はじめに
JIS G0551 : 2020 鋼-結晶粒度の顕微鏡試験方法で規定されている「比較法」を「ディープラーニング」の「画像認識」で行うための画像データやPythonのプログラムを公開します。プログラムの実行にはOpenCVやKerasライブラリを備えたPythonの環境が必要になりますのでご注意ください。なお、本記事は以下の研究報告をベースとして、より簡易な内容に改良しています。
比較法について
金属材料の多くは無数の結晶粒からできています。金属材料の断面を鏡面研磨して、結晶粒の堺目(粒界)を選択的に腐食するエッチング液に浸漬してから洗浄・乾燥して顕微鏡で観察すると、下図のような組織画像が得られます。この図において、粒状のものが結晶粒になります。結晶粒の大きさは熱処理などで変わり、結晶粒の大きさが変わると材料の強度も変わるため、熱処理後の製品の品質に結晶粒の大きさが規定されることもあります。組織画像から結晶粒の大きさを評価する試験方法はJISでいくつか規定されており、その方法の一つが比較法になります。

SCM435焼入れ材の組織画像(旧オーステナイト結晶粒界をAGS腐食液で現出)
比較法はJIS G0551 : 2020 鋼-結晶粒度の顕微鏡試験方法で規定されています。試験内容は、組織画像の結晶粒の状態を「結晶粒度標準図」と呼ばれる図と比較することにより、粒度番号と呼ばれる値を求めるものです。「結晶粒度標準図」はここには掲載できないので、ご存じない方は書籍やインターネット等で調べてみてください。
比較法をディープラーニングの画像認識で行うには
画像を読み込んで粒度番号を出力するディープラーニングのモデルを作成します。上記の研究報告では、結晶粒度標準図に相当する種々の粒度番号の画像データを作成して、それをディープラーニングのモデルで学習しています。学習においては、粒度番号をラベルとして扱っています。
結晶粒度標準図に相当する種々の粒度番号の画像データは、粒度番号が分かっている試料の組織画像を種々の大きさにトリミングして作成しています。さらに、モデルの汎化性能を高めるために、粒度番号が分かっている試料の組織画像には、結晶粒界が明瞭な試料と不明瞭な試料について、撮影した画像を用いています。
本記事での改良点
上記の研究報告からの本記事の改良点には次のものがあります。
-
種々のサイズにトリミングする画像について
上記の研究報告では、結晶粒界が明瞭な組織画像と不明瞭な組織画像を各100枚使用していました。撮影倍率は200倍です。本記事では、結晶粒界が明瞭な組織画像10枚のみ使用します。撮影倍率は上記の研究報告と同じ200倍です。本記事では、組織画像に種々の量のノイズを付加することで、結晶粒界が不明瞭な組織画像を疑似的に作成しています。 -
ディープラーニングのモデルについて
研究報告ではKerasライブラリのVGG16を使用していますが、本記事ではTeachableMachineを使用します。TeachableMachineはプログラムが不要で、ディープラーニングの画像認識のモデルを容易に作成できます。
https://keras.io/api/applications/vgg/
https://teachablemachine.withgoogle.com/ -
推論に使用する画像
研究報告ではSCM435焼入れ材、SCM435焼入れ焼戻し材でしたが、本記事ではSCM435焼入れ材、SCM435焼入れ焼戻し材、SUS304鋭敏化材、SUJ2焼入れ焼戻し材と種類を増やしています。
やり方
githubのサイトからのファイルのダウンロード
- 以下のサイトを開き、緑色の「Code」の▼をクリックして、「Download ZIP」を選び、ZIPファイルをダウンロードします。
- ダウンロードしたファイルを解凍して、3個のPythonファイルと、imgフォルダ内の「1-200」および「GrainBoundaries」を以下のようにフォルダに格納します。この時点でdata1フォルダには何もファイルがない状態です。後ほど使います。
c:.
│
│
├─data
│ └─1-200
│ 1-200 (1).jpg
│ 1-200 (2).jpg
│ .
│ .
├─data1
│
├─Python
│ ImageAugmentation.py
│ MakeGrain.py
│ TestTeachableMachineModel.py
│
├─GrainBoundaries
│ ├─304-200
│ ├─304-500
│ ├─435Q-500
│ ├─435Q-1000
│ .
│ .
組織画像の拡張(ノイズ付加)
- ImageAugmentation.pyを実行します。ImageAugmentation.pyを実行すると、「1-200」フォルダに種々の量のノイズを加えた画像が作成されます。これにより、10枚の画像が80枚に拡張されます。
種々の粒度番号に対する組織画像の作成
- MakeGrain.pyを実行します。Data1のフォルダに「1-200」フォルダが作成され、その中に「2.0」~「7.0」のフォルダが作成されます。「2.0」~「7.0」の各フォルダには、「1-200」の各画像が粒度番号2.0~7.0に相当する大きさにトリミングされた画像が格納されます。これらの画像は幅142mmで表示すると、各粒度番号の大きさになります。
c:.
│
│
├─data1
│ └─1-200
| ├──2.0
| | 1-200 (1)_0.1_2.0.jpg
| | 1-200 (1)_0.2_2.0.jpg
│ | .
│ | .
| ├─2.5
| | 1-200 (1)_0.1_2.5.jpg
| | 1-200 (1)_0.2_2.5.jpg
│ | .
│ | .
│ |
TeachableMachine による学習
-
TeachableMachineのサイトを開き、「使ってみる」「画像プロジェクト」「標準の画像モデル」を順にクリックします。
-
「Class」には粒度番号に「2.0」を入力して、「アップロード」をクリックして「ファイル」の枠内に「2.0」フォルダをドロップします。2.5~7.0フォルダについても同様に作業します。
-
「詳細」をクリックして、学習条件を設定します(デフォルトの条件でも学習は可能です)。

条件設定の一例です。

-
「トレーニング」をクリックすると学習が始まります。「詳細」をクリックして「舞台裏」をクリックすると学習曲線、損失曲線や、クラスごと(粒度番号ごと)の正解率、混合行列を確認できます。
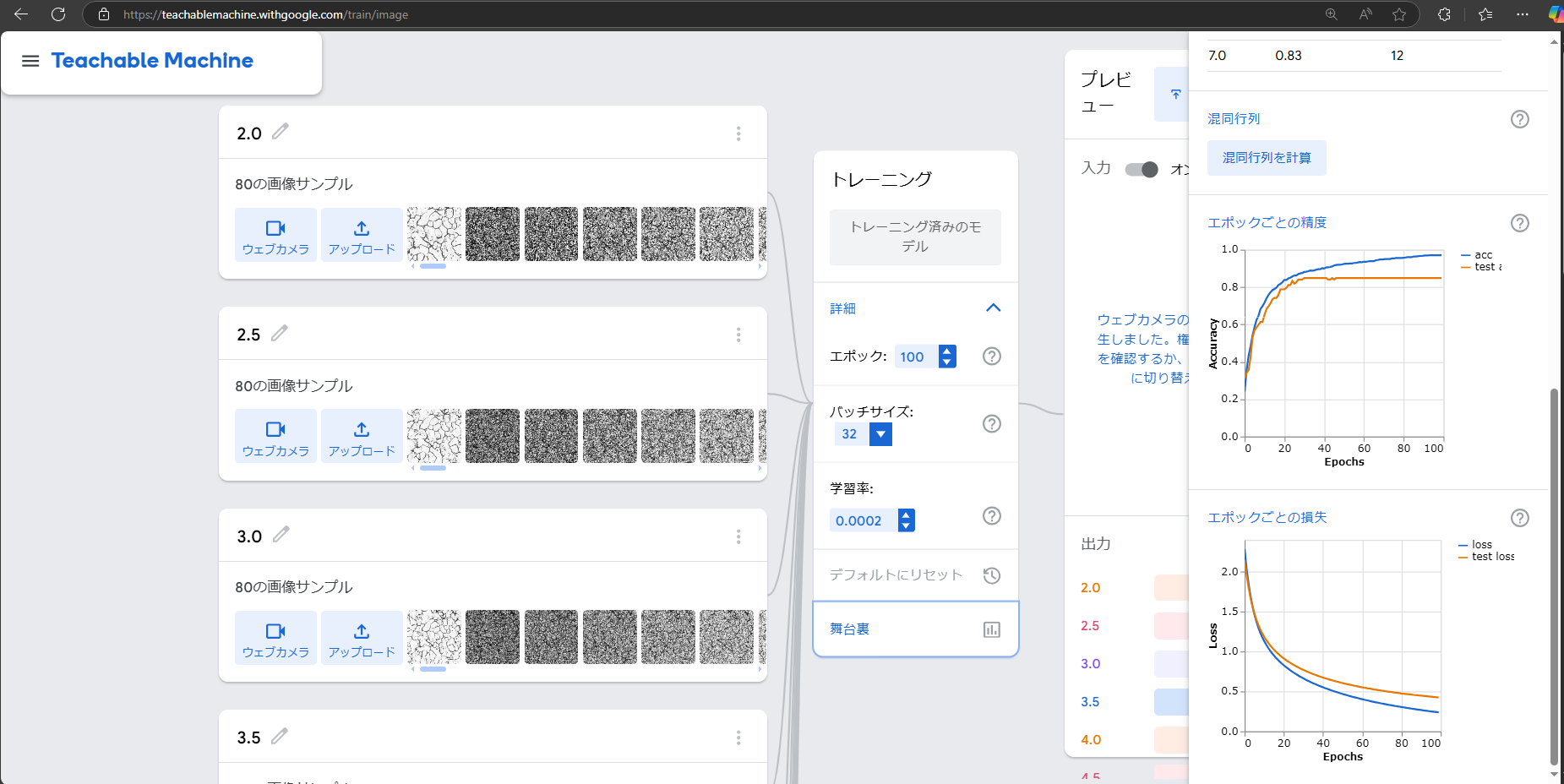
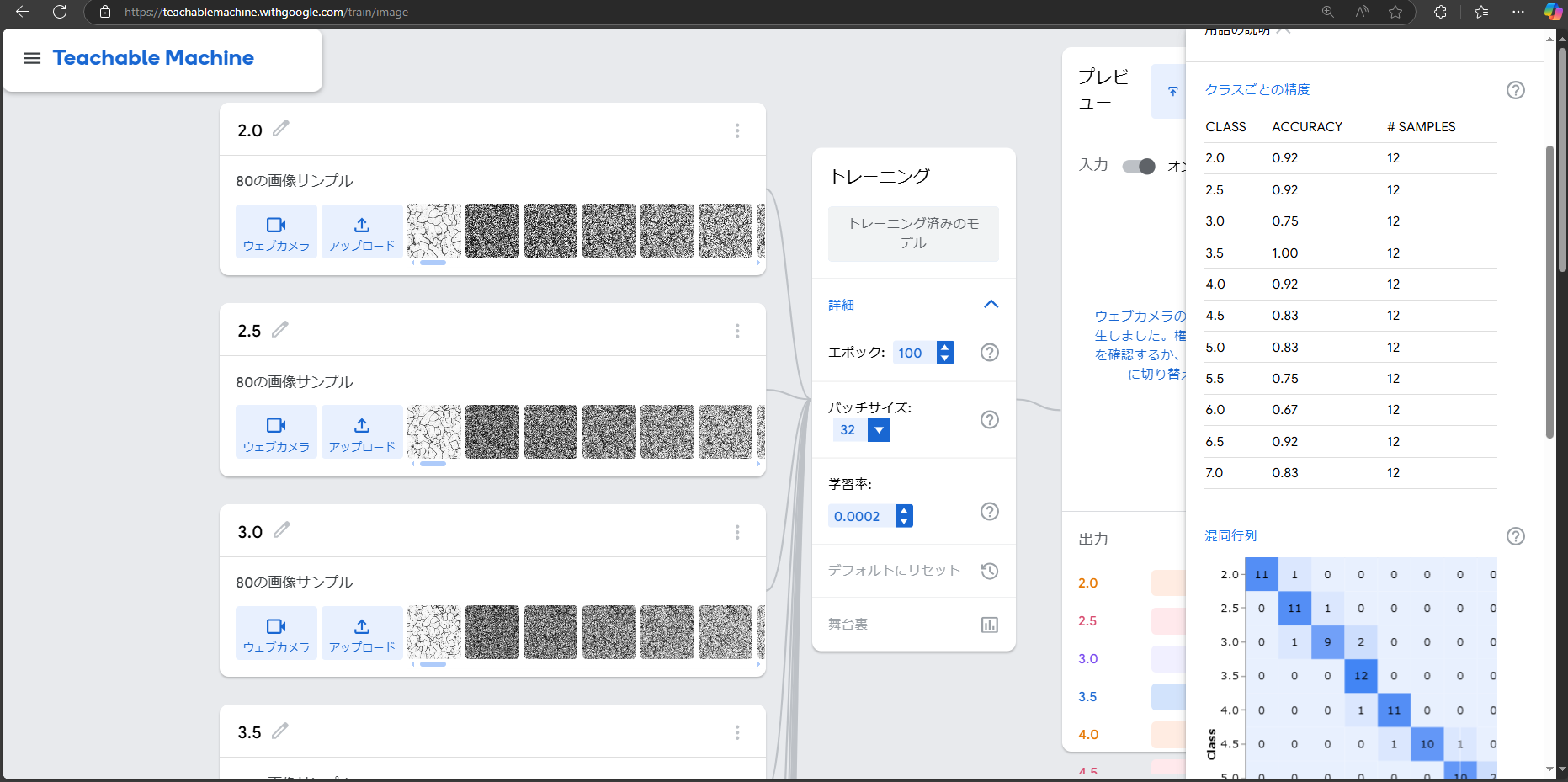
-
クラスごとの正解率が大きくばらつくなど結果が思わしくない場合には、学習条件を変更して「トレーニング済みのモデル」をクリックして再トレーニングします。
-
トレーニングが終了したら、トレーニングで作成されたモデルを保存します。「舞台裏」の「×」をクリックして閉じます。
-
画面右上の「モデルをエクスポートする」をクリックします。

-
モデルをパソコンにダウンロードします。「Tensorflowタブ」を選び、「Keras」にチェックして「モデルをダウンロード」をクリックします。

-
ダウンロードしたzipファイルについて、ファイル名が文字化けしないように解凍します。解凍したファイルはc:\Pythonに格納します。

-
GoogleDriveにプロジェクトとして保存することも可能です。保存にはGoogleアカウントが必要です。
テストデータによる評価
- TestTeachableMachineModel.pyを実行します。テストデータ(学習に使用していない画像)が格納されている「GrainBoundaries」ファイルダ内の各フォルダの5枚の画像について、粒度番号の平均値と標準偏差が表示されます。

テストデータについて
GrainBoundaries内の各フォルダには、下表に示す試料の組織画像5枚と「cond.ini」が入っています。
| フォルダ名 | 試料 | 撮影倍率(倍) | 撮影倍率で表示したときの組織画像の幅(mm) | JIS G0551の比較法による5枚の組織画像の粒度番号の平均値 |
|---|---|---|---|---|
| 304-200 | SUS304鋭敏化材 | 200 | 142 | 8.0 |
| 304-500 | SUS304鋭敏化材 | 500 | 142 | 7.7 |
| 435Q-500 | SCM435焼入材 | 500 | 142 | 9.8 |
| 435Q-1000 | SCM435焼入材 | 1000 | 142 | 9.7 |
| 435QT-500 | SCM435焼入焼戻材 | 500 | 142 | 9.9 |
| 435QT-1000 | SCM435焼入焼戻材 | 1000 | 142 | 10.0 |
| SUJ2QT-500 | SUS2焼入焼戻材 | 500 | 142 | 10.5 |
| SUJ2QT-1000 | SUS2焼入焼戻材 | 1000 | 142 | 10.7 |
cond.iniの内容は次のとおりです。
- 撮影倍率
- 撮影倍率で表示したときの画像の幅
「TestTeachableMachineModel.py」では、画像ファイルがあるフォルダ内の「cond.ini」を参照して、「撮影倍率」と「撮影倍率で表示したときの画像の横幅」を読み込み、粒度番号の計算に用いています。
「撮影倍率」は顕微鏡で観察する結晶粒の大きさによって適宜変わる場合が多く、また、「撮影倍率で表示したときの画像の横幅」は顕微鏡の仕様によって異なります。このため「TestTeachableMachineModel.py」では、これらの値をパラメータとして読み込んでいます。これらのパラメータにより、TeachableMachineのモデルから得られる推論値は補正され、粒度番号となります。
本記事で作成したモデルによる推論結果
本記事で作成したモデルによる粒度番号の推論結果と、比較法による粒度番号を下表に示します。これらの値は5枚の画像の平均値です。なお、推論結果は学習条件によって変わるため、上記の方法でモデルを作成しても下表の推論結果と同じ結果が得られるとは限りません。
| 試料 | 撮影倍率(倍) | 本記事で作成したモデルによる推論結果 | 比較法による粒度番号 |
|---|---|---|---|
| SUS304鋭敏化材 | 200 | 7.20 | 8.0 |
| SUS304鋭敏化材 | 500 | 8.24 | 7.7 |
| SCM435焼入材 | 500 | 10.14 | 9.8 |
| SCM435焼入材 | 1000 | 10.64 | 9.7 |
| SCM435焼入焼戻材 | 500 | 9.94 | 9.9 |
| SCM435焼入焼戻材 | 1000 | 10.14 | 10.0 |
| SUS2焼入焼戻材 | 500 | 10.14 | 10.5 |
| SUS2焼入焼戻材 | 1000 | 10.64 | 10.7 |
プログラムの実行環境
python 3.9.18
opencv 4.6.0
tensorflow 2.10.0
keras 2.10.0
numpy 1.26.3
終わりに
「撮影倍率」と「撮影倍率で表示したときの画像の横幅」の情報が分かっていれば、手持ちの画像についても作成したモデルで試すことができます。その場合は、使いやすいようにTestTeachableMachineModel.py を改良していただければと思います。
また、データセットをお使いの環境(評価する粒度番号の範囲、顕微鏡の画像サイズ)に合わせて作成することも可能と思います。お使いの環境に合った使いやすいモデルが作れると思います。
何かのご参考になれば幸いです。