Zhou, Yizhou and Sun, Xiaoyan and Zha, Zheng-Jun and Zeng, Wenjun, "MiCT: Mixed 3D/2D Convolutional Tube for Human Action Recognition", in CVPR2018, pp.449-458, 2018. Online PDF at CVF
1.どんなもの?
2DCNNと3D畳み込み層を統合することで空間情報をリッチにした特徴マップを生成
残差接続として2DCNNと3DCNNの結果を足し合わせる
時空間の訓練の複雑さを緩和するMixed Convolutional Tube (MiCT)の提案
2.先行研究と比べてどこがすごいか?
動画像は3次元信号→3DCNNを利用した自然的なアプローチが提案されている
その性能は画像内のTwo-Streamのような手法による2DCNNによって達成されるものと比べて良いとは言えない
C3D(3DCNN)は3D畳み込みを重ねて結合することで実装しているため、層を重ねるごとに特徴量が指数的に増えるため、数十層の3D畳み込みを使用したネットワークの最適化が難しい
メモリコストの面でもこれ以上の層を積み重ねることは無理(11層の3DCNN=1.5 x 152層ResNets)
↑以上を踏まえて3D畳み込みの数を抑えて特徴マップの深さを大きくするMiCTを提案している
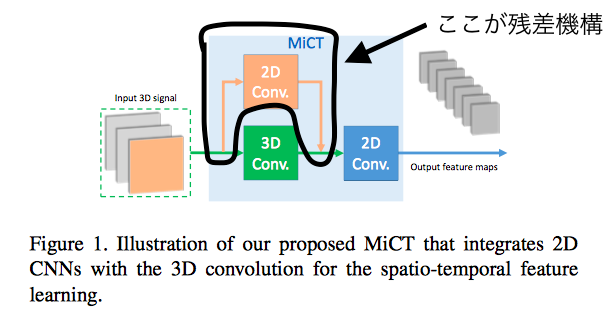
3.技術や手法の肝はどこにあるか?
MiCTの実装により、3D畳み込みの制限(メモリコストや最適化の難しさ)を改善
3D Convolution

動画像はT×H×W×Cのテンソル(T:時間方向,H:縦幅,W:横幅,C:シャネル数)
3D畳み込み層のカーネルは、4Dテンソル
(簡単のためチャネル方向は省略)
下式で定式化されている 詳しくはこちら

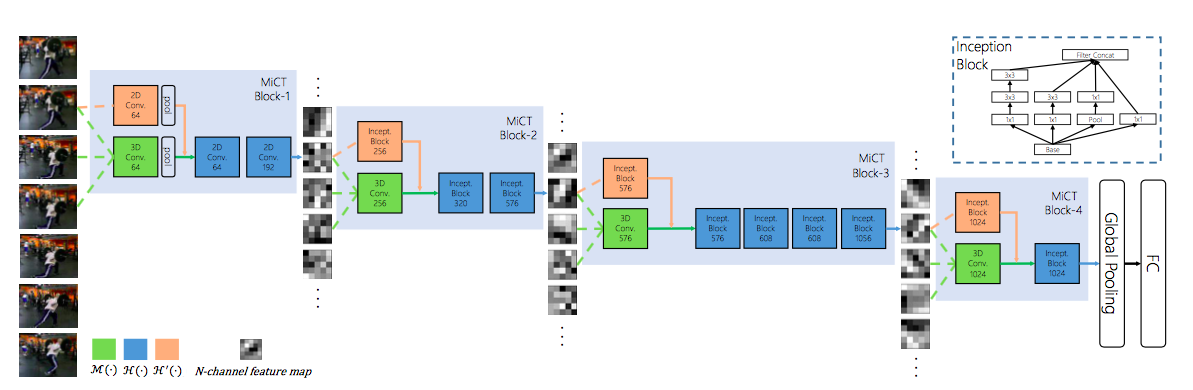
MiCT
ビッグデータで事前学習済みの2DCNNを3D畳み込みモジュールに導入
空間-時間融合の各ラウンドでより深い特徴マップを出力

連結の接続方法
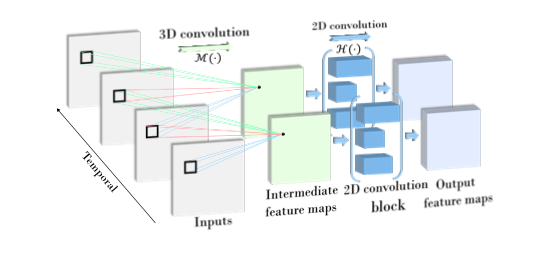
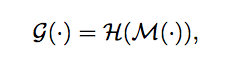
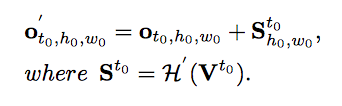
Hは2D畳み込みブロックの写像関数
Mは3D畳み込み
残差接続なしversion
連続するフレームの中に多くの冗長情報を含んでおり、時間的次元に沿って特徴マップに冗長な情報をもたらす
→有益な静的な2D特徴を抽出するために2D畳み込みブロックを導入する
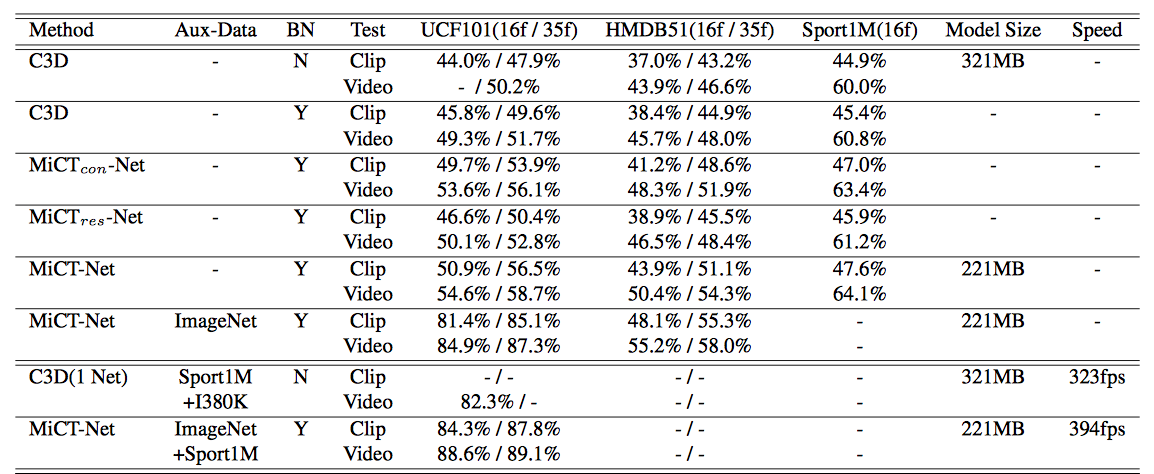
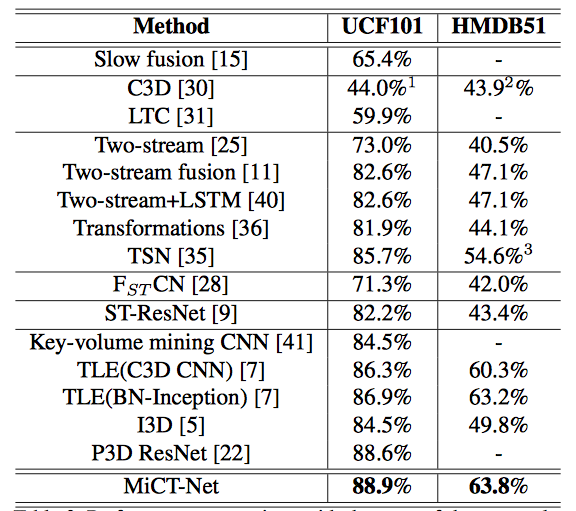
4.どうやって有効だと検証した?
MiCTを積み重ねるMiCT-Netを提案
RGBビデオシーケンスを入力として受け取り、エンドツーエンドで訓練可能
比較検証方法
・データセット
-UCF101とSport1M、HMDB51で実験を行った
・データ拡張
- 各フレームを256×340にリサイズ
- 224×224の領域をランダムにトリミング
- 水平方向にランダムにフリップ(逆転)
- 時間次元方向にダウンサンプリングを行う
- これらのランダム操作はビデオシーケンス全てに渡って処理が行われる
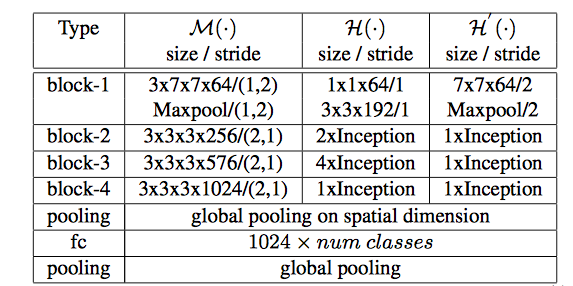
・上図の各ブロックにおける畳み込みサイズの詳細
視覚化
最初のMiCTブロックの特徴マップの視覚化
上図のスローモーションでの認識には身体の部位や背景エッジなどが重要
下図の高速モーションでは特徴マップがモーションエリアにさらに集中していることわかる→時間情報を組み込んでいることがわかる(動きのある位置に集中して特徴が抽出できている?)

5.議論はあるか?
MiCTNetのさらなる拡張が今後の研究課題である