Deep Temporal Linear Encoding Networks [A. Diba+, CVPR17]
-CVF
1.どんなもの?
時間的リニアエンコーディング(TLE)と呼ばれる新しいビデオ表現を提示
2.先行研究と比べてどこがすごいか?
動画像全体をコンパクトな特徴にエンコードできること
TLEをビデオ分類のための2Dおよび3DCNNのようなあらゆる種類のネットワークに適用可能なこと
可変長の動画像データセットを使用可能
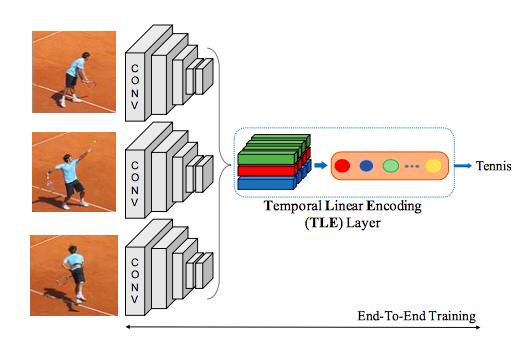
3.技術や手法の肝はどこにあるか?
長時間の時間構造から重要な情報をフレームからキャプチャし、リニアエンコーディングによってコンパクトで堅牢な特徴表現に集約する(高次元から低次元に変換する)
可変長の動画像全体を使うため認識精度が良い(これまで固定長の動画像)
特徴マップを時間集約関数を用いることで1つの特徴マップXを生成
特徴マップXをエンコードして特徴ベクトルyを得る

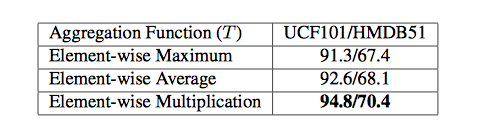
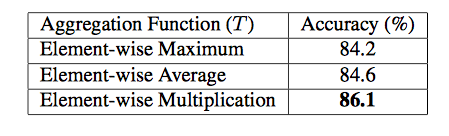
3パターンの方法で実験した結果、乗算の方法が一番いい結果をもたらした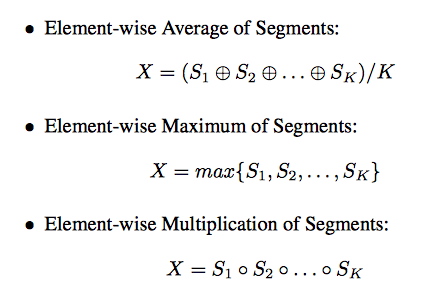
線形符号化(EncodingMethod)の方法としてBilinearモデルとFully connected poolingがある
End-to-End学習の簡略図↓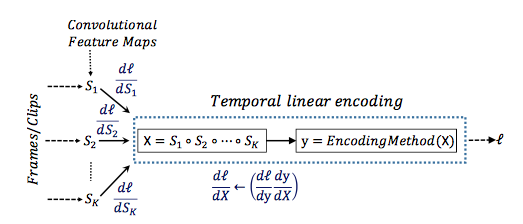
4.どうやって有効だと検証した?
・HMDB51とUCF101データセットで実験
・Two-Stream ConvNetsとC3D ConvNetsで比較検証
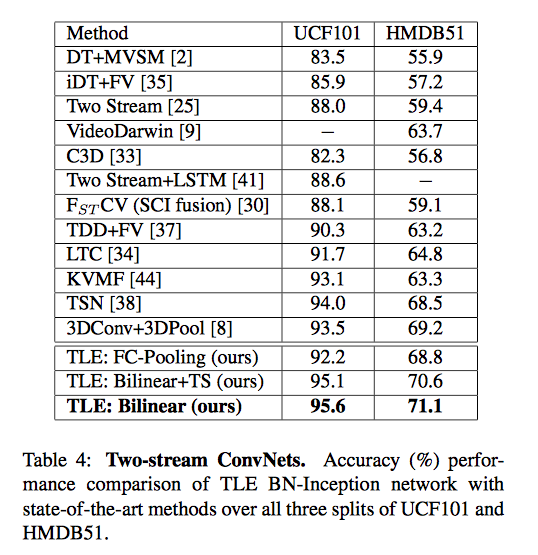
Two-Stream ConvNetsでの時間集約関数の比較
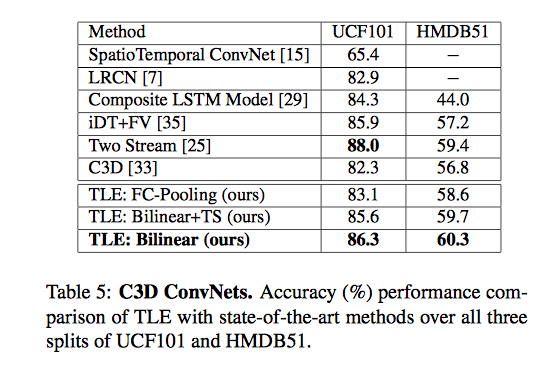
C3D ConvNetsでの時間集約関数の比較
乗算を使ったTLEを組み込んだConvNetsでの性能比較