[0]はじめに
Zitanです。
OCR(Optical Character Recognition)の需要は高いと思いますが、
UiPathでOCR機能が使えることを知りました。
実際に動いた感動をシェアしたく、記事にしてみました。作り方も説明しているので長いです。
[1]全体の流れ
[1-1]タクソノミーを読み込む
タクソノミーとは、UiPathの公式サイトによると、
様々な種類の文書 (請求書、契約書、医療カルテなど) の集合体や、それに関するデータフィールドのことです。
実作業としては、OCRで抽出したい項目名を定義します。
たとえば請求書であれば、「請求書番号」「会社名」「明細金額」など、抽出したい情報がありますね。
事前に、そういった情報を登録します。
ドキュメント全体を読み込むのではなく、事前に設定した項目だけをOCR処理します。
項目と内容の紐づけは、[1-3]のデータ抽出で説明しています。
[1-2]ドキュメントをデジタル化
ドキュメントがあるフルパスを指定します。
UiPathに搭載されているいくつかの種類のOCRエンジンの中から一つ選びます。
選んだOCRエンジンがドキュメントをデジタル化(解析)してくれます。
[1-3]データ抽出
抽出子というものを使って、先ほど[1]で最初に定義した項目名と、ドキュメント(PDFとか)内の内容の位置合わせを行います。
ドキュメント内で抽出したい文字の周りをマウスでドラッグして四角形で囲って、その中の文字列を抽出するように定義します。
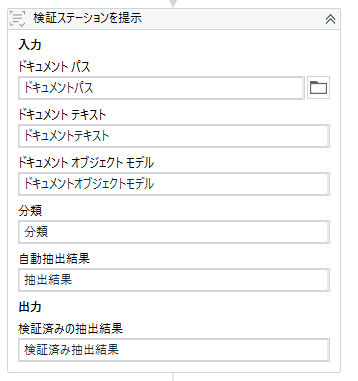
[1-4]抽出したデータの検証(本運用では不要?)
抽出された内容が合っているか人間の目でチェックします。
毎回、検証ステーションというものが起動して、全然自動ではないので、
抽出結果の精度が信頼できるのであれば、本運用では「検証ステーションを提示」というアクティビティは削除するかもしれません。
[1-5]抽出結果を出力
Excelなどに書き込みます。
[2]結果
こんな請求書があったとします。請求書のフォーマットに変更はなく、1枚で完結するとします。(複数枚に渡らない)
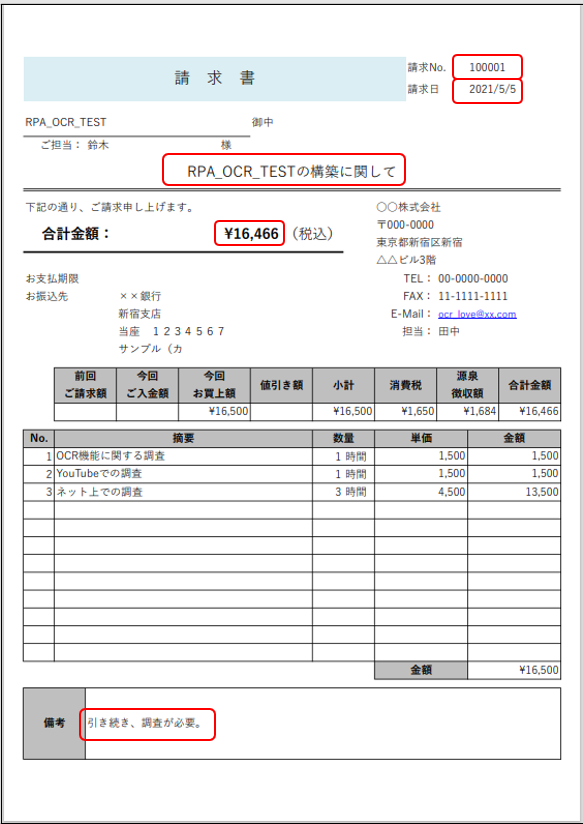
赤枠で囲ったテキストを抽出して、Excelに書き込まれるようにします。

ちなみにテンプレートは、ここで入手しました。
※利用規定に商用・非商用問わず無料で利用できると記載されています。便利なので使用させていただきました。
[3]作り方
今回は、元がExcelファイルでできた請求書をPDFで保存しました。
手書きのデータを読み込む場合もこれから説明する手順で対応できるらしいです。
これから説明する手順は、色んなサイトを見ても同じ流れだったので、お作法として何も考えずに配置して大丈夫だと思います。
私は最初さっぱり分からず真似して作りましたが、動いたものを見て、あとから理解しました。
[3-1]タクソノミーマネージャーで抽出したい項目内容の名称を定義する
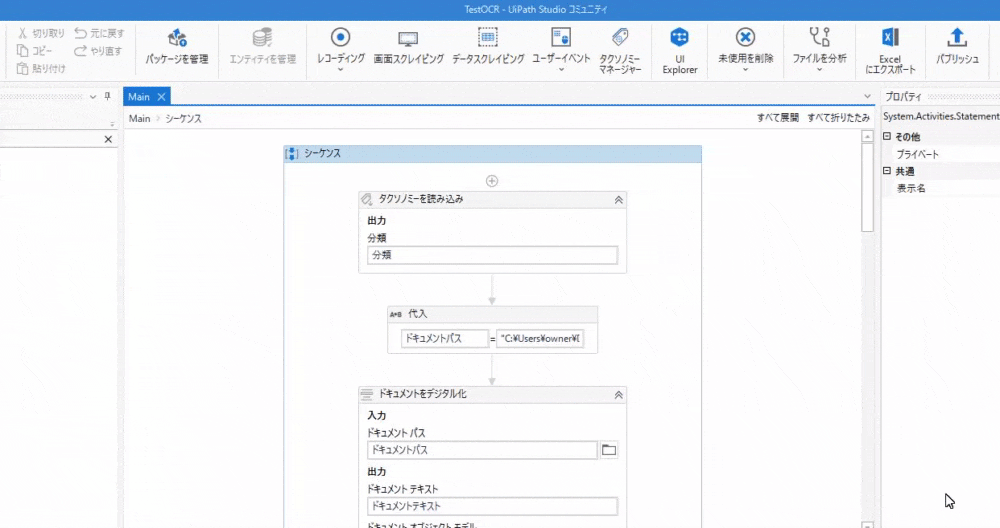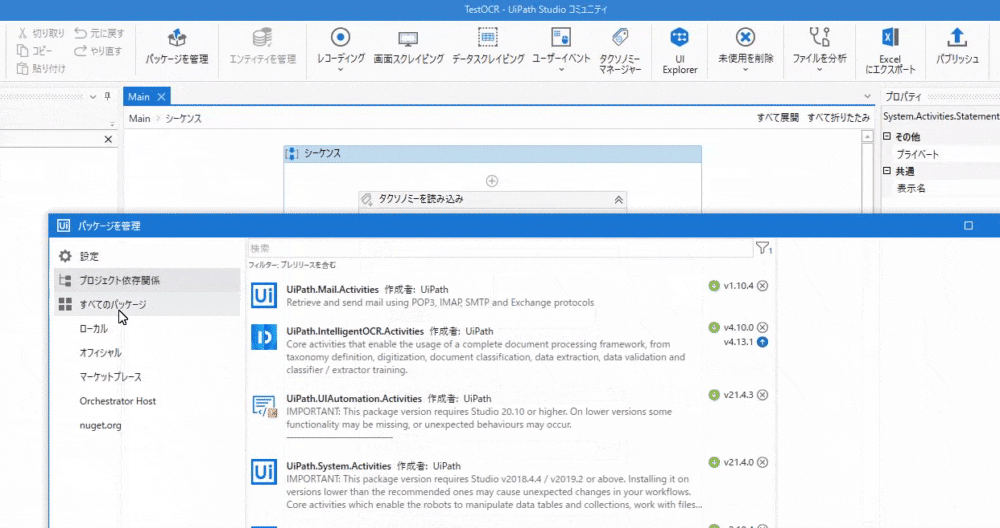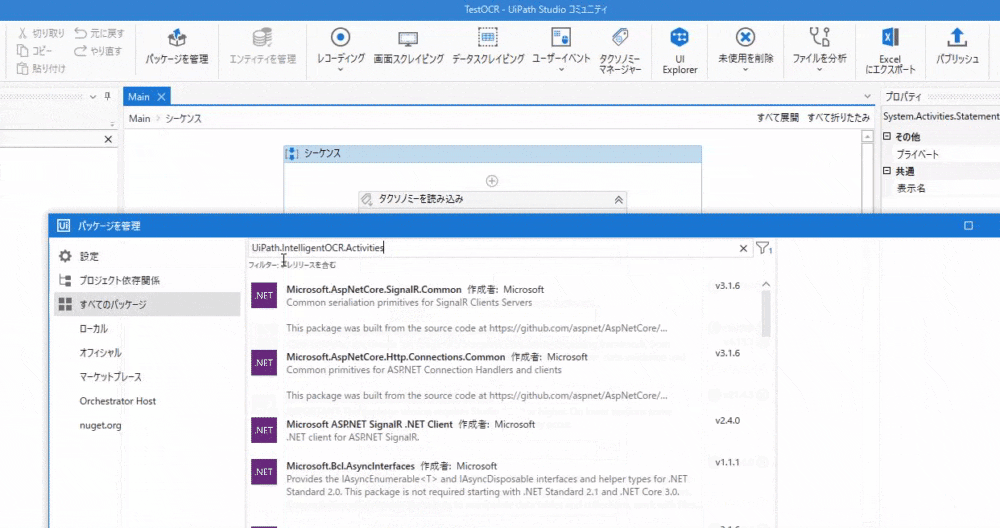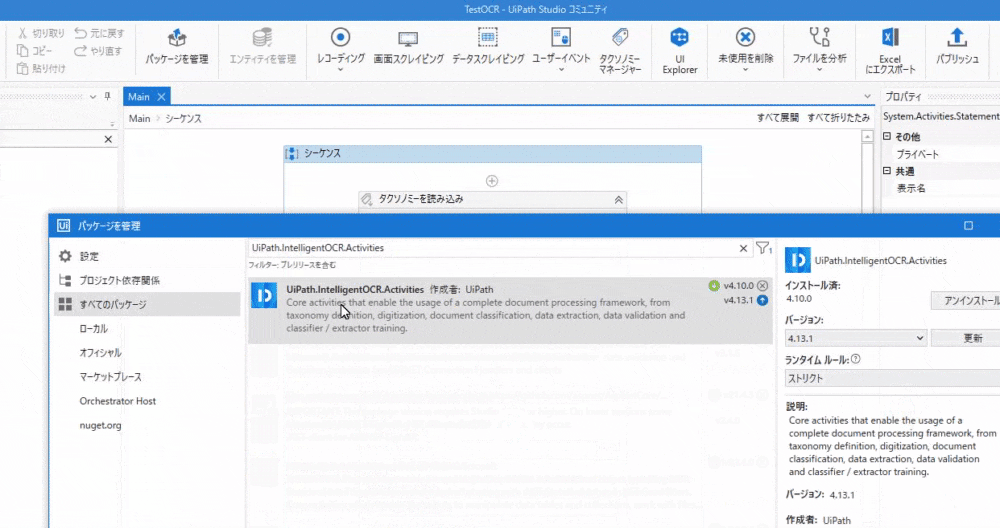
パッケージを管理->すべてのパッケージで「UiPath.IntelligentOCR.Activities」を検索してインストールします。
バージョンは「v4.10.0」にします。最新が「v4.13.1」だったのですが、使いたいアクティビティが見つからず。。。
インストールが終わったら、
タクソノミーマネージャーを開いて、今回OCRで読み込みたい項目名を定義します。
※インストール完了後に出現します。
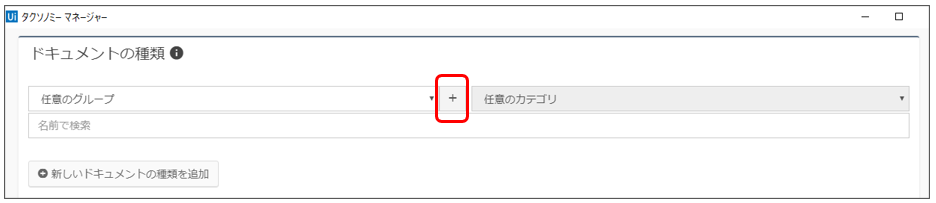
ドキュメントの種類は、いくつか分類分けして登録することができます。
初めての場合は、赤枠で囲った「+」記号をクリックして、グループ名の大区分名を入力します。
その後、カテゴリ名(中区分名)を入力します。
たとえば、あなたが会社の経理部に所属しているならば、
[大区分]経理部
[中区分]A社請求書
といった名称でもいいでしょう。大区分も中区分もそれぞれプルダウン形式で選択できるので複数のドキュメントのパターンが定義できます。
筆者がすでに作成したものはこちらです。あとで抽出したい項目名(フィールド)を「新しいフィールド」から追加します。
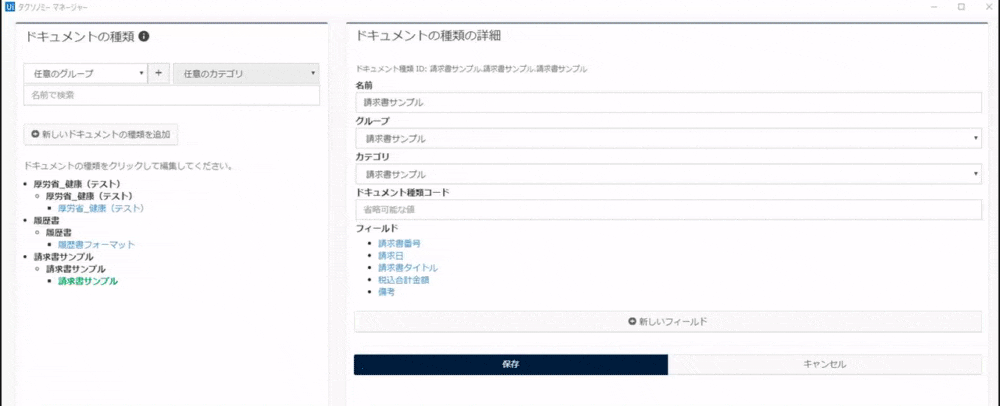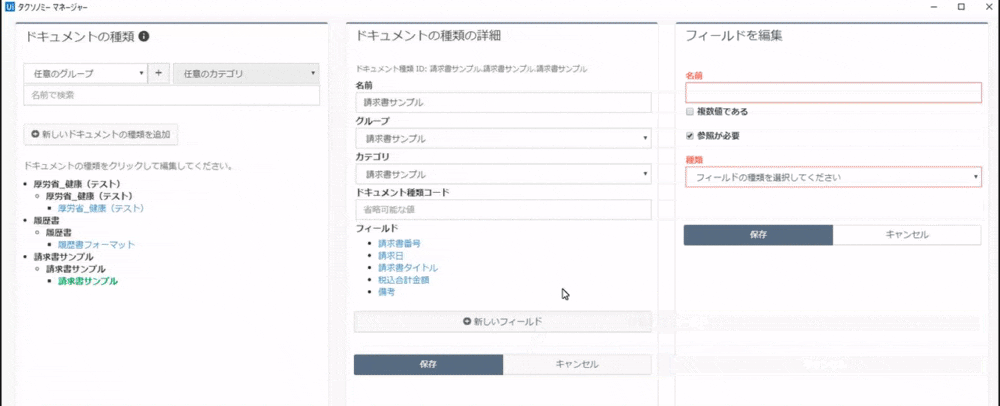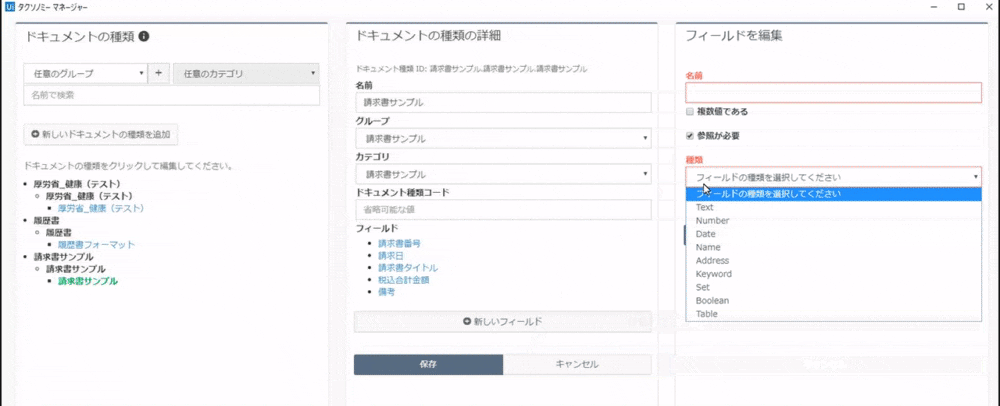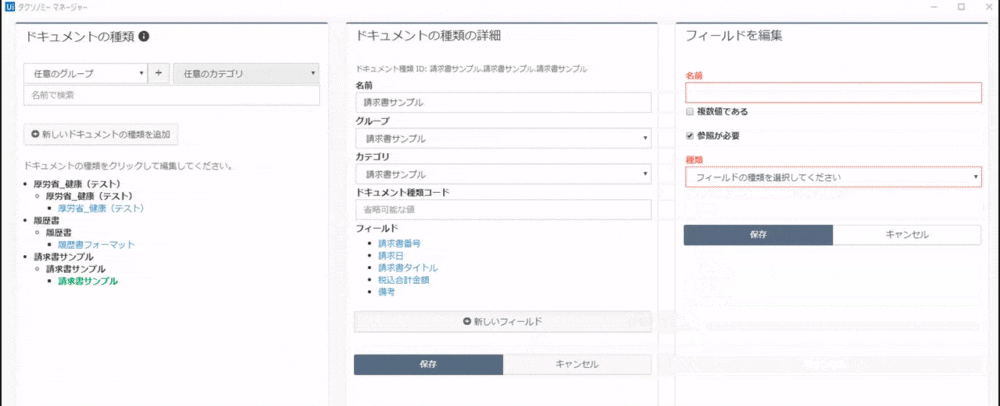
保存して、閉じたらデザイナーパネル内(プロセスを作成する場所)にシーケンスを配置し、
その中にアクティビティ「タクソノミーを読み込み」を配置します。
※今回は条件分岐なしの処理なのでフローチャートは使わず、シーケンスのみの構造です。
[3-2]ドキュメントをデジタル化(OCRエンジンでドキュメントを解析)
その下に読み込みたいドキュメントのフルパスを用意します。アクティビティ「代入」を配置しましょう。
それぞれ入出力の変数は分かりやすいように日本語名にしています。
変数を作成するときは、テキストボックスの中で、「Ctrl+K」を入力してから変数名を入力すると自動的に適切な型を宣言してくれます。
自動的に型を設定してくれます。アクティビティを配置していく過程で、初めて見る変数は、「Ctrl+K」で作りましょう。
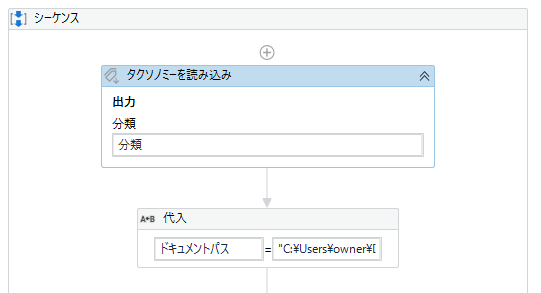

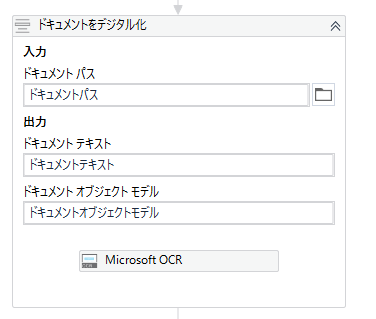
その下に、これです。ドキュメントを「Microsoft OCR」というエンジンで解析します。(ドキュメントをでデジタル化)
アクティビティパネルで「OCR」と検索すれば色んなエンジンが出てきます。
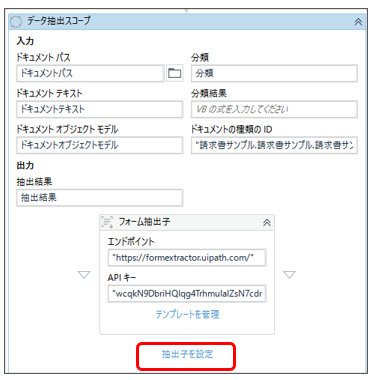
[3-3]データ抽出スコープ(抽出子を選択・抽出内容の位置合わせなど行う)
そして、その下にこれです。
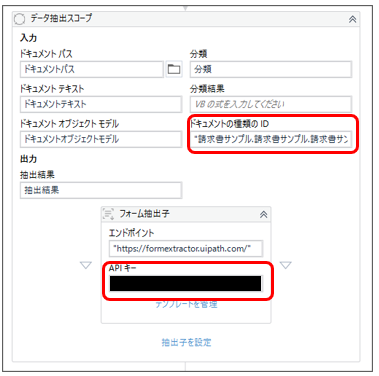
他のWebサイト様だと、「抽出子を設定」のところに「インテリジェントフォーム抽出子」を配置していました。
手書きの文字を抽出したい時に活躍するそうですが、今回は手書きではないので、適当にフォーム抽出子を選んでみました。

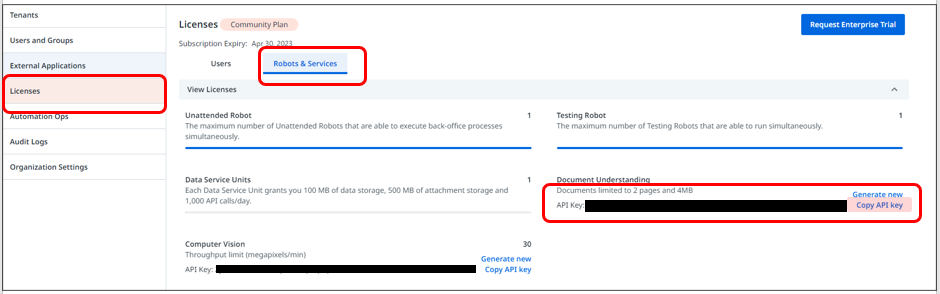
ここで、APIキーを発行して、テキストボックスに入力します。
APIキーはテキストなのでフォルダパス同様、ダブルクォーテーションで囲います。
APIキーの取得_CloudPlatform
「ドキュメントの種類のID」は、タクソノミーマネージャーを開いてコピペします。
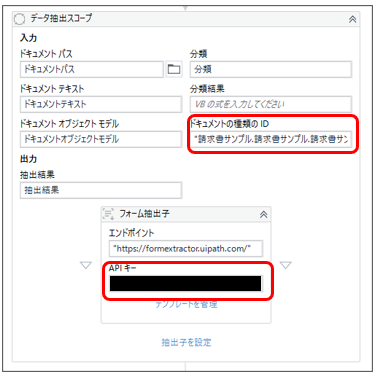
タクソノミーマネージャーで先ほど定義したページを開くと、ウインドウの右上にドキュメント種類IDが見つかります。
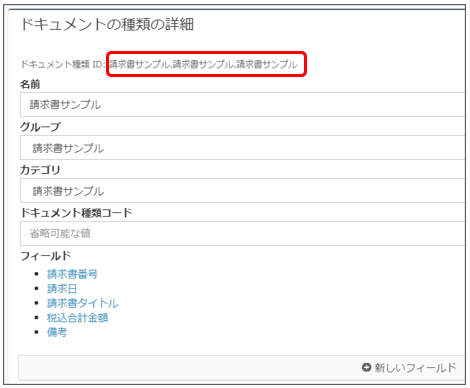
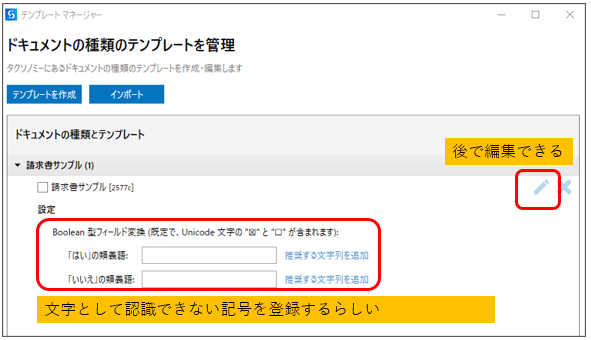
[3-4]抽出子の「テンプレートを管理」で抽出内容の位置合わせを行う。
こんな感じで設定します。
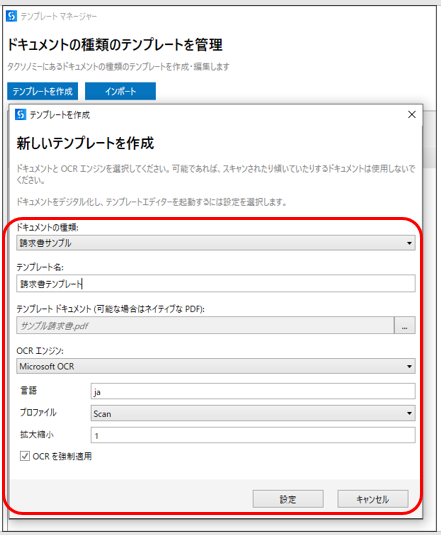
設定ボタンをクリックすると、
テンプレートマネージャーが起動します。
※後で編集することもできます。
よくわからないので、とりあえず、OKボタンを押します。
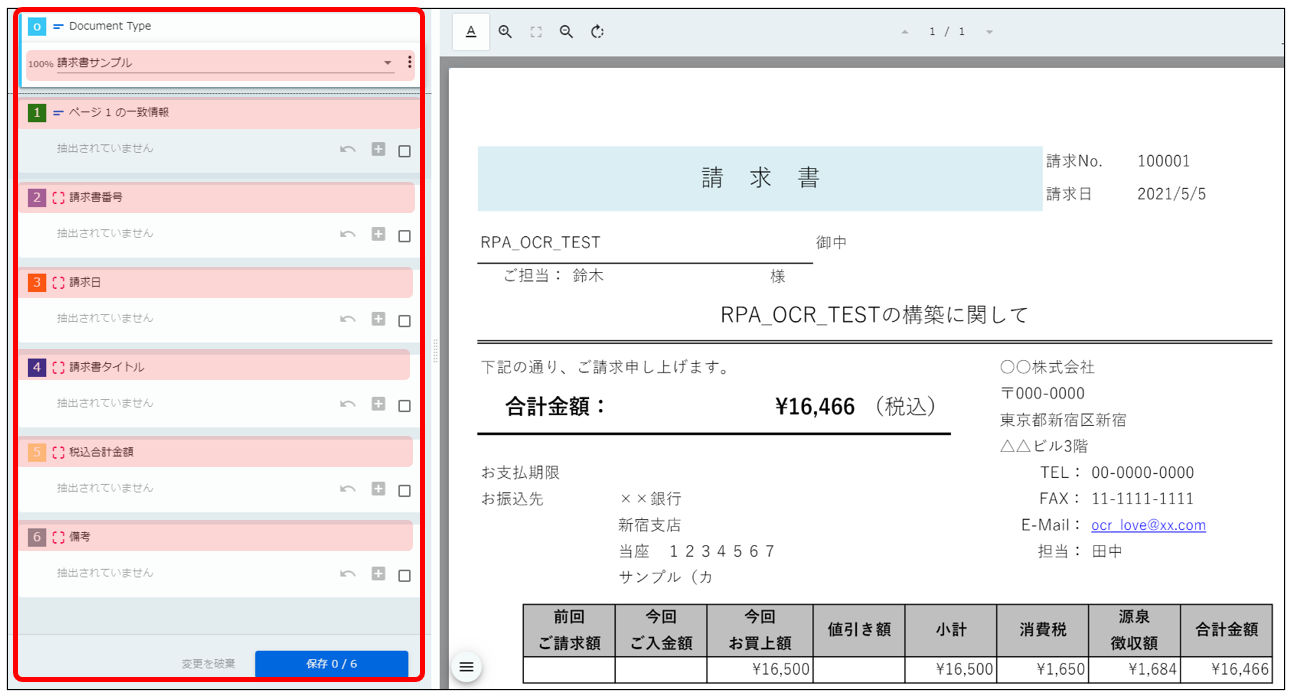
左側をご覧下さい。最初にタクソノミーマネージャーで定義した項目名称が並んでいます。
これから、右側にある請求書と紐づける作業を行います。
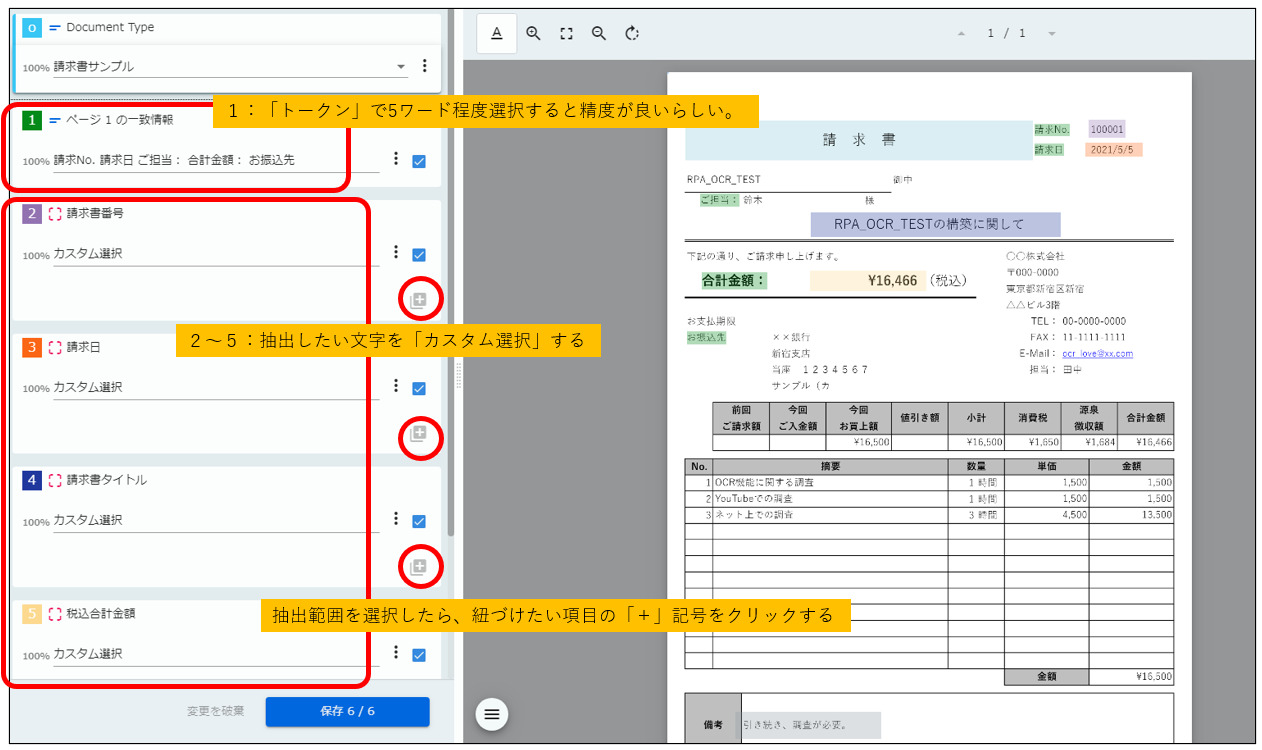
こんな感じです。
<1:トークンで選択>
最初に、ドキュメント内で一致情報を5か所くらい選択するらしいです。
間違った情報を抽出しないように、正しいドキュメントを読み込んでいるのかロボットがチェックしてくれるイメージでしょうか。
複数選択なので、点線の赤枠が出てきたら、「Ctrl+左クリック」で5か所選択した後、「+」記号をクリックします。
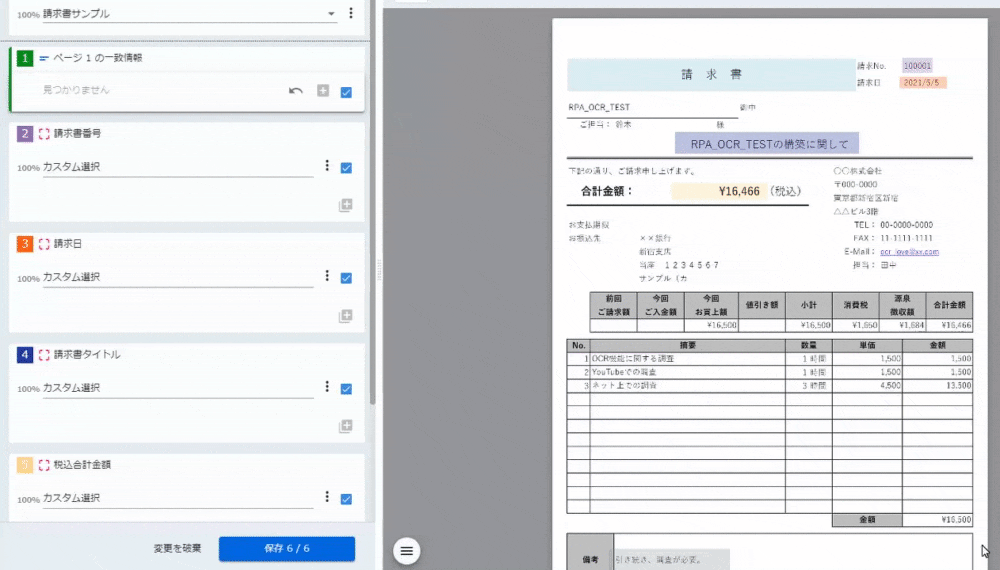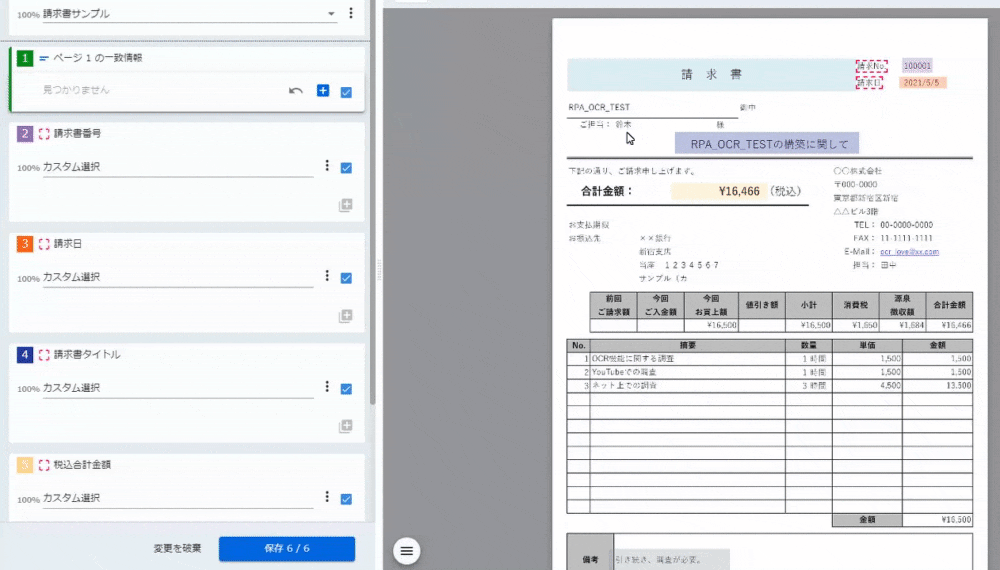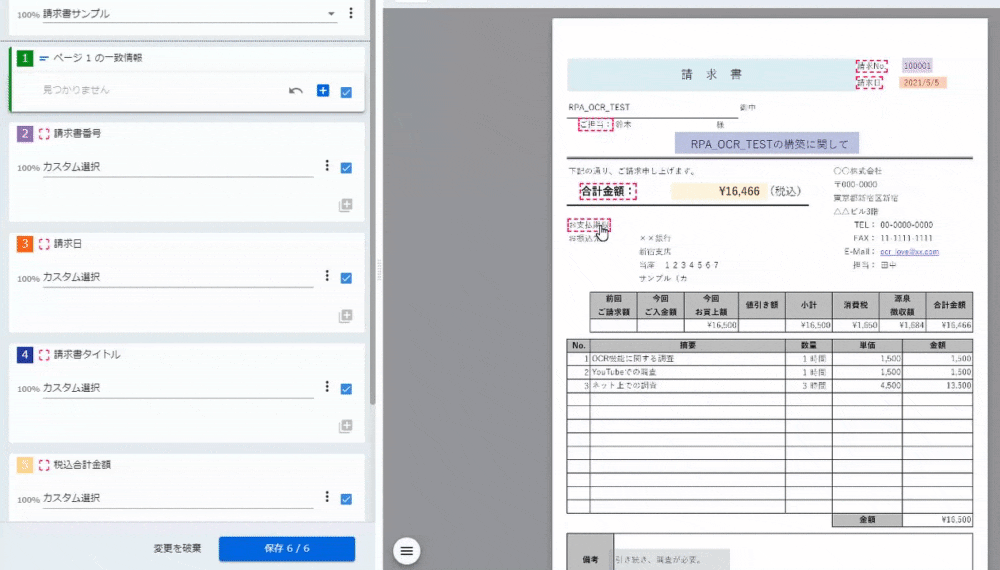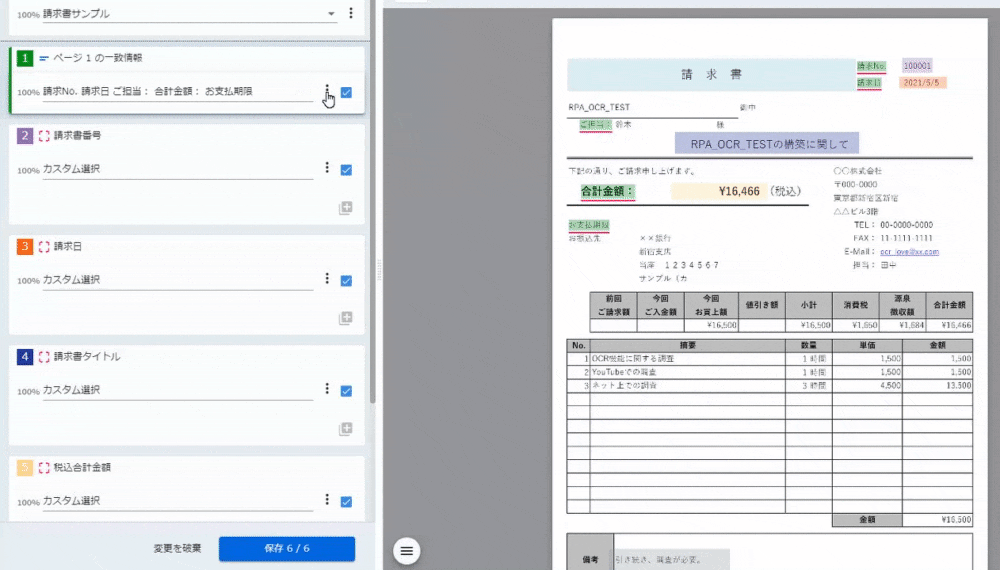
<2~5:カスタム選択>
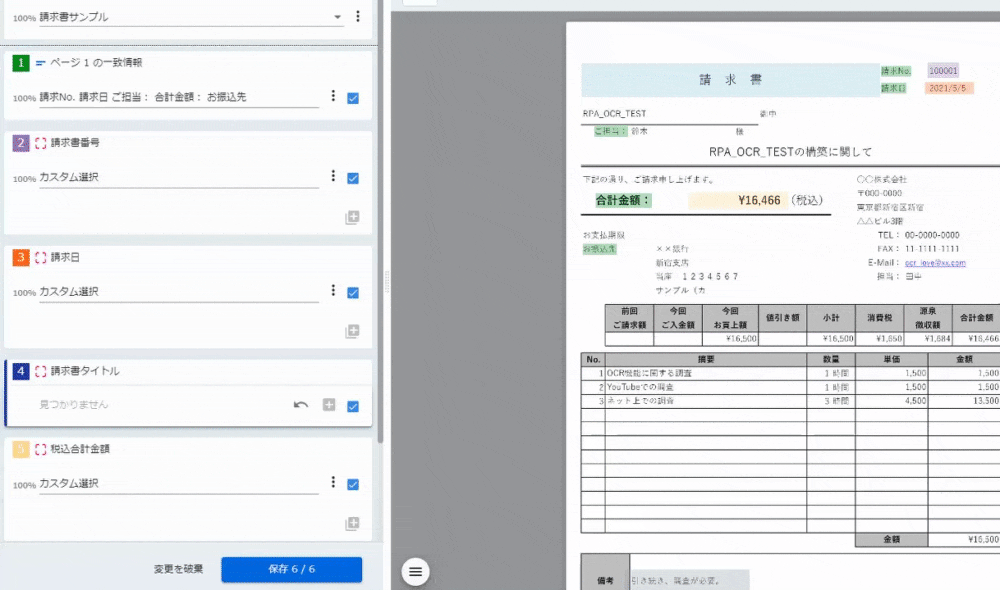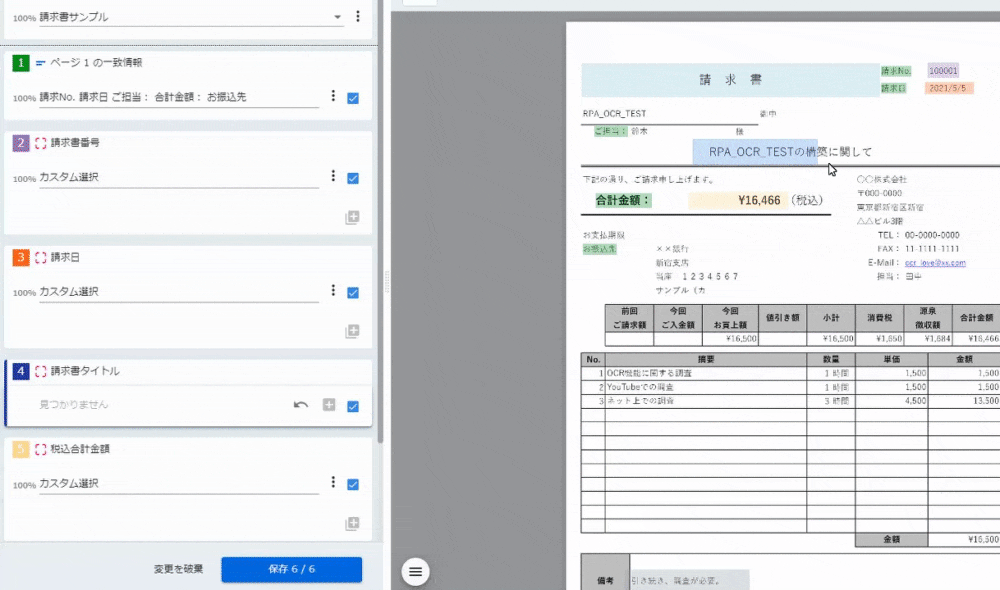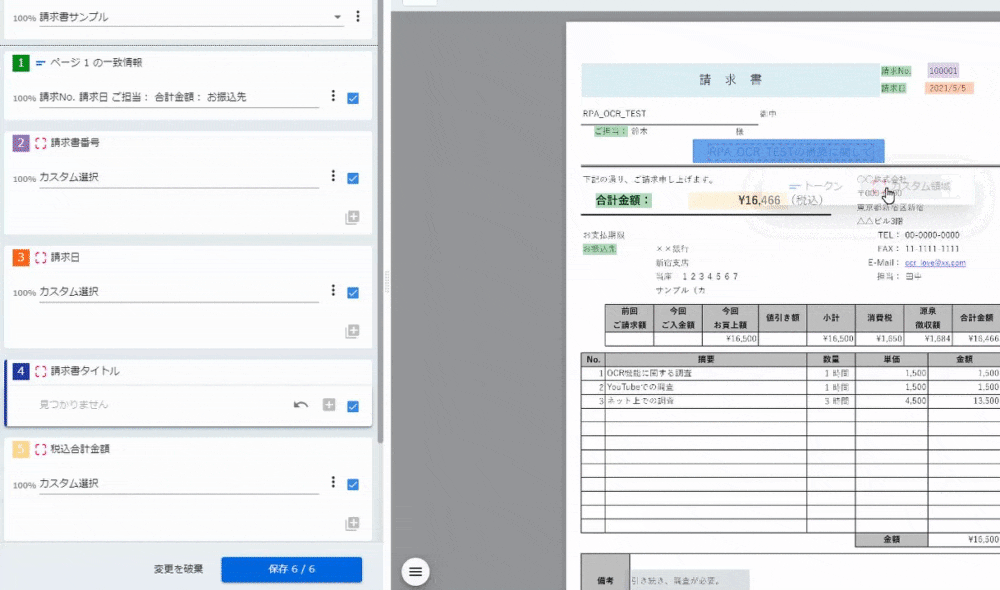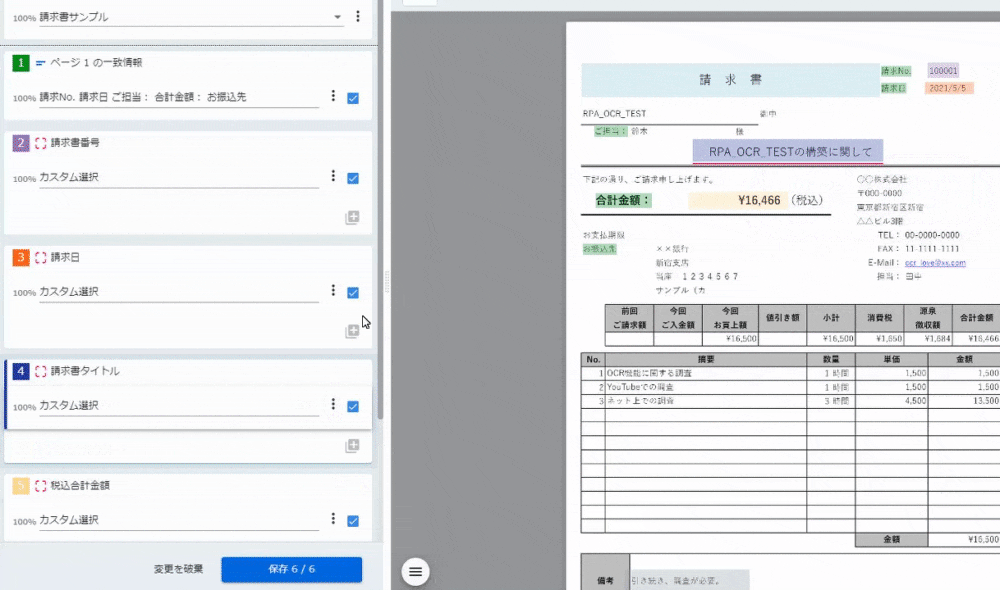
保存した後、この画面になるのだが、今回使わなかったのでスルーしました。「閉じる」ボタンをクリックすると設定が完了です。
[3-5]検証ステーションで人間が目視で精度を確認する
別の媒体に出力する前に人間が目視確認するためのプロセスです。
OCRの精度の答え合わせを人間がするイメージでしょうか。
実行すると毎回、検証画面が開くので本運用では配置しない方がいいかもしれません。
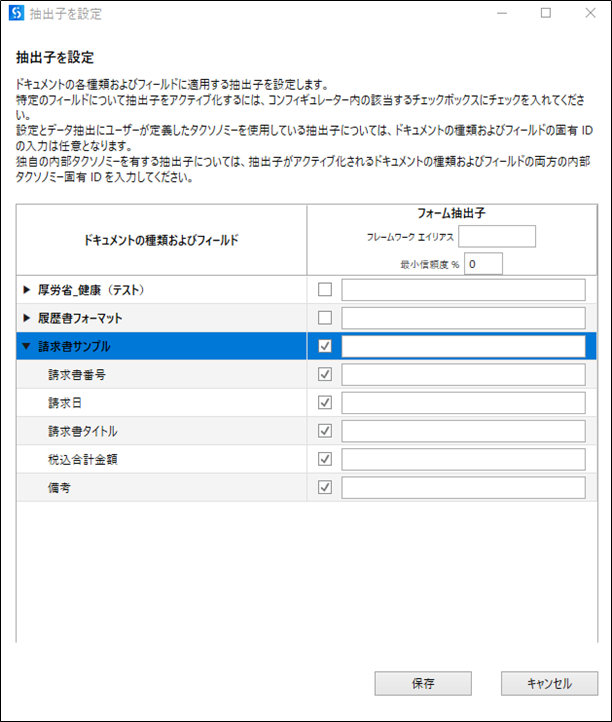
抽出子を設定
「抽出子を設定」のウインドウを開いて「フォーム抽出子」で抽出する項目にチェックを入れます。
[3-6]検証結果のエクスポート(Excelファイルに書き込み)
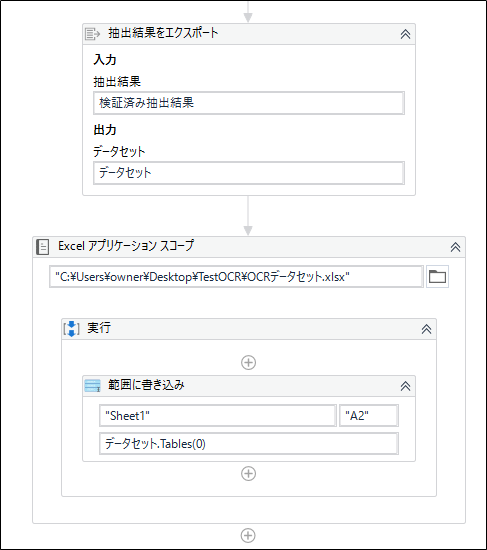
書き込み先ですが、Excelの1行目に項目名を入力したので2行目から書き込まれるよう、「A2セル」をセットしました。
抽出されたデータは、行単位で書き込まれます。
<実行前>

<実行中:検証ステーションの起動>
合ってればチェックを入れてあげて、保存します。
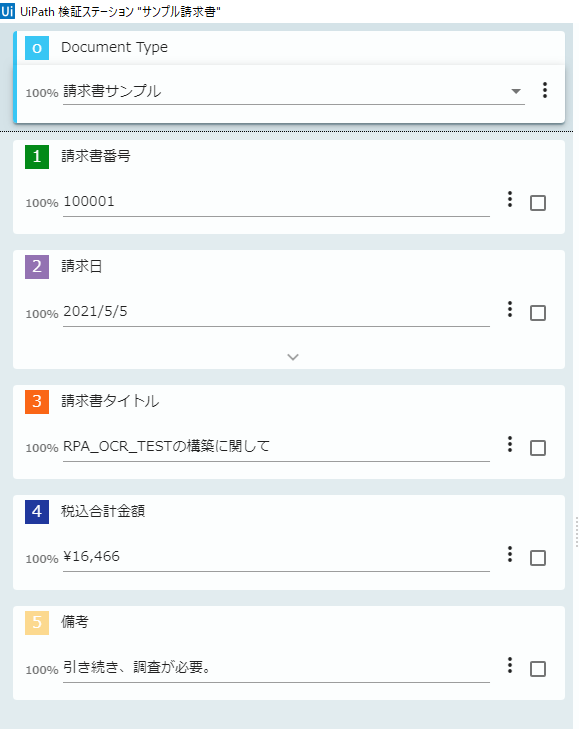
<実行後>
期待していた通りの内容で書き込まれています。

[4]まとめ
いかがでしょうか。
OCR処理の精度が信頼できるようになったら、
検証ステーションのアクティビティを外して自動化が達成できそうですね。
手書きのアンケートをOCR処理するなど、応用例も時間があるときに挑戦したいと思います。
また、今回はデータ1件分の処理ですが、実務では大量の繰り返し処理が発生します。
今後ループ処理を実装したパターンも記事にしていきます。