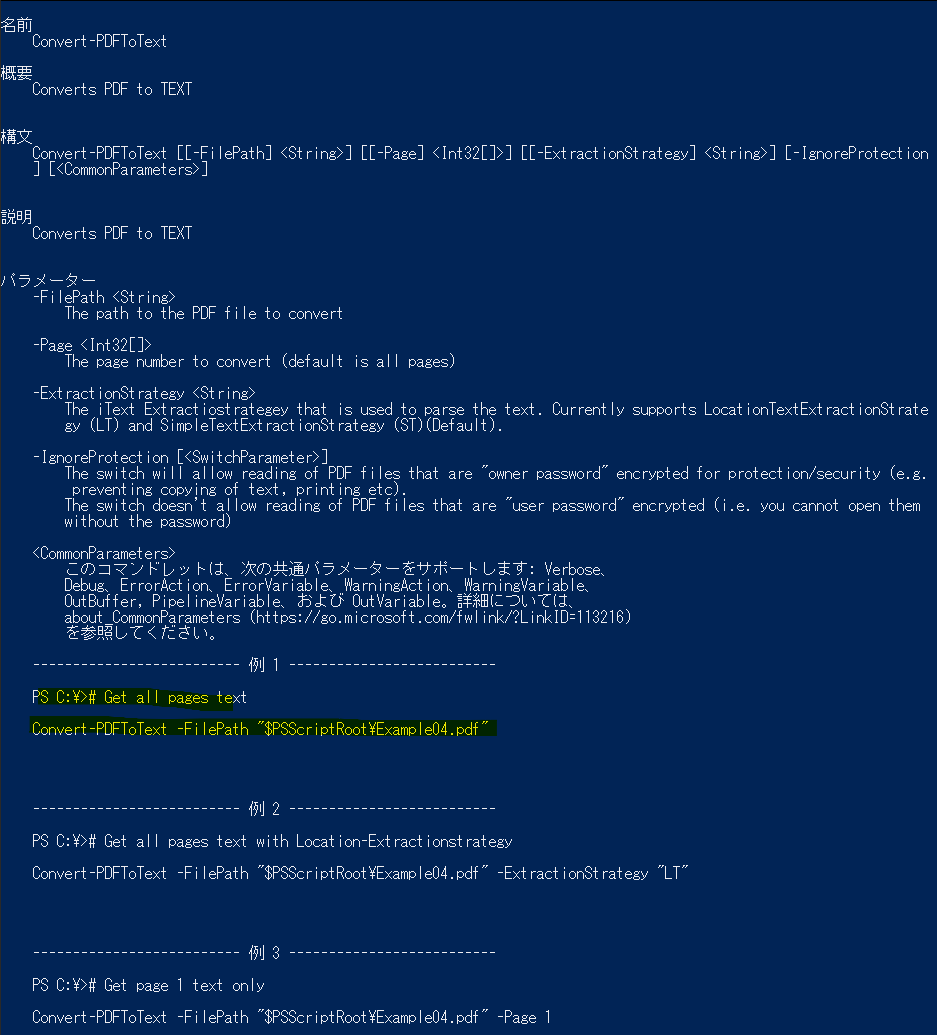
2.準備2:コマンドの確認
コマンド一覧は下記。ひとまずConvert-PDFToTextが気になるのでそれを調べてみる。
ヘルプを見る限り、-FilePathパラメータでpdfファイルを指定すればとりあえずできそうであることを確認。
他にも-Pageパラメータでページ指定出来たり、-IgnoreProtectionパラメータでで保護されたpdfも読めるとのこと。
3. 日本語のPDFをテキストファイル化
誰でもアクセスできるPDFをサンプルとして利用するのがいいのかと思ったので、ひとまず下記IPAのデジタルスキル標準の概要をデスクトップに保存。
https://www.ipa.go.jp/jinzai/skill-standard/dss/t6hhco0000011cr5-att/gaiyou.pdf
カレントディレクトリをDesktopにした状態で下記のワンライナーを実行。 Convert-PDFToTextすれば文字自体は抽出できますが、わかりやすくするために.txtに出力するようにしてます。
Convert-PDFToText -FilePath "C:\Users\Username\Desktop\デジタルスキル標準_概要編.pdf" | Out-File sample-Japanese.txt
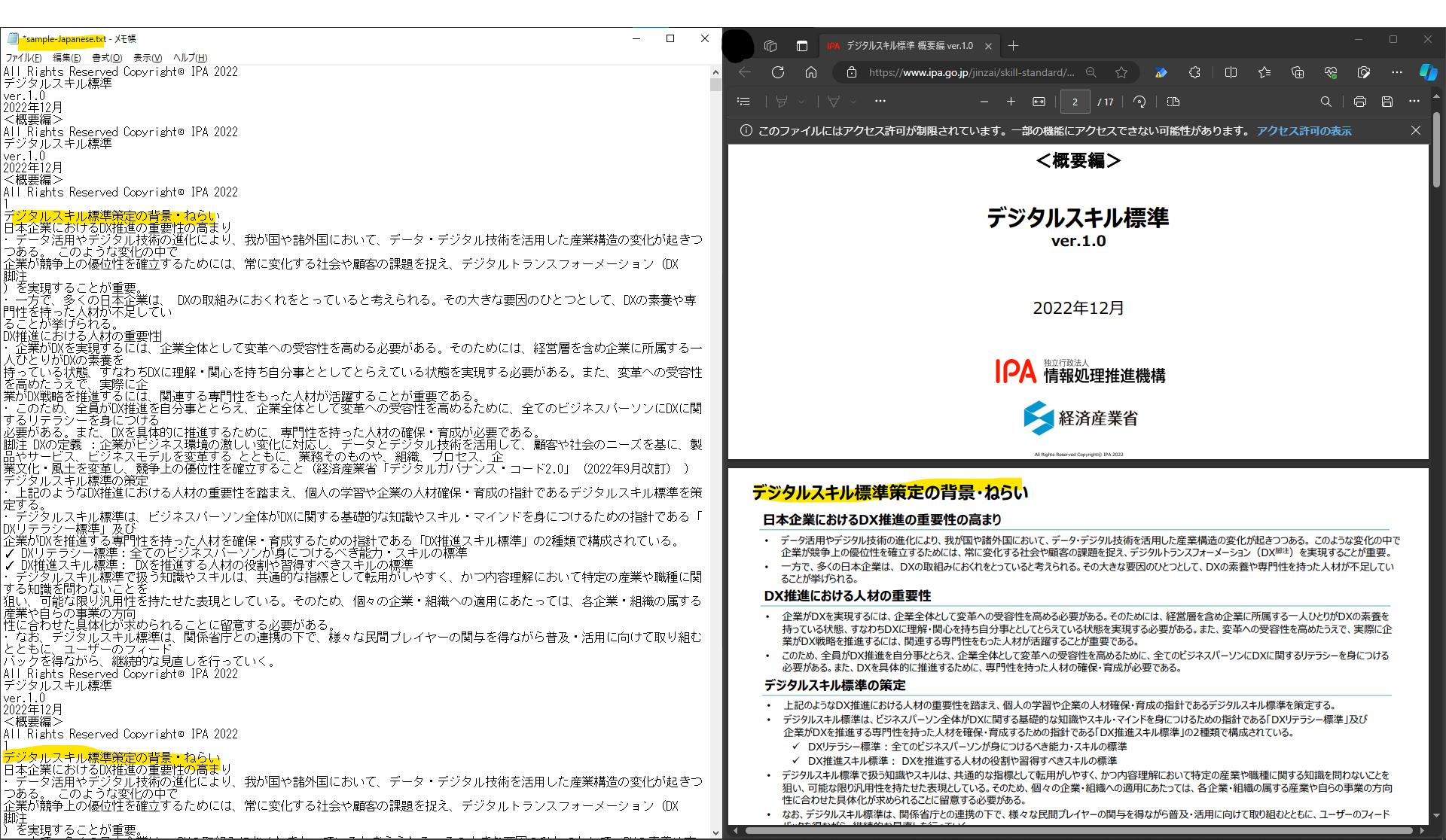
抽出結果と元ファイルの比較は下記。
なぜか同じページの内容が2回現れたり、改行が変なところでなされているようなところがあるものの、テキスト自体はしっかり拾ってくれているので分析などには問題無さそうな印象。
ちなみに.txtに表示せずコンソールに表示するとダブりが無かったので、.txtに出力する場合には注意が必要なのかもしれないです。
4. 英語のPDFをテキストファイル化
こちらも同じく誰でもアクセスできるPDFをサンプルとして利用するのがいいのかと思ったので、ひとまず同様にIPA下記資料をデスクトップに保存。
https://www.ipa.go.jp/en/it-talents/skill-standard/gg62ps0000000lem-att/000009630.pdf
カレントディレクトリをDesktopにした状態で下記のワンライナーを実行。
Convert-PDFToText -FilePath "C:\Users\Username\Desktop\ITSS Model Curriculum_IPA_English.pdf" | Out-File sample-English.txt
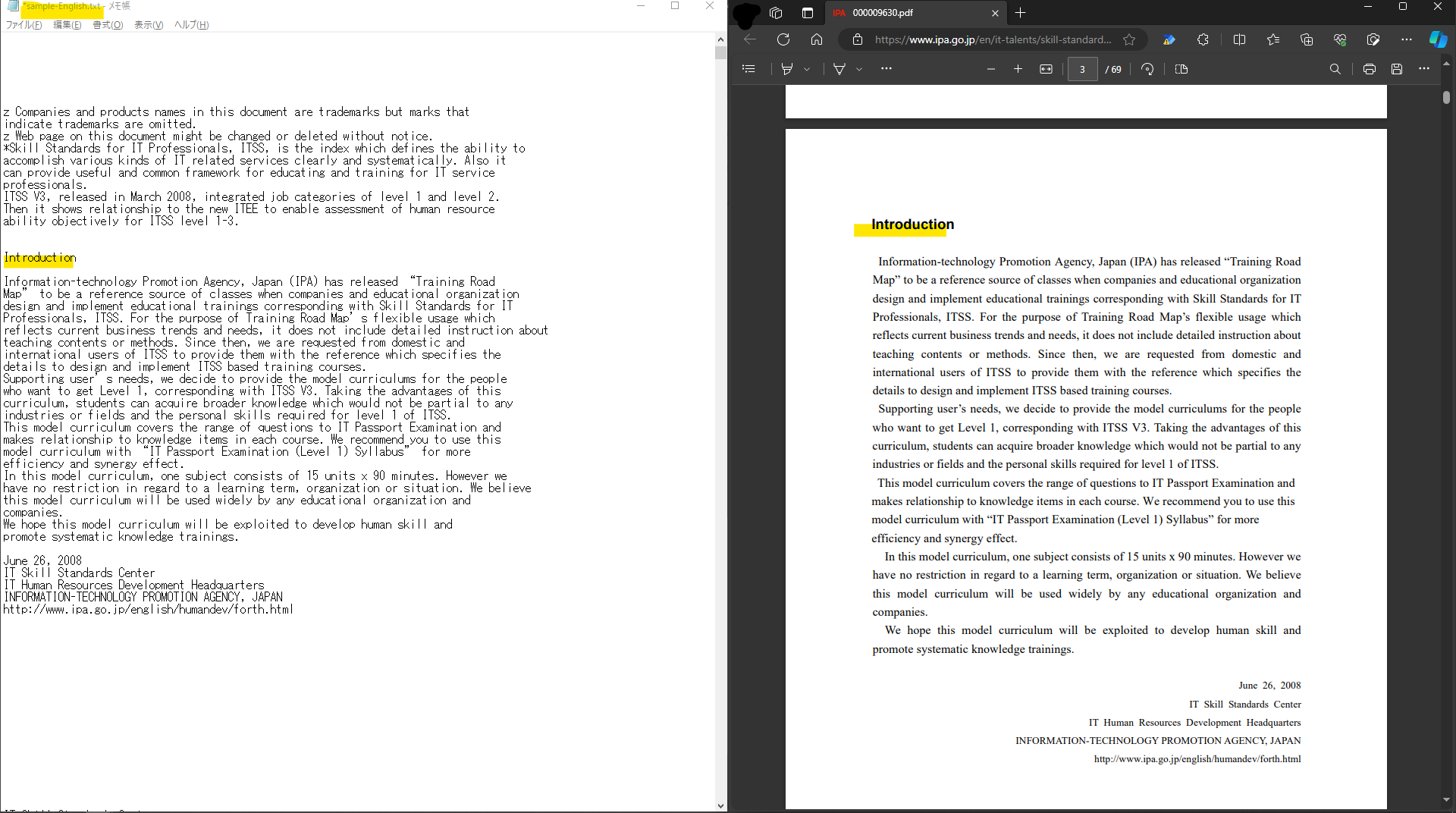
抽出結果と元ファイルの比較は下記。
日本語と同じくなぜか同じページの内容が2回現れるようす。でもテキスト自体はしっかり拾ってくれているので分析などには問題無さそうな印象。また日本語と違って単語の間にスペースがあるので改行位置はそこまで気にならないですね。
ちなみにこちらも.txtに表示せずコンソールに表示するとダブりが無かったです。
5.おわりに
- 基本自分用のメモですがどなたかの役に立てば幸いです。
- ひとまず自分の想定している用途においてこのModuleがあればどうにかなりそうでした。.txtに出力するとなぜかダブる問題があるのでそこは注意した方がよさそうです。